PyTorch-24h 05_模块化
PyTorch-24h 05_模块化

05. PyTorch Going Modular
本节内容:如何编写/组织python脚本?
我们要把 notebook 04. PyTorch Custom Datasets 变成一系列的脚本,称为模块化(going_modular).
什么是模块化?
模块化涉及将笔记本代码(来自 Jupyter Notebook 或 Google Colab 笔记本)转换为一系列提供类似功能的不同 Python 脚本。
例如,我们可以将笔记本代码从一系列单元格转换为以下 Python 文件:
- ?
data_setup.py: 准备和下载数据. - ?
engine.py: 包含不同的训练函数. - ?
model_builder.pyormodel.py: PyTorch model. - ?
train.py: 训练目标 PyTorch 模型. - ?
utils.py: 专用于有用的实用程序功能的文件.
注意: 上述文件的命名和布局将取决于您的用例和代码要求。
为什么要模块化?
笔记本(jupyter notebook)非常适合迭代探索和快速运行实验。但是,对于更大规模的项目,您可能会发现 Python 脚本更具可重复性且更易于运行。
notebooks vs Python scripts
Pros | Cons | |
|---|---|---|
Notebooks | 容易开始实验 | 很难进行版本控制 |
容易分享 (e.g. a link to a Google Colab notebook) | 难以仅使用特定部分 | |
非常直观 | 文本和图形可能会妨碍代码 |
Pros | Cons | |
|---|---|---|
Python scripts | 便于整合代码 (避免像在notebook里需要重复写相同代码) | 实验不那么直观(要运行整个脚本而不能只运行一段) |
可以用git进行版本控制 | ||
很多开源项目使用这种形式 | ||
大型项目可以在云服务器上运行 (notebooks通常不行) |
My workflow
作者的工作流程: 通常用 Jupyter/Google Colab notebooks 进行简单的尝试。然后将其中有用的部分改写成脚本。
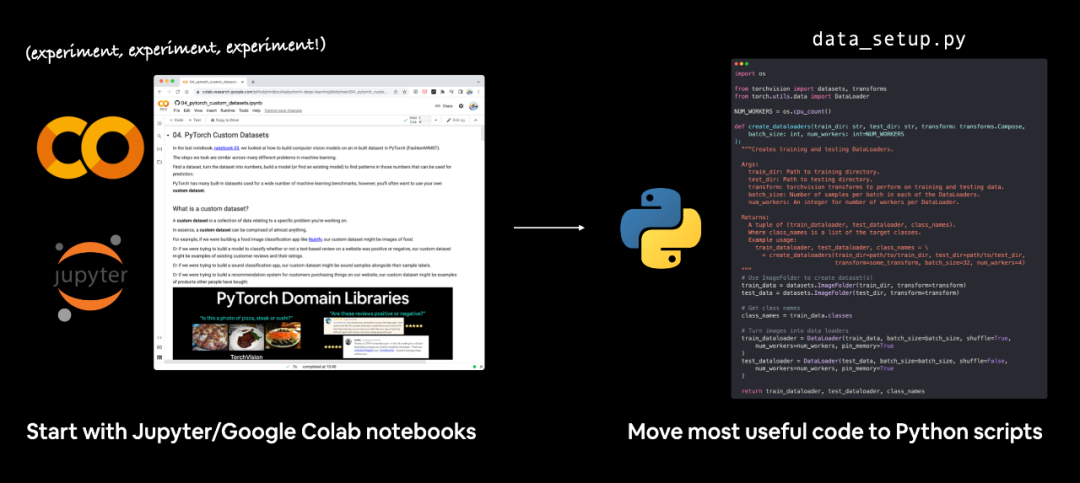
编写机器学习代码有许多可能的工作流程。有些人更喜欢从脚本开始,其他人(像我)更喜欢从笔记本开始,稍后再考虑脚本。
PyTorch in the wild
在您的旅行中,您会看到许多基于 PyTorch 的 ML 项目的代码存储库都有关于如何以 Python 脚本形式运行 PyTorch 代码的说明。
例如,您可能会被指示在终端/命令行中运行如下代码来训练模型:
python train.py --model MODEL_NAME --batch_size BATCH_SIZE --lr LEARNING_RATE --num_epochs NUM_EPOCHS
使用各种超参数设置在命令行上运行PyTorch train.py脚本。
本例中, train.py 是目标脚本, 包含训练模型的函数。 --model, --batch_size, --lr 和 --num_epochs 被称为参数标志。可以为它们设置不同的值。例如,假设我们想从 notebook 04 训练 TinyVGG 模型 10 个 epoch,批量大小为 32,学习率为 0.001:
python train.py --model tinyvgg --batch_size 32 --lr 0.001 --num_epochs 10您可以在您的 train.py 脚本中设置任意数量的这些参数标志以满足您的需要。
用于训练最先进的计算机视觉模型的 PyTorch 博客文章使用了这种风格。

PyTorch command line training script recipe for training state-of-the-art computer vision models with 8 GPUs. Source: PyTorch blog.
What we're going to cover
本节的主要概念是:将有用的笔记本代码单元转换为可重用的 Python 文件。 这样做将节省我们一遍又一遍地编写相同的代码。
本节有两个笔记本:
- 1. 05. Going Modular: Part 1 (cell mode) : 这个笔记本是传统的Jupyter笔记本/Google Colab笔记本,是笔记本04的精简版.
- 2. 05. Going Modular: Part 2 (script mode) : 这个笔记本与第1个笔记本相同,但增加了将每个主要部分转换为Python脚本的功能,例如
data_setup.py和train.py.
本文档中的文本集中于代码单元05. Going Modular: Part 2 (script mode),带有“%%writefile…”在顶部。
Why two parts?
因为学习某物的最好方式是对比它与先前的不同。 如果您并排运行每个笔记本,您会发现它们有何不同。
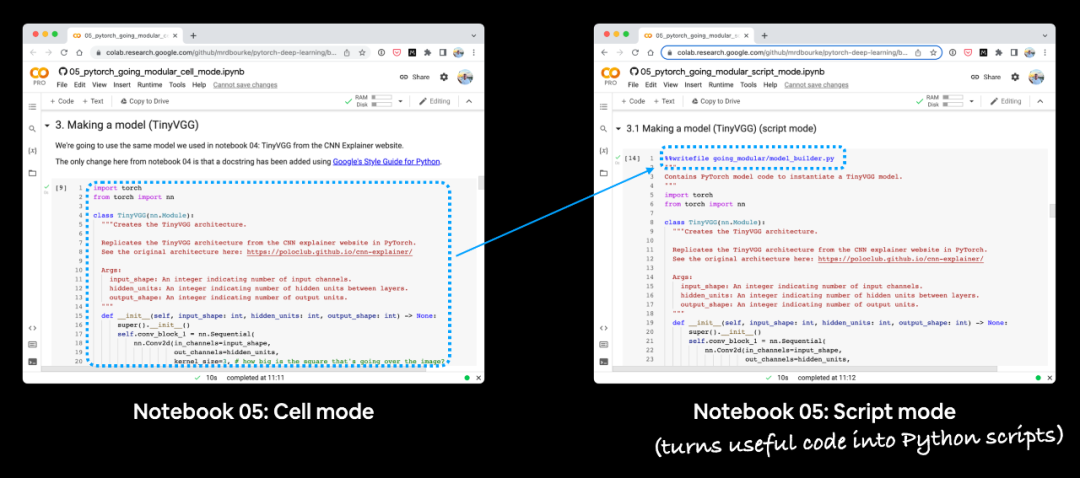
并排运行第 05 节的两个笔记本。 您会注意到脚本模式笔记本具有额外的代码单元,可将单元模式笔记本中的代码转换为 Python 脚本。
What we're working towards
在本节结束时,我们希望实现两个目标:
- 1. 能够通过在命令行中使用一行代码:
python train.py训练我们在notebook 04(Food Vision Mini)中构建的模型, - 2. 可复用的Python脚本的目录结构,如:
going_modular/
├── going_modular/
│ ├── data_setup.py
│ ├── engine.py
│ ├── model_builder.py
│ ├── train.py
│ └── utils.py
├── models/
│ ├── 05_going_modular_cell_mode_tinyvgg_model.pth
│ └── 05_going_modular_script_mode_tinyvgg_model.pth
└── data/
└── pizza_steak_sushi/
├── train/
│ ├── pizza/
│ │ ├── image01.jpeg
│ │ └── ...
│ ├── steak/
│ └── sushi/
└── test/
├── pizza/
├── steak/
└── sushi/Things to note
- ? Docstrings: 编写可重现和可理解的代码很重要。 考虑到这一点,我们将放入脚本中的每个函数/类都是使用 Google 的 Python 文档字符串样式。
- ? 脚本顶部的导入 - 由于我们将要创建的所有 Python 脚本都可以单独视为一个小程序,因此所有脚本都需要在脚本开头导入它们的输入模块 例子:
# Import modules required for train.py
import os
import torch
import data_setup, engine, model_builder, utils
from torchvision import transformsWhere can you get help?
所有材料都可以在github上找到 https://github.com/mrdbourke/pytorch-deep-learning
官方文档通常很有帮助: PyTorch documentation:https://pytorch.org/docs/stable/index.html PyTorch developer forums:https://discuss.pytorch.org/
0. Cell mode vs. script mode
单元模式笔记本,例如 05. Going Modular Part 1 (cell mode) 是一个正常运行的notebook,notebook中的每个单元格都是代码。
脚本模式笔记本,例如 05. Going Modular 第 2 部分(脚本模式) 与单元模式笔记本非常相似,但是,许多 代码单元可以变成 Python 脚本。
注意: 您不需要通过笔记本(notebook)创建 Python 脚本,您可以直接通过 IDE(集成开发人员环境)创建它们,例如 PyCharm、VS Code。 将脚本模式笔记本作为本节的一部分只是为了演示从笔记本到 Python 脚本的一种方式。
1. Get data
获取数据的方法和notebook 04中的一样。
通过 requests 下载一个.zip 文件,然后unzip。
import os
import requests
import zipfile
from pathlib import Path
# Setup path to data folder
data_path = Path("data/")
image_path = data_path / "pizza_steak_sushi"
# If the image folder doesn't exist, download it and prepare it...
if image_path.is_dir():
print(f"{image_path} directory exists.")
else:
print(f"Did not find {image_path} directory, creating one...")
image_path.mkdir(parents=True, exist_ok=True)
# Download pizza, steak, sushi data
with open(data_path / "pizza_steak_sushi.zip", "wb") as f:
request = requests.get("https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip")
print("Downloading pizza, steak, sushi data...")
f.write(request.content)
# Unzip pizza, steak, sushi data
with zipfile.ZipFile(data_path / "pizza_steak_sushi.zip", "r") as zip_ref:
print("Unzipping pizza, steak, sushi data...")
zip_ref.extractall(image_path)
# Remove zip file
os.remove(data_path / "pizza_steak_sushi.zip")解压后的数据如下:
data/
└── pizza_steak_sushi/
├── train/
│ ├── pizza/
│ │ ├── train_image01.jpeg
│ │ ├── test_image02.jpeg
│ │ └── ...
│ ├── steak/
│ │ └── ...
│ └── sushi/
│ └── ...
└── test/
├── pizza/
│ ├── test_image01.jpeg
│ └── test_image02.jpeg
├── steak/
└── sushi/2. Create Datasets and DataLoaders (data_setup.py)
获得数据后,我们可以将其转换为 PyTorch 的Dataset和DataLoader一个用于训练数据,一个用于测试数据。
我们将有用的 Dataset 和 DataLoader 创建代码转换成一个名为 create_dataloaders() 的函数。
并通过%%writefile going_modular/data_setup.py写入文件。
%%writefile going_modular/data_setup.py
"""
Contains functionality for creating PyTorch DataLoaders for
image classification data.
"""
import os
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
NUM_WORKERS = os.cpu_count()
def create_dataloaders(
train_dir: str,
test_dir: str,
transform: transforms.Compose,
batch_size: int,
num_workers: int=NUM_WORKERS
):
"""Creates training and testing DataLoaders.
Takes in a training directory and testing directory path and turns
them into PyTorch Datasets and then into PyTorch DataLoaders.
Args:
train_dir: Path to training directory.
test_dir: Path to testing directory.
transform: torchvision transforms to perform on training and testing data.
batch_size: Number of samples per batch in each of the DataLoaders.
num_workers: An integer for number of workers per DataLoader.
Returns:
A tuple of (train_dataloader, test_dataloader, class_names).
Where class_names is a list of the target classes.
Example usage:
train_dataloader, test_dataloader, class_names = \
= create_dataloaders(train_dir=path/to/train_dir,
test_dir=path/to/test_dir,
transform=some_transform,
batch_size=32,
num_workers=4)
"""
# Use ImageFolder to create dataset(s)
train_data = datasets.ImageFolder(train_dir, transform=transform)
test_data = datasets.ImageFolder(test_dir, transform=transform)
# Get class names
class_names = train_data.classes
# Turn images into data loaders
train_dataloader = DataLoader(
train_data,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=True,
)
test_dataloader = DataLoader(
test_data,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=True,
)
return train_dataloader, test_dataloader, class_names我们现在可以用 data_setup.py获得DataLoader:
# Import data_setup.py
from going_modular import data_setup
# Create train/test dataloader and get class names as a list
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(...)3. Making a model (model_builder.py)
在过去的几个笔记本(notebook 03 和 notebook 04)中,我们已经构建了几次 TinyVGG 模型。
因此,将模型放入其文件中是有意义的,这样我们就可以一次又一次地重用它。
将我们的 TinyVGG() 模型变成脚本 %%writefile going_modular/model_builder.py:
%%writefile going_modular/model_builder.py
"""
Contains PyTorch model code to instantiate a TinyVGG model.
"""
import torch
from torch import nn
class TinyVGG(nn.Module):
"""Creates the TinyVGG architecture.
Replicates the TinyVGG architecture from the CNN explainer website in PyTorch.
See the original architecture here: https://poloclub.github.io/cnn-explainer/
Args:
input_shape: An integer indicating number of input channels.
hidden_units: An integer indicating number of hidden units between layers.
output_shape: An integer indicating number of output units.
"""
def __init__(self, input_shape: int, hidden_units: int, output_shape: int) -> None:
super().__init__()
self.conv_block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=0),
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2)
)
self.conv_block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=0),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, kernel_size=3, padding=0),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# Where did this in_features shape come from?
# It's because each layer of our network compresses and changes the shape of our inputs data.
nn.Linear(in_features=hidden_units*13*13,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.conv_block_1(x)
x = self.conv_block_2(x)
x = self.classifier(x)
return x
# return self.classifier(self.conv_block_2(self.conv_block_1(x))) # <- leverage the benefits of operator fusion现在我们只需要导入模块,不用每次都实现一遍了:
import torch
# Import model_builder.py
from going_modular import model_builder
device = "cuda" if torch.cuda.is_available() else "cpu"
# Instantiate an instance of the model from the "model_builder.py" script
torch.manual_seed(42)
model = model_builder.TinyVGG(input_shape=3,
hidden_units=10,
output_shape=len(class_names)).to(device)4. Creating train_step() and test_step() functions and train() to combine them
我们写过很多训练函数notebook 04:
- 1.
train_step()- takes in a model, aDataLoader, a loss function and an optimizer and trains the model on theDataLoader. - 2.
test_step()- takes in a model, aDataLoaderand a loss function and evaluates the model on theDataLoader. - 3.
train()- performs 1. and 2. together for a given number of epochs and returns a results dictionary.
由于这些将是我们模型训练的引擎,我们可以将它们全部放入名为 engine.py 的 Python 脚本中 %%writefile going_modular/engine.py:
%%writefile going_modular/engine.py
"""
Contains functions for training and testing a PyTorch model.
"""
import torch
from tqdm.auto import tqdm
from typing import Dict, List, Tuple
def train_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
device: torch.device) -> Tuple[float, float]:
"""Trains a PyTorch model for a single epoch.
Turns a target PyTorch model to training mode and then
runs through all of the required training steps (forward
pass, loss calculation, optimizer step).
Args:
model: A PyTorch model to be trained.
dataloader: A DataLoader instance for the model to be trained on.
loss_fn: A PyTorch loss function to minimize.
optimizer: A PyTorch optimizer to help minimize the loss function.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A tuple of training loss and training accuracy metrics.
In the form (train_loss, train_accuracy). For example:
(0.1112, 0.8743)
"""
# Put model in train mode
model.train()
# Setup train loss and train accuracy values
train_loss, train_acc = 0, 0
# Loop through data loader data batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
y_pred = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(y_pred, y)
train_loss += loss.item()
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
# Calculate and accumulate accuracy metric across all batches
y_pred_class = torch.argmax(torch.softmax(y_pred, dim=1), dim=1)
train_acc += (y_pred_class == y).sum().item()/len(y_pred)
# Adjust metrics to get average loss and accuracy per batch
train_loss = train_loss / len(dataloader)
train_acc = train_acc / len(dataloader)
return train_loss, train_acc
def test_step(model: torch.nn.Module,
dataloader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
device: torch.device) -> Tuple[float, float]:
"""Tests a PyTorch model for a single epoch.
Turns a target PyTorch model to "eval" mode and then performs
a forward pass on a testing dataset.
Args:
model: A PyTorch model to be tested.
dataloader: A DataLoader instance for the model to be tested on.
loss_fn: A PyTorch loss function to calculate loss on the test data.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A tuple of testing loss and testing accuracy metrics.
In the form (test_loss, test_accuracy). For example:
(0.0223, 0.8985)
"""
# Put model in eval mode
model.eval()
# Setup test loss and test accuracy values
test_loss, test_acc = 0, 0
# Turn on inference context manager
with torch.inference_mode():
# Loop through DataLoader batches
for batch, (X, y) in enumerate(dataloader):
# Send data to target device
X, y = X.to(device), y.to(device)
# 1. Forward pass
test_pred_logits = model(X)
# 2. Calculate and accumulate loss
loss = loss_fn(test_pred_logits, y)
test_loss += loss.item()
# Calculate and accumulate accuracy
test_pred_labels = test_pred_logits.argmax(dim=1)
test_acc += ((test_pred_labels == y).sum().item()/len(test_pred_labels))
# Adjust metrics to get average loss and accuracy per batch
test_loss = test_loss / len(dataloader)
test_acc = test_acc / len(dataloader)
return test_loss, test_acc
def train(model: torch.nn.Module,
train_dataloader: torch.utils.data.DataLoader,
test_dataloader: torch.utils.data.DataLoader,
optimizer: torch.optim.Optimizer,
loss_fn: torch.nn.Module,
epochs: int,
device: torch.device) -> Dict[str, List]:
"""Trains and tests a PyTorch model.
Passes a target PyTorch models through train_step() and test_step()
functions for a number of epochs, training and testing the model
in the same epoch loop.
Calculates, prints and stores evaluation metrics throughout.
Args:
model: A PyTorch model to be trained and tested.
train_dataloader: A DataLoader instance for the model to be trained on.
test_dataloader: A DataLoader instance for the model to be tested on.
optimizer: A PyTorch optimizer to help minimize the loss function.
loss_fn: A PyTorch loss function to calculate loss on both datasets.
epochs: An integer indicating how many epochs to train for.
device: A target device to compute on (e.g. "cuda" or "cpu").
Returns:
A dictionary of training and testing loss as well as training and
testing accuracy metrics. Each metric has a value in a list for
each epoch.
In the form: {train_loss: [...],
train_acc: [...],
test_loss: [...],
test_acc: [...]}
For example if training for epochs=2:
{train_loss: [2.0616, 1.0537],
train_acc: [0.3945, 0.3945],
test_loss: [1.2641, 1.5706],
test_acc: [0.3400, 0.2973]}
"""
# Create empty results dictionary
results = {"train_loss": [],
"train_acc": [],
"test_loss": [],
"test_acc": []
}
# Loop through training and testing steps for a number of epochs
for epoch in tqdm(range(epochs)):
train_loss, train_acc = train_step(model=model,
dataloader=train_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
device=device)
test_loss, test_acc = test_step(model=model,
dataloader=test_dataloader,
loss_fn=loss_fn,
device=device)
# Print out what's happening
print(
f"Epoch: {epoch+1} | "
f"train_loss: {train_loss:.4f} | "
f"train_acc: {train_acc:.4f} | "
f"test_loss: {test_loss:.4f} | "
f"test_acc: {test_acc:.4f}"
)
# Update results dictionary
results["train_loss"].append(train_loss)
results["train_acc"].append(train_acc)
results["test_loss"].append(test_loss)
results["test_acc"].append(test_acc)
# Return the filled results at the end of the epochs
return results现在只需要从 engine.py 导入函数:
# Import engine.py
from going_modular import engine
# Use train() by calling it from engine.py
engine.train(...)5. Creating a function to save the model (utils.py)
通常,您会希望在训练时或训练后保存模型。
由于我们在以前的笔记本中已经编写了几次保存模型的代码,因此将其转换为函数并将其保存到文件是有意义的。
将辅助函数存储在一个名为“utils.py”(实用程序utilities的缩写)的文件中是一种常见的做法。
让我们将功能 save_model() 写入文件 utils.py : %%writefile going_modular/utils.py:
%%writefile going_modular/utils.py
"""
Contains various utility functions for PyTorch model training and saving.
"""
import torch
from pathlib import Path
def save_model(model: torch.nn.Module,
target_dir: str,
model_name: str):
"""Saves a PyTorch model to a target directory.
Args:
model: A target PyTorch model to save.
target_dir: A directory for saving the model to.
model_name: A filename for the saved model. Should include
either ".pth" or ".pt" as the file extension.
Example usage:
save_model(model=model_0,
target_dir="models",
model_name="05_going_modular_tingvgg_model.pth")
"""
# Create target directory
target_dir_path = Path(target_dir)
target_dir_path.mkdir(parents=True,
exist_ok=True)
# Create model save path
assert model_name.endswith(".pth") or model_name.endswith(".pt"), "model_name should end with '.pt' or '.pth'"
model_save_path = target_dir_path / model_name
# Save the model state_dict()
print(f"[INFO] Saving model to: {model_save_path}")
torch.save(obj=model.state_dict(),
f=model_save_path)想要保存模型时只需要导入 save_model() :
# Import utils.py
from going_modular import utils
# Save a model to file
save_model(model=...
target_dir=...,
model_name=...)6. Train, evaluate and save the model (train.py)
如前所述,您经常会遇到 PyTorch 存储库,它们将所有功能组合在一个 train.py 文件中。
该文件本质上是说“使用任何可用数据训练模型”。
在我们的train.py文件中,我们将结合我们创建的其他 Python 脚本的所有功能,并使用它来训练模型。
通过这种方式,我们可以在命令行上使用一行代码来训练 PyTorch 模型:
python train.py为了创建 train.py ,我们将实现如下步骤:
- 1. 导入各种依赖项,即
torch、os、torchvision.transforms以及going_modular目录、data_setup、engine、model_builder、utils中的所有脚本。
- ? 注意: 由于
train.py将在going_modular目录中,我们可以通过import ...导入其他模块,而不是from going_modular import ...。
- 1. 设置各种超参数,例如批量大小、时期数、学习率和隐藏单元数(这些可以在未来通过
argparse设置)。 - 2. 设置训练和测试目录。
- 3. 设置与设备无关的代码。
- 4. 创建必要的数据转换。
- 5. 使用
data_setup.py创建 DataLoader。 - 6. 使用
model_builder.py创建模型。 - 7. 设置损失函数和优化器。
- 8. 使用
engine.py训练模型。 - 9. 使用
utils.py保存模型。
我们可以使用 %%writefile going_modular/train.py 行从笔记本单元创建文件:
%%writefile going_modular/train.py
"""
Trains a PyTorch image classification model using device-agnostic code.
"""
import os
import torch
import data_setup, engine, model_builder, utils
from torchvision import transforms
# Setup hyperparameters
NUM_EPOCHS = 5
BATCH_SIZE = 32
HIDDEN_UNITS = 10
LEARNING_RATE = 0.001
# Setup directories
train_dir = "data/pizza_steak_sushi/train"
test_dir = "data/pizza_steak_sushi/test"
# Setup target device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Create transforms
data_transform = transforms.Compose([
transforms.Resize((64, 64)),
transforms.ToTensor()
])
# Create DataLoaders with help from data_setup.py
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(
train_dir=train_dir,
test_dir=test_dir,
transform=data_transform,
batch_size=BATCH_SIZE
)
# Create model with help from model_builder.py
model = model_builder.TinyVGG(
input_shape=3,
hidden_units=HIDDEN_UNITS,
output_shape=len(class_names)
).to(device)
# Set loss and optimizer
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=LEARNING_RATE)
# Start training with help from engine.py
engine.train(model=model,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
loss_fn=loss_fn,
optimizer=optimizer,
epochs=NUM_EPOCHS,
device=device)
# Save the model with help from utils.py
utils.save_model(model=model,
target_dir="models",
model_name="05_going_modular_script_mode_tinyvgg_model.pth")我们可用下面语句训练模型:
python train.py这样做将利用我们创建的所有其他代码脚本。
如果我们愿意,我们可以调整我们的 train.py 文件以使用 Python 的 argparse 模块的参数标志输入,这将允许我们提供不同的超参数设置,如前所述:
参考argparse模块
python train.py --model MODEL_NAME --batch_size BATCH_SIZE --lr LEARNING_RATE --num_epochs NUM_EPOCHS