GEO数据库挖掘
原创
生信技能树学习之geo数据库挖掘

1、图表介绍
1.1 热图:
输入数据是数值型矩阵/数据框,颜色的变化表示数值的大小。有相关性热图和差异基因热图。
1.2 散点图、箱线图:
输入数据是一个连续型向量和一个有重复值的离散型向量。
箱线图可以表示单个基因在两组之间的表达量差异。同一个分组,必须是同一个关键词。
1.3 火山图:
Foldchange(FC):处理组表达量的平均值/对照组表达量的平均值。
logFoldchange(logFC):Foldchange取log2;
芯片差异分析,拿到的表达矩阵是已经取过log的,如果没有取,需要先取log2;
取完log2的相除,得到的结果就是 处理组表达量平均值减去对照组平均值。
如果表达量矩阵里面数值过大,可能是因为没有取log2;
logFC>0,treat > control 基因表达量上升;logFC<0,treat < control 基因表达量下降;
通常所说的上调、下调基因是指表达量显著上升/下降的基因。
1.4 PCA 主成分分析
图上的点代表样本(中心点除外),点与点之间的距离代表样本与样本之间的差异。
同一分组是否聚成一簇(组内重复好);中心点之间是否有距离(组间差别大)
用于“预实验”,简单查看组建是否有差异。
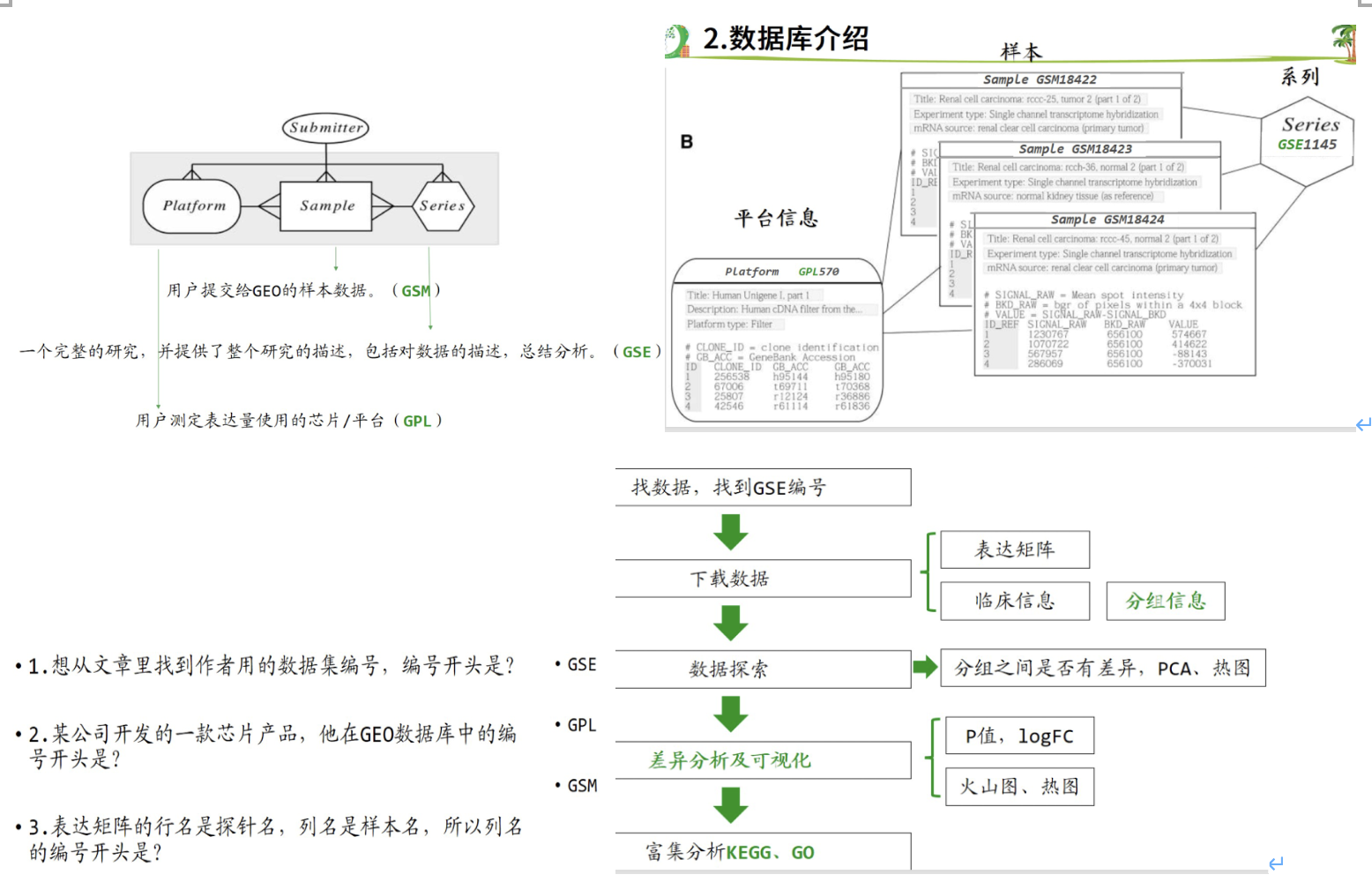
2、GEO背景介绍及表达芯片分析思路
2.1 表达数据实验设计
实验目的:通过基因表达量数据的差异分析和富集分析来解释生物学现象。 WGCNA 共表达网络分析
有差异的材料--差异基因--找功能/找关联--解释差异,缩小基因范围。
2.2 表达矩阵
需要探针ID转换和分组信息
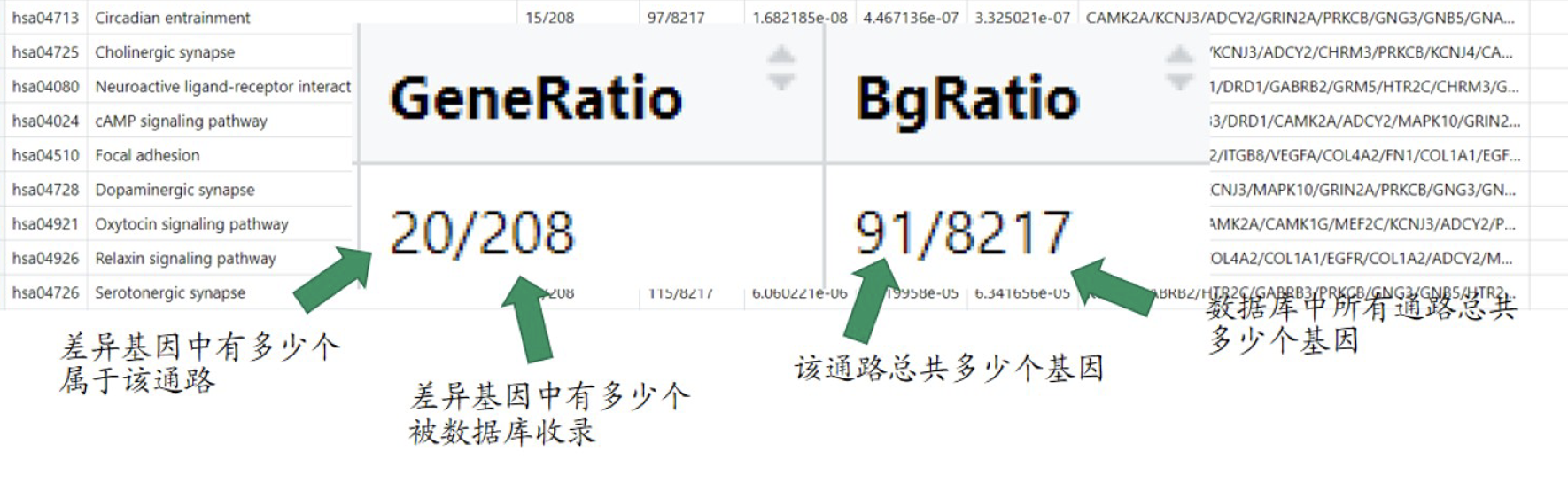
2.3 富集分析知识补充
输入数据是差异基因的entrezid。 衡量每个通路中的基因在差异基因中是否足够多
symbol是常说的基因名;entrezid 富集分析指定用,两者并非一一对应,损失/增加部分基因属于正常。
2.4 数据库介绍
3、代码分析流程
3.1 数据分析之前先安装R包
options("repos"="https://mirrors.ustc.edu.cn/CRAN/") ##这个地方的镜像可以设置为清华镜像
if(!require("BiocManager")) install.packages("BiocManager",update = F,ask = F)
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/")
cran_packages <- c('tidyr',
'tibble',
'dplyr',
'stringr',
'ggplot2',
'ggpubr',
'factoextra',
'FactoMineR',
'devtools',
'cowplot',
'patchwork',
'basetheme',
'paletteer',
'AnnoProbe',
'ggthemes',
'VennDiagram',
'tinyarray')
Biocductor_packages <- c('GEOquery',
'hgu133plus2.db',
'ggnewscale',
"limma",
"impute",
"GSEABase",
"GSVA",
"clusterProfiler",
"org.Hs.eg.db",
"preprocessCore",
"enrichplot")
for (pkg in cran_packages){
if (! require(pkg,character.only=T) ) {
install.packages(pkg,ask = F,update = F)
require(pkg,character.only=T)
}
}
for (pkg in Biocductor_packages){
if (! require(pkg,character.only=T) ) {
BiocManager::install(pkg,ask = F,update = F)
require(pkg,character.only=T)
}
}
#前面的所有提示和报错都先不要管。主要看这里
for (pkg in c(Biocductor_packages,cran_packages)){
require(pkg,character.only=T)
}
#没有任何提示就是成功了,如果有warningxx包不存在,用library检查一下。
#library报错,就单独安装。3.2 实战代码
#实战代码有很多注意事项, 请不要不听课直接跑代码。。
3.2.1 GEO数据库 芯片数据获取
#数据下载
rm(list = ls())
library(GEOquery)
#先去网页确定是否是表达芯片数据,不是的话不能用本流程。 Expression profiling by array 可以,
# 如果是高通量测序结果不能用,转录组测序,单细胞测序结果是高通量测序结果。
gse_number = "GSE56649"
eSet <- getGEO(gse_number, destdir = '.', getGPL = F)
###getGEO网页下载数据后读取到R,如果代码下载不下来,就可以去网页下载下来,然后放到工作目录下边。
class(eSet) ##返回结果是列表
length(eSet) ##返回结果是1,提示这是一个长度为1的列表
eSet = eSet[[1]] ##提取列表
class(eSet)
#(1)提取表达矩阵exp
exp <- exprs(eSet)
dim(exp)
exp[1:4,1:4]
#检查矩阵是否正常,如果是空的就会报错,空的和有负值的、有异常值的矩阵需要处理原始数据。
#如果表达矩阵为空,大多数是转录组数据,不能用这个流程(后面另讲)。
#自行判断是否需要log、一般boxplot 后的纵坐标范围在0-20之间,如果过高就需要取log
exp = log2(exp+1)
boxplot(exp)
#(2)提取临床信息
pd <- pData(eSet)
#(3)让exp列名与pd的行名顺序完全一致
p = identical(rownames(pd),colnames(exp));p
if(!p) exp = exp[,match(rownames(pd),colnames(exp))]
###分组信息来自临床信息,分组信息需要与表达矩阵列名一一对应,
###临床信息需要和表达矩阵列一一对应
#(4)提取芯片平台编号
gpl_number <- eSet@annotation;gpl_number
###在右上角环境中打开eSet,看annotation前面是@就用@提取,annotation前面是$,就用$提取。
save(gse_number,pd,exp,gpl_number,file = "step1output.Rdata")? ## 流程,getGEO函数下载数据→转换格式→提取表达矩阵→提取分组信息→确认分组对应
###如果网络下载太慢,可以用以下的代码:
rm(list = ls())
library(AnnoProbe)
#先去网页确定是否是表达芯片数据,不是的话不能用本流程。
gse_number = "GSE56649"
eSet = geoChina(gse_number,destdir=".")3.2.2 确定分组以及探针注释的获取
# Group(实验分组)和ids(探针注释)
rm(list = ls())
load(file = "step1output.Rdata")
library(stringr)
# 标准流程代码是二分组,多分组数据的分析后面另讲
# 生成Group向量的三种常规方法,三选一,选谁就把第几个逻辑值写成T,另外两个为F。
## 如果三种办法都不适用,可以继续往后写else if
if(F){
# 1.Group----
# 第一种方法,有现成的可以用来分组的列
Group = pd$`disease state:ch1`
}else if(F){
# 第二种方法,自己生成
Group = c(rep("RA",times=13),
rep("control",times=9))
Group = rep(c("RA","control"),times = c(13,9)) ### 两个Group意思是一样的,运行一个就行
}else if(T){
# 第三种方法,使用字符串处理的函数获取分组
Group=ifelse(str_detect(pd$source_name_ch1,"control"),
"control",
"RA")
}
factor(Group) 自动生成levels,levels顺序以首字母排序为准,参考水平将在做差异分析时,被设为对照组
### 水平 因子里面的取值,顺序重要,第一个位置上的是参考水平
### 应该让对照组在前,处理组在后,保证差异分析不反
factor(Group) #水平按照首字母顺序排序,有一半可能是错误的,按照下面的代码写
factor(Group,levels = c("control","RA")) #水平按照代码里写的顺序排。
# 需要把Group转换成因子,并设置参考水平,指定levels,对照组在前,处理组在后。
### 因子正文与levels不对应时会产生NA,两者必须是对应的关系。
Group = factor(Group,levels = c("control","RA"))
Group
#2.探针注释的获取-----------------
#捷径
library(tinyarray)
find_anno(gpl_number) #打出找注释的代码
ids <- AnnoProbe::idmap('GPL570')
#四种方法,方法1里找不到就从方法2找,以此类推。
#方法1 BioconductorR包(最常用)
gpl_number
### http://www.bio-info-trainee.com/1399.html
if(!require(hgu133plus2.db))BiocManager::install("hgu133plus2.db")
library(hgu133plus2.db)
ls("package:hgu133plus2.db")
ids <- toTable(hgu133plus2SYMBOL)
head(ids)
# 方法2 读取GPL网页的表格文件,按列取子集
##https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL570
if(F){
#注:表格读取参数、文件列名不统一,活学活用,有的表格里没有symbol列,也有的GPL平台没有提供注释表格
b = read.delim("GPL570-55999.txt",
check.names = F,
comment.char = "#")
colnames(b)
ids2 = b[,c("ID","Gene Symbol")]
colnames(ids2) = c("probe_id","symbol")
k1 = ids2$symbol!="";table(k1)
k2 = !str_detect(ids2$symbol,"///");table(k2)
ids2 = ids2[ k1 & k2,]
# ids = ids2
}
# 方法3 官网下载注释文件并读取
##http://www.affymetrix.com/support/technical/byproduct.affx?product=hg-u133-plus
# 方法4 自主注释
#https://mp.weixin.qq.com/s/mrtjpN8yDKUdCSvSUuUwcA
save(exp,Group,ids,gse_number,file = "step2output.Rdata")3.2.3 PCA和热图绘制
rm(list = ls())
load(file = "step1output.Rdata")
load(file = "step2output.Rdata")
#输入数据:exp和Group
#Principal Component Analysis
#http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/112-pca-principal-component-analysis-essentials
# 1.PCA 图----
dat=as.data.frame(t(exp))
library(FactoMineR)
library(factoextra)
dat.pca <- PCA(dat, graph = FALSE)
pca_plot <- fviz_pca_ind(dat.pca,
geom.ind = "point", # show points only (nbut not "text")
col.ind = Group, # color by groups
palette = c("#00AFBB", "#E7B800"),
addEllipses = TRUE, # Concentration ellipses
legend.title = "Groups"
)
pca_plot
save(pca_plot,file = "pca_plot.Rdata")
# 2.top 1000 sd 热图----
cg=names(tail(sort(apply(exp,1,sd)),1000))
n=exp[cg,]
# 直接画热图,对比不鲜明
library(pheatmap)
annotation_col=data.frame(group=Group)
rownames(annotation_col)=colnames(n)
pheatmap(n,
show_colnames =F,
show_rownames = F,
annotation_col=annotation_col
)
# 按行标准化,把行与行之间的差别去掉,只展示行内部的差别。
pheatmap(n,
show_colnames =F,
show_rownames = F,
annotation_col=annotation_col,
scale = "row",
breaks = seq(-3,3,length.out = 100)
)
### breaks 设置色带分布范围的函数
### 画出来的图,上面的同一个分组的聚类是被分开的,要设置成不分开的
cluster_cols = F ###这样就不会设置聚类了
dev.off()
# 关于scale的进一步学习:zz.scale.R关于scale的进一步学习
上面的因为行名是基因,所以对行进行标准化,是为了让基因在不同的样本中进行标准化。
require(stats)
# 1.示例数据
x <- matrix(sample(1:30,30), ncol = 6)
rownames(x) = paste0("gene",1:5)
colnames(x) = paste0("sample",1:6)
# 2.标准化
scale(x) #函数只能按列标准化,但是我们需要按行
x
y = t(scale(t(x)))
# 3.标准化前后,某gene的表达量点图比较,大小趋势不变。
par(mfrow = c(2,2))
plot(x[1,])
plot(y[1,])
plot(x[2,])
plot(y[2,])去重方式
Q:为什么要去重,各种去重方法对结果有什么影响 A:去重是因为行名中不能有重复值,所以需要先将基因名去重,然后再将这个基因名作为行名。各种去重方法没有好坏的定论,一般都可以使用
探针注释:多个基因对应一个基因。
rm(list = ls())
load("step2output.Rdata")
#保留最大值
exp2 = exp[ids$probe_id,]
identical(ids$probe_id,rownames(exp2))
ids = ids[order(rowSums(exp2),decreasing = T),]
ids = ids[!duplicated(ids$symbol),];nrow(ids)
# 拿这个ids去inner_join
#求平均值
rm(list = ls())
load("step2output.Rdata")
exp3 = exp[ids$probe_id,]
rownames(exp3) = ids$symbol
exp3[1:4,1:4]
exp4 = limma::avereps(exp3)
# 此时拿到的exp4已经是一个基因为行名的表达矩阵,直接差异分析,不再需要inner_join 3.2.4 差异分析
只需要表达矩阵和分组信息
在这个部分才进行id转换,不过也可以提到热图之前,不过在求差异基因后,再进行ID转换,热图可以直接画上调和下调基因了
rm(list = ls())
load(file = "step2output.Rdata")
#差异分析,用limma包来做
#需要表达矩阵和Group,不需要改,适合二分组的数据
### 方法一
library(limma)
design=model.matrix(~Group)
fit=lmFit(exp,design)
fit=eBayes(fit)
deg=topTable(fit,coef=2,number = Inf)
###方法二
dfanalysis = function(exp,Group){
design=model.matrix(~Group)
fit=lmFit(exp,design)
fit=eBayes(fit)
deg=topTable(fit,coef=2,number = Inf)
return(deg)
}
a = dfanalysis(exp,Group)
#为deg数据框添加几列
#1.加probe_id列,把行名变成一列
library(dplyr)
deg <- mutate(deg,probe_id=rownames(deg))
#2.加上探针注释,,
### 多个探针对应一个基因时去重:1.随机去重;2.保留行和/行平均值最大的探针;3.取多个探针的平均值
ids = ids[!duplicated(ids$symbol),]
## ids =distinct(ids,symbol,.keep _ all = T) 随机去重
#其他去重方式在zz.去重方式.R
deg <- inner_join(deg,ids,by="probe_id")
nrow(deg)
#3.加change列,标记上下调基因
logFC_t=1
P.Value_t = 0.05
k1 = (deg$P.Value < P.Value_t)&(deg$logFC < -logFC_t)
k2 = (deg$P.Value < P.Value_t)&(deg$logFC > logFC_t)
deg <- mutate(deg,change = ifelse(k1,"down",ifelse(k2,"up","stable")))
table(deg$change)
#4.加ENTREZID列,用于富集分析(symbol转entrezid,然后inner_join)
library(clusterProfiler)
library(org.Hs.eg.db)
s2e <- bitr(deg$symbol,
fromType = "SYMBOL",
toType = "ENTREZID",
OrgDb = org.Hs.eg.db)#人类
#其他物种http://bioconductor.org/packages/release/BiocViews.html#___OrgDb
deg <- inner_join(deg,s2e,by=c("symbol"="SYMBOL"))
save(Group,deg,logFC_t,P.Value_t,gse_number,file = "step4output.Rdata")3.3 绘图
Q1:画火山图需要什么数据 A1:需要差异分析后的数据,即DESeq2、edgeR、limma分析后的数据,需要使用logFC、P.Value。需要加载ggplot2包
Q2:如何画基因的相关性图? A2:需要加载corrplot包,然后筛选自己想要的基因和它在各组的表达量,M = cor(t(exp[g,])),具体看代码
Q3:如何拼图? A3:如果使用ggplot2画出来的图,可以加载patchwork包,如果是其他,可以使用plot_grid()函数,具体如下
3.3.1. 火山图
rm(list = ls())
load(file = "step1output.Rdata")
load(file = "step4output.Rdata")
library(dplyr)
library(ggplot2)
dat = deg[!duplicated(deg$symbol),]
p <- ggplot(data = dat,
aes(x = logFC,
y = -log10(P.Value))) +
geom_point(alpha=0.4, size=3.5,
aes(color=change)) +
scale_color_manual(values=c("blue", "grey","red"))+
geom_vline(xintercept=c(-logFC_t,logFC_t),lty=4,col="black",linewidth=0.8) +
geom_hline(yintercept = -log10(P.Value_t),lty=4,col="black",linewidth=0.8) +
theme_bw()
p
for_label <- dat%>%
filter(symbol %in% c("HADHA","LRRFIP1")) #在火山图上标记出来自己想要的基因名字
volcano_plot <- p +
geom_point(size = 3, shape = 1, data = for_label) +
ggrepel::geom_label_repel(
aes(label = symbol),
data = for_label,
color="black"
)
volcano_plot3.3.2.差异基因热图----
load(file = 'step2output.Rdata')
# 表达矩阵行名替换
exp = exp[dat$probe_id,]
rownames(exp) = dat$symbol
if(T){
#取前10上调和前10下调
library(dplyr)
d
at2 = dat %>%
filter(change!="stable") %>%
arrange(logFC)
cg = c(head(dat2$symbol,10),
tail(dat2$symbol,10))
}else{
#全部差异基因
cg = dat$symbol[dat$change !="stable"]
length(cg)
}
n=exp[cg,]
dim(n)
#差异基因热图
library(pheatmap)
annotation_col=data.frame(group=Group)
rownames(annotation_col)=colnames(n)
heatmap_plot <- pheatmap(n,show_colnames =F,
scale = "row",
#cluster_cols = F,
annotation_col=annotation_col,
breaks = seq(-3,3,length.out = 100)
)
heatmap_plot
#拼图
library(patchwork)
library(ggplotify)
volcano_plot +heatmap_plot$gtable
### 或者 volcano_plot +as.ggplot(heatmap_plot)
# f <- volcano_plot +as.ggplot(heatmap_plot)
# ggsave(f,filename = "./pin.pdf",width = 15,height = 15)3.3.3 感兴趣基因的相关性----
library(corrplot)
g = deg$symbol[1:10] # 换成自己感兴趣的基因
##或者用这个 g = sample(deg$symbol[1:500],10) # 这里是随机取样,注意换成自己感兴趣的基因
g
M = cor(t(exp[g,])) ##相关系数矩阵
pheatmap(M)
library(paletteer)
my_color = rev(paletteer_d("RColorBrewer::RdYlBu")) ##16进制颜色编码
my_color = colorRampPalette(my_color)(10)
corrplot(M, type="upper",
method="pie",
order="hclust",
col=my_color,
tl.col="black",
tl.srt=45)
library(cowplot)
cor_plot <- recordPlot()3.3.4 拼图
load("pca_plot.Rdata")
plot_grid(pca_plot,cor_plot,
volcano_plot,heatmap_plot$gtable)
dev.off()3.3.5 保存
pdf("deg.pdf",width= 10 , height = 10) ###数字随意更改,改成适合图片大小的数字
plot_grid(pca_plot,cor_plot,
volcano_plot,heatmap_plot$gtable)
dev.off()如何在差异分析后再确认自己的上下调基因有没有反?
a = deg$symbol[1]
boxplot(exp[a,]~Group)
deg$logFC[1]3.3.6 GO 富集分析----
rm(list = ls())
load(file = 'step4output.Rdata')
library(clusterProfiler)
library(ggthemes)
library(org.Hs.eg.db)
library(dplyr)
library(ggplot2)
library(stringr)
library(enrichplot)#(1)输入数据
gene_up = deg$ENTREZID[deg$change == 'up']
gene_down = deg$ENTREZID[deg$change == 'down']
gene_diff = c(gene_up,gene_down)
#(2)富集
#以下步骤耗时很长,设置了存在即跳过
f
= paste0(gse_number,"_GO.Rdata")
if(!file.exists(f)){
ego <- enrichGO(gene = gene_diff,
OrgDb= org.Hs.eg.db,
ont = "ALL",
readable = TRUE)
ego_BP <- enrichGO(gene = gene_diff,
OrgDb= org.Hs.eg.db,
ont = "BP",
readable = TRUE)
#ont参数:One of "BP", "MF", and "CC" subontologies, or "ALL" for all three.
save(ego,ego_BP,file = f)
}
load(f)
#(3)可视化
#条带图
barplot(ego)
barplot(ego, split = "ONTOLOGY", font.size = 10,
showCategory = 5) +
facet_grid(ONTOLOGY ~ ., space = "free_y",scales = "free_y")
#气泡图
dotplot(ego)
dotplot(ego, split = "ONTOLOGY", font.size = 10,
showCategory = 5) +
facet_grid(ONTOLOGY ~ ., space = "free_y",scales = "free_y")
#(3)展示top通路的共同基因,要放大看。
#gl 用于设置下图的颜色
gl = deg$logFC
names(gl)=deg$ENTREZID
#Gene-Concept Network,要放大看
cnetplot(ego,
#layout = "star",
color.params = list(foldChange = gl),
showCategory = 3)
3.3.7 KEGG pathway analysis
#上调、下调、差异、所有基因
#(1)输入数据
gene_up = deg[deg$change == 'up','ENTREZID']
gene_down = deg[deg$change == 'down','ENTREZID']
gene_diff = c(gene_up,gene_down)
#(2)对上调/下调/所有差异基因进行富集分析
f2 = paste0(gse_number,"_KEGG.Rdata")
if(!file.exists(f2)){
kk.up <- enrichKEGG(gene = gene_up,
organism = 'hsa')
kk.down <- enrichKEGG(gene = gene_down,
organism = 'hsa')
kk.diff <- enrichKEGG(gene = gene_diff,
organism = 'hsa')
save(kk.diff,kk.down,kk.up,file = f2)
}
load(f2)
#(3)看看富集到了吗?https://mp.weixin.qq.com/s/NglawJgVgrMJ0QfD-YRBQg
table(kk.diff@result$p.adjust<0.05)
table(kk.up@result$p.adjust<0.05)
table(kk.down@result$p.adjust<0.05)
#(4)双向图# 富集分析所有图表默认都是用p.adjust,富集不到可以退而求其次用p值,在文中说明即可
source("kegg_plot_function.R")
g_kegg <- kegg_plot(kk.up,kk.down)
g_kegg
#g_kegg +scale_y_continuous(labels = c(2,0,2,4,6))3.3.8 string蛋白互作
rm(list = ls())
load("step4output.Rdata")
gene_up= deg[deg$change == 'up','symbol']
gene_down=deg[deg$change == 'down','symbol']
gene_diff = c(gene_up,gene_down)
# 1.制作string的输入数据
write.table(gene_diff,
file="diffgene.txt",
row.names = F,
col.names = F,
quote = F)
# 从string网页获得string_interactions.tsv
# 2.准备cytoscape的输入文件
p = deg[deg$change != "stable",
c("symbol","logFC")]
head(p)
write.table(p,
file = "deg.txt",
sep = "\t",
quote = F,
row.names = F)
# string_interactions.tsv是网络文件
# deg.txt是属性表格3.3.9.能看懂的资料越来越多
# GSEA:https://www.yuque.com/docs/share/a67a180f-dd2b-4f6f-96c2-68a4b86fe862?
## 富集分析学习更多:http://yulab-smu.top/clusterProfiler-book/index.html#
弦图:https://www.yuque.com/xiaojiewanglezenmofenshen/dbwkg1/dgs65p#
GOplot:https://mp.weixin.qq.com/s/LonwdDhDn8iFUfxqSJ2Wew
# 网上的资料和宝藏无穷无尽,学好R语言慢慢发掘~
4、问题数据和常见错误分析
数据提交者的错:1.表达矩阵是空的;2.表达矩阵不完整;3.表达矩阵被标准化过;4.表达矩阵游错误或异常值
自己的错误:1.用芯片流程分析转录组数据;2.忘记log或多余log;3.分组错误;4.探针注释错误;5.id转换用错物种
不可抗力:找不到探针注释;数据有错又找不到原始数据;找不到想要的实验设计
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。