数据分享|PYTHON用决策树分类预测糖尿病和可视化实例|附代码数据
原创数据分享|PYTHON用决策树分类预测糖尿病和可视化实例|附代码数据
原创
全文下载链接:http://tecdat.cn/?p=23848
最近我们被客户要求撰写关于决策树的研究报告,包括一些图形和统计输出。
在本文中,决策树是对例子进行分类的一种简单表示。它是一种有监督的机器学习技术,数据根据某个参数被连续分割。决策树分析可以帮助解决分类和回归问题
决策树算法将数据集分解成更小的子集;同时,相关的决策树也在逐步发展。决策树由节点(测试某个属性的值)、边/分支(对应于测试的结果并连接到下一个节点或叶子)和叶子节点(预测结果的终端节点)组成,使其成为一个完整的结构。”
扩展:GBDT (Gradient Boosting Decision Tree) 梯度提升决策树
GBDT (Gradient Boosting Decision Tree) 梯度提升决策树。DT-Decision Tree决策树,GB是Gradient Boosting,是一种学习策略,GBDT的含义就是用Gradient Boosting的策略训练出来的DT模型。
在这篇文章中,我们将学习Python中决策树的实现,使用scikit learn包。
对于我们的分析,我们选择了一个非常相关和独特的数据集,该数据集适用于医学科学领域,它将有助于预测病人是否患有糖尿病 ( 查看文末了解数据免费获取方式 ) ,基于数据集中采集的变量。这些信息来自国家糖尿病、消化道和肾脏疾病研究所,包括预测变量,如病人的BMI、怀孕情况、胰岛素水平、年龄等。让我们直接用决策树算法来解决这个问题,进行分类。
用Python实现决策树
对于任何数据分析问题,我们首先要清理数据集,删除数据中的所有空值和缺失值。在这种情况下,我们不是在处理错误的数据,这使我们省去了这一步。?
- 为我们的决策树分析导入所需的库并拉入所需的数据
#?加载库
from?sklearn.model_selection?import?train_test_split?#导入?train_test_split?函数
from?sklearn?import?metrics?#导入scikit-learn模块以计算准确率
#?载入数据集
data?=?pd.read_csv("diabs.csv",?header=None,?names=col_names)让我们看看这个数据集的前几行是什么样子的
pima.head()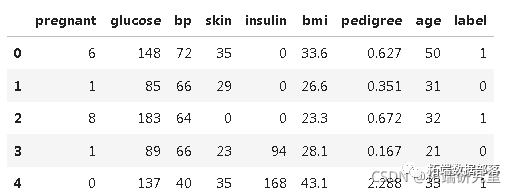
- 在加载数据后,我们了解结构和变量,确定目标变量和特征变量(分别为因变量和自变量)。
#在特征和目标变量中拆分数据集
X?=?pima[feature]?#?特征
y?=?pima.label?#?目标变量- 我们把数据按70:30的比例分成训练集和测试集。
#?将数据集分成训练集和测试集
train_test_split(X,?y,?test_size=0.3,?random_state=1)?#?70%的训练和30%的测试标准做法,你可以根据需要调整70:30至80:20。?
- 使用scikit learn进行决策树分析
#?创建决策树分类器对象
clf?=?DecisionTreeClassifier()- 估计分类器预测结果的准确程度。准确度是通过比较实际测试集值和预测值来计算的。
#?模型准确率,分类器正确的概率是多少?
print("准确率:",metrics.accuracy_score(y_test,?y_pred))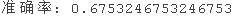
我们的决策树算法有67.53%的准确性。这么高的数值通常被认为是好的模型。?
- 现在我们已经创建了一棵决策树,看看它在可视化的时候是什么样子的
决策树的可视化。
Image(graph.create_png())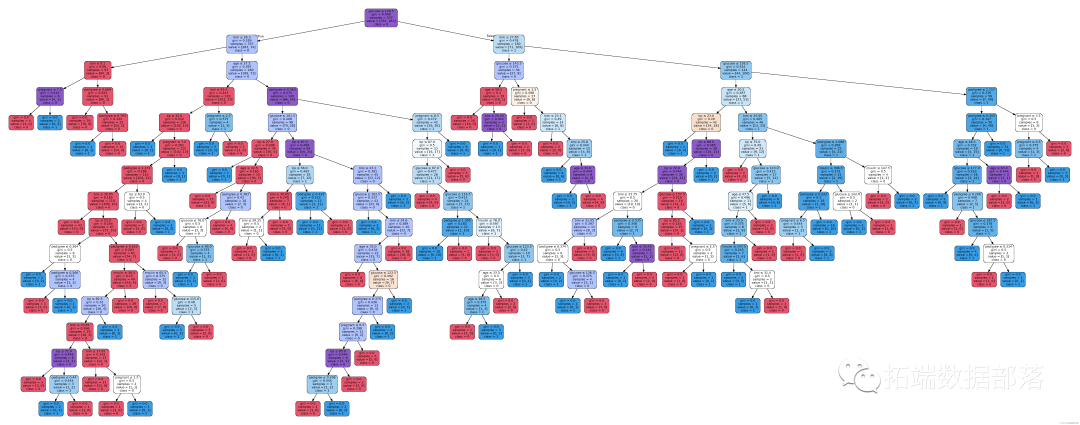
Python输出
你会注意到,在这个决策树图中,每个内部节点都有一个分割数据的决策规则。
衡量通过决策树分析创建的节点的不纯度
Gini指的是Gini比,衡量决策树中节点的不纯度。人们可以认为,当一个节点的所有记录都属于同一类别时,该节点是纯的。这样的节点被称为叶子节点。
在我们上面的结果中,由于结果的复杂性,完整的决策树很难解释。修剪一棵树对于结果的理解和优化它是至关重要的。这种优化可以通过以下三种方式之一进行。
- 标准:默认="gini"
- splitter:字符串,可选(默认="best")或分割策略。选择分割策略。可以选择 "best"来选择最佳分割,或者选择 "random"来选择最佳随机分割。
- max_depth: int或None,可选(默认=None)或树的最大深度 这个参数决定了树的最大深度。这个变量的数值越高,就会导致过度拟合,数值越低,就会导致拟合不足。
在我们的案例中,我们将改变树的最大深度作为预修剪的控制变量。让我们试试max_depth=3。
#?创建决策树分类器对象
DecisionTree(?max_depth=3)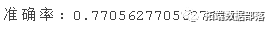
在Pre-pruning上,决策树算法的准确率提高到77.05%,明显优于之前的模型。
决策树在Python中的实现
Image(graph.create_png())结果:
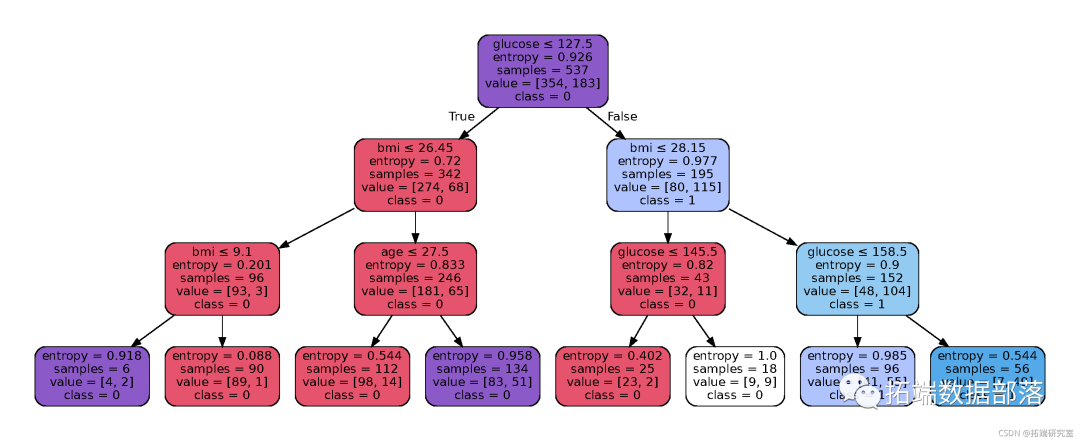
Python输出
这个修剪过的模型的结果看起来很容易解释。有了这个,我们就能够对数据进行分类,并预测一个人是否患有糖尿病。但是,决策树并不是你可以用来提取这些信息的唯一技术,你还可以探索其他各种方法。
如果你想学习和实现这些算法,那么你应该探索通过辅助方法学习,并得到专业人士的1对1指导。拓端数据科学职业轨道计划保证了1:1的指导,项目驱动的方法,职业辅导,提供实习工作项目保证,来帮助你将职业生涯转变为数据驱动和决策的角色。请联系我们以了解更多信息!
本文摘选 《 PYTHON用决策树分类预测糖尿病和可视化实例 》 ,点击“阅读原文”获取全文完代码和数据资料。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。