QueryҪЧ¶ОЧФ¶ЁТеОДұҫПаЛЖ¶Иҙт·Ц№«КҪ
ФӯҙҙQueryҪЧ¶ОЧФ¶ЁТеОДұҫПаЛЖ¶Иҙт·Ц№«КҪ
Фӯҙҙ
ұіҫ°
ОТГЗЦӘөА, ФЪК№УГө№ЕЕЛчТэЧцХЩ»ШКұ, »бУҰУГОДұҫПаЛЖ¶И№«КҪҙт·Ц, ұИИзLuceneД¬ИПөДbm25.

Чў: ДҝЗ°LuceneКөПЦөДКұәт°С·ЦЧУАпөД(k1+1)ІОКэИҘөфБЛ, ИҘөф(k1+1)І»У°ПмЕЕРт.
* LUCENE-8563: BM25 scores don't include the (k1+1) factor in their numerator
anymore. This doesn't affect ordering as this is a constant factor which is
the same for every document. (Luca Cavanna via Adrien Grand)ОДұҫПаЛЖРФ·ЦКэіэБЛbm25, »№УРЦ®З°LuceneК№УГөДtfidfөИ.
ХвР©ОДұҫПаЛЖРФҙт·Ц№«КҪ, ұҫЦК¶јКЗ¶ФПВБРМШХчөДЧФ¶ЁТеЧйәП:
- idf // ДжҙКЖө. LuceneКөПЦОӘlog(1 + (docCount - docFreq + 0.5)/(docFreq + 0.5)), docFreqОӘ°ьә¬ёГtermөДОДөөЧЬКэ, docCountОӘ°ьә¬ёГЧЦ¶ОЧЬОДөөКэ
- boost // queryҪЧ¶ОөДјУИЁ
- tf // term frequency
- dl // ОДөөіӨ¶И. LuceneКөПЦОӘОДөөЦРtermsөДdistincet count
- avgdl // ФЪөұЗ°ЛчТэ(solr/esОӘөұЗ°shard)ЦР, ОДөөёГЧЦ¶ОөДЖҪҫщdl
bm25әНtfidfФЪҙ«НіУпБПЙПҫӯ№эҙуБҝІвКФІўұнПЦУЕТм, ө«УРКұ¶ФОТГЗМШКвөДТөОсіЎҫ°ОҙұШККәП. ұИИзЛөbm25НЁ№эdlІОКэіН·ЈіӨ¶ИұИҪПіӨөДОДұҫ, ¶шФЪУРР©іЎҫ°ПВ, ұИҪПіӨөДОДұҫ·ҙ¶шҙъұнОДөөЦКБҝұИҪПёЯ.
ТтҙЛ, ОТГЗ»бУРПлФЪІ»Н¬ТөОсіЎҫ°ЧФ¶ЁТеОДұҫПаЛЖРФөГ·ЦөДРиЗу, ФЪLuceneЦРҝЙТФНЁ№эЧФ¶ЁТеSimilarityөД·ҪКҪЧФ¶ЁТеОДұҫПаЛЖРФөГ·Ц, ө«КЗИз№ыОТГЗРҙЛАТ»ёцЧФ¶ЁТ幫КҪ, »бУРПВБРОКМв:
- ГҝҙОПлөчХы№«КҪ, ОТГЗ¶јРиТӘРЮёДҙъВлЦШРВЙППЯ.
- Г»·ЁФЪІ»Н¬ТөОсіЎҫ°ЦРК№УГІ»Н¬өДҙт·Ц№«КҪ.
ЧЫЙП, ОТГЗҫц¶ЁФЪQueryҪЧ¶ОЦ§іЦ¶ҜМ¬ЧФ¶ЁТ幫КҪ.
ЙијЖЛјВ·
ЙијЖЛјВ·әЬјтөҘ, УГESУп·ЁАҙІыКц, ұИИзОТГЗЦ®З°¶ЁТеТ»ёцmatchІйСҜХвСщРҙ:
{
"match": {
"TITLE": {
"query": "hello world"
}
}
}ХвЦЦРҙ·Ёҙт·ЦКұәтД¬ИПУГөДКЗЧЦ¶О¶ФУҰөДОДұҫПаЛЖРФ№«КҪ(Д¬ИПbm25).
ОТГЗНЁ№эМнјУТ»ёцІОКэ, Ц§іЦФЪqueryҪЧ¶О¶ҜМ¬өчХыҙт·Ц№«КҪ:
// К№УГtfidf
{
"match": {
"TITLE": {
"query": "hello world",
"similarity": {
"name": "tfidf"
}
}
}
}
// К№УГbm25
{
"match": {
"TITLE": {
"query": "hello world",
"similarity": {
"name": "bm25"
}
}
}
}
// К№УГЧФ¶ЁТ幫КҪ
{
"match": {
"TITLE": {
"query": "hello world",
"operator": "and",
"similarity": {
"name": "custom",
"expression": "idf*boost*tf/(tf+k*((1-b)+b*dl/avgdl))",
"params": {
"k": 1.2,
"b": 0.75
}
}
}
}
}ЖдЦР, name="tfidf", "bm25"КЗФӨЙиөДҙт·Ц№«КҪ, ¶ФУҰLuceneөДКөПЦ, ¶ш"custom"КЗОТГЗЧФјәКөПЦөД, Ц§іЦНЁ№эЧФ¶ЁТеexpression¶ҜМ¬Рҙ№«КҪ, »№ҝЙТФЧФ¶ЁТеІОКэ.
КҫАэЦРОТГЗНЁ№эЧФ¶ЁТеөД·ҪКҪЧФјәКөПЦБЛТ»ёцәНbm25өИР§өД№«КҪ.
expressionҝЙТФРҙИОәО№«КҪ, ФЪ№«КҪЦРҝЙТФЦұҪУТэУГПВБРФӨЙиұдБҝ, ФЪФЛРРКұ»бМж»»ОӘКөјКЦө:
- idf
- boost
- tf
- dl
- avgdl
әЛРДКөПЦ
ТӘКөПЦөДР§№ыЗеіюБЛ, ҪУПВАҙЛөЛөФхГҙКөПЦөД.
КЧПИОТГЗТӘЦӘөА, LuceneКЗФхГҙ¶БөҪД¬ИПөДbm25 similarityөД:
Т»ёцmatch query»бұ»·ЦҪвОӘТ»ёцbool query, МЧЧЕ¶аёцterm query.
ұИИз:
{
"match": {
"TITLE": {
"query": "hello world",
"operator": "and"
}
}
}КөјКЙПҪвОціЙLucene QueryКЗХвСщөДВЯјӯҪб№№:
BoolQuery
must:
TermQuery(TITLE:hello)
TermQuery(TITLE:world)ПаЛЖРФҙт·Ц№«КҪКЗФЪTermQueryАпУҰУГөД:
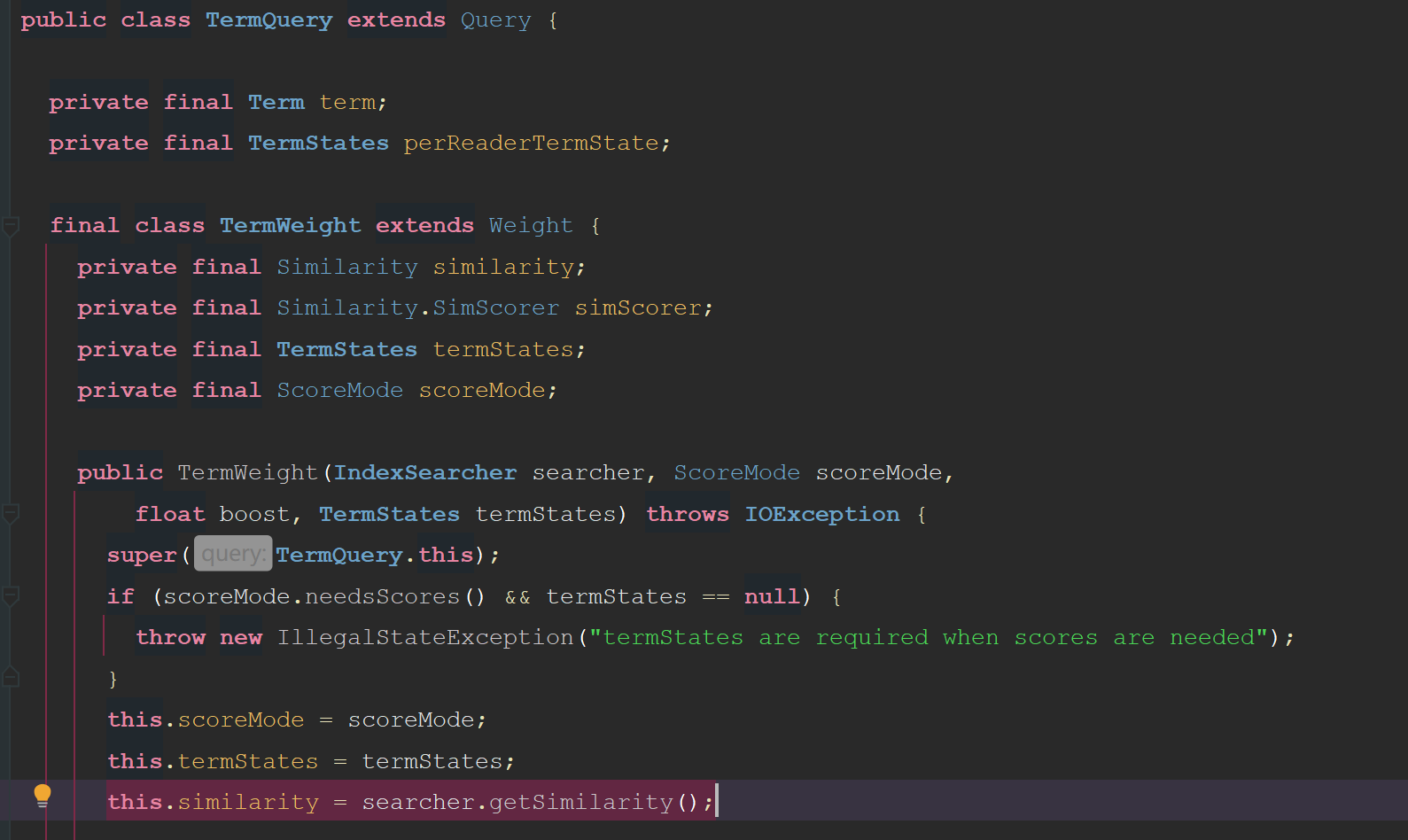
ЧўТвНјЦРёЯББөДҙъВл, ИЭТЧҝҙіц, LuceneөДsimilarityКЗ¶ЁТеөҪIndexSearcherЙПөД, ОӘЙ¶»бХвГҙЙијЖДШ? КөјКЙПКЗТтОӘSimilarityХвёцАа, ФЪLuceneЛчТэҪЧ¶ОТІУГөҪБЛ, ТтОӘSimilarityҙт·ЦКұУГөҪөДdl, КөјККЗРиТӘФЪЛчТэҪЧ¶ОҙжөҪЛчТэОДјюөД, ¶шLuceneФЪКөПЦөДКұәтОӘБЛА©Х№РФ, КЗФКРнУГ»§НЁ№эcomputeNorm(state)·Ҫ·ЁЧФ¶ЁТеdlөДјЖЛг·Ҫ·ЁөД:
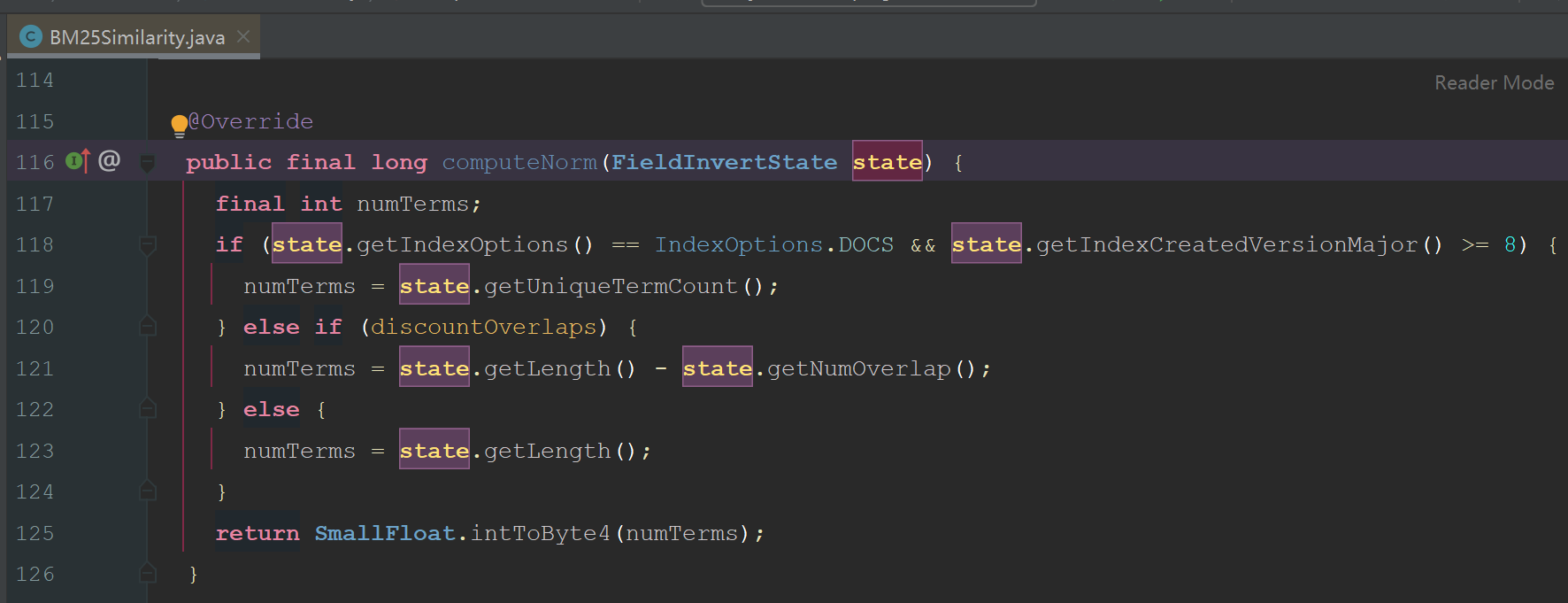
І»№эДҝЗ°°ьАЁBM25Similarity, TFIDFSimilarityФЪДЪөДЛщУРLucene Similarity, јёәх¶јКЗПаН¬өДКөПЦ, ЛщТФИз№ыОТГЗІ»ҝјВЗЧФ¶ЁТеdlөДјЖЛг·Ҫ·Ё, КөјКЙПSimilarityКЗНкИ«ҝЙТФФЪQueryҪЧ¶ОЛжТвРЮёДөД.
ҙУTermQueryөДҙъВлАҙҝҙ, TermQueryРҙЛАБЛТӘҙУIndexSearcher»сөГSimilarityАа, ТтҙЛОӘБЛҝЙТФФЪQueryҪЧ¶ОИОТвРЮёД, ОТГЗРиТӘЧФјәКөПЦТ»ёцTermQuery, ЦчТӘҫНКЗјУТ»ёцSimilarityІОКэ:
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.lucene.search;
import org.apache.lucene.index.IndexReaderContext;
import org.apache.lucene.index.LeafReader;
import org.apache.lucene.index.LeafReaderContext;
import org.apache.lucene.index.PostingsEnum;
import org.apache.lucene.index.ReaderUtil;
import org.apache.lucene.index.Term;
import org.apache.lucene.index.TermState;
import org.apache.lucene.index.TermStates;
import org.apache.lucene.index.TermsEnum;
import org.apache.lucene.search.similarities.Similarity;
import java.io.IOException;
import java.util.Objects;
import java.util.Set;
/**
* A Query that matches documents containing a term. This may be combined with
* other terms with a {@link BooleanQuery}.
* РЮёДLuceneФӯЙъөДTermQuery, ФКРнФЪQueryҪЧ¶Оҙ«ИлЧФ¶ЁТеsimilarity.
* РиТӘЧўТвКЗ, luceneФЪЛчТэҪЧ¶ОТСөчУГЧЦ¶О¶ФУҰsimilarityөДcomputeNorm()·Ҫ·ЁјЖЛгБЛnormІўҙўҙжЖрАҙ.
* ЛдИ»ОТГЗҝЙТФЧФ¶ЁТеQueryҪЧ¶Оҙ«ИлөДsimilarity, ө«КЗЧоәГТӘұЈЦӨQueryҪЧ¶ОК№УГөДsimilarityәНЧЦ¶ОұҫЙнөДsimilarityөДcomputeNorm()·Ҫ·ЁКЗТ»ЦВөД.
* Т»°гАҙЛө¶јУГbm25өДcomputeNorm()ҫНРРБЛ.
*/
public class TermQueryWithSimilarity extends Query {
private final Term term;
private final TermStates perReaderTermState;
// private final String similarity;
private final Similarity similarity;
final class TermWeight extends Weight {
private final Similarity similarity;
private final Similarity.SimScorer simScorer;
private final TermStates termStates;
private final ScoreMode scoreMode;
public TermWeight(IndexSearcher searcher, ScoreMode scoreMode,
float boost, TermStates termStates, Similarity similarity) throws IOException {
super(TermQueryWithSimilarity.this);
if (scoreMode.needsScores() && termStates == null) {
throw new IllegalStateException("termStates are required when scores are needed");
}
this.scoreMode = scoreMode;
this.termStates = termStates;
this.similarity = similarity;
final CollectionStatistics collectionStats;
final TermStatistics termStats;
if (scoreMode.needsScores()) {
collectionStats = searcher.collectionStatistics(term.field());
termStats = termStates.docFreq() > 0 ? searcher.termStatistics(term, termStates.docFreq(), termStates.totalTermFreq()) : null;
} else {
// we do not need the actual stats, use fake stats with docFreq=maxDoc=ttf=1
collectionStats = new CollectionStatistics(term.field(), 1, 1, 1, 1);
termStats = new TermStatistics(term.bytes(), 1, 1);
}
if (termStats == null) {
this.simScorer = null; // term doesn't exist in any segment, we won't use similarity at all
} else {
this.simScorer = similarity.scorer(boost, collectionStats, termStats);
}
}
@Override
public void extractTerms(Set<Term> terms) {
terms.add(getTerm());
}
@Override
public Matches matches(LeafReaderContext context, int doc) throws IOException {
TermsEnum te = getTermsEnum(context);
if (te == null) {
return null;
}
if (context.reader().terms(term.field()).hasPositions() == false) {
return super.matches(context, doc);
}
return MatchesUtils.forField(term.field(), () -> {
PostingsEnum pe = te.postings(null, PostingsEnum.OFFSETS);
if (pe.advance(doc) != doc) {
return null;
}
return new TermMatchesIterator(getQuery(), pe);
});
}
@Override
public String toString() {
return "weight(" + TermQueryWithSimilarity.this + ")";
}
@Override
public Scorer scorer(LeafReaderContext context) throws IOException {
assert termStates == null || termStates.wasBuiltFor(ReaderUtil.getTopLevelContext(context)) : "The top-reader used to create Weight is not the same as the current reader's top-reader (" + ReaderUtil.getTopLevelContext(context);
;
final TermsEnum termsEnum = getTermsEnum(context);
if (termsEnum == null) {
return null;
}
LeafSimScorer scorer = new LeafSimScorer(simScorer, context.reader(), term.field(), scoreMode.needsScores());
if (scoreMode == ScoreMode.TOP_SCORES) {
return new TermScorer(this, termsEnum.impacts(PostingsEnum.FREQS), scorer);
} else {
return new TermScorer(this, termsEnum.postings(null, scoreMode.needsScores() ? PostingsEnum.FREQS : PostingsEnum.NONE), scorer);
}
}
@Override
public boolean isCacheable(LeafReaderContext ctx) {
return true;
}
/**
* Returns a {@link TermsEnum} positioned at this weights Term or null if
* the term does not exist in the given context
*/
private TermsEnum getTermsEnum(LeafReaderContext context) throws IOException {
assert termStates != null;
assert termStates.wasBuiltFor(ReaderUtil.getTopLevelContext(context)) :
"The top-reader used to create Weight is not the same as the current reader's top-reader (" + ReaderUtil.getTopLevelContext(context);
final TermState state = termStates.get(context);
if (state == null) { // term is not present in that reader
assert termNotInReader(context.reader(), term) : "no termstate found but term exists in reader term=" + term;
return null;
}
final TermsEnum termsEnum = context.reader().terms(term.field()).iterator();
termsEnum.seekExact(term.bytes(), state);
return termsEnum;
}
private boolean termNotInReader(LeafReader reader, Term term) throws IOException {
// only called from assert
// System.out.println("TQ.termNotInReader reader=" + reader + " term=" +
// field + ":" + bytes.utf8ToString());
return reader.docFreq(term) == 0;
}
@Override
public Explanation explain(LeafReaderContext context, int doc) throws IOException {
TermScorer scorer = (TermScorer) scorer(context);
if (scorer != null) {
int newDoc = scorer.iterator().advance(doc);
if (newDoc == doc) {
float freq = scorer.freq();
LeafSimScorer docScorer = new LeafSimScorer(simScorer, context.reader(), term.field(), true);
Explanation freqExplanation = Explanation.match(freq, "freq, occurrences of term within document");
Explanation scoreExplanation = docScorer.explain(doc, freqExplanation);
return Explanation.match(
scoreExplanation.getValue(),
"weight(" + getQuery() + " in " + doc + ") ["
+ similarity.getClass().getSimpleName() + "], result of:",
scoreExplanation);
}
}
return Explanation.noMatch("no matching term");
}
}
/**
* Constructs a query for the term <code>t</code>.
*/
public TermQueryWithSimilarity(Term t, Similarity similarity) {
term = Objects.requireNonNull(t);
perReaderTermState = null;
this.similarity = similarity;
}
/**
* Expert: constructs a TermQuery that will use the provided docFreq instead
* of looking up the docFreq against the searcher.
*/
public TermQueryWithSimilarity(Term t, TermStates states, Similarity similarity) {
assert states != null;
term = Objects.requireNonNull(t);
perReaderTermState = Objects.requireNonNull(states);
this.similarity = similarity;
}
/**
* Returns the term of this query.
*/
public Term getTerm() {
return term;
}
@Override
public Weight createWeight(IndexSearcher searcher, ScoreMode scoreMode, float boost) throws IOException {
final IndexReaderContext context = searcher.getTopReaderContext();
final TermStates termState;
if (perReaderTermState == null
|| perReaderTermState.wasBuiltFor(context) == false) {
termState = TermStates.build(context, term, scoreMode.needsScores());
} else {
// PRTS was pre-build for this IS
termState = this.perReaderTermState;
}
return new TermWeight(searcher, scoreMode, boost, termState, similarity);
}
@Override
public void visit(QueryVisitor visitor) {
if (visitor.acceptField(term.field())) {
visitor.consumeTerms(this, term);
}
}
/**
* Prints a user-readable version of this query.
*/
@Override
public String toString(String field) {
StringBuilder buffer = new StringBuilder();
if (!term.field().equals(field)) {
buffer.append(term.field());
buffer.append(":");
}
buffer.append(term.text());
return buffer.toString();
}
/**
* Returns the {@link TermStates} passed to the constructor, or null if it was not passed.
*
* @lucene.experimental
*/
public TermStates getTermStates() {
return perReaderTermState;
}
/**
* Returns true iff <code>other</code> is equal to <code>this</code>.
*/
@Override
public boolean equals(Object other) {
return sameClassAs(other) &&
term.equals(((TermQueryWithSimilarity) other).term);
}
@Override
public int hashCode() {
return classHash() ^ term.hashCode();
}
}ОТГЗЧФ¶ЁТеөДTermQueryWithSimilarityҙуІҝ·ЦҙъВл¶јКЗЦұҪУҙУTermQueryёҙЦЖөД, ЦчТӘҫНКЗМнјУБЛsimilarityКфРФІўҙУ№№Фм·Ҫ·Ёҙ«Ил, К№УГөДКұәтІ»ФЩК№УГIndexSearcherАпГжөДsimilarityКфРФ¶шКЗК№УГОТГЗҙ«ИлөД.
И»әуОТГЗРЮёДmatch queryөДКөПЦ, ФЪРиТӘЙъіЙTermQueryөДөШ·Ҫ, К№УГПВГжөДКөПЦ(ІОКэөДҪвОц№эіМВФ, match queryҪвОцЙъіЙbool queryөД№эіМВФ):
public static Query getTermQueryWithSimilarity(String field, String text, Similarity similarity) {
if (similarity == null) {
return new TermQuery(new Term(field, text));
}
return new TermQueryWithSimilarity(new Term(field, text), similarity);
}НЁ№эЧФ¶ЁТеөДTermQueryWithSimilarity, ФКРнОТГЗФЪQueryҪЧ¶ОЧФ¶ЁТеSimilarityБЛ.
ДЗГҙcustom SimilarityФхГҙКөПЦДШ? ЖдКөәЛРДОКМвҫНКЗ, ФхГҙ»сИЎөҪРиТӘөДtf, idfөИРиТӘөДМШХчЦөДШ?
ПВГжёшіцБЛТ»ёцКҫАэ:
package com.zhaopin.solr.search.similarity.custom;
import com.zhaopin.solr.util.Exp4jUtil;
import org.apache.lucene.index.FieldInvertState;
import org.apache.lucene.search.CollectionStatistics;
import org.apache.lucene.search.Explanation;
import org.apache.lucene.search.TermStatistics;
import org.apache.lucene.search.similarities.BM25Similarity;
import org.apache.lucene.search.similarities.Similarity;
import org.apache.lucene.util.SmallFloat;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Created by jiabao.gao on 2023-04-17.
*/
public class CustomSimilarity extends Similarity {
private static final Similarity BM25_SIM = new BM25Similarity();
private final String expression;
private final Map<String, Float> params;
public CustomSimilarity(String expression, Map<String, Float> params) {
this.expression = expression;
this.params = params;
}
/**
* Implemented as <code>log(1 + (docCount - docFreq + 0.5)/(docFreq + 0.5))</code>.
*/
protected float idf(long docFreq, long docCount) {
return (float) Math.log(1 + (docCount - docFreq + 0.5D) / (docFreq + 0.5D));
}
/**
* The default implementation computes the average as <code>sumTotalTermFreq / docCount</code>
*/
protected float avgFieldLength(CollectionStatistics collectionStats) {
return (float) (collectionStats.sumTotalTermFreq() / (double) collectionStats.docCount());
}
/**
* Cache of decoded bytes.
*/
private static final float[] LENGTH_TABLE = new float[256];
static {
for (int i = 0; i < 256; i++) {
LENGTH_TABLE[i] = SmallFloat.byte4ToInt((byte) i);
}
}
@Override
public long computeNorm(FieldInvertState state) {
return BM25_SIM.computeNorm(state);
}
/**
* Computes a score factor for a simple term and returns an explanation
* for that score factor.
*
* <p>
* The default implementation uses:
*
* <pre class="prettyprint">
* idf(docFreq, docCount);
* </pre>
* <p>
* Note that {@link CollectionStatistics#docCount()} is used instead of
* {@link org.apache.lucene.index.IndexReader#numDocs() IndexReader#numDocs()} because also
* {@link TermStatistics#docFreq()} is used, and when the latter
* is inaccurate, so is {@link CollectionStatistics#docCount()}, and in the same direction.
* In addition, {@link CollectionStatistics#docCount()} does not skew when fields are sparse.
*
* @param collectionStats collection-level statistics
* @param termStats term-level statistics for the term
* @return an Explain object that includes both an idf score factor
* and an explanation for the term.
*/
public Explanation idfExplain(CollectionStatistics collectionStats, TermStatistics termStats) {
final long df = termStats.docFreq();
final long docCount = collectionStats.docCount();
final float idf = idf(df, docCount);
return Explanation.match(idf, "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
Explanation.match(df, "n, number of documents containing term"),
Explanation.match(docCount, "N, total number of documents with field"));
}
/**
* Computes a score factor for a phrase.
*
* <p>
* The default implementation sums the idf factor for
* each term in the phrase.
*
* @param collectionStats collection-level statistics
* @param termStats term-level statistics for the terms in the phrase
* @return an Explain object that includes both an idf
* score factor for the phrase and an explanation
* for each term.
*/
public Explanation idfExplain(CollectionStatistics collectionStats, TermStatistics termStats[]) {
double idf = 0d; // sum into a double before casting into a float
List<Explanation> details = new ArrayList<>();
for (final TermStatistics stat : termStats) {
Explanation idfExplain = idfExplain(collectionStats, stat);
details.add(idfExplain);
idf += idfExplain.getValue().floatValue();
}
return Explanation.match((float) idf, "idf, sum of:", details);
}
@Override
public SimScorer scorer(float boost, CollectionStatistics collectionStats, TermStatistics... termStats) {
Explanation idf = termStats.length == 1 ? idfExplain(collectionStats, termStats[0]) : idfExplain(collectionStats, termStats);
float avgdl = avgFieldLength(collectionStats);
return new CustomScorer(expression, params, boost, idf, avgdl);
}
private static class CustomScorer extends SimScorer {
private final String expression;
private final Map<String, Float> params;
private final float boost;
private final Explanation idf;
private final float avgdl;
public CustomScorer(String expression, Map<String, Float> params, float boost, Explanation idf, float avgdl) {
this.expression = expression;
// ТтОӘОТГЗҙт·ЦКұ»бРЮёДІОКэmap, ёҙЦЖТ»·Э, І»ТӘУ°ПмФӯКјҙ«ИлөД.
this.params = new HashMap<>(params);
this.boost = boost;
this.idf = idf;
this.avgdl = avgdl;
}
@Override
public float score(float freq, long encodedNorm) {
final float idf = this.idf.getValue().floatValue();
final float dl = LENGTH_TABLE[((byte) encodedNorm) & 0xFF];
params.put("idf", idf);
params.put("boost", boost);
params.put("tf", freq);
params.put("dl", dl);
params.put("avgdl", avgdl);
return Exp4jUtil.eval(expression, params);
}
}
}ҝЙТФҝҙіц, ОТГЗФЪҙт·ЦөДҪЧ¶О, әЬИЭТЧөДДГөҪБЛЛщУРРиТӘөДКфРФөДЦө:

ЧоәуөДExp4jUtil, КЗОТГЗЧФјә·вЧ°өДЦҙРРұнҙпКҪөДҝв, »щУЪexp4jПоДҝ: https://github.com/fasseg/exp4j.
АаЛЖөДҝвУҰёГУРәЬ¶а, exp4jҝП¶ЁІ»КЗЧоәГөД, К№УГДЗЦЦФӨұаТл¶ҜМ¬ЙъіЙjavaЧЦҪЪВлөДЦҙРРҝвРФДЬУҰёГёьәГ. ТтОӘ№«ЛҫДЪТСҫӯУРПоДҝФЪУГexp4jБЛ, ОТҫНУГБЛХвёц.
UPDATE: ҫӯ№эРФДЬІвКФ, ·ўПЦexp4jІ»ДЬВъЧгРФДЬТӘЗу.
іўКФ»»УГ: paralithic.
ЧЬҪб
ХыМеАҙЛөКөПЦІ»ДС, ЦШөгҫНКЗТӘГч°ЧLuceneТ»Р©АаөД№ҰДЬУл№ШПө:
- SimilarityКЗУГУЪ¶ЁТеОДұҫПаЛЖРФҙт·ЦөД.
- SimilarityД¬ИПКЗУлIndexSearcher°у¶ЁөД, ТтОӘSimilarityЦРөДcomputeNorm(state)»бФЪЛчТэҪЧ¶ОөчУГ. Из№ыОТГЗІ»ЧФ¶ЁТеcomputeNorm·Ҫ·Ё, КөјКЙПSimilarityІ»РиТӘУлIndexSearcher°у¶Ё, ФЪQueryҪЧ¶О¶ҜМ¬Цё¶ЁТІКЗҝЙТФөД.
- TermQueryКЗФЪІйСҜКұSimilarityөДК№УГХЯ, ЛьРҙЛАБЛҙУIndexSearcher»сИЎSimilarity, Из№ыТӘРЮёДД¬ИПРРОӘ, Ц»ДЬЧФјәcopyИ»әуҙҙҪЁТ»ёцРВөДTermQuery.
ФӯҙҙЙщГчЈәұҫОДПөЧчХЯКЪИЁМЪС¶ФЖҝӘ·ўХЯЙзЗш·ўұнЈ¬ОҙҫӯРнҝЙЈ¬І»өГЧӘФШЎЈ
ИзУРЗЦИЁЈ¬ЗлБӘПө cloudcommunity@tencent.com ЙҫіэЎЈ
ФӯҙҙЙщГчЈәұҫОДПөЧчХЯКЪИЁМЪС¶ФЖҝӘ·ўХЯЙзЗш·ўұнЈ¬ОҙҫӯРнҝЙЈ¬І»өГЧӘФШЎЈ
ИзУРЗЦИЁЈ¬ЗлБӘПө cloudcommunity@tencent.com ЙҫіэЎЈ