使用pyspark实现RFM模型及应用(超详细)
原创使用pyspark实现RFM模型及应用(超详细)
原创
本文主要介绍了RFM模型,以及使用pyspark实现利用RFM模型对用户分层的简单应用~让大家对RFM有一个更深刻的认识
1 RFM模型
以下回答来自chatGPT:
1.1 什么是RFM模型
RFM模型最早在20世纪90年代由数据库营销行业提出,用于分析和预测客户的购买行为。最初,RFM模型主要应用于邮购行业,帮助企业识别最有可能响应邮件营销的客户。随着电子商务和数据科学的发展,RFM模型逐渐被应用到更多的行业和领域,如零售、电信、金融等。
RFM代表Recency(最近一次消费)、Frequency(消费频率)和Monetary(消费金额),这三个指标可以帮助企业了解客户的购买行为和价值。
Recency(最近一次消费):衡量客户最近一次购买的时间。一般来说,最近购买的客户更有可能再次购买。这个指标可以帮助企业识别那些可能流失的客户,以便采取措施挽留他们。
Frequency(消费频率):衡量客户在一段时间内的购买次数。高频消费的客户往往对企业的产品或服务更感兴趣,也更有可能成为忠实客户。通过分析消费频率,企业可以找到那些具有较高潜在价值的客户。
Monetary(消费金额):衡量客户在一段时间内的总消费金额。消费金额较高的客户对企业的贡献更大,因此需要重点关注和维护。通过分析消费金额,企业可以了解客户的购买能力和偏好。
1.2 RFM模型实施步骤
RFM模型的实施步骤如下:
数据收集:收集客户的购买记录,包括购买时间、购买次数和购买金额等信息。
数据处理:将收集到的数据按照RFM指标进行整理,计算每个客户的R、F、M值。
客户分级:根据R、F、M值,将客户分为不同的等级。例如,可以将R、F、M值分别划分为1-5的等级,然后根据客户的RFM组合进行细分。
制定策略:根据客户细分结果,制定相应的营销策略。例如,针对高价值客户,可以提供更高级别的服务和优惠;针对低价值客户,可以采取措施提高他们的消费频率和金额。
评估效果:执行营销策略后,需要对效果进行评估,以便调整策略并持续优化客户关系。
总之,RFM模型是一种简单而有效的客户分析方法,可以帮助企业更好地了解客户需求,提高客户满意度和忠诚度。
RFM分层示例图:
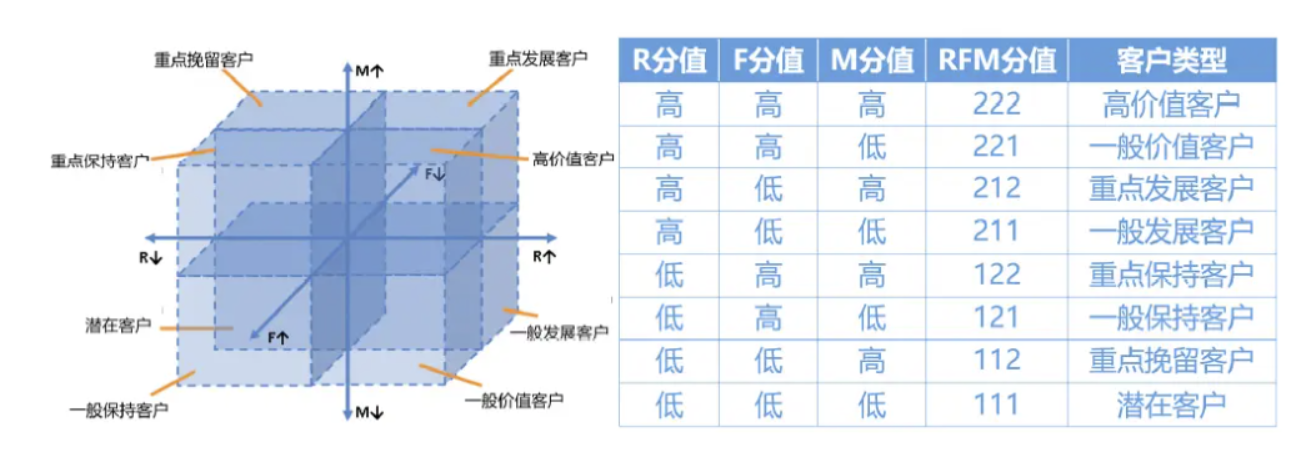
1.3 RFM模型应用场景
在客户分析和营销策略中的应用价值:
客户细分:RFM模型可以帮助企业将客户分为不同的群体,如高价值客户、潜在客户、流失客户等。这有助于企业更好地理解客户的需求和行为,提供个性化的产品和服务。
营销策略制定:根据RFM模型的结果,企业可以制定针对性的营销策略。例如,对于最近购买且购买频率高的客户,企业可以提供优惠券或特别优惠以增加客户忠诚度;对于长时间未购买的客户,企业可以发送提醒邮件或推送相关产品以激发他们的购买欲望。
客户流失预警:RFM模型可以帮助企业识别可能流失的客户。通过分析客户的购买行为,企业可以提前采取措施挽留客户,减少客户流失。
客户价值评估:RFM模型可以帮助企业评估每个客户的价值,优化资源分配。例如,企业可以将更多的资源投入到高价值客户的维护和发展上,提高营销效率和ROI。
总的来说,RFM模型是一种强大的客户分析工具,可以帮助企业更好地理解客户,提高营销效果和客户满意度。
2 采用pyspark实现RFM
以下是本人一个字一个字敲出来:
了解了RFM模型后,我们来使用pyspark来实现RFM模型以及应用~
在代码实践之前,最好先配置好环境:
2.1 创建数据
RFM三要素:消费时间,消费次数,消费金额。我们就围绕这三个元素使用随机数创建源数据,并保存到文件。
def create_rfm_excel(file_path):
""" 随机生成一个rfm的源数据表格,保存到csv
"""
workbook = xlwt.Workbook()
worksheet = workbook.add_sheet("sheet1")
# 消费时间,消费用户id,消费物品id,消费维度(次数,金额),消费值
column_names = ['ftime', 'uin', 'item_id', 'pay_dimension', 'value']
column_count = len(column_names)
for i in range(column_count):
worksheet.write(0, i, column_names[i])
# 向构建好字段的excel表写入所有的数据记录
row_count = 200
# 付费总次数(天)
pay_dimension_cnt = "pay_cnt"
# 付费总金额(天)
pay_dimension_amt = "pay_amt"
for i in range(0, row_count, 2):
# 随机时间(一个月内)
random_ftime = random.randint(20220101, 20220131)
# 随机uin--10个用户
random_uin = str(random.randint(1, 10))
# 随机item--10个产品
random_item_id = str(random.randint(1000, 1010))
# 每天随机登录次数--1-5次
# 每次登录次数/消费金额
value_cnt = random.randint(1, 5)
value_amt = random.randint(100, 10000)
# 写消费次数数据
worksheet.write(i + 1, 0, random_ftime)
worksheet.write(i + 1, 1, random_uin)
worksheet.write(i + 1, 2, random_item_id)
worksheet.write(i + 1, 3, pay_dimension_cnt)
worksheet.write(i + 1, 4, value_cnt)
# 写消费金额数据
worksheet.write(i + 2, 0, random_ftime)
worksheet.write(i + 2, 1, random_uin)
worksheet.write(i + 2, 2, random_item_id)
worksheet.write(i + 2, 3, pay_dimension_amt)
worksheet.write(i + 2, 4, value_amt)
workbook.save(file_path)2.2 读取文件到数据库
上节我们有一个本地的csv文件,当然如果你有现有的业务数据,可以直接使用表格数据~
这一步我们将文件保存到数据库中。
def create_table_from_excel(excelFile, table_name):
""" 从excel读取表并保存到数据库
"""
df = pd.DataFrame(pd.read_excel(excelFile))
engine =create_engine('mysql+pymysql://root:123456@localhost:3306/test')
df.to_sql(table_name, con=engine, if_exists='replace', index=False)2.3 读取数据库的数据表
从数据库中读取表数据进行操作~
如果你本来就有数据库表,那上面两步都可以省略,直接进入这一步。
def spark_read_table(spark, table_name):
data = spark.read.jdbc(url=url, table=table_name, properties=prop)
return data这里返回的数据格式:pyspark.sql.dataframe.DataFrame。有了df后就可以使用pyspark进行操作,构建RFM模型了。
2.4 构建RFM模型
通过第一章的了解,我们需要通过用户的行为得到用户在周期(一个月)内的最近消费时间和当前时间的间隔,一个月内的消费次数,一个月内的消费金额,那通过pyspark如何统计呢?上代码
def get_rfm_value(df, base_time):
# 今天做为basetime,离今天的距离作为消费时间,r_value最小值为最近消费时间
# today = datetime.datetime.now().strftime("%Y%m%d")
# 计算当天和base_time的间隔天数
new_item_r_pay = df.withColumn('base_time', func.lit(base_time)). \
withColumn('date_diff', get_r_value(func.col("ftime"), func.col("base_time")))
new_item_r_pay = new_item_r_pay.select(["uin", "item_id", "date_diff"])
# 计算消费时间和base_time最近的天数(最近消费时间)
r_value = new_item_r_pay.groupby("uin", "item_id").agg(func.min('date_diff').alias("r_value")).drop("date_diff")
# 近一个月的最近消费时间
new_item_r_pay = new_item_r_pay.drop("date_diff").distinct().join(r_value, ["uin", "item_id"], "inner")
# 近一个月的消费次数
f_value = df.filter(df['pay_dimension'] == 'pay_cnt').groupby("uin", "item_id").agg(func.sum("value").alias("f_value"))
new_item_f_value = df.select(["uin", "item_id"]).distinct().join(f_value, ["uin", "item_id"], "inner")
# 近一个月的消费金额
m_value = df.filter(df['pay_dimension'] == 'pay_amt').groupby("uin", "item_id").agg(func.sum("value").alias("m_value"))
new_item_m_value = df.select(["uin", "item_id"]).distinct().join(m_value, ["uin", "item_id"], "inner")
rfm_values = new_item_r_pay.join(new_item_f_value, ["uin", "item_id"], "inner").join(new_item_m_value, ["uin", "item_id"], "inner")
rfm_values.show()
return rfm_values2.5 RFM模型应用
有了RFM模型,我们就可以通过策略对用户分层了。其实这里就是要为RFM定义阈值来对用户划分,实际情况要依据产品和运营策略,比如是否有运营策略,是否有运营阈值等等因素。
本文就用最简单的中位数来作为阈值啦~
@udf(returnType=StringType())
def get_rfm_score(r_value, r_med, f_value, f_med, m_value, m_med):
score = ""
# 最近
if r_value <= r_med:
score += "1"
else:
score += "0"
# 频率
if f_value >= f_med:
score += "1"
else:
score += "0"
# 金额
if m_value >= m_med:
score += "1"
else:
score += "0"
score_dict = {"111": "重要价值用户", "011": "重要保持用户", "101": "重要发展用户", "001": "重要挽留用户", "110": "一般价值用户", "010": "一般保持用户",
"100": "一般发展用户", "000": "一般挽留用户"}
return score_dict[score]
def test_statistics_RFM(df):
df.select([func.mean("r_value"), func.min("r_value"), func.max("r_value")]).show()
r_med = df.approxQuantile("r_value", [0.5], 0)[0]
f_med = df.approxQuantile("f_value", [0.5], 0)[0]
m_med = df.approxQuantile("m_value", [0.5], 0)[0]
print("quantiles", r_med, f_med, m_med)
# 获取rfm的划分阈值
df = df.withColumn('ftime', func.lit(base_time)) \
.withColumn('r_med_val', func.lit(r_med)) \
.withColumn('f_med_val', func.lit(f_med)) \
.withColumn('m_med_val', func.lit(m_med))
# 获取最终分层分数
df = df.withColumn('score', get_rfm_score(func.col("r_value"), func.col("r_med_val"),
func.col("f_value"), func.col("f_med_val"),
func.col("m_value"), func.col("m_med_val")))
df.show()2.6 整体调用逻辑
prop = {'user': 'root',
'password': '123456',
'driver': 'com.mysql.cj.jdbc.Driver'}
url = 'jdbc:mysql://localhost:3306/test'
if __name__ == '__main__':
file_path = r'F:\mine_code\my_spark_code\test_excels\test_rfm.xls'
# step1:制作一个rfm需要的源数据,包括用户,用户消费时间,用户消费金额
create_rfm_excel(file_path)
# step2: excel数据转DataFrame,然后保存到数据库表中,有第一步数据可以不需要这一步,为了更详细步骤添加
table_name = 'my_test_rfm'
create_table_from_excel(file_path, table_name)
# step3:从数据库中读取数据
spark = SparkSession. \
Builder(). \
appName('sql'). \
master('local'). \
getOrCreate()
src_df = spark_read_table(spark, table_name)
src_df.show()
# step4: 通过用户行为计算RFM值
base_time = "20220129"
rfm_df = get_rfm_value(src_df, base_time)
# step5: 根据策略进行用户分层
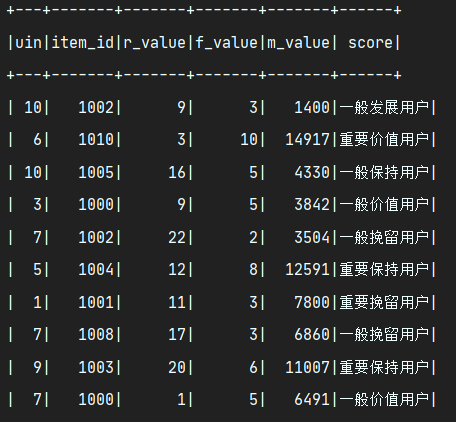
test_statistics_RFM(rfm_df)看看结果
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。