使用腾讯云Elasticsearch 8.8.1实现:NLP+Vector Search+GAI
原创使用腾讯云Elasticsearch 8.8.1实现:NLP+Vector Search+GAI
原创
腾讯云Elasticsearch service在最近上线了8.8.1版本。该版本中的核心能力,是为AI革命提供高级搜索能力!该版本特别引入了Elasticsearch Relevance Engine?(ESRE?)—— 一款强大的AI增强搜索引擎,为搜索与分析带来全新的前沿体验。
或许大家会觉得现在遍地开花的向量库,这个发布也仅仅是“其中之一”。但如果我给大家强调一下其中的重点,或许会给大家一个更清楚的认知和定位:
这是目前中国公有云上仅有的提供从自然语言处理,到向量化,再到向量搜索,并能与大模型集成的端到端的搜索与分析平台:
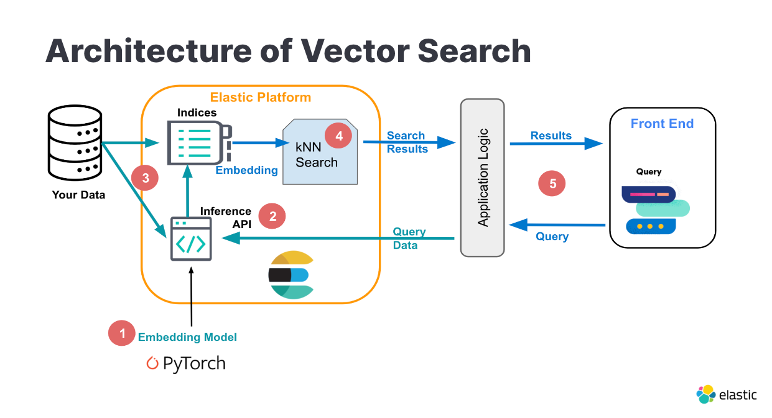
不是所有的向量库,都能在单一接口调用中实现多路召回混合排序!
也不是所有的搜索引擎,能在执行向量搜索之后能再进行聚合操作!

当然,本文的重点不是介绍,而是应用与实践。接下来,本文将展示如何在腾讯云上创建Elasticsearch 8.8.1集群,并部署与使用NLP模型结合,并在向量搜索的基础上,与大模型进行结合。
创建Elasticsearch 8.8.1集群
创建的过程很简单,与以往一样,选择对应的版本即可。这里需要强调的是,因为我们要将各种NLP模型,embedding模型部署到集群当中,因此需要尽量选择足够的内存用于模型的部署。
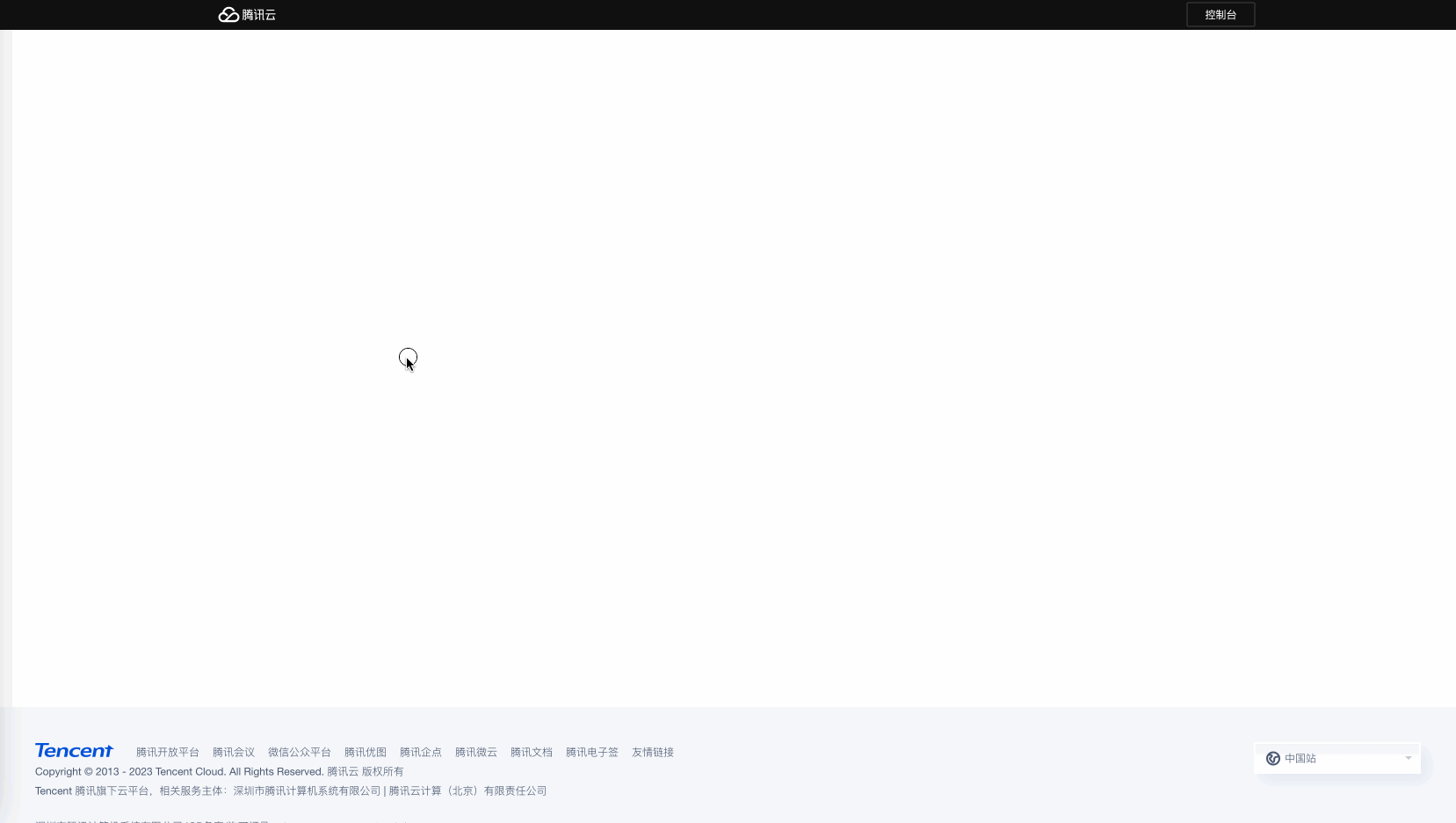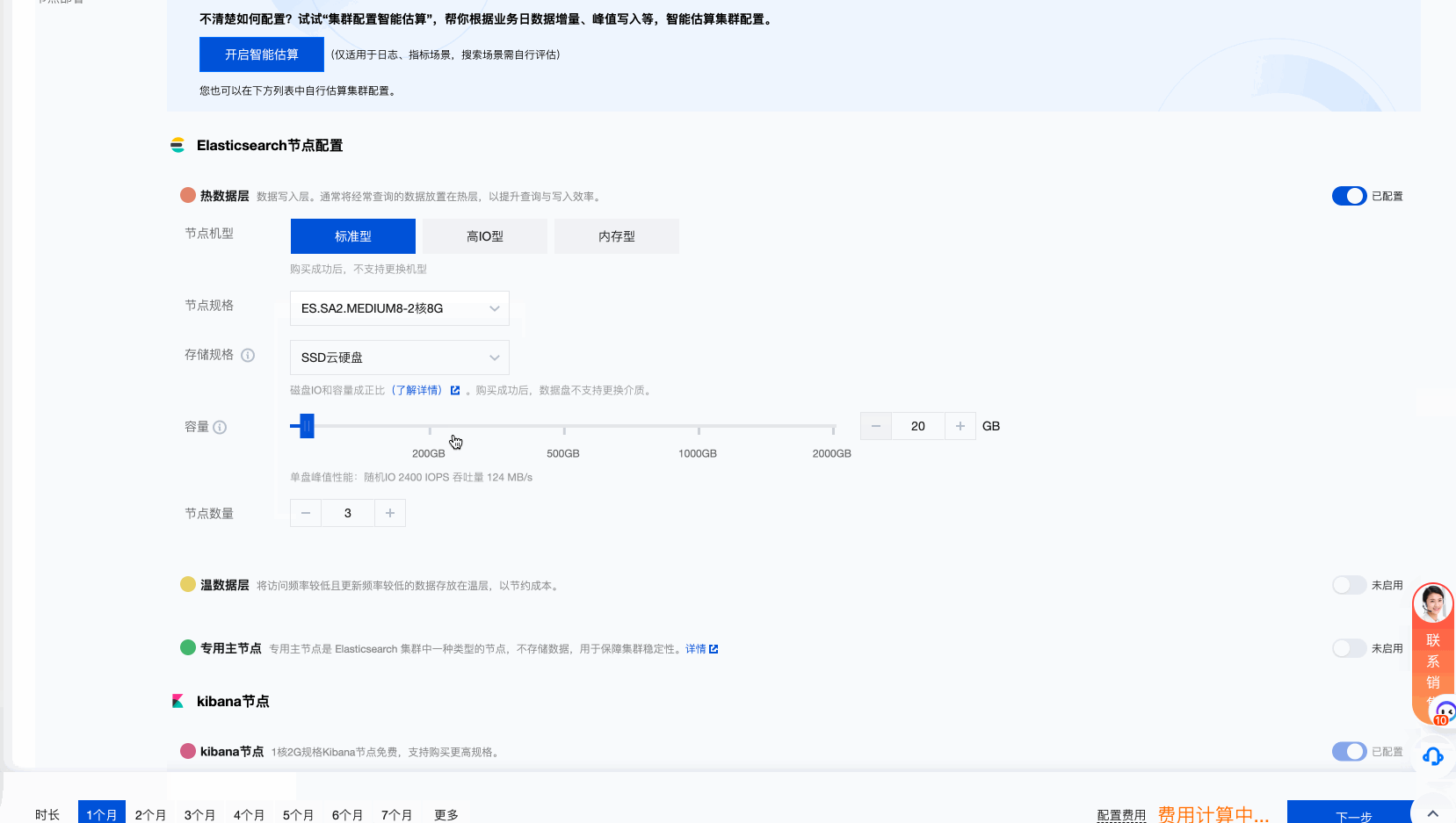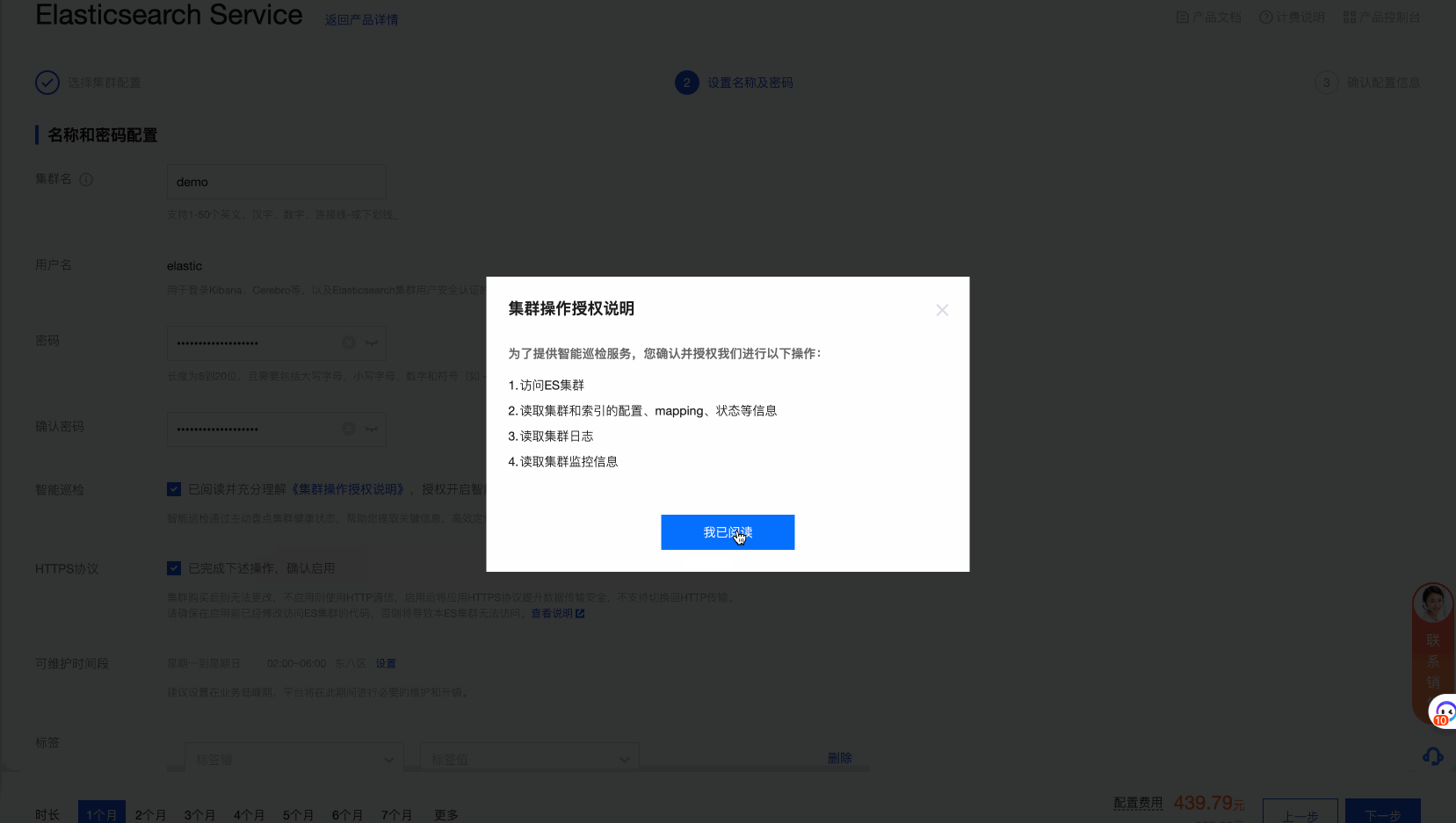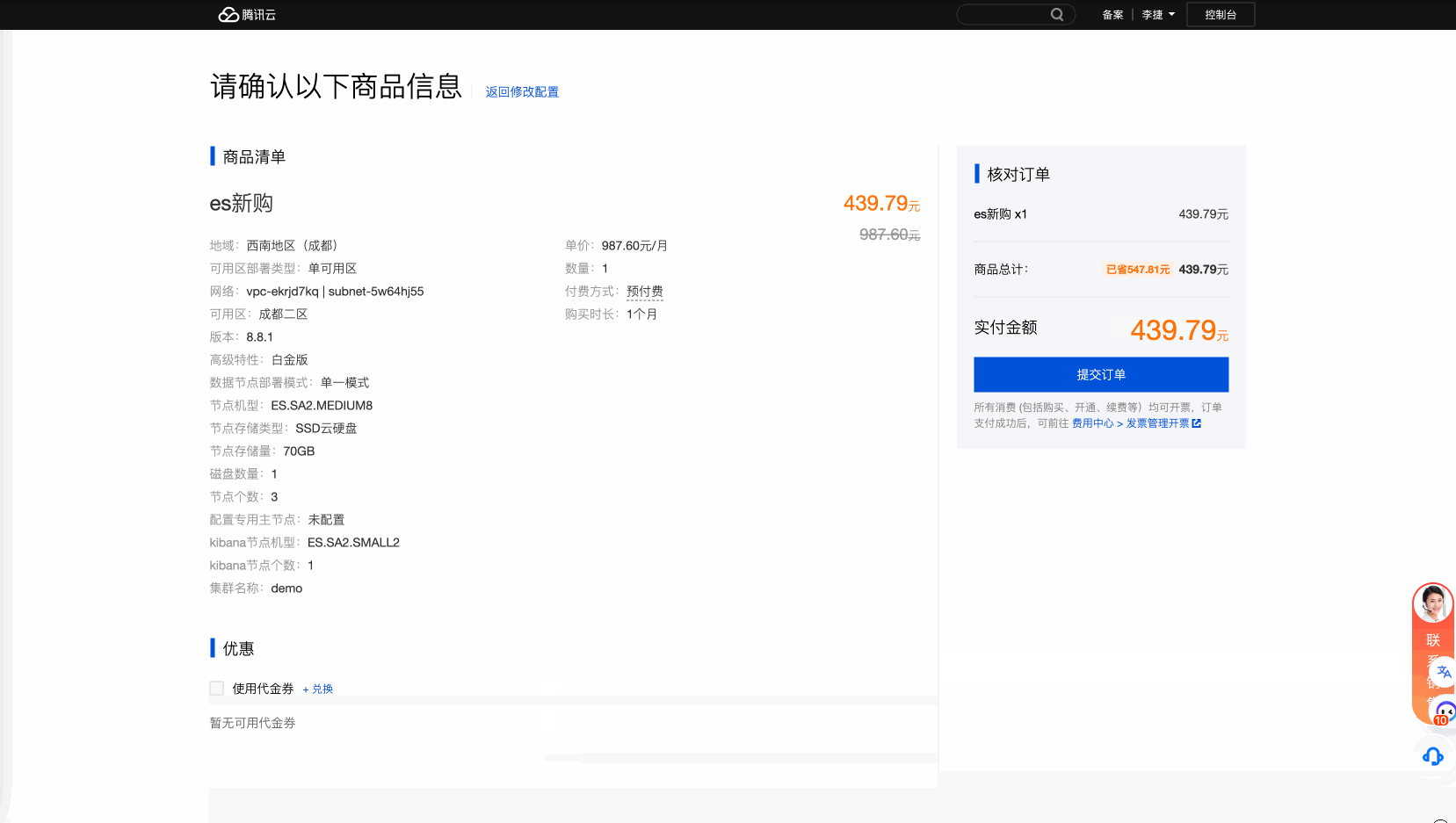
部署NLP模型
无论是执行向量搜索还是通过执行命名实体识别等NLP任务的来提取文本中的信息,都需要执行推理任务。腾讯云Elasticsearch 8.8.1最大的区别在于,您无需再搭建一套机器学习环境用于数据的处理和推理,您可以直接在Elasticsearch上,通过在管道中集成不同的Processor,灵活的处理数据。
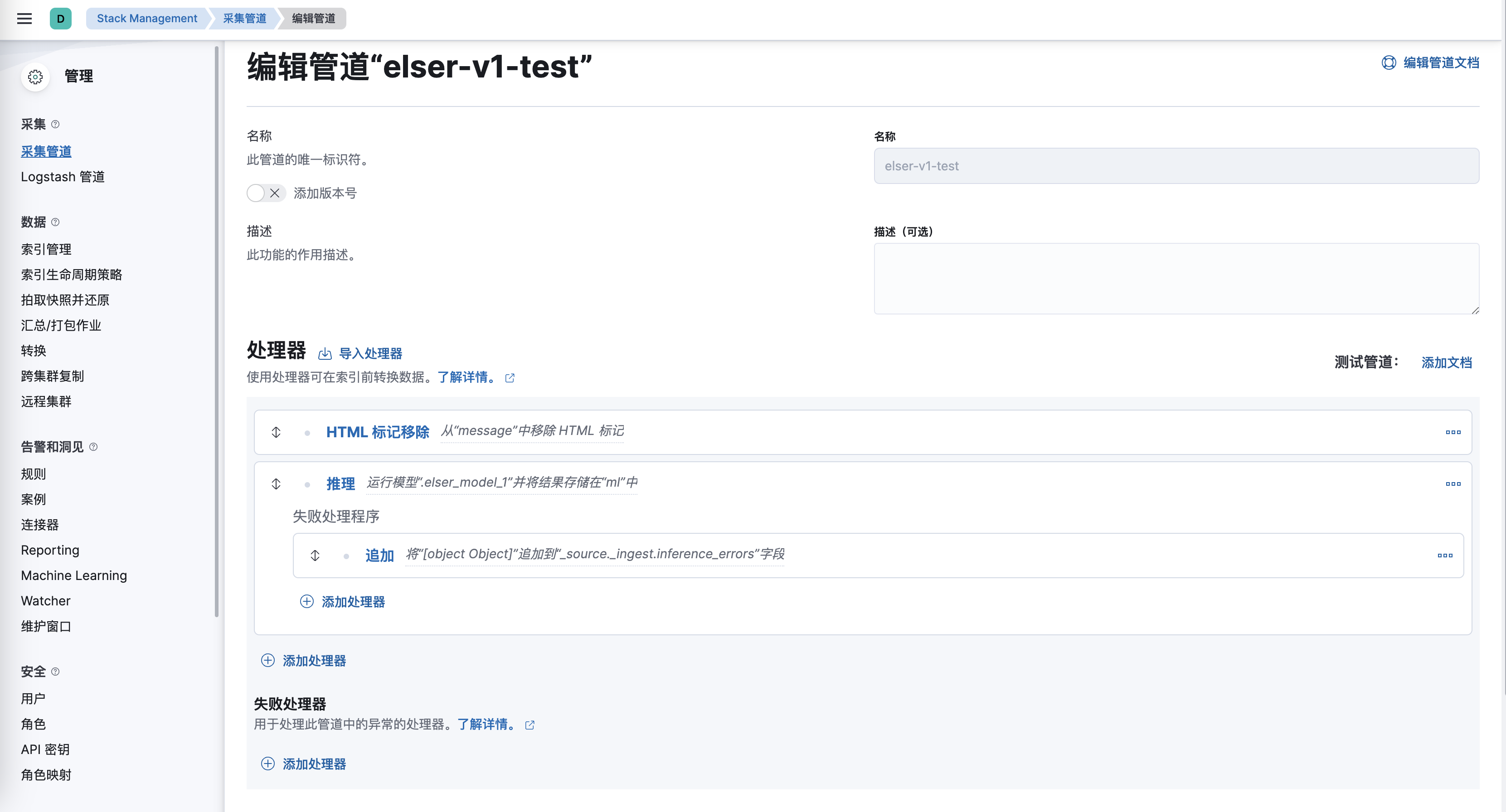
并且保证我们的查询和写入的数据都是使用同样的一个模型来处理数据。以简化模型在使用,更新和维护上的成本。

而部署的方式非常简单。我们提供了一款叫做eland的工具来实现模型的上传和部署:
eland_import_hub_model --url https://es-7cu6zx9m.public.tencentelasticsearch.com:9200 --insecure -u elastic -p changeme --hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 --task-type text_embedding --start --insecure在部署时,如果是在你自己的个人电脑上使用eland_import_hub_model(因为如果是从huggingFace上下载模型,需要互联网的访问能力),则需要提供腾讯云Elasticsearch的公网访问接口:
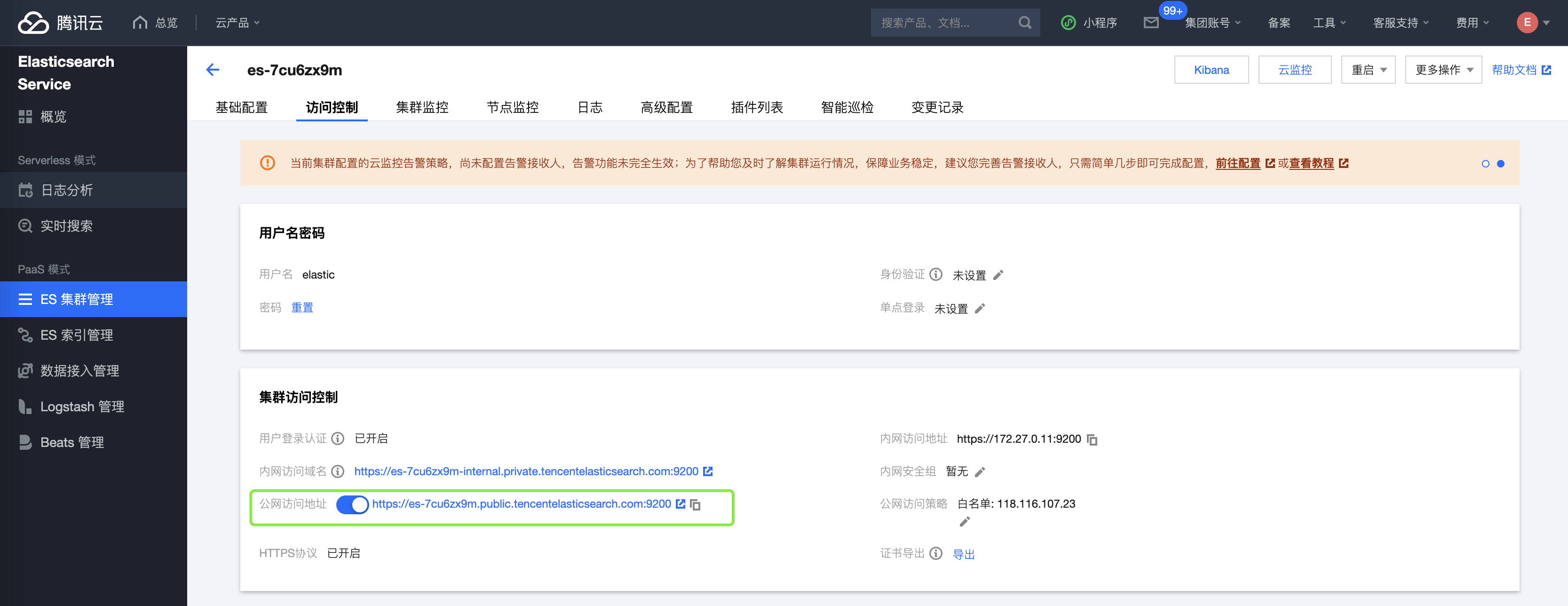
当然,你也可以在腾讯云上购买一个CVM,然后使用内网访问地址:
eland_import_hub_model --url https://172.27.0.11:9200 --insecure -u elastic -p changeme --hub-model-id canIjoin/datafun --task-type ner --start但需要注意的是,CVM上有时无法访问huggingFace或者访问超时,都可能会造成模型无法上传和部署。
与互联网访问受限类似,如果你是自己训练的自有模型,又不想发布到huggingFace,则可以参考本文 如何将本地transformer模型部署到Elasticsearch,以将本地的NLP模型上传和部署。
如果正确执行了模型的上传,你会看到如下的打印:
eland_import_hub_model --url https://es-7cu6zx9m.public.tencentelasticsearch.com:9200 --insecure -u elastic -p changeme --hub-model-id distilbert-base-uncased-finetuned-sst-2-english --task-type text_classification --start --insecure
2023-07-13 10:06:23,354 WARNING : NOTE: Redirects are currently not supported in Windows or MacOs.
2023-07-13 10:06:24,358 INFO : Establishing connection to Elasticsearch
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/elasticsearch/_sync/client/__init__.py:394: SecurityWarning: Connecting to 'https://es-7cu6zx9m.public.tencentelasticsearch.com:9200' using TLS with verify_certs=False is insecure
_transport = transport_class(
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:06:24,535 INFO : Connected to cluster named 'es-7cu6zx9m' (version: 8.8.1)
2023-07-13 10:06:24,537 INFO : Loading HuggingFace transformer tokenizer and model 'distilbert-base-uncased-finetuned-sst-2-english'
Downloading pytorch_model.bin: 100%|████████████████████████████████████████████████████████████| 268M/268M [00:19<00:00, 13.6MB/s]
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/transformers/models/distilbert/modeling_distilbert.py:223: TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
mask, torch.tensor(torch.finfo(scores.dtype).min)
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:06:48,795 INFO : Creating model with id 'distilbert-base-uncased-finetuned-sst-2-english'
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:06:48,855 INFO : Uploading model definition
0%| | 0/64 [00:00<?, ? parts/s]/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2%|█ | 1/64 [00:01<01:25, 1.36s/ parts]/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
3%|██ | 2/64 [00:01<00:53, 1.16 parts/s]/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
...
100%|██████████████████████████████████████████████████████████████████████████████████████████| 64/64 [00:45<00:00, 1.42 parts/s]
2023-07-13 10:07:34,021 INFO : Uploading model vocabulary
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:07:34,110 INFO : Starting model deployment
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/urllib3/connectionpool.py:1045: InsecureRequestWarning: Unverified HTTPS request is being made to host 'es-7cu6zx9m.public.tencentelasticsearch.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/1.26.x/advanced-usage.html#ssl-warnings
warnings.warn(
2023-07-13 10:07:41,163 INFO : Model successfully imported with id 'distilbert-base-uncased-finetuned-sst-2-english'模型管理和测试
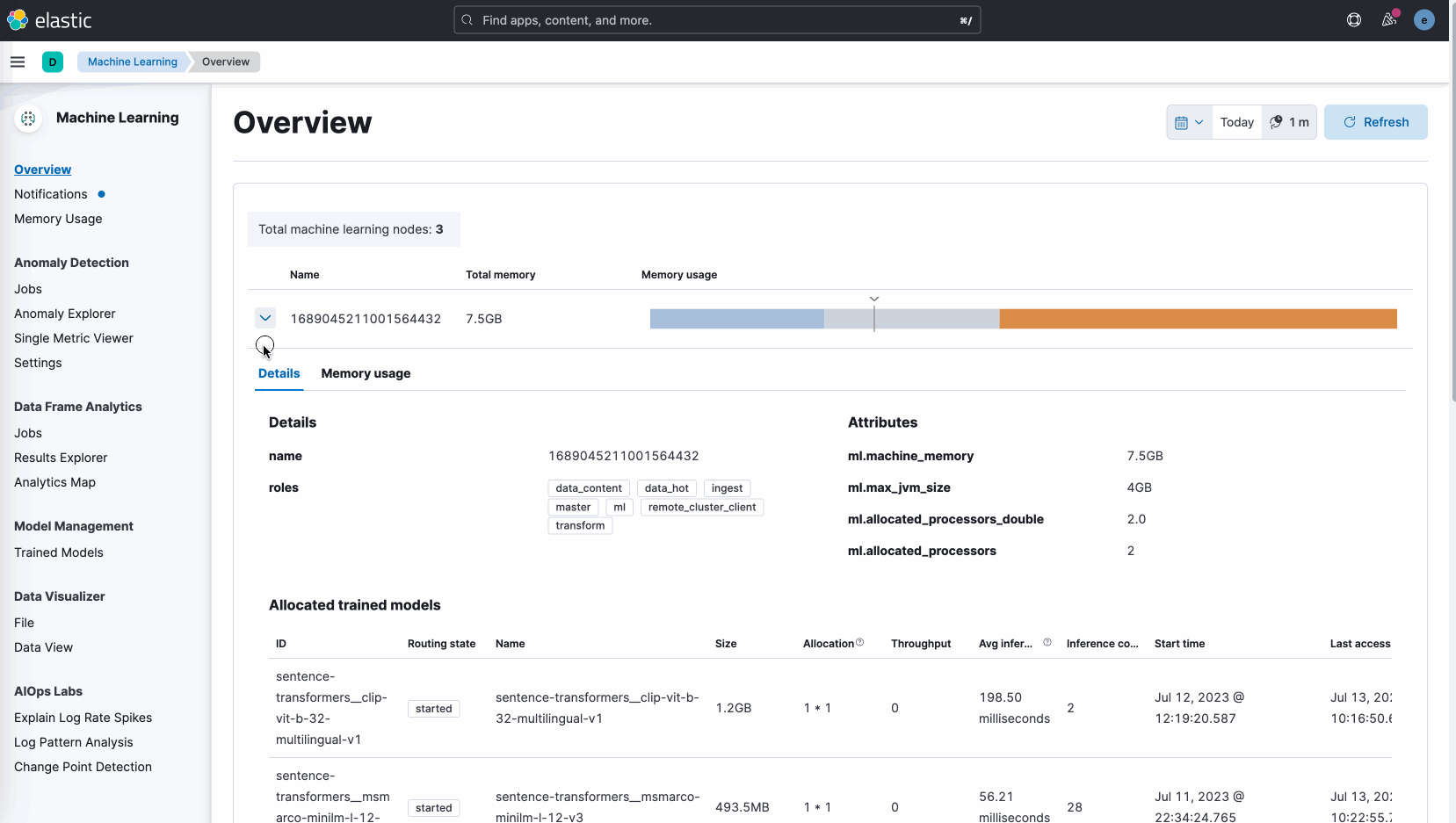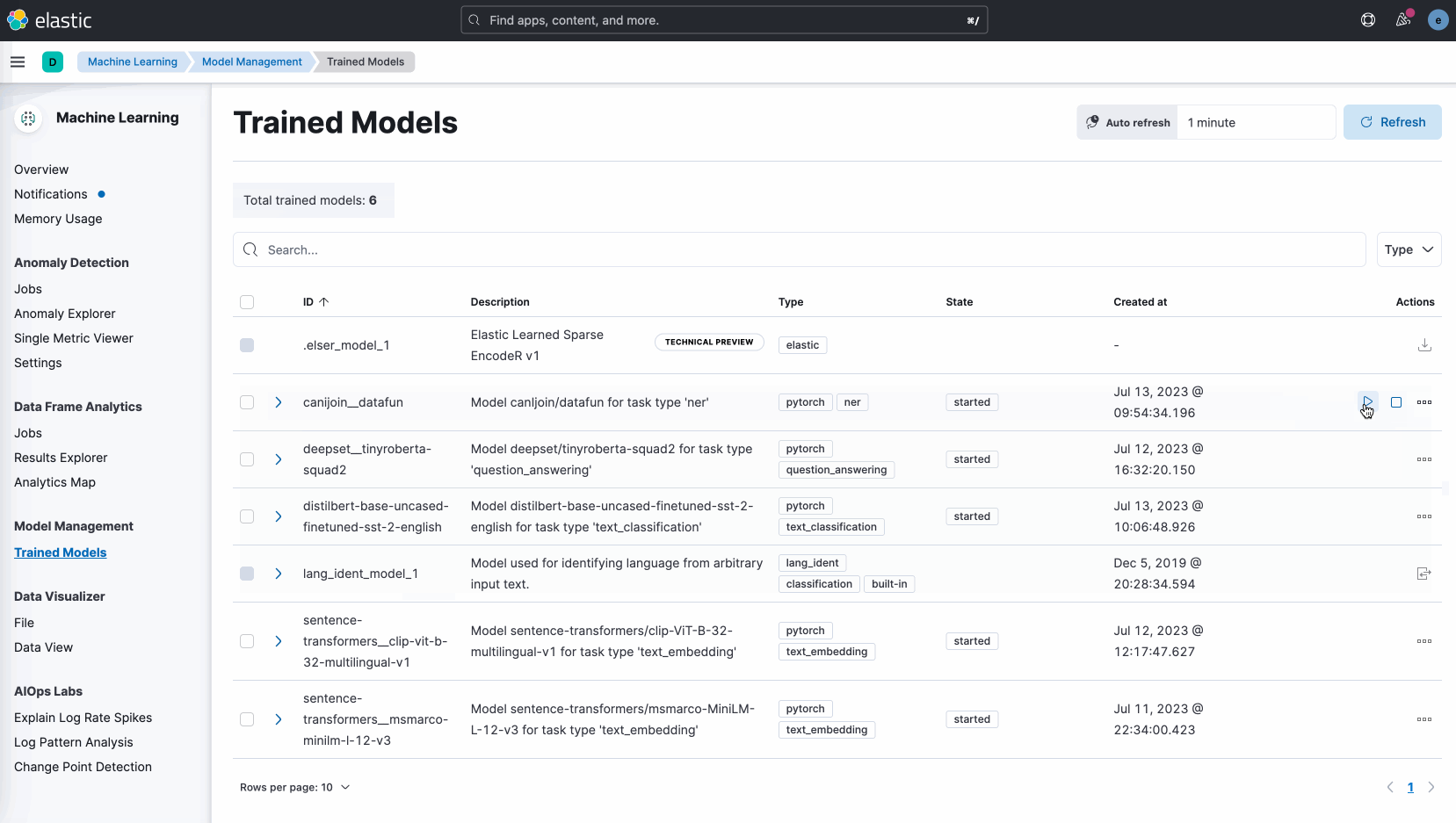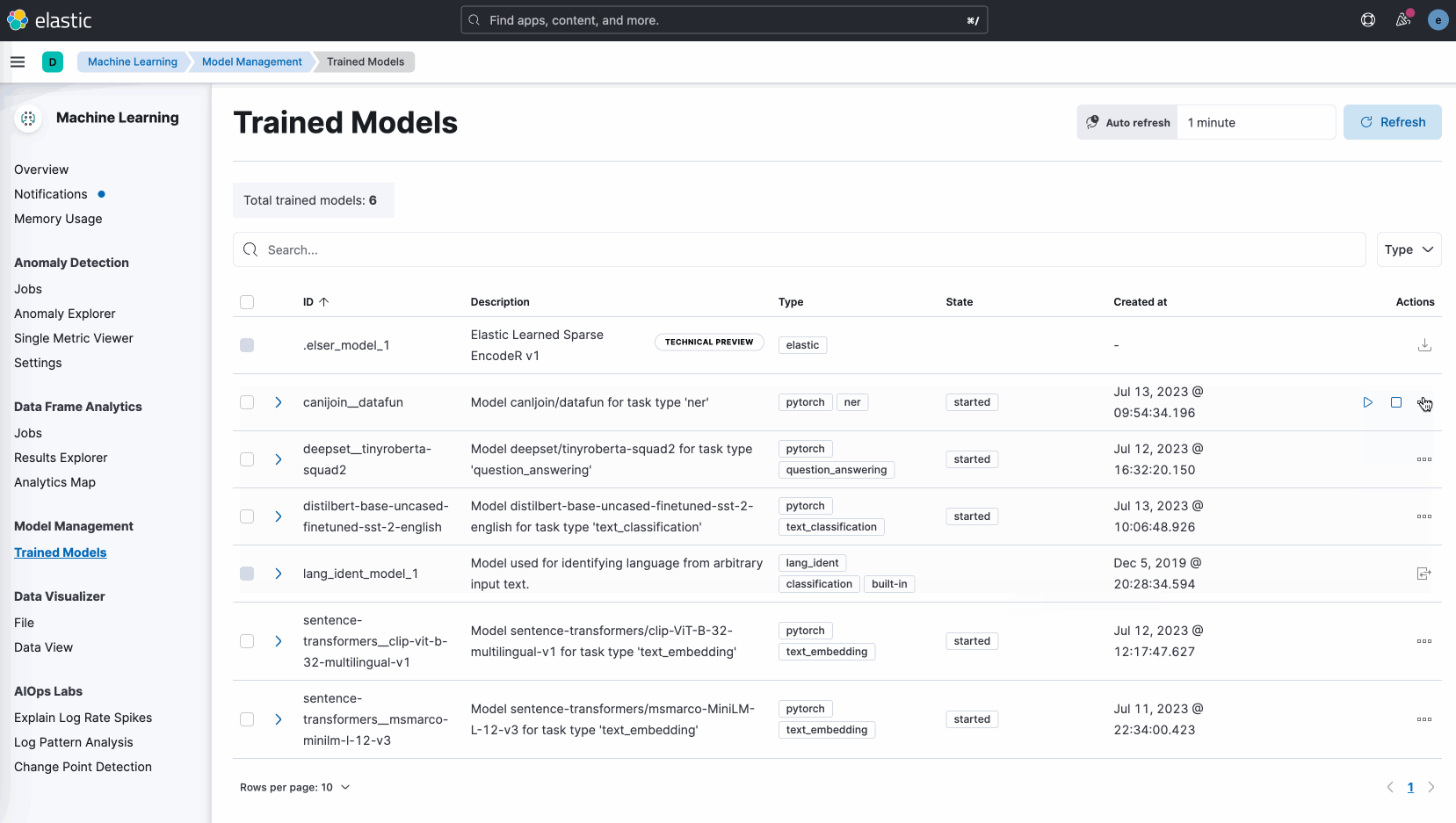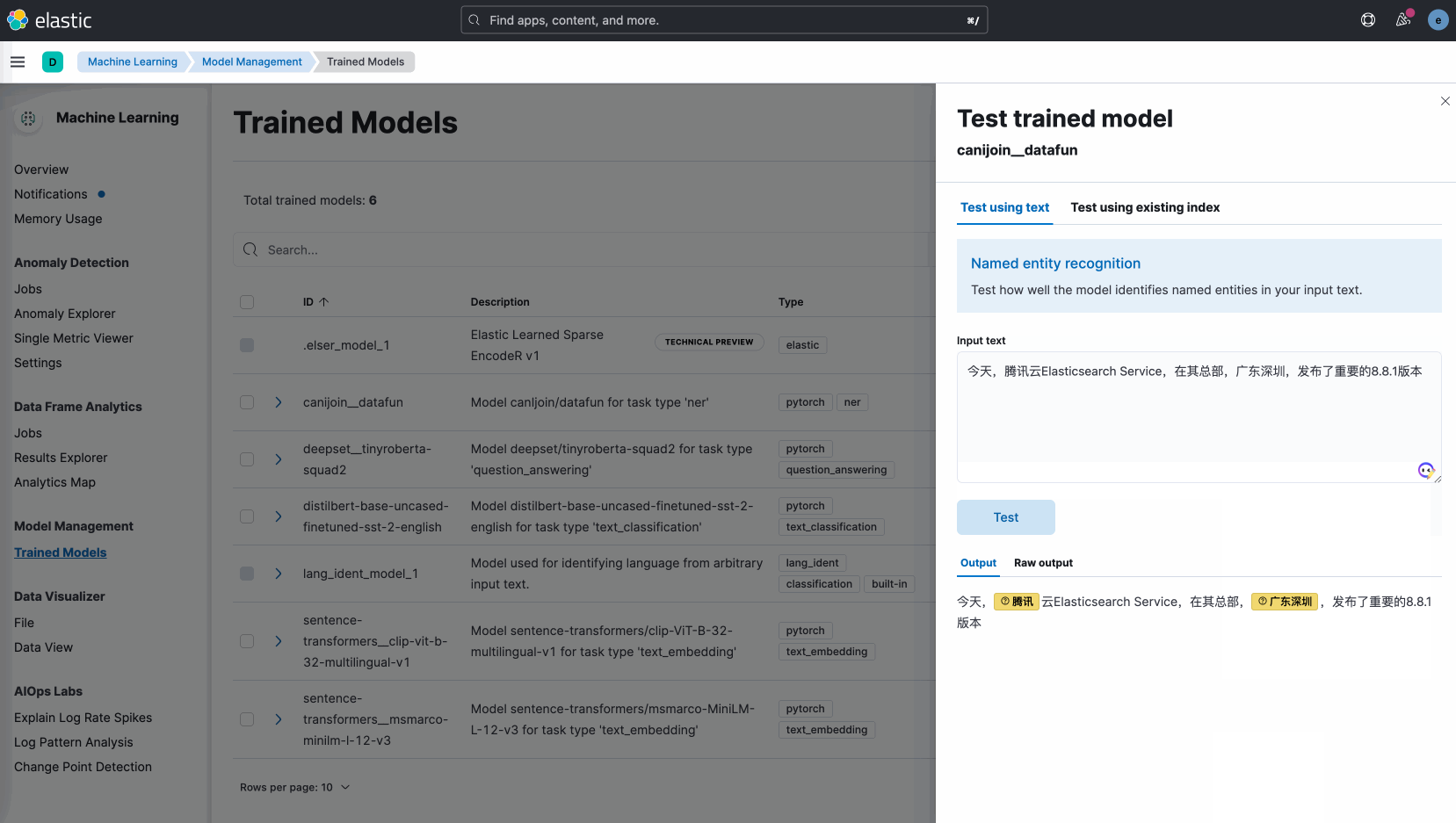
模型上传之后,您可以直接在腾讯云Elasticsearch Service的Kibana界面上管理和测试模型:
在应用中通过Elasticsearch实现NLP+Vector Search+GAI
当我们完成模型的部署和调试之后,就可以在应用中集成这种能力。比如,我们要实现一个论文的问答系统,可以按照如下的步骤实施:
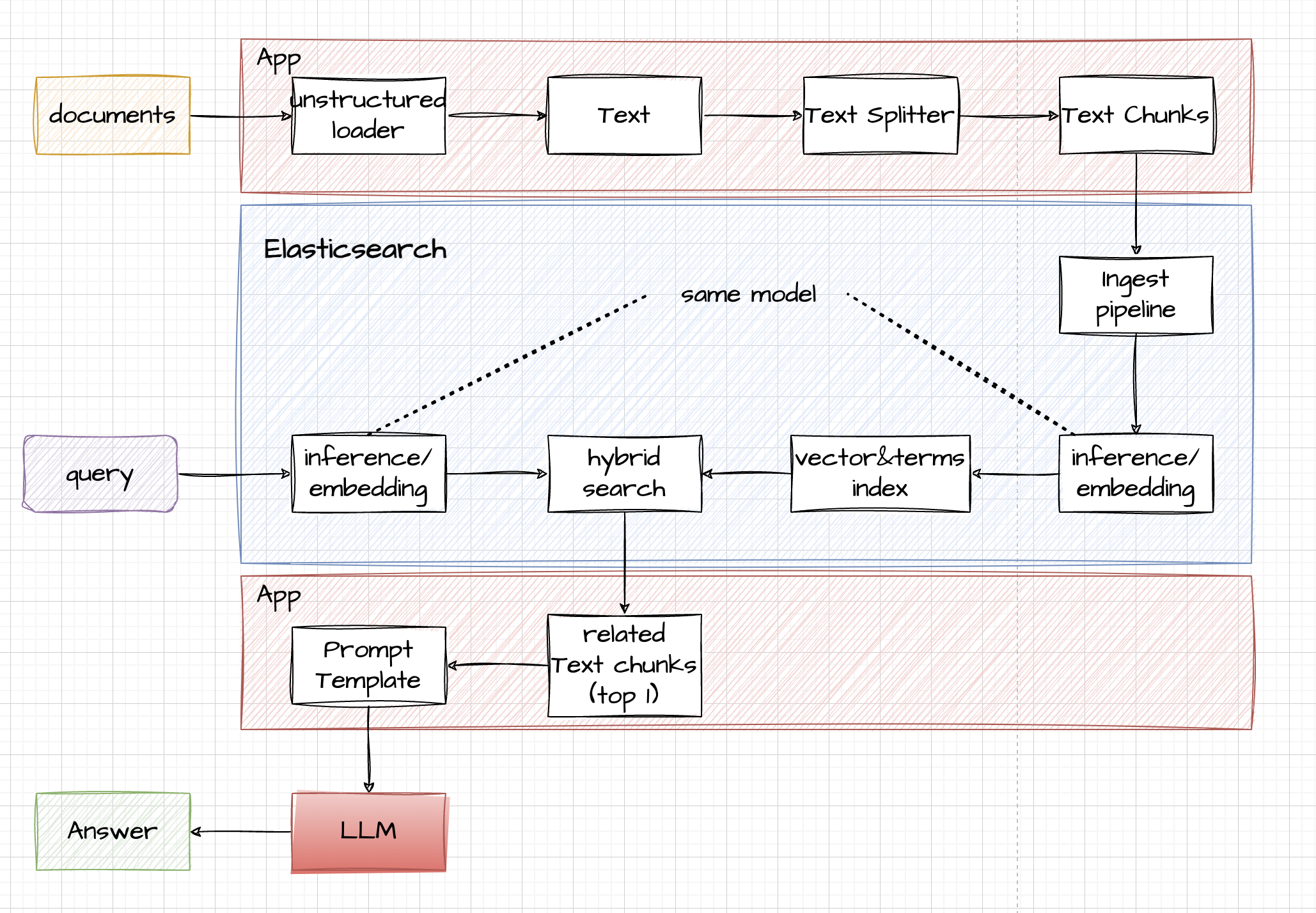
其中的一些核心代码为:
async def nlp_blog_search():
# 判断模型是否在Elasticsaerch中加载
global app_models
is_model_up_and_running(INFER_MODEL_TEXT_EMBEDDINGS)
is_model_up_and_running(INFER_MODEL_Q_AND_A)
qa_model = True if app_models.get(
INFER_MODEL_Q_AND_A) == 'started' else False
index_name = INDEX_BLOG_SEARCH
if not es.indices.exists(index=index_name):
return render_template('nlp_blog_search.html', title='Blog search', te_model_up=False,
index_name=index_name, missing_index=True, qa_model_up=qa_model)
if app_models.get(INFER_MODEL_TEXT_EMBEDDINGS) == 'started':
form = SearchBlogsForm()
# Check for method
if request.method == 'POST':
if form.validate_on_submit():
if 'filter_by_author' in request.form:
form.searchboxAuthor.data = request.form['filter_by_author']
if form.searchboxBlogWindow.data is None or len(form.searchboxBlogWindow.data) == 0:
# 对查询进行embedding转换
embeddings_response = infer_trained_model(
form.searchbox.data, INFER_MODEL_TEXT_EMBEDDINGS)
# 执行向量搜索()混合搜索、/混合搜索
search_response = knn_blogs_embeddings(embeddings_response['predicted_value'],
form.searchboxAuthor.data)
cfg = {
"question_answering": {
"question": form.searchbox.data,
"max_answer_length": 30
}
}
hits_with_answers = search_response['hits']['hits']
#使用QA模型做第一遍过滤
answers = executor.map(q_and_a, map(lambda hit: hit["_id"], hits_with_answers),
map(lambda hit: form.searchbox.data, hits_with_answers),
map(lambda hit: get_text(hit=hit), hits_with_answers))
best_answer = None
for i in range(0, len(hits_with_answers)):
hit_with_answer = hits_with_answers[i]
matched_answer = next(
(obj['result'] for obj in answers if obj["_id"] == hit_with_answer["_id"]), None)
if (matched_answer is not None):
hit_with_answer['answer'] = matched_answer
if (best_answer is None or (
matched_answer is not None and 'prediction_probability' in matched_answer and
matched_answer['prediction_probability'] > best_answer['prediction_probability'])):
best_answer = matched_answer
start_idx = matched_answer['start_offset']
end_idx = matched_answer['end_offset']
text = hits_with_answers[i]['fields']['body_content_window'][0]
text_with_highlighted_answer = Markup(''.join([text[0:start_idx - 1],
"<b>", text[start_idx -
1:end_idx],
"</b>", text[end_idx:]]))
hits_with_answers[i]['fields']['body_content_window'][0] = text_with_highlighted_answer
# 将结果交给大模型进行总结
messages = blogs_convert_es_response_to_messages(search_response,
form.searchbox.data)
# Send a request to the OpenAI API
try:
response_ai = openai.ChatCompletion.create(
engine="gpt-35-turbo",
temperature=0,
messages=messages
)
answer_openai = response_ai["choices"][0]["message"]["content"]
except RateLimitError as e:
print(e.error.message)
answer_openai = e.error.message
except APIConnectionError as e:
print(e.error.message)
answer_openai = e.error.message
return render_template('nlp_blog_search.html', title='Blog search', form=form,
search_results=hits_with_answers,
best_answer=best_answer, openai_answer=answer_openai,
query=form.searchbox.data, te_model_up=True, qa_model_up=qa_model,
missing_index=False)
else:
search_response = q_and_a(
question=form.searchbox.data, full_text=form.searchboxBlogWindow.data)
return render_template('nlp_blog_search.html', title='Blog search', form=form,
qa_results=search_response,
query=form.searchbox.data, te_model_up=True, qa_model_up=qa_model,
missing_index=False)
else:
return redirect(url_for('nlp_blog_search'))
else: # GET
return render_template('nlp_blog_search.html', title='Blog Search', form=form, te_model_up=True,
qa_model_up=qa_model, missing_index=False)
else:
return render_template('nlp_blog_search.html', title='Blog search', te_model_up=False, qa_model_up=qa_model,
model_name=INFER_MODEL_TEXT_EMBEDDINGS, missing_index=False)通过这些集成,可以实现如下效果:
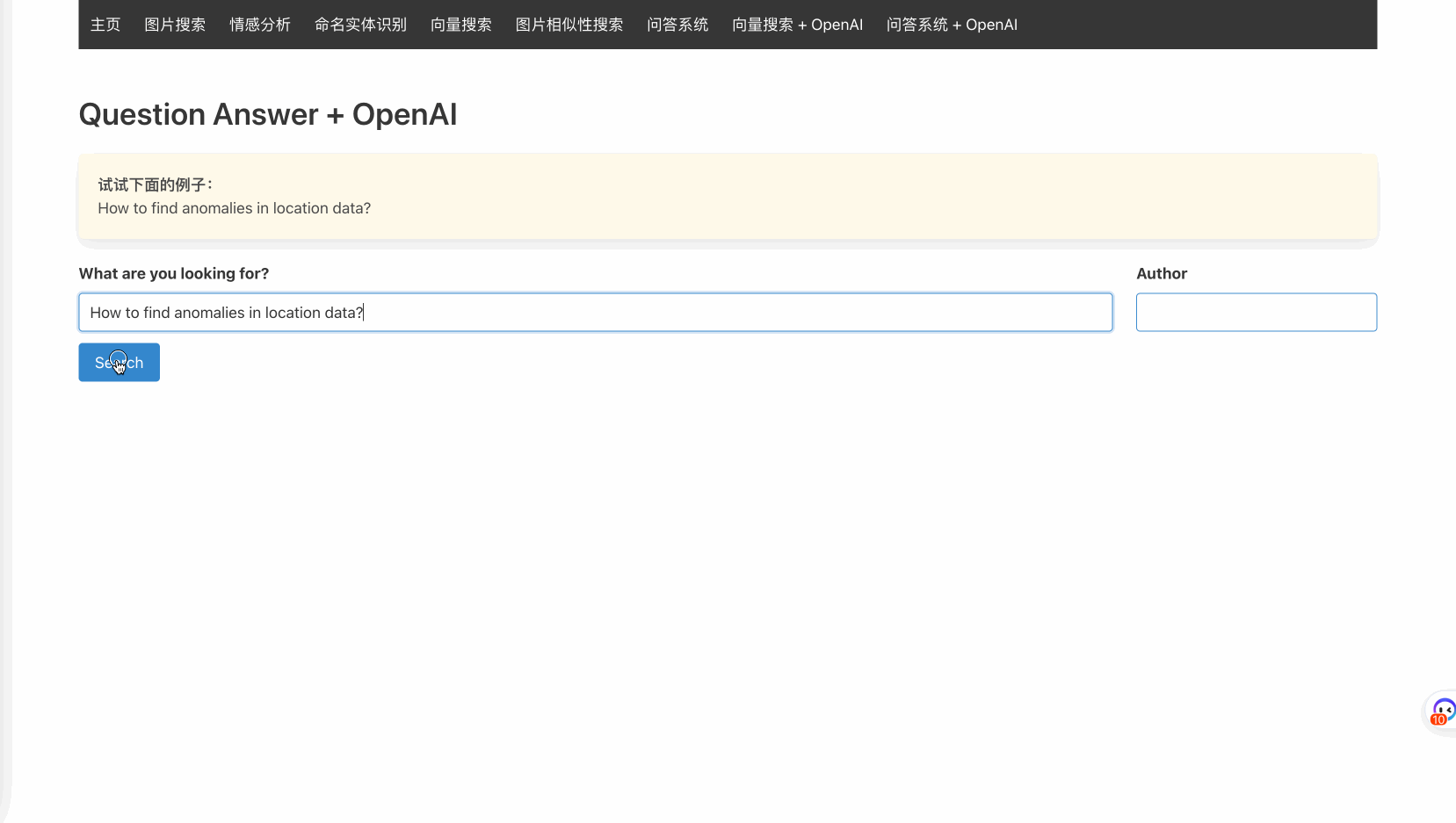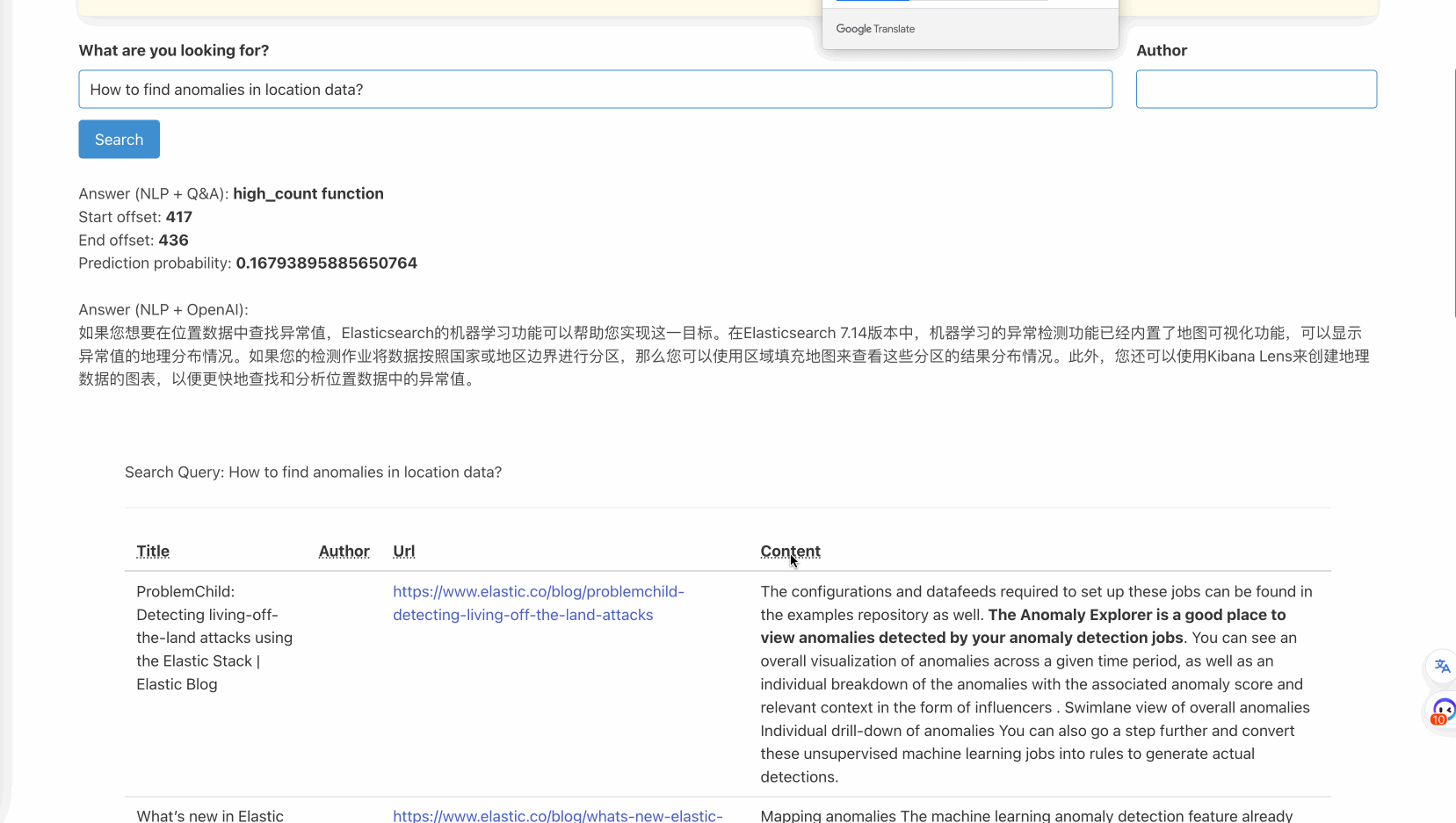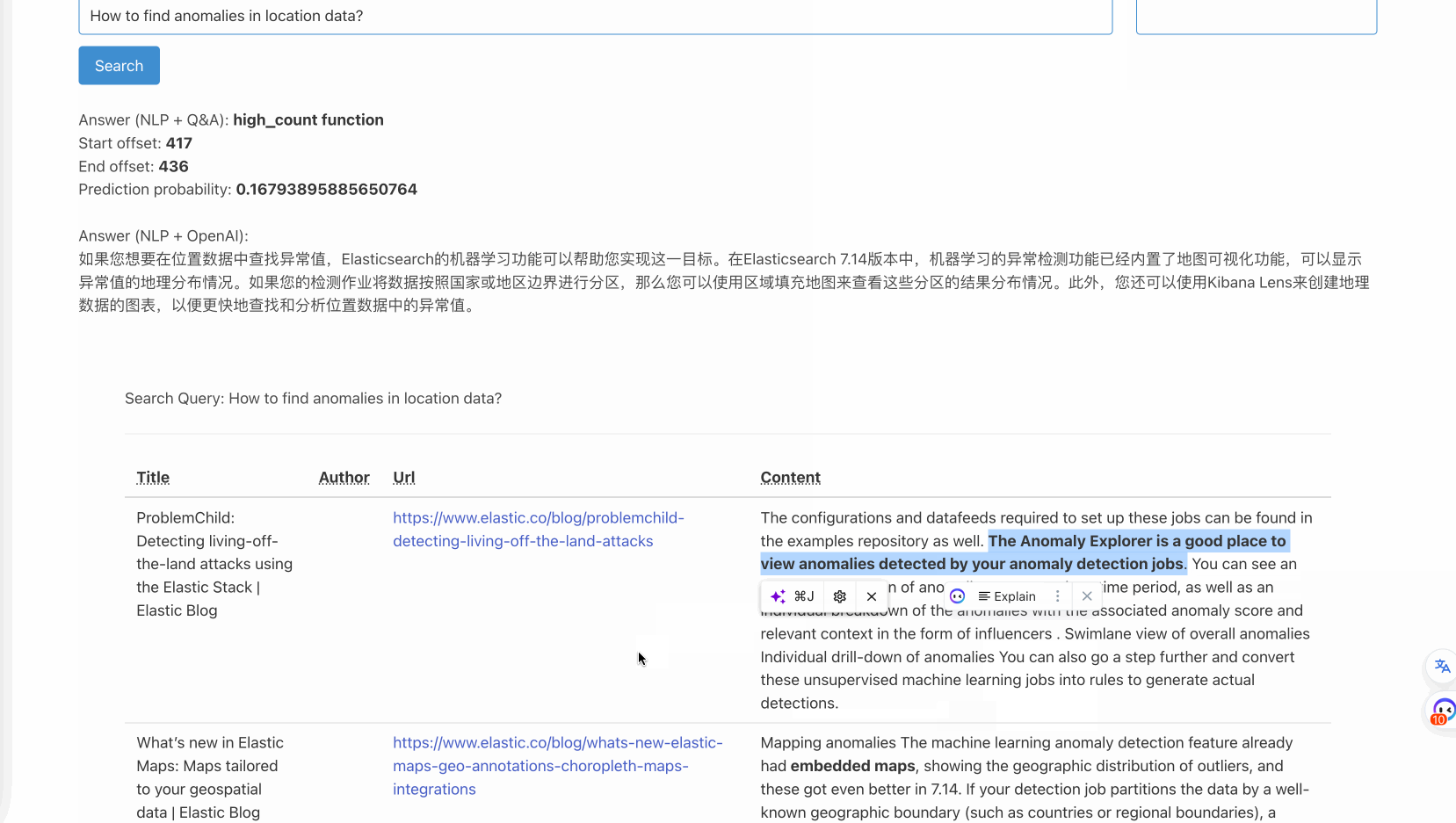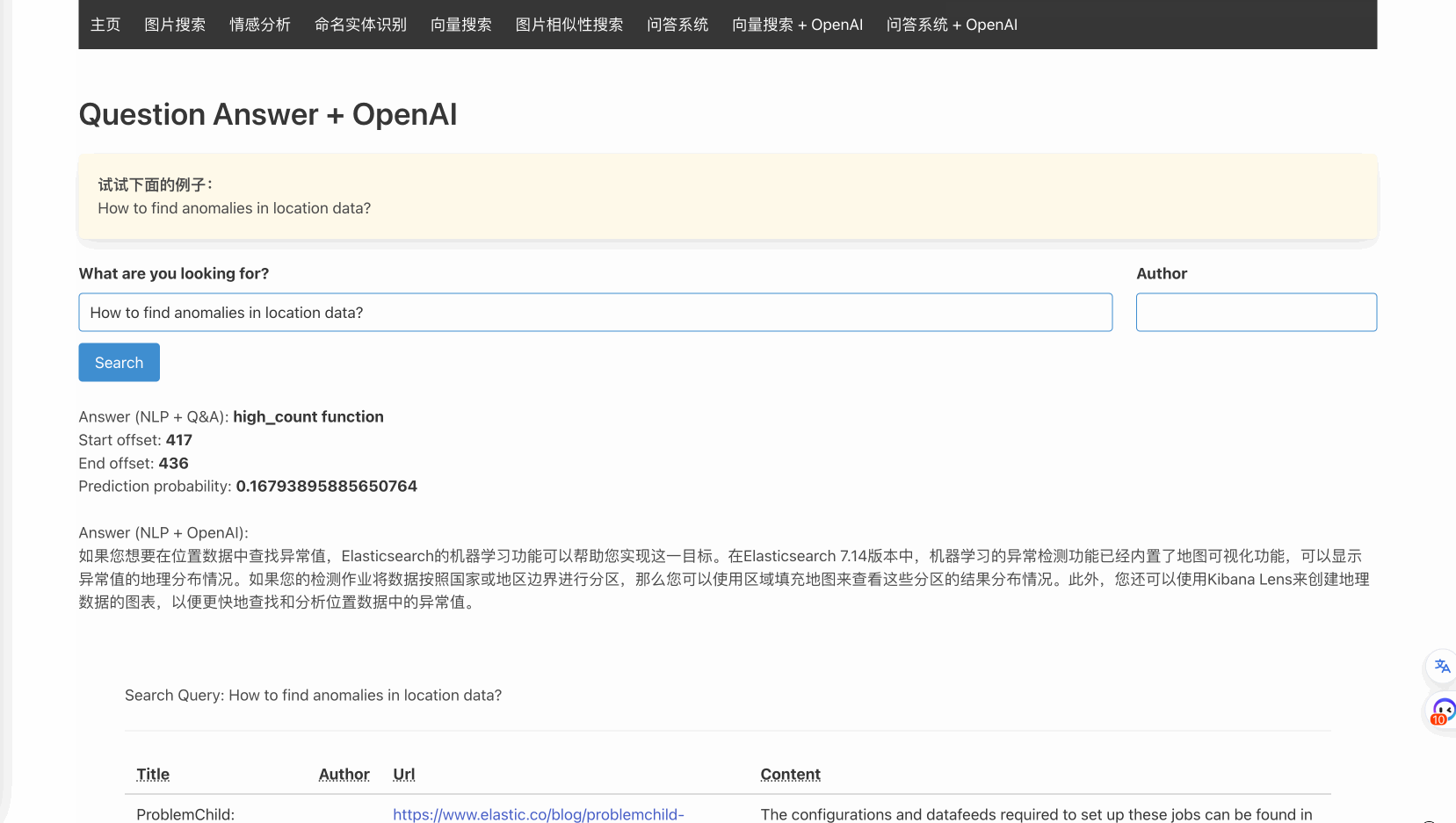
也就是说,通过腾讯云Elasticsearch 8.8.1,我们可以在应用轻松实现仅通过调用Elasticsearch的接口,即可实现向量搜索并将结果交给QnA模型来抓取重点。并进一步把内容交给大模型来进行总结。
总结
腾讯云Elasticsearch service发布的这个最新版本8.8.1,它引入了Elasticsearch Relevance Engine?(ESRE?),提供高级搜索和AI增强搜索功能。这个版本支持在单一端到端搜索与分析平台中实现自然语言处理、向量搜索以及与大模型的集成。使用该服务,你可以轻松创建集群、部署NLP模型,并进行搜索和推理任务。你还可以在Kibana界面上进行模型的管理和测试。通过腾讯云Elasticsearch,你可以实现由AI驱动的高级搜索能力,并帮助你更好地利用AI技术。赶快体验吧!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。