PCAΓΔSVD…ν»κ«≥≥ω”κpython¥ζ¬κ
PCAΓΔSVD…ν»κ«≥≥ω”κpython¥ζ¬κ

Έ“Ηω»ΥΒΡάμΫβΘΚPCA±Ψ÷ …œΨΆ «―Α’“ ΐΨίΒΡ÷ς≥…Ζ÷ΓΘΈ“Ο«Ω…“‘ΦρΒΞΒΡ¥ρΗω±»ΖΫΘ§ΦΌ…η”–“ΜΉιΗΏΈ§ ΐΨίΓΘΥϊΒΡ÷ς≥…Ζ÷ΖΫœρΨΆ «”Ο“ΜΗωœΏ–‘ΜΊΙιΡβΚœ’β–©ΗΏΈ§ ΐΨίΒΡΖΫœρΓΘ”ΟΉν–ΓΕΰ≥ΥΒΡ¬ΏΦ≠ΡβΚœΒΡΓΘΤδΥϊΒΡ÷ς≥…Ζ÷ΕΦ «”κΉν¥σ÷ς≥…Ζ÷’ΐΫΜΒΡΓΘ
Ρ«Ο¥Έ“Ο«»γΚΈΒΟΒΫ’β–©ΑϋΚ§÷ς≥…Ζ÷ΖΫœρΡΊΘΩ
Ά®ΙΐΦΤΥψ ΐΨίΨΊ’σΒΡ–≠ΖΫ≤νΨΊ’σΘ§»ΜΚσΒΟΒΫ–≠ΖΫ≤νΨΊ’σΒΡΧΊ’ς÷ΒΚΆΧΊ’ςœρΝΩΘ§―Γ‘ώΧΊ’ς÷ΒΉν¥σΒΡkΗωΧΊ’ςΕ‘”ΠΒΡΧΊ’ςœρΝΩΉι≥…ΒΡΨΊ’σΨΆΩ…“‘ΝΥΓΘ’βΗωΨΊ’σΨΆΩ…“‘ΫΪ‘≠ ΦmΈ§Ε»ΒΡΧΊ’ςΉΣΜΜ≥…kΈ§Ε»ΓΘ
Ρ«Ο¥Έ“Ο«»γΚΈΒΟΒΫ ΐΨίΒΡΧΊ’ςœρΝΩΡΊΘΩ
“ΜΑψ”–ΝΫ÷÷ΖΫΖ®ΘΚ
- ΧΊ’ς÷ΒΖ÷Ϋβ–≠ΖΫ≤νΨΊ’σ
- Τφ“λ÷ΒΖ÷Ϋβ–≠ΖΫ≤νΨΊ’σΓΘ
Υυ“‘PCAΥψΖ®”–ΝΫ÷÷ Βœ÷Θ§Ζ÷±π «Μυ”ΎΧΊ’ς÷ΒΖ÷ΫβΖΫ≤νΨΊ’σ Βœ÷PCAΓΔΜυ”ΎSVDΖ÷ΫβΒΡ–≠ΖΫ≤νΨΊ’σPCAΥψΖ®ΓΘ
–≠ΖΫ≤νΨΊ’σΚΆ…ΔΕ»ΨΊ’σ
―υ±ΨΨυ÷ΒΘΚ
―υ±ΨΖΫ≤νΘΚ
―υ±ΨXΚΆ―υ±ΨYΘ®XΚΆY «ΝΫΗω±δΝΩΘ©ΒΡ–≠ΖΫ≤νΘΚ
¥”…œΟφΙΪ ΫΩ…“‘ΒΟΒΫ“‘œ¬Ϋα¬έΘΚ
- –≠ΖΫ≤ν «‘ΎΝΫΗω±δΝΩΦδΦΤΥψΒΡΘ§ΖΫ≤νΩ…“‘Ω¥≥…–≠ΖΫ≤νΒΡΧΊ’ς«ιΩω
- ΖΫ≤νΚΆ–≠ΖΫ≤ν≥ΐ“‘ΝΥn-1Θ§’β «ΒΟΒΫΖΫ≤νΚΆ–≠ΖΫ≤νΒΡΈόΤΪΙάΦΤΓΘ
–≠ΖΫ≤ν¥σ”Ύ0Θ§XΚΆYΈΣ’ΐœύΙΊΙΊœΒΘ§–Γ”Ύ0ΨΆ «ΗΚœύΙΊΘ§Β»”Ύ0ΨΆ «œύΜΞΕάΝΔΓΘ
Β±œ÷‘Ύ”–NΗω±δΝΩΘ§Έ“Ο«“ΣΦΤΥψ’βnΗω±δΝΩΒΡ±Υ¥ΥΝΫΝΫΒΡ–≠ΖΫ≤νΒΡ ±ΚρΘ§ΨΆΙΙ≥…ΝΥ–≠ΖΫ≤νΨΊ’σΓΘΕ‘”Ύ»ΐΗω±δΝΩXYZΘΚ

image.png
œ÷‘ΎΈ“Ο«ά¥Ω¥…ΔΕ»ΨΊ’σΒΡΕ®“εΓΘ
?the scatter matrix is computed by the following equation:
–η“ΣΉΔ“βΒΡ «Θ§…ΔΕ»ΨΊ’σΚΆ–≠ΖΫ≤νΨΊ’σΤδ ΒΨΆ «±Ε ΐΙΊœΒΘ®n-1Θ©±ΕΓΘ…ΔΕ»ΨΊ’σΒΡ–¥Ζ® «ΨΊ’σΒΡ–¥Ζ®Θ§ΚΆ–≠ΖΫ≤νΨΊ’σΙΪ ΫΤδ ΒΒ»ΦέΓΘ
- ΙΪ Ϋ÷–ΒΡn «―υ±Ψ ΐΝΩ
- Ε‘”ΎΟΩ“ΜΗω―υ±Ψ
,Έ“Ο«Ω…“‘ΦΌ…ηΟΩ“ΜΗω―υ±ΨΕΦΑϋΚ§nΗωΧΊ’ςΘ§“≤ΨΆ «ΟΩ“ΜΗω―υ±ΨΕΦ «mΈ§Ε» ΐΨίΓΘ
- Υυ“‘ΉνΚσΩ…“‘ΒΟΒΫ“ΜΗωmxmΒΡΨΊ’σΘ§Ζ÷±π±μ ΨΟΩ“ΜΗωΧΊ’ςΚΆΤδΥϊΒΡΧΊ’ςΒΡ–≠ΖΫ≤νΘ®…ΔΕ»Θ©
- –¥≥…ΨΊ’σΒΡ–Έ ΫΘ§ΦΌ…η
«mxnΒΡ’≈ΝΩΘ§Ρ«Ο¥…ΔΕ»ΨΊ’σΩ…“‘–¥≥…
…ΔΕ»ΨΊ’σΚΆ–≠ΖΫ≤νΨΊ’σΒΡΧΊ’ς÷ΒΚΆΧΊ’ςœρΝΩ «“Μ―υΒΡΓΘ
ΧΊ’ς÷ΒΖ÷ΫβΨΊ’σ‘≠άμ
ΧΊ’ς÷ΒΖ÷ΫβΚΆΤφ“λ÷ΒΖ÷Ϋβ‘ΎΜζΤς―ßœΑ÷–ΕΦ «Κή≥ΘΦϊΒΡΨΊ’σΖ÷ΫβΥψΖ®ΓΘΝΫ’Ώ”–Ή≈ΚήΫτΟήΒΡΙΊœΒΘ§ΡΩΒΡΕΦ «Χα»Γ≥ωΨΊ’σΒΡΉν÷Ί“ΣΒΡΧΊ’ςΓΘ
»γΙϊ“ΜΗωœρΝΩv «ΨΊ’σAΒΡΧΊ’ςœρΝΩΘ§Ρ«Ο¥“ΜΕ®Ω…“‘±μ Ψ≥…œ¬ΟφΒΡ–Έ ΫΘΚ
Τδ÷–
«ΧΊ’ςœρΝΩvΕ‘”ΠΒΡΧΊ’ς÷ΒΘ§“ΜΗωΨΊ’σΒΡΧΊ’ςœρΝΩ±Υ¥Υ’ΐΫΜΓΘ
’β ±ΚρΈ Χβά¥ΝΥΘΚΈΣ ≤Ο¥“ΜΗωœρΝΩΚΆΨΊ’σœύ≥ΥΒΡΫαΙϊΚΆ“ΜΗω ΐΉ÷œύ≥ΥΒΡ–ßΙϊ“Μ―υΡΊΘΩ
“ρΈΣΨΊ’σAΚΆœρΝΩbœύ≥ΥΘ§ΨΆ «Ε‘œρΝΩvΫχ––ΝΥ“Μ¥ΈœΏ–‘ΒΡ±δΜΜΘ§–ΐΉΣΓΔά≠…λ»»ΓΘ»γΙϊΗΡ±δΜΜΒ»Φέ”Ύ“ΜΗω≥Θ λΒΡ±Ε ΐ±δΜΜΘ§Ρ«Ο¥ΨΆ“‘ΈΜ÷ΟΘ§Έ“Ο««σ»ΓΧΊ’ςœρΝΩΒΡ ±ΚρΘ§ΨΆ «ΈΣΝΥ«σΨΊ’σAΩ…“‘ ΙΒΟΡ«–©ΡΡ–©œρΝΩ÷ΜΖΔ…ζ…λΥθ±δΜΜΘ§≤ΜΖΔ…ζ–ΐΉΣ±δΜΜΓΘ
Έ“Ο«ά¥Ω¥ΧΊ’ς÷ΒΚΆΧΊ’ςœρΝΩΒΡΦΗΚΈ“β“ε
≤ΈΩΦΉ ΝœΘΚΜζΤς―ßœΑ÷–SVDΉήΫα (qq.com)
“ΜΗωΨΊ’σΤδ ΒΨΆ «“Μ¥ΈœΏ–‘±»Ρ«ΜΜΘ§“ρΈΣΨΊ’σ≥Υ“‘“ΜΗωœρΝΩΚσΒΟΒΫΒΡœρΝΩΘ§ΨΆœύΒ±”Ύ «ΫΪ’βΗωœρΝΩΫχ––ΝΥœΏ–‘±δΜΜΘ§±»ΖΫΥΒœ¬Οφ’βΗωΨΊ’σ

image.png
Ή‘ΦΚΩ…“‘≥Δ ‘“Μœ¬Θ§Τδ ΒΨΆ «»ΟxΖΫœρ±δ≥…‘≠ά¥ΒΡ3±ΕΘ§yΖΫœρ «‘≠ά¥ΒΡ1±ΕΘΚ

image.png
Υυ“‘ «’βΗω―υΉ”ΒΡΘΚ
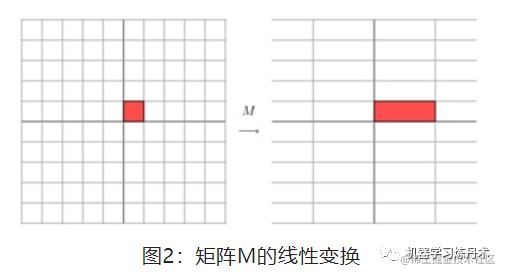
image.png
Ά§άμΘ§’β―υΒΡΨΊ’σ «“ΜΗωά≠…λ±δΜΜΘΚ
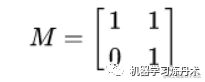
image.png
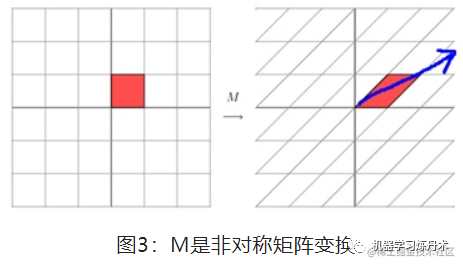
image.png
œ÷‘ΎΈ“Ο«÷ΣΒάΝΥΘ§ΨΊ’σΕ‘”Ύ“ΜΗωœρΝΩά¥ΥΒΘ§ΨΆ «“Μ÷÷œΏ–‘±δΜΜΓΘΧΊ’ς÷ΒΖ÷ΫβΨΆ «ΫΪΨΊ’σAΖ÷Ϋβ≥…œ¬ΟφΒΡ―υΉ”ΘΚ
- Q «ΨΊ’σAΒΡΧΊ’ςœρΝΩΉι≥…ΒΡΨΊ’σΘ§
«“ΜΗωΕ‘Ϋ«ΨΊ’σΘ§Ε‘Ϋ«œΏ…œΒΡ‘ΣΥΊΨΆ «ΧΊ’ς÷ΒΓΘΖ÷ΫβΒΡ’βΗω
ΨΊ’σ «“ΜΗωΕ‘Ϋ«ΨΊ’σΘ§άοΟφΒΡΧΊ’ς÷Β «¥”¥σΒΫ–Γ≈≈Ν–ΒΡΓΘ
- …œΟφΙΪ Ϋ‘θΟ¥ά¥ΒΡΡΊΘΩΤδ ΒΨΆ «¥”ΧΊ’ς÷ΒΒΡΕ®“εΒΟΒΫΒΡΓΘ
’Ι ΨΒΡ «ΒΞΗωΧΊ’ςœρΝΩΒΡ±δΜ·ΓΘΦΌ…ηΨΊ’σA «mxmΒΡΖΫ’κΓΘΡ«Ο¥vΨΆ «“ΜΗωmx1ΒΡΡ≥“ΜΗωΧΊ’ςœρΝΩΓΘ»γΙϊΈ“Ο«Ε‘Υυ”–ΒΡmΗωΧΊ’ςœρΝΩΕΦΉω’βΗω‘ΥΥψΘ§Ρ«Ο¥ΨΆΩ…“‘–¥≥…ΘΚ
’βάο–η“ΣΖ¥Ιΐά¥Θ§Ή‘ΦΚΨΌ“ΜΗωάΐΉ”ΨΆΩ…“‘ΖΔœ÷Θ§–η“ΣΖ¥Ιΐά¥ΓΘ
»ΜΚσΈ“Ο«Α―Ήσ±ΏΒΡV±δ≥…”“±ΏΒΡΩ…Ρφ–Έ ΫΨΆΩ…“‘ΝΥΓΘ
Τφ“λ÷ΒΖ÷Ϋβ
ΧΊ’ς÷ΒΖ÷Ϋβ÷ΜΡή’κΕ‘ΖΫ’κΘ§»γΙϊA «“ΜΗωΖ«ΖΫ’σΘ§”»Τδ «‘ΎPCAΒ±÷–Θ§―υ±ΨΒΡΧΊ’ς ΐΝΩΚΆ―υ±Ψ ΐΝΩ“ΜΑψΕΦ «≤ΜœύΆ§ΒΡΓΘ’β ±ΚρΨΆΈόΖ® Ι”ΟΧΊ’ς÷ΒΖ÷ΫβΒΡΖΫΖ®ά¥ΦΤΥψΧΊ’ςœρΝΩΓΘ
- SVDȧsingular value decomposition
Ε®“ε
Ε‘”Ύ»Έ“βΨΊ’σAΉή «¥φ‘Ύ“ΜΗωΤφ“λ÷ΒΖ÷ΫβΘΚ
ΦΌ…ηA «“ΜΗωmnΒΡΨΊ’σΘ§Ρ«Ο¥U «“ΜΗωmmΒΡΖ¬’φΘ§UΒΡ’ΐΫΜœρΝΩΘ®ΧΊ’ςœρΝΩΘ©±Μ≥ΤΈΣΉσΤφ“λœρΝΩΘ§
«“ΜΗωmnΒΡΨΊ’σΘ§ «“ΜΗωΕ‘Ϋ«ΨΊ’σΘ§Ε‘Ϋ«œΏ…œΒΡ‘ΣΥΊ≥ΤΈΣΤφ“λ÷ΒΓΘ
«“ΜΗωnnΒΡΨΊ’σΘ§άοΟφΒΡ’ΐΫΜœρΝΩ±Μ≥ΤΈΣ”“Τφ“λœρΝΩΓΘ
–η“ΣΉΔ“βΒΡ «ΘΚ
- ”κΧΊ’ς÷ΒΖ÷ΫβάύΥΤΘ§UΚΆVΕΦ «’ΐΫΜΨΊ’σΘ§“≤ΨΆ «άμΫβΈΣΧΊ’ςœρΝΩΤ¥≥…ΒΡΨΊ’σΘΜ
Ρ«Ο¥Έ“Ο«»γΚΈΦΤΥψΤφ“λ÷ΒΚΆΤφ“λœρΝΩΡΊΘΩΜΙΒΟΜΊΒΫΧΊ’ςœρΝΩΒΡΕ®“εΒ±÷–ΓΘ
’βάοΒΡvΨΆ «”“Τφ“λœρΝΩΘ§“≤ΨΆ «ΥΒ
ΨΆ «
Ηϋ”–»ΛΒΡ «ΘΚ
’βάοΒΡuΨΆ «ΉσΤφ“λœρΝΩΘ§“≤ΨΆ «ΥΒ
ΨΆ «
ΈΣ ≤Ο¥”–’β―υΒΡ–ßΙϊΡΊΘΩ
’βάο
Θ§“ρΈΣU «’ΐΫΜΨΊ’σΓΘ
Υυ“‘…œ÷ΛΟςΝΥ
ΒΡΧΊ’ςœρΝΩΘ§ΨΆ «Έ“Ο«ΒΡVΘ§ΨΊ’σVΨΆ «ATAΒΡΧΊ’ςœρΝΩΘ§Ρ«Ο¥
ΨΆ «ΨΊ’σVΒΡΧΊ’ς÷ΒΓΘ¥”…œΙΪ Ϋ÷–Ω…“‘Ω¥ΒΫΘ§Τφ“λ÷ΒΨΆ «ΧΊ’ς÷ΒΒΡ0.5¥ΈΖΫΓΘ
ΉήΫαΘΚœ÷‘ΎΈ“Ο«“―Ψ≠÷ΣΒά”ΟΤφ“λ÷ΒΖ÷ΫβSVDά¥¥Πάμ»ΈΚΈΒΡΨΊ’σΝΥΓΘ“≤ΨΆ «ΥΒΘ§»ΈΚΈΒΡΨΊ’σΕΦΩ…“‘±ΜΖ÷Ϋβ
ΒΡ–Έ ΫΓΘ
Ρ«Ο¥SVDΫΒΈ§Θ§ΨΆ «―Γ‘ώΉν¥σΒΡΦΗΗωΤφ“λ÷ΒΚΆΤφ“λœρΝΩά¥Οη ω ΐΨίΨΆΩ…“‘ΝΥΓΘ“ρΈΣΤφ“λ÷ΒΒΡœ¬ΫΒΥΌΕ»Ζ«≥ΘΩλΘ§Ω…ΡήΉν¥σΒΡ1%ΒΡΤφ“λ÷ΒΨΆ“―Ψ≠’ΦΨίΝΥ»Ϊ≤ΩΤφ“λ÷Β÷°ΚΆΒΡ99%“‘…œ
PCA
œ÷‘ΎΈ“Ο«ΝΥΫβΝΥΧΊ’ς÷ΒΖ÷ΫβΚΆΤφ“λ÷ΒΖ÷ΫβΓΘ
ΓΨΜυ”ΎΧΊ’ς÷ΒΖ÷Ϋβ–≠ΖΫ≤νΨΊ’σ Βœ÷PCAΓΩ
- »ΞΤΫΨυ÷ΒΘ§ΟΩ“ΜΗωΧΊ’ςΕΦ“Σ‘Λ¥ΠάμΘ§±δ≥…0Ψυ÷ΒΖ÷≤Φ
- ΦΤΥψ–≠ΖΫ≤νΨΊ’σΜρ’Ώ…ΔΕ»ΨΊ’σΘ§ΨΆ «
- ”ΟΧΊ’ς÷ΒΖ÷Ϋβ«σ–≠ΖΫ≤νΨΊ’σΒΡΧΊ’ς÷ΒΚΆΧΊ’ςœρΝΩ
- ―Γ‘ώΉν¥σΒΡkΗωΧΊ’ς÷ΒΒΡΧΊ’ςœρΝΩΘ§Ήι≥…“ΜΗωΧΊ’ςœρΝΩΨΊ’σPΘ§’βΗωΨΊ’σΒΡ–ΈΉ¥ΈΣmxkΒΡΘ§m «‘≠ά¥―υ±ΨΧΊ’ςΈ§Ε»Θ§“≤ «–≠ΖΫ≤νΨΊ’σΘ®ΖΫ’σΘ©ΒΡΈ§Ε»ΓΘ
- ΟΩ“ΜΗω ΐΨίΕΦΑϋΚ§mΗωΧΊ’ςΘ§ΩΑ≥Τ «1xmΒΡœρΝΩΘ§”κmxkΒΡΧΊ’ςœρΝΩΉω≥ΥΖ®ΨΆΩ…“‘ΒΟΒΫ1xkΒΡ―ΙΥθΧΊ’ςΓΘ
±Ψ÷ ΨΆ «―Γ‘ώk÷–Φ”»®ΖΫΑΗΘ§ΟΩ“ΜΗωΖΫΑΗΕΦ «Ε‘‘≠ά¥mΗωΧΊ’ςΫχ––œΏ–‘Φ”»®ΉιΚœΘ§Έ®“ΜΒΡœό÷ΤΨΆ «Φ”»®ΖΫΑΗ±Υ¥Υ’ΐΫΜΓΘ
ΓΨΜυ”ΎSVDΖ÷ΫβΒΡ–≠ΖΫ≤νΨΊ’σ Βœ÷PCAΓΩ Τδ ΒΝς≥ΧΚΆ…œΟφ «“Μ―υΒΡΘ§ΦΤΥψ–≠ΖΫ≤νΨΊ’σΘ§Ά®ΙΐSVDΦΤΥψΧΊ’ς÷ΒΚΆΧΊ’ςœρΝΩΘ®Τφ“λœρΝΩΘ©
«χ±π‘Ύ”ΎΘ§PCA‘ΎΧΊ’ς÷ΒΖ÷Ϋβ÷–Θ§–η“ΣΦΤΥψ≥ω–≠ΖΫ≤νΨΊ’σΒΡkΗωΉν¥σΧΊ’ςœρΝΩΓΘΦΤΥψ–≠ΖΫ≤νΨΊ’σΒΡ ±ΚρΤδ ΒΦΤΥψΝΩΖ«≥Θ¥σΘ§±»ΖΫΥΒ”–…œΆρΗω ΐΨίΘ§ΟΩΗω ΐΨί”–…œΆρΗωΧΊ’ςΓΘΦΌ…ηΕΦ «1w―υ±ΨΚΆ1wΧΊ’ςΘ§Ρ«Ο¥kxn”κnxkΝΫΗωΨΊ’σΫαΙϊΒΟΒΫ“ΜΗω10000x10000ΒΡ–≠ΖΫ≤νΨΊ’σΘ§’βΗωΨΊ’σΒΡΟΩ“ΜΗω‘ΣΥΊΕΦ–η“ΣΨ≠Ιΐ10000¥Έ≥ΥΖ®‘ΥΥψΘ§Υυ“‘–η“Σ1Άρ“Ύ¥ΈΒΡΦΤΥψΓΘ
SVDά¥ΉωΖ÷ΫβΒΡ ±ΚρΘ§SVDΒΡ Βœ÷ΥψΖ®”–“Μ–©Ω…“‘≤Μ«σ≥ω–≠ΖΫ≤νΨΊ’σΘ§‘Ύ≤Μ«σ
ΒΡ«ιΩωœ¬Θ§“≤Ω…“‘«σ≥ωΈ“Ο«ΒΡΉσΤφ“λΨΊ’σUΓΘ ΒΦ …œscikit-learnΒΡPCAΥψΖ®±≥ΚσΨΆ «”ΟSVD Βœ÷ΒΡΘ§Εχ≤Μ «ΧΊ’ς÷ΒΖ÷ΫβΓΘ
Ήσ”“Τφ“λΨΊ’σΕΦΩ…“‘ΉςΈΣΫΒΈ§ΒΡΨΊ’σ Ι”ΟΓΘΝΫ’ΏΖ÷±πΫΒΈ§―υ±ΨΨΊ’σΒΡΝΫΗωΈ§Ε»Θ§“ΜΗω «ΧΊ’ςΘ§“≤ΨΆ «Έ“Ο«≥Θ”ΟΒΡΉσΤφ“λΨΊ’σΘΜΝμ“ΜΗω «ΫΒΒΆ―υ±Ψ ΐΝΩΘ§ «”ΟΒΡ”“Τφ“λΨΊ’σΓΘ
python¥ζ¬κ
”ΟΧΊ’ς÷ΒΖ÷ΫβΒΡΖΫΖ®,Α―6Ηω―υ±Ψ2ΗωΧΊ’ςΉΣΜ·ΈΣ1ΗωΧΊ’ςΘΚ
##Python Βœ÷PCA
import numpy as np
def pca(X,k):#k is the components you want
#mean of each feature
n_samples, n_features = X.shape
mean=np.array([np.mean(X[:,i]) for i in range(n_features)])
#normalization
norm_X=X-mean
#scatter matrix
scatter_matrix=np.dot(np.transpose(norm_X),norm_X)
#Calculate the eigenvectors and eigenvalues
eig_val, eig_vec = np.linalg.eig(scatter_matrix)
eig_pairs = [(np.abs(eig_val[i]), eig_vec[:,i]) for i in range(n_features)]
# sort eig_vec based on eig_val from highest to lowest
eig_pairs.sort(reverse=True)
# select the top k eig_vec
feature=np.array([ele[1] for ele in eig_pairs[:k]])
#get new data
data=np.dot(norm_X,np.transpose(feature))
return data
X = np.array([[-1, 1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
print(pca(X,1))
ΫαΙϊΘΚ

”Οscikit-learnΒΡΖΫΖ®ΘΚ
from sklearn.decomposition import PCA
import numpy as np
X = np.array([[-1,1],[-2,-1],[-3,-2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components=1)
pca.fit(X)
print(pca.transform(X))
ΫαΙϊΘΚ

image.png
±ΨΈΡΖ÷œμΉ‘ ΜζΤς―ßœΑΝΕΒΛ θ ΈΔ–≈ΙΪ÷ΎΚ≈Θ§«ΑΆυ≤ιΩ¥
»γ”–«÷»®Θ§«κΝΣœΒ cloudcommunity@tencent.com …Ψ≥ΐΓΘ
±ΨΈΡ≤Έ”κ?ΧΎ―Ε‘ΤΉ‘ΟΫΧεΖ÷œμΦΤΜ°? Θ§ΜΕ”≠»»Α°–¥ΉςΒΡΡψ“ΜΤπ≤Έ”κΘΓ