Beam-介绍

简介
Beam提供了一套统一的API来处理两种数据处理模式(批和流),让我们只需要将注意力专注于在数据处理的算法上,而不用再花时间去对两种数据处理模式上的差异进行维护。
Beam每6周更新一个小版本。
编程模型
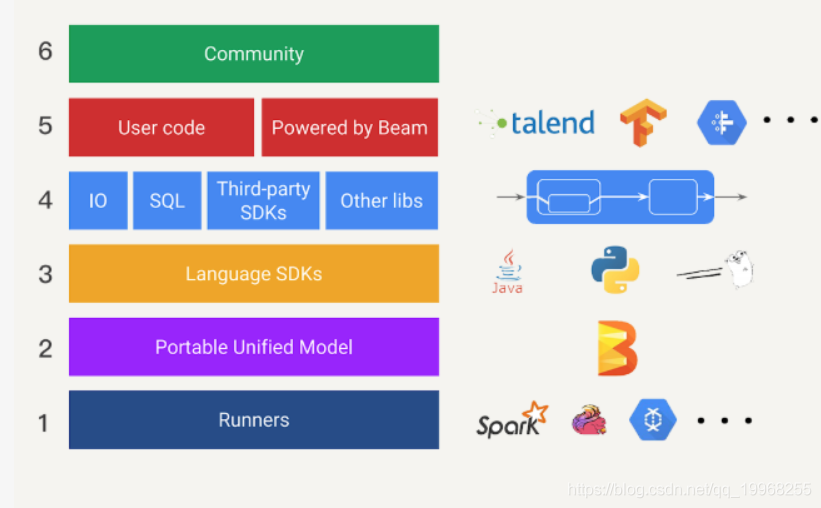
- 第一层是现有各大数据处理平台(spark或者flink),在Beam中它们也被称为Runner。
- 第二层,是可移植的统一模型层,各个Runners将会依据中间抽象出来的这个模型思想,提供一套符合这个模型APLs出来,以供上层转换。
- 第三层,是SDK层。SDK层将会给工程师提供不同语言版本的API来编写数据处理逻辑,这些逻辑就会被转化Runner中相应API来运行。
- 第四层,是可扩展库层。工程师可以根据已有的BeamSDK,贡献分享出更多的新开发者SDK,IO连接器,转换操作库等等。
- 第五层,我们可以看作是应用层,各种应用将会通过下层的BeamSDK或工程师贡献的开发者SDK来实现。
- 第六层,社区。
窗口将无边界数据根据事件时间分成一个个有限数据集。我们可以看看批处理这个特例。在批处理中,我们其实是把一个无穷小到无穷大的时间窗口赋予了数据集。
水印是用来表示与数据事件时间相关联的输入完整性的概念。对于事件时间X的水印是指:数据处理逻辑已经得到了所有时间小于X的无边界数据。在数据处理中,水印是用来测量数据进度的。
触发器指的是表示在具体什么时候,数据处理逻辑会真正地出发窗口中的数据被计算。触发器能让我们可以在有需要时对数据进行多次运算,例如某时间窗口内数据有更新,这一窗口内的数据结果需要重算。
累加模式指的是如果我们在同一窗口中得到多个运算结果,我们应该如何处理这些运算结果。这些结果之间可能完全不相关,例如与时间先后无关的结果,直接覆盖以前的运算结果即可。这些结果也可能会重叠在一起。
数据处理常见设计模式:
- 复制模式通常是将单个数据处理模块中的数据,完整地复制到两个或更多的数据处理模块中,然后再由不同的数据处理模块进行处理。
- 过滤掉不符合特定条件的数据。
- 如果你在处理数据集时并不想丢弃里面的任何数据,而是想把数据分类为不同的类别进行处理时,你就需要用到分离式来处理数据。
- 合并模式会将多个不同的数据转换集中在一起,成为一个总数据集,然后将这个总数据集放在一个工作流中进行处理。
PCollection
可并行计算数据集。
Coders通信编码。
无序-跟分布式有关。
没有固定大小。
不可变性。
Pipeline
Beam数据流水线的底层思想其实还是mr得原理,在分布式环境下,整个数据流水线启动N个Workers来同时处理PCollection.而在具体处理某一个特定Transform的时候,数据流水线会将这个Transform的输入数据集PCollection里面元素分割成不同Bundle,将这些Bundle分发给不同Worker处理。
Beam数据流水线具体会分配多少个Worker,以及将一个PCollection分割成多少个Bundle都是随机的。但是Beam数据流水线会尽可能让整个处理流程达到完美并行。
Beam数据流水线错误处理:
- 在一个Transform里面,如果某一个Bundle里面的元素因为任意原因导致处理失败了,则这个整个Bundle里面的元素都必须重新处理。
- 在多步骤Transform上如果处理的一个Bundle元素发生错误了,则这个元素所在的整个Bundle以及这个Bundle有关联所有Bundle都必须重新处理。
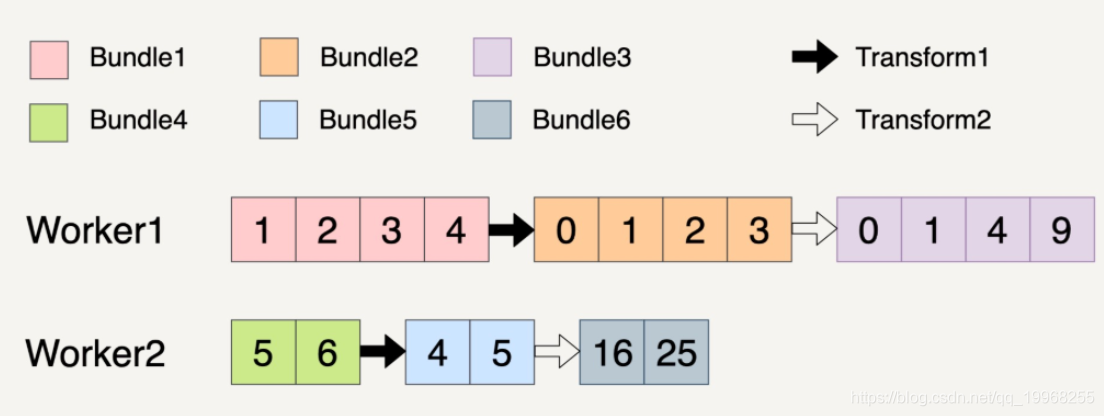
两个Transforms,第一个Transform会将元素的数值减一,第二Transform会对元素的数值求平方,整个过程分配两个workers。
Transform
并行处理数据操作
类似spark的map,parDo支持数据输出到多个PCollection,而Spark得MapReduce的map可以说是单线的,ParDo提供内建的状态存储机制,而Spark和mr没有。
ParDo
使用ParDo时,你需要继承它提供DoFn(DoFn分布式处理功能类)类:
// The input PCollection of Strings.
PCollection<String> words = ...;
// The DoFn to perform on each element in the input PCollection.
static class ComputeWordLengthFn extends DoFn<String, Integer> { ... }
// Apply a ParDo to the PCollection "words" to compute lengths for each word.
PCollection<Integer> wordLengths = words.apply(
ParDo
.of(new ComputeWordLengthFn())); // The DoFn to perform on each element, which
// we define above.过滤一个数据集:
@ProcessElement
public void processElement(@Element T input, OutputReceiver<T> out) {
if (IsNeeded(input)) {
out.output(input);
}
}格式换一个数据集:
@ProcessElement
public void processElement(@Element String csvLine, OutputReceiver<tf.Example> out) {
out.output(ConvertToTfExample(csvLine));
}?提取一个数据集的特定值
@ProcessElement
public void processElement(@Element Item item, OutputReceiver<Integer> out) {
out.output(item.price());
}GroupByKey?
Key/Value 数据集按Key归并
Pipeline I/O
读取数据集
PCollection<String> inputs = p.apply(TextIO.read().from(filepath));
PCollection<String> inputs = p.apply(TextIO.read().from("filepath/.../YYYY-MM-*.csv");
PCollection<String> inputs = p.apply(TextIO.read().from("filepath/.../YYYY/MM/*.csv");
//数据集合并
PCollection<String> input1 = p.apply(TextIO.read().from(filepath1);
PCollection<String> input2 = p.apply(TextIO.read().from(filepath2);
PCollection<String> input3 = p.apply(TextIO.read().from(filepath3);
PCollectionList<String> collections = PCollectionList.of(input1).and(input2).and(input3);
PCollection<String> inputs = collections.apply(Flatten.<String>pCollections());输出数据集
output.apply(TextIO.write().to(filepath));
output.apply(TextIO.write().to(filepath/output));
output.apply(TextIO.write().to(filepath/output).withSuffix(".csv"));在Beam里面,Read和Write的Transform都是在名为I/O连接器类面实现。例如文件读取FileIO.TFRecordIO,基于流处理KafkaIO,PubsubIO,基于数据可JdbcIO,RedisIO等等。并不可能支持所有外部源(自定义I/O连接器)。
自定义I/O连接器,通常指的就是实现Read Transform和Write Transform 这两种操作,这两种操作都有各自实现方法。
自定义读取操作:
读取有界数据集
- 1.两个 Transform 接口,ParDo 和 GroupByKey 来模拟读取数据的逻辑。
- 2.继承 BoundedSource 抽象类来实现一个子类去实现读取逻辑。
读取无界数据集
如果读取的是无界数据集的话,那我们就必须继承 UnboundedSource 抽象类来实现一个子类去实现读取逻辑。
无论是 BoundedSource 抽象类还是 UnboundedSource 抽象类,其实它们都是继承了 Source 抽象类。为了能够在分布式环境下处理数据,这个 Source 抽象类也必须是可序列化的,也就是说 Source 抽象类必须实现 Serializable 这个接口。、
多文件路径数据集
从多文件路径中读取数据集相当于用户转入一个 glob 文件路径,我们从相应的存储系统中读取数据出来。比如说读取“filepath/**”中的所有文件数据,我们可以将这个读取转换成以下的 Transforms:
- 获取文件路径的 ParDo:从用户传入的 glob 文件路径中生成一个 PCollection的中间结果,里面每个字符串都保存着具体的一个文件路径。
- 读取数据集 ParDo:有了具体 PCollection的文件路径数据集,从每个路径中读取文件内容,生成一个总的 PCollection 保存所有数据。
NoSQL数据库中读取数据
NoSQL 这种外部源通常允许按照键值范围(Key Range)来并行读取数据集。我们可以将这个读取转换成以下的 Transforms:
- 确定键值范围 ParDo:从用户传入的要读取数据的键值生成一个 PCollection 保存可以有效并行读取的键值范围。
- 读取数据集 ParDo:从给定 PCollection 的键值范围,读取相应的数据,并生成一个总的 PCollection 保存所有数据。
关系数据库读取数据集
从传统的关系型数据库查询结果通常都是通过一个 SQL Query 来读取数据的。所以,这个时候只需要一个 ParDo,在 ParDo 里面建立与数据库的连接并执行 Query,将返回的结果保存在一个 PCollection 里。
自定义输出
相比于读取操作,输出操作会简单很多,只需要在一个 ParDo 里面调用相应文件系统的写操作 API 来完成数据集的输出。
如果我们的输出数据集是需要写入到文件去的话,Beam 也同时提供了基于文件操作的 FileBasedSink 抽象类给我们,来实现基于文件类型的输出操作。像很常见的 TextSink 类就是实现了 FileBasedSink 抽象类,并且运用在了 TextIO 中的。
如果我们要自己写一个自定义的类来实现 FileBasedSink 的话,也必须实现 Serializable 这个接口,从而保证输出操作可以在分布式环境下运行。
同时,自定义的类必须具有不可变性(Immutability)。怎么理解这个不可变性呢?其实它指的是在这个自定义类里面,如果有定义私有字段(Private Field)的话,那它必须被声明为 final。如果类里面有变量需要被修改的话,那每次做的修改操作都必须先复制一份完全一样的数据出来,然后再在这个新的变量上做修改。
设计Beam Pipeline
1.输入数据存储位置
2.输入数据格式
3.数据进行哪些Transform
4.输出数据格式
Beam的Transform单元测试
一般来说,Transform 的单元测试可以通过以下五步来完成:
- 1.创建一个 Beam 测试 SDK 中所提供的 TestPipeline 实例。
- 2.创建一个静态(Static)的、用于测试的输入数据集。
- 3.使用 Create Transform 来创建一个 PCollection 作为输入数据集。
- 4.在测试数据集上调用我们需要测试的 Transform 上并将结果保存在一个 PCollection 上。
- 5.使用 PAssert 类的相关函数来验证输出的 PCollection 是否是我所期望的结果。
Transform单元测试示例
final class TestClass {
static final List<Integer> INPUTS = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
public void testFn() {
Pipeline p = TestPipeline.create();
PCollection<Integer> input = p.apply(Create.of(INPUTS)).setCoder(VarIntCoder.of());
PCollection<String> output = input.apply(ParDo.of(new EvenNumberFn()));
PAssert.that(output).containsInAnyOrder(2, 4, 6, 8, 10);
p.run();
}
}Beam的端到端的测试
在 Beam 中,端到端的测试和 Transform 的单元测试非常相似。唯一的不同点在于,我们要为所有的输入数据集创建测试数据集,而不是只针对某一个 Transform 来创建。对于在数据流水线的每一个应用到 Write Transfrom 的地方,我们都需要用到 PAssert 类来验证输出数据集。
步骤
- 创建一个 Beam 测试 SDK 中所提供的 TestPipeline 实例。
- 对于多步骤数据流水线中的每个输入数据源,创建相对应的静态(Static)测试数据集。
- 使用 Create Transform,将所有的这些静态测试数据集转换成 PCollection 作为输入数据集。
- 按照真实数据流水线逻辑,调用所有的 Transforms 操作。
- 在数据流水线中所有应用到 Write Transform 的地方,都使用 PAssert 来替换这个 Write Transform,并且验证输出的结果是否我们期望的结果相匹配。
//测试用例
final class TestClass {
static final List<String> INPUTS =
Arrays.asList("1", "2", "3", "4", "5", "6", "7", "8", "9", "10");
static class EvenNumberFn extends DoFn<Integer, Integer> {
@ProcessElement
public void processElement(@Element Integer in, OutputReceiver<Integer> out) {
if (in % 2 == 0) {
out.output(in);
}
}
}
static class ParseIntFn extends DoFn<String, Integer> {
@ProcessElement
public void processElement(@Element String in, OutputReceiver<Integer> out) {
out.output(Integer.parseInt(in));
}
}
public void testFn() {
Pipeline p = TestPipeline.create();
PCollection<String> input = p.apply(Create.of(INPUTS)).setCoder(StringUtf8Coder.of());
PCollection<Integer> output1 = input.apply(ParDo.of(new ParseIntFn())).apply(ParDo.of(new EvenNumberFn()));
PAssert.that(output1).containsInAnyOrder(2, 4, 6, 8, 10);
PCollection<Integer> sum = output1.apply(Combine.globally(new SumInts()));
PAssert.that(sum).is(30);
p.run();
}
}运行模式
直接运行模式
如果是在命令行中指定 Runner 的话,那么在调用这个程序时候,需要指定这样一个参数–runner=DirectRunner。比如:
mvn compile exec:java -Dexec.mainClass=YourMainClass \???? -Dexec.args="--runner=DirectRunner" -Pdirect-runner
PipelineOptions options =?????? PipelineOptionsFactory.fromArgs(args).create();
一般我们会把 runner 通过命令行指令传递进程序。就需要使用 PipelineOptionsFactory.fromArgs(args) 来创建 PipelineOptions。PipelineOptionsFactory.fromArgs() 是一个工厂方法,能够根据命令行参数选择生成不同的 PipelineOptions 子类。
pom.xml
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.9.0</version>
<scope>runtime</scope>
</dependency>使用 Java Beam SDK 时,我们要给程序添加 Direct Runner 的依赖关系。在下面这个 maven 依赖关系定义文件中,我们指定了 beam-runners-direct-java 这样一个依赖关系。
我们先从直接运行模式开始讲。这是我们在本地进行测试,或者调试时倾向使用的模式。在直接运行模式的时候,Beam 会在单机上用多线程来模拟分布式的并行处理。
spark运行模式
目前使用 Spark Runner 必须使用 Spark 2.2 版本以上。
Spark Runner 为在 Apache Spark 上运行 Beam Pipeline 提供了以下功能:
- Batch 和 streaming 的数据流水线;
- 和原生 RDD 和 DStream 一样的容错保证;
- 和原生 Spark 同样的安全性能;
- 可以用 Spark 的数据回报系统;
- 使用 Spark Broadcast 实现的 Beam side-input。
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-spark</artifactId>
<version>2.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
</dependency>使用 SparkPipelineOptions 传递进 Pipeline.create() 方法。常见的创建方法是从命令行中读取参数来创建 PipelineOption,使用的是 PipelineOptionsFactory.fromArgs(String[]) 这个方法。在命令行中,你需要指定 runner=SparkRunner:
mvn exec:java -Dexec.mainClass=YourMainClass \??? -Pspark-runner \??? -Dexec.args="--runner=SparkRunner \????? --sparkMaster=spark master url>"
也可以在 Spark 的独立集群上运行,这时候 spark 的提交命令,spark-submit。
spark-submit --class YourMainClass --master spark://HOST:PORT target/...jar --runner=SparkRunner
当 Beam 程序在 Spark 上运行时,你也可以同样用 Spark 的网页监控数据流水线进度。
flink运行模式
Flink Runner 是 Beam 提供的用来在 Flink 上运行 Beam Pipeline 的模式。你可以选择在计算集群上比如 Yarn/Kubernetes/Mesos 或者本地 Flink 上运行。Flink Runner 适合大规模,连续的数据处理任务,包含了以下功能:
- 以 Streaming 为中心,支持 streaming 处理和 batch 处理;
- 和 flink 一样的容错性,和 exactly-once 的处理语义;
- 可以自定义内存管理模型;
和其他(例如 YARN)的 Apache Hadoop 生态整合比较好。
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-flink-1.6</artifactId>
<version>2.13.0</version>
</dependency>flink runner:
mvn exec:java -Dexec.mainClass=YourMainClass \??? -Pflink-runner \??? -Dexec.args="--runner=FlinkRunner \????? --flinkMaster=flink master url>"
google dataflow运行模式
Beam Pipeline 也能直接在云端运行。Google Cloud Dataflow 就是完全托管的 Beam Runner。当你使用 Google Cloud Dataflow 服务来运行 Beam Pipeline 时,它会先上传你的二进制程序到 Google Cloud,随后自动分配计算资源创建 Cloud Dataflow 任务。
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-google-cloud-dataflow-java</artifactId>
<version>2.13.0</version>
<scope>runtime</scope>
</dependency>mvn -Pdataflow-runner compile exec:java \????? -Dexec.mainClass=YourMainClass> \????? -Dexec.args="--project=PROJECT_ID> \????? --stagingLocation=gs://STORAGE_BUCKET>/staging/ \????? --output=gs://STORAGE_BUCKET>/output \????? --runner=DataflowRunner"
Beam Window
窗口
PCollectionString> input = p.apply(TextIO.read().from(filepath));PCollectionString> batchInputs = input.apply(Window.String>into(new GlobalWindows()));需要注意的是,你在处理有界数据集的时候,可以不用显式地将一个窗口分配给一个 PCollection 数据集。但是,在处理无边界数据集的时候,你必须要显式地分配一个窗口给这个无边界数据集。而这个窗口不可以是前面提到的全局窗口,否则在运行数据流水线的时候会直接抛出异常错误。
固定窗口(Fixed Window)
通常由一个静态窗口大小定义
PCollectionString> input = p.apply(KafkaIO.Long, String>read()).apply(Values.String>create());PCollectionString> fixedWindowedInputs = input.apply(Window.String>into(FixedWindows.of(Duration.standardHours(1))));滑动窗口
一个静态窗口大小和一个滑动周期定义而来
PCollectionString> input = p.apply(KafkaIO.Long, String>read()).apply(Values.String>create());PCollectionString> slidingWindowedInputs = input.apply(Window.String>into(SlidingWindows.of(Duration.standardHours(1)).every(Duration.standardMinutes(30))));会话窗口(Session Window)
会话窗口主要是用于记录持续了一段时间的活动数据集。在一个会话窗口中的数据集,如果将它里面所有的元素按照时间戳来排序的话,那么任意相邻的两个元素它们的时间戳相差不会超过一个定义好的静态间隔时间段(Gap Duration)。
PCollectionString> input = p.apply(KafkaIO.Long, String>read()).apply(Values.String>create());PCollectionString> sessionWindowedInputs = input.apply(Window.String>into(Sessions.withGapDuration(Duration.standardMinutes(5))));示例
经典例子wordcount
public class BeamMinimalWordCountTest {
@SuppressWarnings("serial")
public static void main(String[] args) {
PipelineOptions options = PipelineOptionsFactory.create();
options.setRunner(DirectRunner.class); // 显式指定PipelineRunner:DirectRunner(Local模式)
Pipeline pipeline = Pipeline.create(options);
// 读取本地文件,构建第一个PTransform
pipeline.apply("ReadLines", TextIO.read().from("文件url"))
.apply("ExtractWords", ParDo.of(new DoFn<String, String>() {
// 对文件中每一行进行处理(实际上Split)
@ProcessElement
public void processElement(ProcessContext c) {
for (String word : c.element().split("[\\s:\\,\\.\\-]+")) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}))
// 统计每一个Word的Count
.apply(Count.<String> perElement())
.apply("ConcatResultKVs", MapElements.via(
// 拼接最后的格式化输出(Key为Word,Value为Count)
new SimpleFunction<KV<String, Long>, String>() {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}))
.apply(TextIO.write().to("wordcount"));
// 输出结果
pipeline.run().waitUntilFinish();
}
}引用蔡元楠《大规模数据处理实战》