不背锅运维:享一个具有高可用性和可伸缩性的ELK架构实战案例


写在开篇
本文只分享各个链路环节的配置对接,关于环境的搭建,比如kafka集群、es集群的搭建等请自行完成。还有,业务应用的日志可以是你的其他业务日志,希望本文可以起到抛砖引用的效果。
测试架构
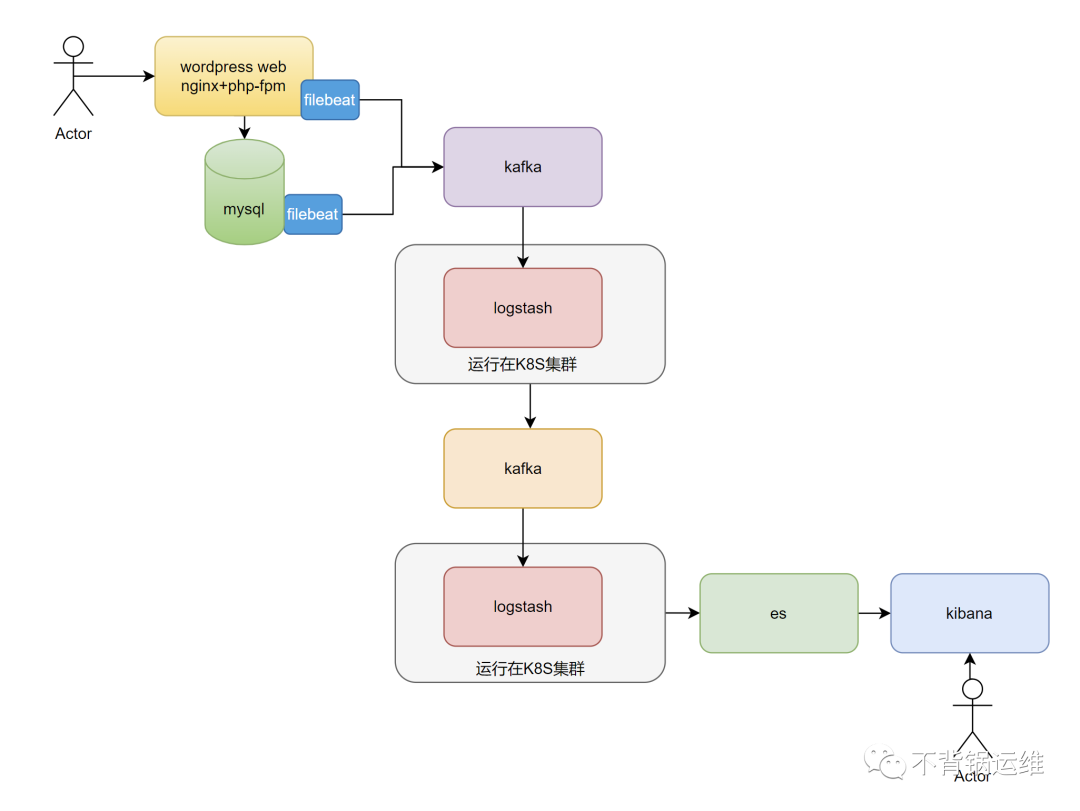
这个架构描述了一个将来自不同数据源的数据通过 Kafka 中转,然后使用 Logstash 将数据从 Kafka 中读取并处理,最终将处理后的数据再写回到 Kafka 中,以供 Elasticsearch 进行存储和分析的过程。通过使用 Kafka 和 Logstash,可以将来自不同数据源的数据进行集中管理和处理,并将数据以可靠的方式发送到 Elasticsearch 进行存储和分析。这种架构具有高可用性和可伸缩性,并且可以在处理大量数据时提供良好的性能。同时,由于 Logstash 可以从多种来源读取数据,因此可以适应各种数据集成方案的需求。
注意:kafka集群a接收来自filebeat的消息,并由logstash进行消费。kafka集群b接收来自logstash的消息,并由es或者其他业务进行消费。
机器规划
主机名 | 角色 | IP | 备注 |
|---|---|---|---|
srv-mysql8 | mysql+filebeat | 192.168.11.161 | 业务数据库,filebeat读取mysql的日志 |
wordpress | nginx+filebeat | 192.168.11.170 | 业务web应用,filebeat读取nginx的日志 |
kafka01 | kafka节点 | 192.168.11.247 | kafka集群a,broker.id=1 |
kafka02 | kafka节点 | 192.168.11.248 | kafka集群a,broker.id=2 |
kafka03 | kafka节点 | 192.168.11.249 | kafka集群a,broker.id=3 |
logstash01 | logstash | 192.168.11.250 | 第1套logstash |
kafka-b01 | kafka节点 | 192.168.11.40 | kafka集群b,broker.id=10 |
kafka-b02 | kafka节点 | 192.168.11.41 | kafka集群b,broker.id=20 |
kafka-b03 | kafka节点 | 192.168.11.42 | kafka集群b,broker.id=30 |
logstash02 | logstash | 192.168.11.133 | 第2套logstash |
es-node01 | es节点(主) | 192.168.11.243 | es集群 |
es-node02 | es节点 | 192.168.11.244 | es集群 |
es-node03 | es节点 | 192.168.11.245 | es集群 |
kibana-svr | kibana | 192.168.11.246 |
注意:在同一个网段中,两个 Kafka 集群必须要使用不同的 broker.id,否则会导致冲突。因为 broker.id 是 Kafka 集群中唯一标识一个 Broker 的参数,同一个网段中不能存在两个具有相同 broker.id 的 Broker。
实战开撸
创建kafka主题
在kafka集群a中创建主题
bin/kafka-topics.sh?--create?--zookeeper?192.168.11.247:2181?--replication-factor?2?--partitions?3?--topic?wordpress-nginx-log安装和配置filebeat
在安装了wordpress web的业务主机上进行安装
- 下载和安装
wget?https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.6.2-x86_64.rpm
rpm?-ivh?filebeat-8.6.2-x86_64.rpm?
filebeat?version- 配置filebeat读取日志 打开和编辑/etc/filebeat/filebeat.yml配置文件,添加以下内容,使其读取Nginx访问日志文件:
filebeat.inputs:
-?type:?log
??enabled:?true
??paths:
????-?/usr/local/nginx/logs/wordpress.access.log
??fields:
????log_type:?wordpress_access
output.kafka:
??hosts:?["192.168.11.247:9092",192.168.11.248:9092,192.168.11.249:9092]
??topic:?"wordpress-nginx-log"- 启动filebeat
systemctl?start?filebeat配置logstash01,消费kafka集群a的消息
在logstash01主机上配置logstash,使其能够消费kafka集群a中主题为"wordpress-nginx-log"的消息。
- 安装kafka插件
bin/logstash-plugin?install?logstash-input-kafka注意:如果安装的时候提示:ERROR: Installation aborted, plugin 'logstash-input-kafka' is already provided by 'logstash-integration-kafka',这个错误提示'logstash-input-kafka'插件已经被Logstash集成插件'logstash-integration-kafka'提供了,可以直接使用 logstash-integration-kafka 插件消费 Kafka 消息
- 在 Logstash 的配置文件中使用 kafka 输入插件
配置之前,先说明下我的nginx日志自定义的格式:
log_format my_log_format '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';创建和编辑配置文件config/wordpress-logstash.conf,添加以下内容:
input {
kafka {
bootstrap_servers => "192.168.11.247:9092,192.168.11.248:9092,192.168.11.249:9092"
topics => ["wordpress-nginx-log"]
}
}
filter {
# 解析Nginx日志行
grok {
match => { "message" => '%{IPORHOST:clientip} - %{USERNAME:remote_user} [%{HTTPDATE:timestamp}] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:body_bytes_sent} "%{DATA:http_referer}" "%{DATA:user_agent}"' }
}
# 将时间戳转换为ISO 8601格式
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "@timestamp"
}
}
output {
stdout { codec => rubydebug }
}- 启动 Logstash
bin/logstash?-f?config/wordpress-logstash.conf?在这里,先让其输出到屏幕,看看是否正常。确保logstash消费kafka集群a的消息没问题、以及确保过滤没问题可以正常打印到屏幕之后,就可以继续下面的步骤了。
配置logstash01,过滤后的消息写入到kafka集群b
继续在logstash01上配置,从kafka集群a中消费数据并过滤,处理后写入到kafka集群b中的主题wordpress-web-log。
- 在kafka集群b中创建主题
bin/kafka-topics.sh?--create?--zookeeper?192.168.11.40:2181?--replication-factor?2?--partitions?3?--topic?wordpress-web-log- 编辑配置文件config/wordpress-logstash.conf,配置output
input {
kafka {
bootstrap_servers => "192.168.11.247:9092,192.168.11.248:9092,192.168.11.249:9092"
topics => ["wordpress-nginx-log"]
}
}
filter {
# 解析Nginx日志行
grok {
match => { "message" => '%{IPORHOST:clientip} - %{USERNAME:remote_user} [%{HTTPDATE:timestamp}] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:status} %{NUMBER:body_bytes_sent} "%{DATA:http_referer}" "%{DATA:user_agent}"' }
}
# 将时间戳转换为ISO 8601格式
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "@timestamp"
}
}
output {
kafka {
bootstrap_servers => "192.168.11.40:9092,192.168.11.41:9092,192.168.11.42:9092"
topic_id => "wordpress-web-log"
}
}编辑完成后,记得重启logstash哦。
- 临时启动一个消费者,验证从kafka集群b消费主题wordpress-web-log的消息
bin/kafka-console-consumer.sh?--bootstrap-server?192.168.11.40:9092?--topic?wordpress-web-log如果能正常消费,读取到的消息打印到控制台上,就可以继续下面的步骤了。
配置logstash02,消费kafka集群a的消息
在logstash02主机上配置logstash,使其能够消费kafka集群b中主题为"wordpress-web-log"的消息,并写入到ES集群
打开并编辑config/logstash.conf,添加以下内容:
input?{
??kafka?{
????bootstrap_servers?=>?"192.168.11.40:9092,192.168.11.41:9092,192.168.11.42:9092"
????topics?=>?["wordpress-web-log"]
??}
}
output?{
??elasticsearch?{
????hosts?=>?["http://192.168.11.243:9200","http://192.168.11.244:9200","http://192.168.11.245:9200"]
????index?=>?"wordpress-web-log-%{+YYYY.MM.dd}"
??}
}写在最后
所有环节对接完毕,看看最终成果。
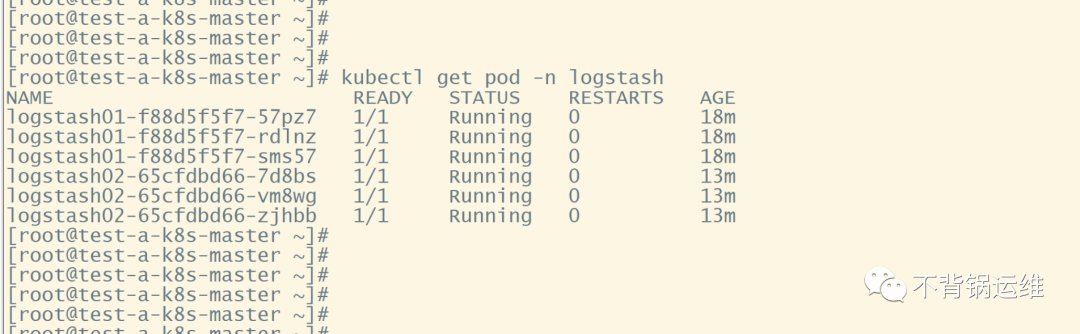
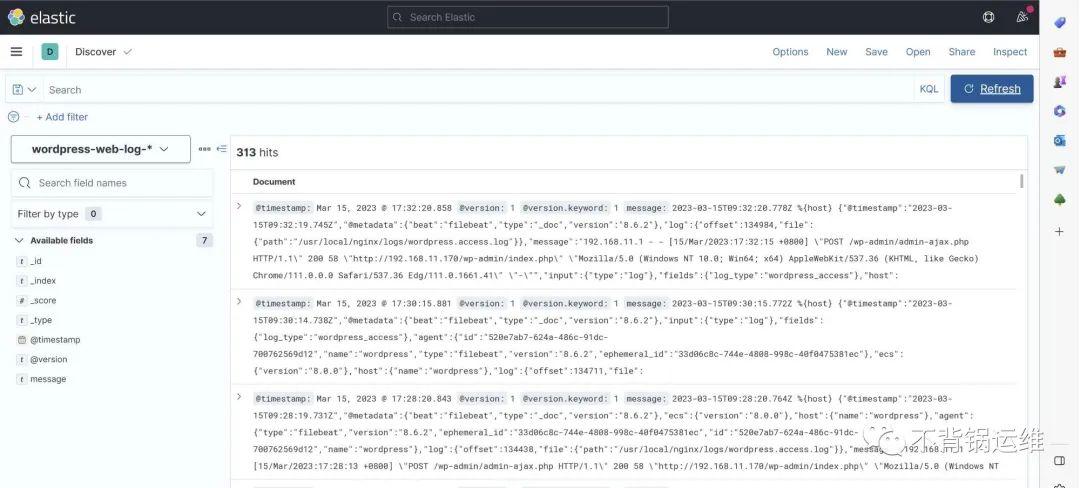
关于如何将logstash部署到K8S,感兴趣?请保持高度关注,有空了再分享。
本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。