NLP: Text Neural Network (Part5: BERT)
NLP: Text Neural Network (Part5: BERT)

JiahuiZhu1998
修改于 2023-06-20 17:07:25
修改于 2023-06-20 17:07:25
预训练
Frozen
先对Model进行预训练,Model之后被用作训练别的任务,保持参数不动
Fine-Tuning
先对Model进行预训练,Model之后被用作训练别的任务,通过训练对模型微调
Elmo (基于Context的Embedding)
解决了一个word的多语义问题
Elmo第一阶段进行预训练,第二阶段提取每一层的word embeddings 作为新特征补充到运行New Task时
BERT
BERT 也是 预训练 + Fine-Tuning
BERT 预训练分为3个部分 Embedding,Masked LM,Next Sentence Prediction
Embedding
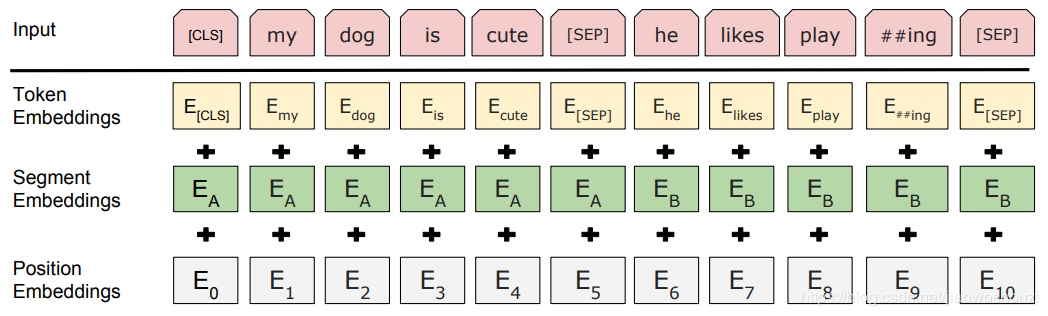
BERT Embedding = Token Embeddings + Segment Embeddings + Position Embeddings
- Token Embedding 是词向量 (CLS标志用于之后的分类任务)
- Segment Embeddings 用于区分 Sentence A 和 Sentence B
- Position Embeddings 位置编码 (和 Transformer 中的不一样)
Masked LM
使用 Mask覆盖一个Sentence中 15%的words;例如 my dog is hairy → my dog is [MASK]
0%是采用[mask],my dog is hairy → my dog is [MASK]
10%是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%保持不变,my dog is hairy -> my dog is hairy
Next Sentence Prediction
选择 A的 Next Sentence which is B
50%的B是A在document中的下一句;另外50%是随机拿取的

GPT
GPT 表示 Generative Pre-Training,生成式预训练,也采用两阶段;第一阶段预训练,第二阶段Fine-tuning

本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录