【建议收藏】Flink watermark分析实战
【建议收藏】Flink watermark分析实战

Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算 flink中提供了时间窗的相关算子计算区域时间内的数据 本次分享基于flink 1.14 此次分享内容中,api演示与旧版略有不同,概念并无不同 本次分享需要对流式数据处理计算有一定的了解
概念篇
Flink时间语义概念简介
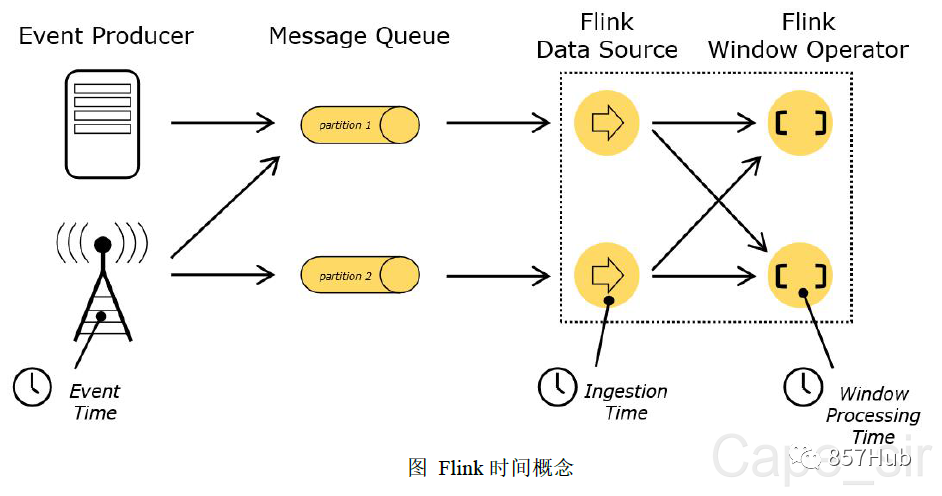
- 在flink的流式处理中,会涉及到时间的不同概念
- Processing Time 处理时间
- Event Time 事件时间
- Ingestion Time 注入时间
- Processing Time 处理时间
每一个执行基于时间操作的算子的本地系统时间,与机器相关
- Event Time 事件时间
事件发生的时间,通常由数据中的某个字段进行提供。
- Ingestion Time 注入时间
数据进入flink的事件
时间语义
- 就1.14版本而言,根据时间推进和时间判断的不同标准,一共由两种时间语义
- 以process time为依据:处理时间语义
- 以event time为依据:事件时间语义
对于事件时间的重要性和应用场景众所周知
需求和问题
需求
当前时间13:10,计算[13:00,13:10)分钟内订单数量/活跃用户数量
已知
flink中提供了时间窗的相关算子计算区域时间内的数据.
问题
由于网络波动或者网络传输的时间消耗, 一条由13:09分产生的数据,在13:11分才进入计算逻辑, 那么是否要将此数据计入到计算结果中? 在分布式运算中,不同节点的运算速度不同, 时间窗口先接收到一个并发中发送的13:10:00:000的数据, 时间窗口后接收到一个并发中发送的13:09:59:999的数据, 那么是否要将后接收到的这条数据计入到计算结果中?
分享者回答
如果是以事件时间进行处理的话,应当计入计算结果 如果是以处理时间进行处理的话,可以不计入计算结果 flink1.14不使用注入时间
再次提问
在业务场景中,我们很多需求都是要使用事件时间来作为依据的, 我想要按照时间事件来完成这个需求, 并且将迟到的数据也纳入到计算结果中, 应该如何解决?
问题总结
使用EventTime所要面对的问题
- 数据延迟
- 网络延迟
- 性能延迟
- ...
- 乱序
- 数据源数据相对于时间本身就无序
- 分布式场景下本身有序的数据也难以保持被读取时有序
- ...
分享者回答
如果使用类似于hive、doris、clinkhous之类的olap数据仓库, 我们可以等待到一个合适的时间(数据完全到达之后)再进行排序/计算, 而在flink中,提供了一个叫做watermark的机制来完成这个需求,应对这些问题。
watermark
背景
在流式数据中,虽然数据本身是按照时间顺序向下游推送的, 但在网络环境、分布式等因素下, 导致到达时间窗中的顺序并不是按照原本发送的顺序。有时数据发送的本身就不是按照严格的事件时间进行推送的
什么是watermark
以前我对watermark了解不够深的时候,我以为watermark是flink的时间等待机制, 后来我才知道,watermark是flink的事件时间推进机制,事件时间等待机制,只是他的一部分。
- watermark是解决数据乱序到达的,也可以理解为解决数据延迟到达,
- watermark在解决上述问题时,要结合flink的window(时间窗)机制,
- flink中的window(时间窗)是由watermark来触发的,这就意味着窗口触发时,数据中timeStamp<=watermark的,均已到达时间窗
watermark 事件时间推进机制
- 特点
- watermark本身也会是上游向下游发送数据时,附带的一个记录
- watermark必须是单调递增的,保证任务的时间一直在往前推进,不可后退
- watermark由数据中的时间戳来更新
watermark的生命周期
env.getConfig().setAutoWatermarkInterval(200)//(默认值200ms)
如果要禁用watermark机制,可以通过设置watermark生成频率来实现
env.getConfig().setAutoWatermarkInterval(0)//(默认值200ms)
AssignerWithPeriodicWatermarks (已过期)周期性生成watermark
AssignerWithPunctuatedWatermarks(已过期) 按照指定标记性事件生成watermark
watermark的更新机制
当flink开启watermark时,在所有的并发中的数据首先经过watermark管理, source算子每200ms从数据中获取一次时间戳,并更新自己的maxTimeStamp,并广播到下游 下游的算子拿到数据时,并不会根据数中时间进行更新watermark,而是根据上游发送过来的数据中携带的maxTimeStamp来更新自身watermark的值
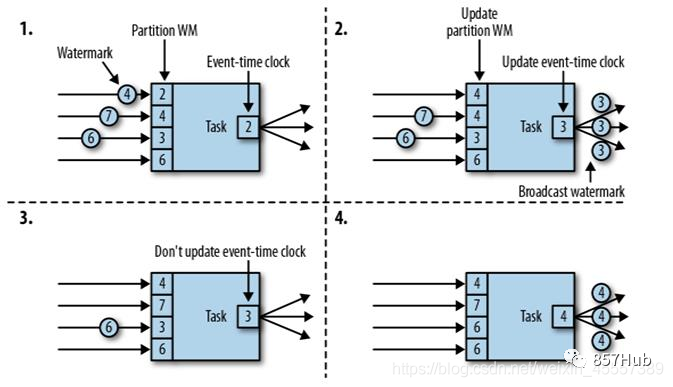
而是根据watermark广播到下游的maxTimeStamp值进行触发和结束,计算, 下游每200ms对比各个并发发送的maxTimeStamp,并根据最小值,刷新自身的maxTimeStamp并广播到下游 当上游有多个watermark发来的maxTimeStamp值,下游更新自身maxTimeStamp时取最小值 以最小值为基准,较大值到达时可以分发到他应该到的时间分桶中, 如果收到超出时间窗之外的未来数据,会创建此数据应有的时间窗,并开始缓存,时间窗(桶)的数量时没有限制的 如果以最大值为基准,会导致时间窗提前结束,maxTimeStamp较小的被抛弃掉
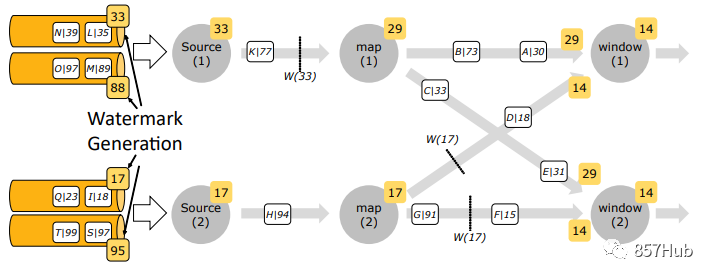
问题/需求解决
watermark是如何解决我们讨论之处提出的问题的呢? 我们也是时候上代码了!!!
完整的watermark使用代码
WatermarkStrategy<Bean> beanWatermarkStrategy = WatermarkStrategy
.forGenerator(new WatermarkGeneratorSupplier<Bean>() {
@Override
public WatermarkGenerator<Bean> createWatermarkGenerator(Context context) {
return new WatermarkGenerator<Bean>() {
/** 最大时间戳. */
private long maxTimestamp;
/** 水印生成的最大无序度 */
private final long outOfOrdernessMillis = 0;
//watermark比较器
@Override
public void onEvent(Bean event, long eventTimestamp, WatermarkOutput output) {
maxTimestamp = Math.max(maxTimestamp, eventTimestamp);
}
//watermark生成和发送
@Override
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
};
}
})
// .noWatermarks() //创建完全不生成水印的水印策略。这在执行纯处理基于时间的流处理的场景中可能很有用。
// .forMonotonousTimestamps() //紧跟最大时间时间,完全不容忍乱序
// .<Bean>forBoundedOutOfOrderness(Duration.ofMillis(0)) //允许乱序的生成策略 最大时间时间-容错时间
.withIdleness(Duration.ofSeconds(5)) //当某一并发迟迟没有数据进来时,多长时间发送一次watermark值
.withTimestampAssigner(new SerializableTimestampAssigner<Bean>() {
@Override
public long extractTimestamp(Bean element, long recordTimestamp) {
return element.getEventTime();
}
})//watermark提取策略(从数据中)
小延迟 - watermark推后机制 - BoundedOutOfOrderness策略
- BoundedOutOfOrderness策略
用wartermark容错,减慢时间的推进,在迟到数据到达时,让下游认为他还没有迟到
说句人话,实际上就是用已经获取到的时间戳-允许迟到的时间=watermark值
- 样例
.<Bean>forBoundedOutOfOrderness(Duration.ofMillis(0)) //允许乱序的生成策略 最大时间时间-容错时间
- 源码
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.api.common.eventtime;
import org.apache.flink.annotation.Public;
import java.time.Duration;
import static org.apache.flink.util.Preconditions.checkArgument;
import static org.apache.flink.util.Preconditions.checkNotNull;
/**
* A WatermarkGenerator for situations where records are out of order, but you can place an upper
* bound on how far the events are out of order. An out-of-order bound B means that once an event
* with timestamp T was encountered, no events older than {@code T - B} will follow any more.
*
* <p>The watermarks are generated periodically. The delay introduced by this watermark strategy is
* the periodic interval length, plus the out-of-orderness bound.
*/
@Public
public class BoundedOutOfOrdernessWatermarks<T> implements WatermarkGenerator<T> {
/** The maximum timestamp encountered so far. */
private long maxTimestamp;
/** The maximum out-of-orderness that this watermark generator assumes. */
private final long outOfOrdernessMillis;
/**
* Creates a new watermark generator with the given out-of-orderness bound.
*
* @param maxOutOfOrderness The bound for the out-of-orderness of the event timestamps.
*/
public BoundedOutOfOrdernessWatermarks(Duration maxOutOfOrderness) {
checkNotNull(maxOutOfOrderness, "maxOutOfOrderness");
checkArgument(!maxOutOfOrderness.isNegative(), "maxOutOfOrderness cannot be negative");
this.outOfOrdernessMillis = maxOutOfOrderness.toMillis();
// start so that our lowest watermark would be Long.MIN_VALUE.
this.maxTimestamp = Long.MIN_VALUE + outOfOrdernessMillis + 1;
}
// ------------------------------------------------------------------------
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
maxTimestamp = Math.max(maxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));
}
}
中延迟 - 事件时间等待
- allowedLateness(窗口)
设置允许元素延迟的时间。到达水印后超过指定时间的元素将被丢弃。默认情况下,允许的迟到时间为0L。 设置允许的迟到时间仅对事件时间窗口有效。
- 样例
OutputTag<Bean> WMTag = new OutputTag("w_m_tag", TypeInformation.of(Bean.class)) {
};
//窗口版
source.keyBy(Bean::getId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(5)) //窗口最大等待时间
.sideOutputLateData(WMTag)
.reduce(new ReduceFunction<Bean>() {
@Override
public Bean reduce(Bean value1, Bean value2) throws Exception {
System.out.println(value2);
return value2;
}
})
;
大延迟 - 测输出流机制
- sideOutputLateData(窗口)
将迟到数据,输入到测流 此处同测流输出
- 样例
OutputTag<Bean> WMTag = new OutputTag("w_m_tag", TypeInformation.of(Bean.class)) {
};
//窗口版
source.keyBy(Bean::getId)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(5))
.sideOutputLateData(WMTag) //迟到数据测流输出
.reduce(new ReduceFunction<Bean>() {
@Override
public Bean reduce(Bean value1, Bean value2) throws Exception {
System.out.println(value2);
return value2;
}
})
;
eventime获取
- withTimestampAssigner
传入上游数据的对象,通过反射,告诉watermark应该从哪个字段获取timestamp
- 样例
此处主要为实现接口
.withTimestampAssigner(new SerializableTimestampAssigner<Bean>() {
@Override
public long extractTimestamp(Bean element, long recordTimestamp) {
return element.getEventTime();
}
})//watermark提取策略(从数据中)
问题延申
在上述过程中,我们讲了watermark机制是怎么工作的,也知道了他是怎么解决迟到数据的。但是根据watermark的刷新机制,下游获取到上游所有并发向下广播的watermark后,是对比所有watermark的最小值来做自身的watermark值的。那么如果碰到上游某一并发迟迟没有新数据进入,岂不是会导致自身的watermark一直没有更新,从而导致下游时间窗一直不触发?
idle
- 是的
是的,上述场景是存在的。但flink已经是一个成熟的计算引擎了,他不应该存在这样的漏洞。如果有,那就是我们没用对
- 概念
如果其中一个input stream中一直没有数据出现,WatermarkGenerator就无法生成watermark, 因为watermark取的是多个input stream中的最小值。这是我们称这个input是空闲的。watermarkStrategy提供了withIdleness方法处理这种情况。 其实就是当某个分区的窗口触发条件达到,并且其他的分区没有数据的情况下持续我们约定好的空闲时间,那么窗口会触发计算。如果一直有数据但是无法达到触发条件的话,窗口并不会触发计算。
- 样例
.withIdleness(Duration.ofSeconds(5))
- 源码
public class WatermarksWithIdleness<T> implements WatermarkGenerator<T> {
private final WatermarkGenerator<T> watermarks;
private final IdlenessTimer idlenessTimer;
/**
创建一个新的WatermarksWithIdleness生成器,用于在给定超时的情况下检测给定的生成器空闲状态。
参数:
watermarks–原始水印生成器。
idleTimeout–空闲检测的超时。
*/
public WatermarksWithIdleness(WatermarkGenerator<T> watermarks, Duration idleTimeout) {
this(watermarks, idleTimeout, SystemClock.getInstance());
}
@VisibleForTesting
WatermarksWithIdleness(WatermarkGenerator<T> watermarks, Duration idleTimeout, Clock clock) {
checkNotNull(idleTimeout, "idleTimeout");
checkArgument(
!(idleTimeout.isZero() || idleTimeout.isNegative()),
"idleTimeout must be greater than zero");
this.watermarks = checkNotNull(watermarks, "watermarks");
this.idlenessTimer = new IdlenessTimer(clock, idleTimeout);
}
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
watermarks.onEvent(event, eventTimestamp, output);
idlenessTimer.activity();
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
if (idlenessTimer.checkIfIdle()) {
output.markIdle();
} else {
watermarks.onPeriodicEmit(output);
}
}
}
FlinkSQL
- flink sql中的watermark定义方式
//建表
tenv.executeSql( "CREATE TABLE t_kafka("
+" shopId string, "
+" shopName string,"
+" eventTime bigint, "//flink-sql中,watermark的数据来源字段需要是timestamp(3)类型
+" rt as to_timestamp_ltz(eventTime,3), "//所以我们想要使用他,必须要从数据中格式化时间
+" orderId string, "
+" orderAmount bigint, "
+" WATERMARK FOR rt AS rt - INTERVAL '3' SECOND" //watermark_Field-interval ‘int’ date_tpye为boundoutoforderness机制
// +" et timestamp(3) metadata from 'rowtime'"//如果你的时间字段,在kafka的key中,需要以元数据的形式进行提取,具体方式参考官网样例
+") WITH ( "
+" 'connector' = 'kafka', "
+" 'topic' = 'test', "
+" 'properties.bootstrap.servers' = '192.168.110.128:9092', "
+" 'properties.group.id' = 'testGroup', "
+" 'scan.startup.mode' = 'earliest-offset', "
+" 'format' = 'json', "
+" 'json.fail-on-missing-field' = 'false', "
+" 'json.ignore-parse-errors' = 'true' "
+") "
);
- 通过查看表结构和打印数据来查看表中watermark的情况
//打印表结构
tenv.executeSql("desc t_kafka").print();
//查看在flinksql中的watermark表现效果
env.executeSql("select eventTime,CURRENT_WATERMARK(rt) as wmTime from t_kafka").print();
- 表转流与流转表
//演示二,表转流后的watermark表现效果--可以继承
//1.表转流时,参数需要传入表而不是sql或者表名,所以需要先提取出表
Table t_kafka = tenv.from("t_kafka");
DataStream<Row> rowDataStream = tenv.toDataStream(t_kafka); //apply-only 流
// tenv.toChangelogStream(t_kafka);//回撤流 +u -u -d
SingleOutputStreamOperator<Row> process = rowDataStream.process(new ProcessFunction<Row, Row>() {
@Override
public void processElement(Row value, ProcessFunction<Row, Row>.Context ctx, Collector<Row> out) throws Exception {
long l = ctx.timerService().currentWatermark();
// System.out.println("表转流时的watermark:" + l);
out.collect(value);
}
});
// process.print();
Table table = tenv.fromDataStream(process); //当由流转表时,此表不会从上层继承任何元数据信息,包括watermark,需要重新定义
table.printSchema();