快速落地基于“AIGC+数字人”的数字化内容生产
快速落地基于“AIGC+数字人”的数字化内容生产

谁不想有一个可爱的数字人形象呢?在日常的工作和娱乐中,越来越多的数字人虚拟形象与大家见面,他们可以是主播,也可以是语音助手,还可以是你自己的虚拟宠物。只有更快更精准的生成数字人,才能让数字人更加普及,普通消费者才能更多地接触到数字人。LiveVideoStackCon 2022北京站邀请到了张瑞全老师为我们分享美摄科技的数字人技术。
文/张瑞全
编辑/LiveVideoStack
大家好,我是来自美摄科技研发中心的高级AI算法专家张瑞全。今天分享的主题是美摄科技关于快速落地基于“AIGC+数字人”的数字化内容生产的整体方案。
-01-
整体概括

美摄科技产品主要分为AI数字人、视音频处理SDK、AI智能处理、汽车及智能硬件方案、云端/PC端视频处理方案和开发及设计服务六个部分。

美摄的技术已经在超过千余款实际产品中落地,尤其针对大量的手机厂商和大型互联网客户,面向多款超千万级的DAU应用,美摄的SDK技术对大量的硬件和系统进行适配,保障各类场景下兼容性的同时,提供高质量的服务。

实时语音数字人是基于语音和文字实时驱动的高精度数字人,主要用于数字客服、车载形象和APP助手等场景中。虚拟主播则更多的应用于新闻播报、直播助手和虚拟讲解等场景中。

-02-
数字人形象生成
数字人形象的三维渲染是数字人领域核心内容。美摄科技自研的三维图像渲染技术拥有强大的渲染能力、多端互通、高效率处理、体积小巧、快速拓展和制作方便六个特点,可以为数字人制作提供非常强大的辅助作用。
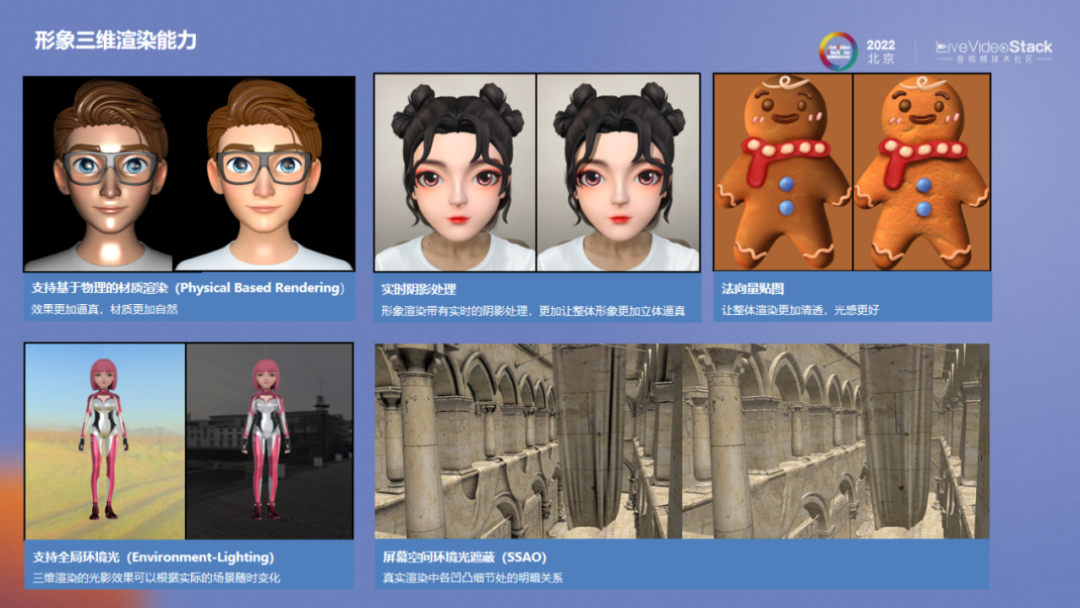
目前美摄科技支持支持基于物理的材质渲染、实时阴影处理、法向量贴图、全局环境光和屏幕空间环境光遮蔽,为各种环境下的数字人提供全面且逼真的渲染能力。为了增加可玩性和用途,可以在数字人身上添加不同的配饰等。目前美摄科技的渲染引擎可以很好地支持辅助道具和数字人动作的同步,让数字形象更加逼真。

要实现实时语音输出,就需要数字人拥有唇音同步能力。美摄科技基于AI训练建立了一套独特的唇音分析算法,可以实现自然生动的形象展现。通过对输入的语音进行轻量化AI分析,获取实际人物的面部表情,再将AI算法输出的结果与语音内容结合,驱动数字人模型,实现实时的三维唇音同步效果。美摄AI唇音同步技术具有高效、无时延、过度顺滑自然、适配多种语音系统等特点。

基于自研的Morphing技术,美摄渲染引擎支持多达54种人脸基础表情。这些基础表情相互组合,构成了拟真的数字人面部系统,几乎可以囊括所有的人脸表情,为数字人模型生动的表情展现奠定基础。左边5张图是通过基础的表情融合出的一些复杂面部动作。中间是一个实时驱动的样例,同时也携带了头发的物理效果。
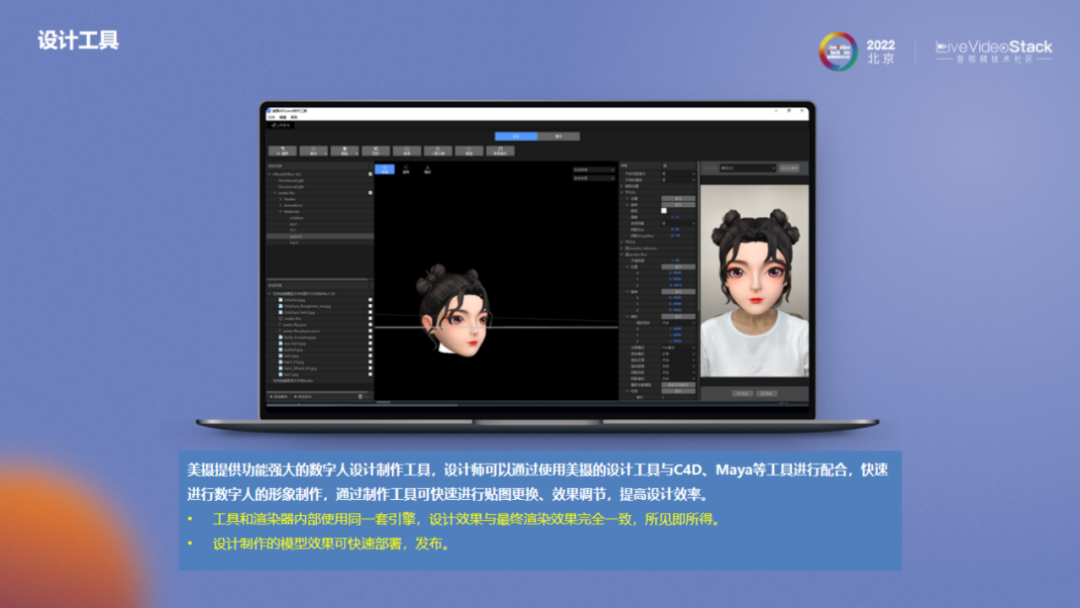
同时我们也提供了非常全面的数字人设计工具,设计师可以将其与C4D、Maya等工具配合,快速进行贴图更换、效果调节,实现高效设计。其中,美摄自研的数字人设计工具与渲染器内部使用同一套引擎,设计效果与最终渲染效果完全一致,所见即所得。设计制作出的模型效果可快速部署发布。
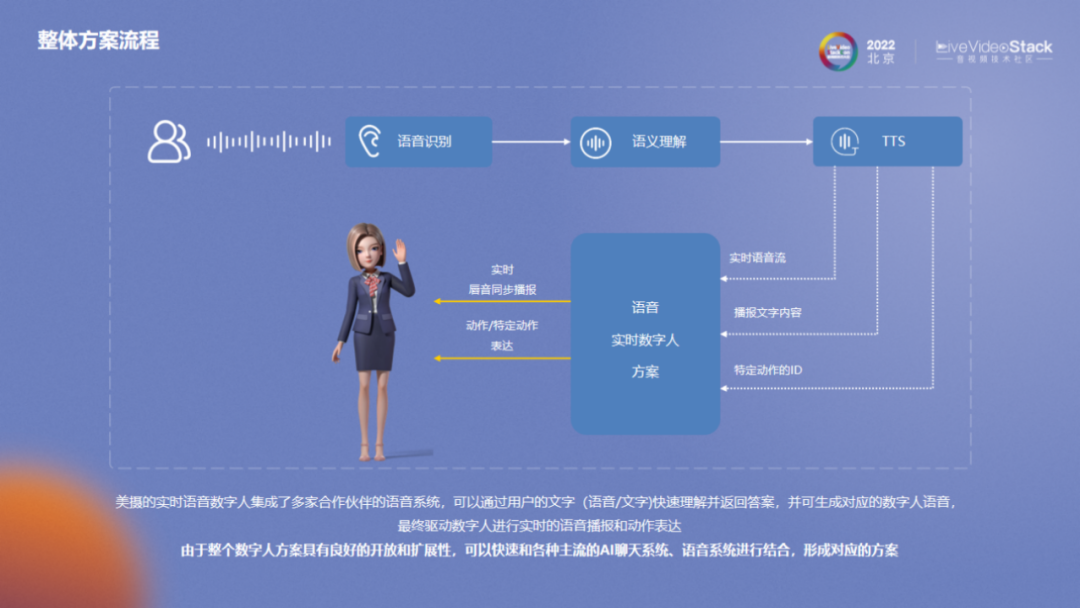
这张图是数字人的一套基本流程。美摄实时语音数字人集成了多家合作伙伴的语音系统,可以快速理解用户输入的文字信息并返回答案,并生成对应的数字人语音,驱动数字人进行实时语音播报和动作表达。整套数字人方案具有良好的开放性和可拓展性,能够快速与各种主流的AI聊天系统、语音系统进行结合,形成对应的方案。

一些用户希望生成的数字人更加贴合自己的形象,对此我们也提供了形象自动生成的方案。用户只需提供一张照片,系统将提取特征生成对应的数字人形象。在此基础上,我们提供人脸属性检测+自动形象生成的算法,根据检测分析的结果自动添加配饰,形成用户专属的虚拟形象。目前已支持性别、年龄、眼型、发型等多种人物属性分析。
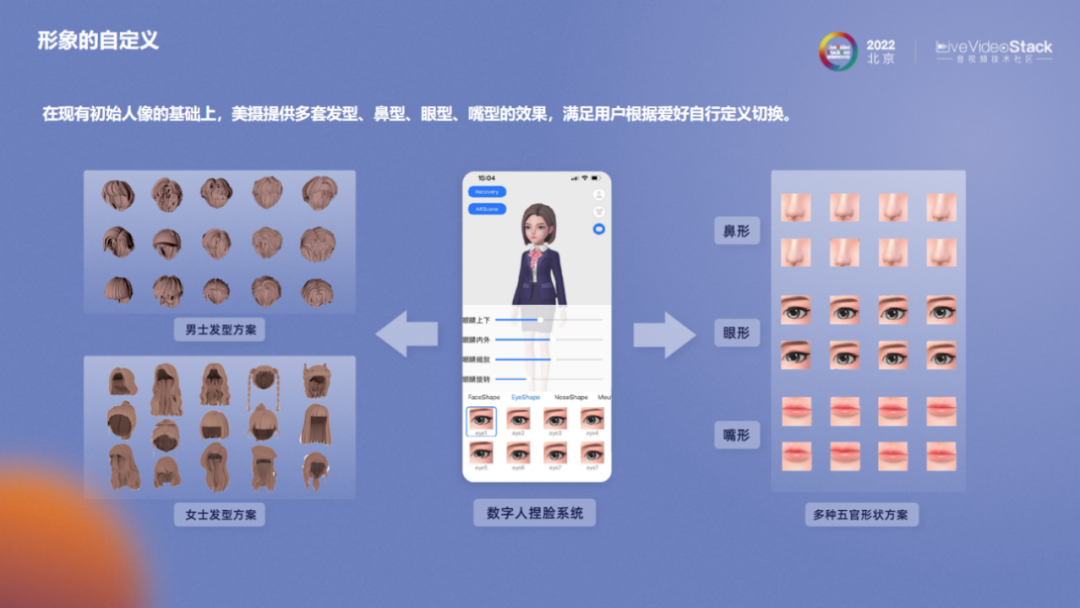
除了自动生成形象外,用户还可以在生成的形象基础上修改预先提供的可修改元素,自定义数字人形象,满足个性化需求。

为应对运营成长需求,如本土化适配,节日、热点等,美摄科技提供了可自定义的配饰。根据基础属性,通过捏脸换装可延展出不同的形象。
-03-
AIGC+数字人

虚拟视频合成技术是指通过综合利用计算机视觉、图像处理和深度学习等技术,实现虚拟视频的生成,包含语音驱动、动作驱动和换脸三个关键技术。语音驱动,利用语音去驱动口型和面部表情,生成讲话视频;动作驱动,基于源视频输入的动作和口型、表情等,驱动目标视频人物做出相同的动作、表情和口型;换脸,将目标视频中的人脸换成某个指定的形象,并且保持目标视频中人物的动作、表情、口型不变。

这张图展示了表情和口型预测的基本逻辑。使用语音特征提取算法对语音特征进行提取,基于特征进行口型参数的预测。随后根据口型参数进行3D面部渲染,并与真实人脸拟合,生成最终的渲染图。
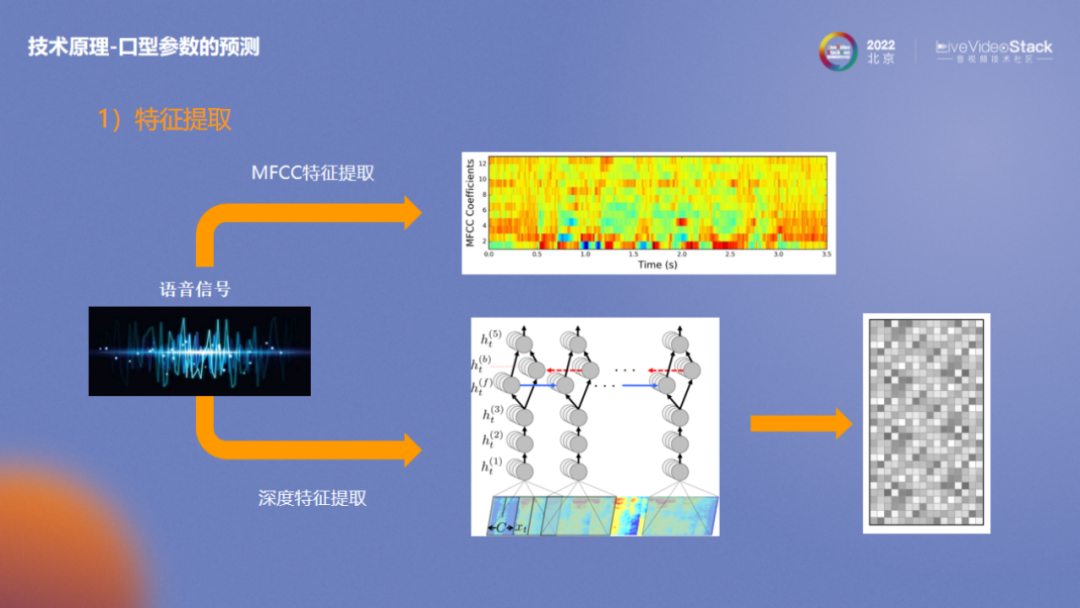
特征提取目前常用的算法有两种,一种是MFCC特征提取,另一种是深度特征提取。目前美摄科技推出了自研的综合算法和对应的特征提取算法。
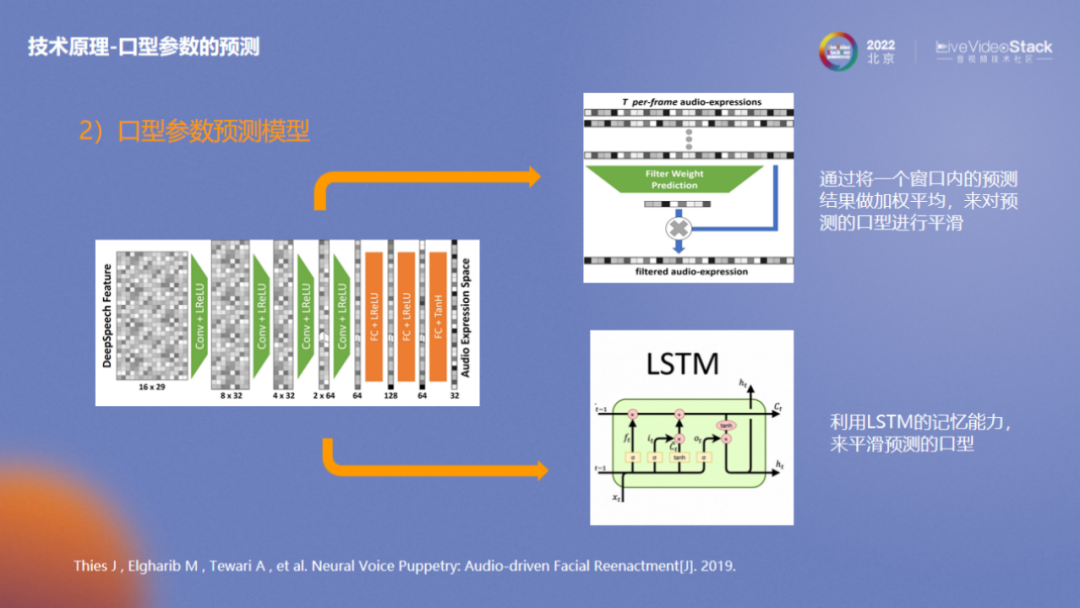
口型预测使用深度学习算法,初步生成当前语音对应的口型参数。为了使帧与帧之间的口型变化更加平滑,我们采用了两种方法:一种是将一个窗口内的预测结果做加权平均,来对预测的口型进行平滑;另一种是利用LSTM的记忆能力,来平滑预测口型。

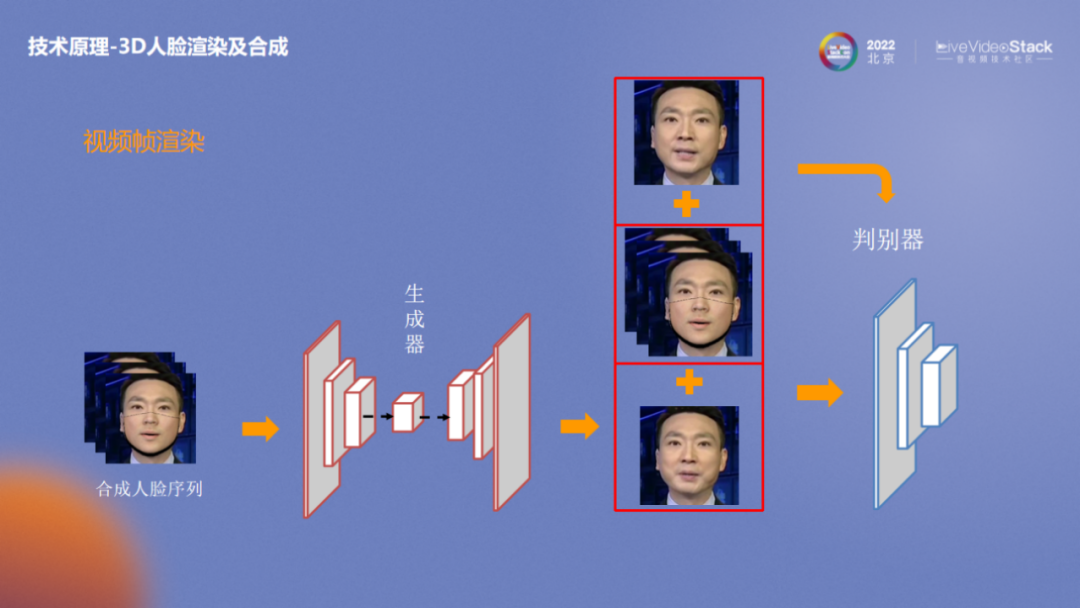
在讲话过程中,当口型发生变化时人脸的表情和肌肉等都会发生对应的变化。为了使表情更加贴合口型,我们对整个人脸的参数进行了预测。基于预测的人脸参数,通过渲染引擎,对当前人脸进行拟合,渲染得出一套人脸参数对应的人脸表情片。最后基于渲染出的3D人脸表情以及视频真正对应的人脸和mask眼模,利用GAN网络完成最终渲染。
考虑到客户和用户多样化的使用场景,美摄科技提供了三种不同的形式,让大家快速生成自己想要的数字人形象——照片自动生成形象、视频自动生成形象以及GLB模型自动生成形象。
图片生成数字人形象方案是基于照片快速生成需要的语音播报数字人。用户只需要上传一张人物照,根据照片和录入的文本产生对应的播报视频。
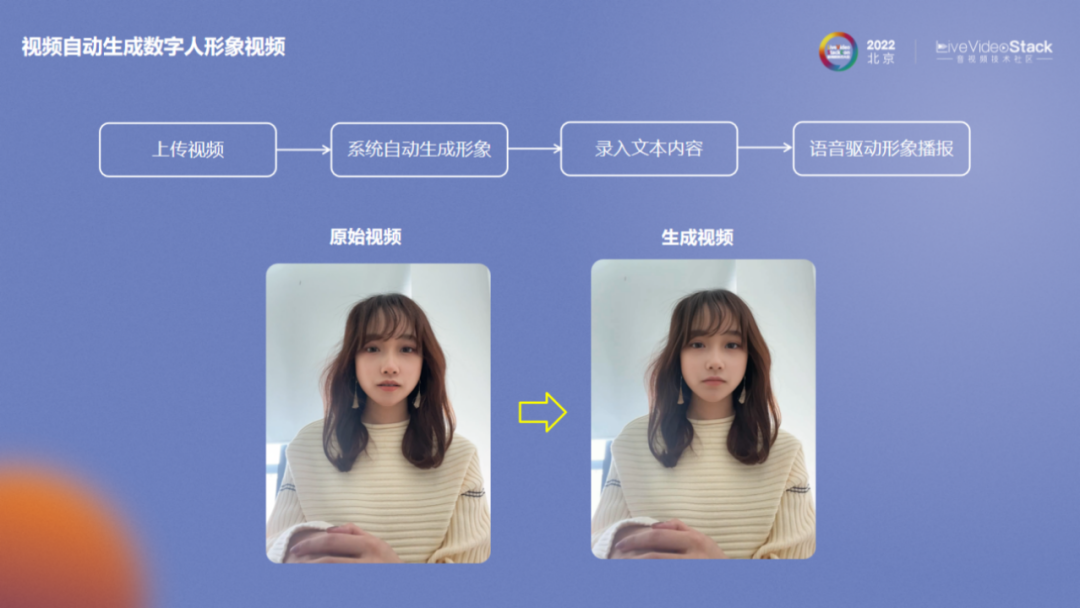
上图为视频自动生成数字人形象方案。用户可以上传一段视频,系统会将视频中人物的口型替换成想要的口型,同时保持原来视频中的动作和表情,生成播报形象。

美摄科技还支持基于传统3D模型GLB文件快速生成数字人。GLB文件是以图形语言传输格式保存的3D模型,它以二进制格式存储有关3D模型的信息,包括节点层级、摄像机、材质、动画和网格。以GLB生成数字人形象时,可以将其转换为美摄自研的3D文件格式“.ARSCENE”,转换后的效果包可以通过美摄SDK在不同的平台上实时渲染驱动。
ChatGPT最近非常火,美摄科技也将ChatGPT的混合语义理解能力和美摄已有的语音交互系统相结合,利用ChatGPT对语义的理解和回答,生成交互式数字人。用户只需输入一段语音或文字,利用ChatGPT对于语音或文字进行理解,对返回的答案进行语音播报。该方案更多用于大屏、车载、APP数字人等产品中。
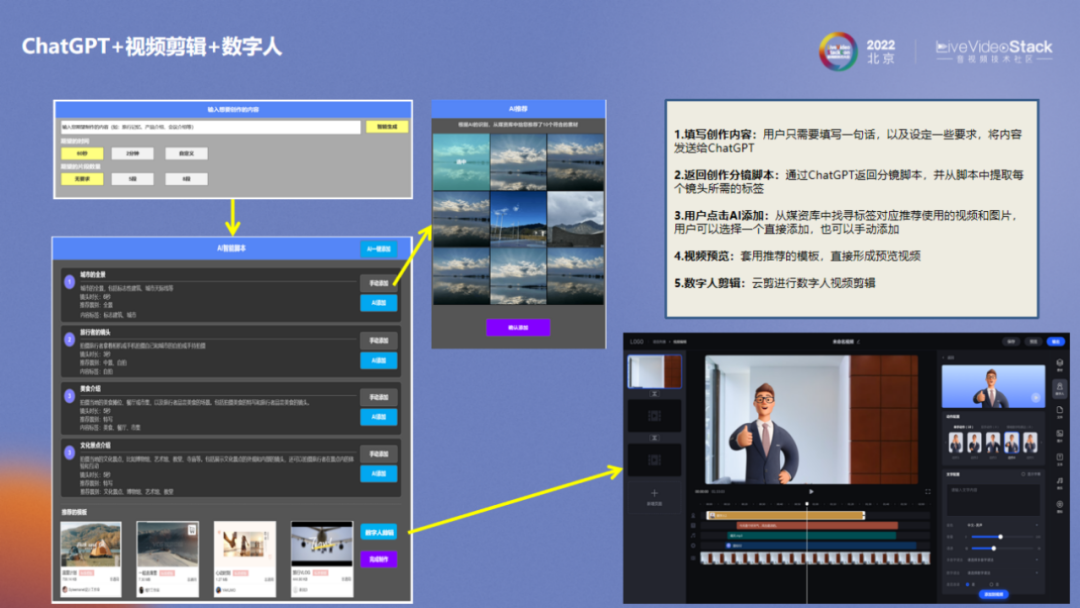
此外,我们还尝试了将ChatGPT与视频剪辑和数字人结合。用户只需填写一句话,设定好要求,系统就可以通过ChatGPT返回分镜脚本,并从中提取所需标签,由系统从媒资库中智能寻找对应的图像和视频资料。用户可以选择推荐素材,一键套用模板,直接形成预览视频,极大提高视频创作效率。另外我们也提供云剪技术,客户可以借助云剪对数字人视频进行进一步包装编辑。

LiveVideoStackCon 2023上海讲师招募中
LiveVideoStackCon是每个人的舞台,如果你在团队、公司中独当一面,在某一领域或技术拥有多年实践,并热衷于技术交流,欢迎申请成为LiveVideoStackCon的讲师。请提交演讲内容至邮箱:speaker@livevideostack.com。
本文分享自 LiveVideoStack 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与?腾讯云自媒体分享计划? ,欢迎热爱写作的你一起参与!