零基础手把手带你阅读Redis源代码系列-ZSet底层原理详解(跳表SkipList)
原创
零基础手把手带你阅读Redis源代码系列-ZSet底层原理详解(跳表SkipList)
原创
之前就说了要来西索Redis,现在来辣!
本文的部分内容参考自《小林Coding》,部分地方根据源代码进行剖析。
Redis源码地址:https://github.com/redis/redis.git
ZSet
观其面
和Set类似,但是新增了一个排序字段。
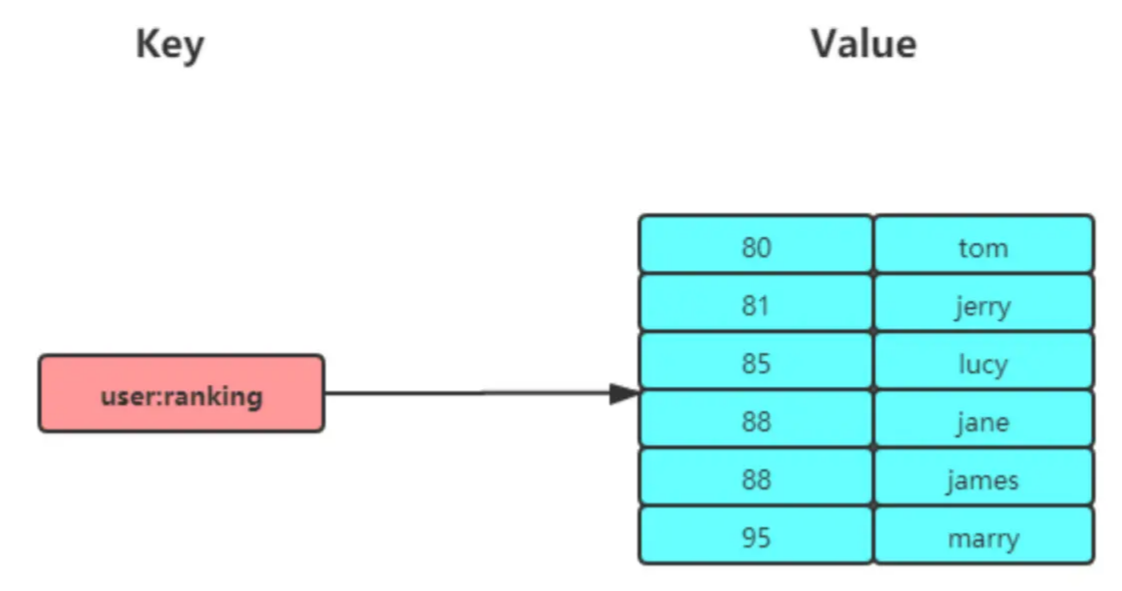
常用操作
# 往有序集合key中加入带分值元素
ZADD key score member [[score member]...]
# 往有序集合key中删除元素
ZREM key member [member...]
# 返回有序集合key中元素member的分值
ZSCORE key member
# 返回有序集合key中元素个数
ZCARD key
# 为有序集合key中元素member的分值加上increment
ZINCRBY key increment member
# 正序获取有序集合key从start下标到stop下标的元素
ZRANGE key start stop [WITHSCORES]
# 倒序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES]
# 返回有序集合中指定分数区间内的成员,分数由低到高排序。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
# 返回指定成员区间内的成员,按字典正序排列, 分数必须相同。
ZRANGEBYLEX key min max [LIMIT offset count]
# 返回指定成员区间内的成员,按字典倒序排列, 分数必须相同
ZREVRANGEBYLEX key max min [LIMIT offset count]运算操作
# 并集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZUNIONSTORE destkey numberkeys key [key...]
# 交集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZINTERSTORE destkey numberkeys key [key...]应用场景
排行榜
点赞数量和内容ID相关联,最后再根据ID去查,或者异步更新也可以
为什么不存全部数据?部分数据会修改,那么可能导致value伪重复,加大了业务复杂度
电话、姓名区间排序
使用有序集合的 ZRANGEBYLEX 或 ZREVRANGEBYLEX 可以帮助我们实现电话号码或姓名的排序,我们以 ZRANGEBYLEX (返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
注意:不要在分数不一致的 SortSet 集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因为获取的结果会不准确。
1、电话排序
我们可以将电话号码存储到 SortSet 中,然后根据需要来获取号段:
> ZADD phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
> ZADD phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
> ZADD phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3获取所有号码:
> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"获取 132 号段的号码:
> ZRANGEBYLEX phone [132 (133
1) "13200111100"
2) "13210414300"
3) "13252110901"获取132、133号段的号码:
> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"2、姓名排序
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6获取所有人的名字:
> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"获取名字中大写字母A开头的所有人:
> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"获取名字中大写字母 C 到 Z 的所有人:
> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"究其身
cv完了,现在来看看源码。
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数小于
128个,并且每个元素的值小于64字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构; - 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
listpack和压缩列表在之前讲List的时候就已经讲过了,这里主要来讲一讲跳表。
跳表
跳表是从链表的结构上面改进出来的,可以说是多层链表

图中头节点有 L0~L2 三个头指针,分别指向了不同层级的节点,然后每个层级的节点都通过指针连接起来:
- L0 层级共有 5 个节点,分别是节点1、2、3、4、5;
- L1 层级共有 3 个节点,分别是节点 2、3、5;
- L2 层级只有 1 个节点,也就是节点 3 。
下面我们来看看实际的结构
如上图,记录头节点和尾节点(图上没有,后面细说),我们封装在一起,成了整个链跳表体
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头节点、尾节点
unsigned long length; // 跳表长度
int level; // 最高的层级
} zskiplist;那么节点又是怎么定义的呢?如果让我来做的话,我会用给一个数组来表示下一个节点(详细看上图),不过也确实是这样做的
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; // 内容
double score; // 用于排序的字段,我们称之为权重
struct zskiplistNode *backward; //后向指针 前继
// level 数组中的每一个元素代表跳表的一层,也就是由 zskiplistLevel 结构体表示,比如 leve[0] 就表示第一层,leve[1] 就表示第二层。
struct zskiplistLevel {
struct zskiplistNode *forward; // 每层的前向指针 后继
unsigned long span; // 跨度
} level[];
} zskiplistNode;这里对前向和后向进行一个解释:
其实就是一个双链表,不过后续指针是一个指针数组,前向指针是后继,后向指针是前继那么这个跨度是啥?
跨度
用于计算这个节点在跳表中的排位。具体怎么做的呢?因为跳表中的节点都是按序排列的,那么计算某个节点排位的时候,从头节点点到该结点的查询路径上,将==沿途访问过==的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
没懂?看上图,把这个节点前面的阶段求个前缀和,他们的结果就是跨度,也就是当前节点的编号。
跳表的创建
// 定义最高层数 Redis 7.0 定义为 32,Redis 5.0 定义为 64,Redis 3.0 定义为 32
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1; // 初始只有一层
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL); // 创建一个节点,节点创建在后面讲
// 把每一层都初始化
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
// 初始化跳表
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}节点创建
/* Create a skiplist node with the specified number of levels.
* The SDS string 'ele' is referenced by the node after the call. */
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}跳表的释放
/* Free a whole skiplist. */
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
zfree(zsl->header); // 释放头节点
// 在初始化的时候直接指向了第一个元素
while(node) {
next = node->level[0].forward;
// 释放每一个节点
zslFreeNode(node);
node = next;
}
zfree(zsl);
}
/* Free the specified skiplist node. The referenced SDS string representation
* of the element is freed too, unless node->ele is set to NULL before calling
* this function. */
void zslFreeNode(zskiplistNode *node) {
sdsfree(node->ele); // 释放member
zfree(node); // 释放节点
}
/* Free an sds string. No operation is performed if 's' is NULL. */
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1])); // s_free就是z_free
}
// 呃呃呃,这不解释了
void zfree(void *ptr) {
#ifndef HAVE_MALLOC_SIZE
void *realptr;
size_t oldsize;
#endif
if (ptr == NULL) return;
#ifdef HAVE_MALLOC_SIZE
update_zmalloc_stat_free(zmalloc_size(ptr));
free(ptr);
#else
realptr = (char*)ptr-PREFIX_SIZE;
oldsize = *((size_t*)realptr);
update_zmalloc_stat_free(oldsize+PREFIX_SIZE);
free(realptr);
#endif
}跳表节点查询过程
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
- 如果当前节点的权重 < 要查找的权重时,跳表就会访问该层上的下一个节点。
- 如果当前节点的权重 = 要查找的权重时,并且当前节点的 SDS 类型数据 < 要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
举个例子,下图有个 3 层级的跳表。
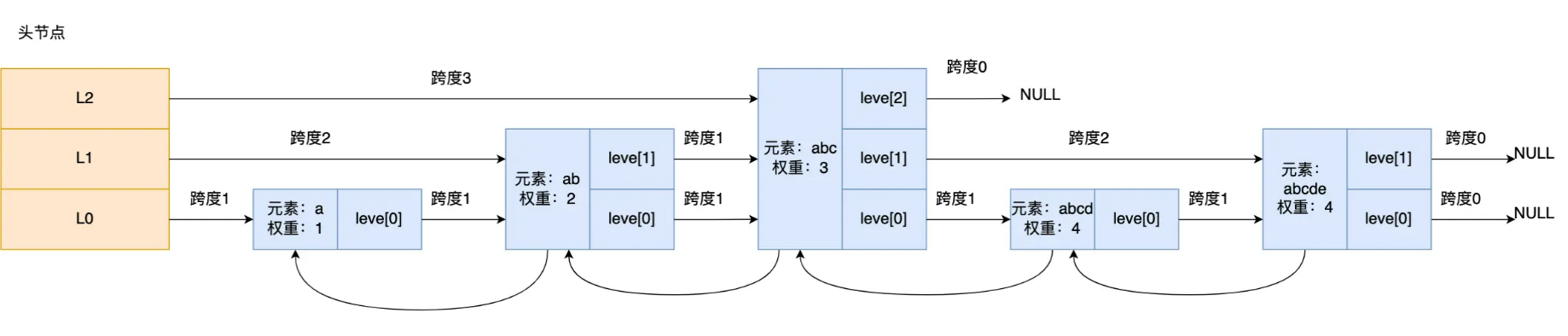
如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve2指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve1;
- 「元素:abc,权重:3」节点的 leve1 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据 > 要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve0;
- 「元素:abc,权重:3」节点的 leve0 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
// 这里是查找的源码,来自下面新增节点的函数
x = zsl->header;
//从顶层开始,遍历开始,每次移动不只是移动头节点的level,是所有节点的level,每次都是从上一次遍历到的节点开始
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; //如果从头开始,跨度为0,否则累加上一层已经计算的跨度
while (x->level[i].forward &&
(x->level[i].forward->score < score || // 权值小于目标
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0))) // 当前节点的memer小于目标节点
{
rank[i] += x->level[i].span; //计算跨度
x = x->level[i].forward; //到下一个索引位置
}
update[i] = x; //记录当前层开始修改的节点的位置
}新增节点
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
//从顶层开始,遍历开始,每次移动不只是移动头节点的level,是所有节点的level,每次都是从上一次遍历到的节点开始
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; //如果从头开始,跨度为0,否则累加上一层已经计算的跨度
while (x->level[i].forward &&
(x->level[i].forward->score < score || // 权值小于目标
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0))) // 当前节点的Memer小于目标节点
{
rank[i] += x->level[i].span; //计算跨度
x = x->level[i].forward; //到下一个索引位置
}
update[i] = x; //记录当前层开始修改的节点的位置
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
// 假设要插入的元素在跳跃表中尚不存在,因为跳跃表允许有相同的分值(score)。
// 再次插入相同的元素是不应该发生的,因为调用 zslInsert() 函数的调用者应该在哈希表(或其他数据结构)中先测试元素是否已经存在。
// 在跳跃表中,允许多个节点具有相同的分值,但它们的元素值必须不同。
level = zslRandomLevel(); //随机生成一个层数
if (level > zsl->level) {
// 如果这个level达到新高,那么往上面走,走到顶全部初始化(你可以理解为对level进行扩容)
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
// 新的level,那么再old_level到level之间的跨度每层都是length
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele); // 创建一个新的节点
for (i = 0; i < level; i++) {
//插入节点(基础知识:单链表的节点插入),修改第Li层的后继
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
// (rank[0] - rank[i])为新节点到前一层节点的跨度差
// update[i]->level[i].span 表示的是原本前一个节点到后一个节点建的跨度
// 这里新来了一个节点,前一个节点新节点的跨度是rank[0] - rank[i],另外一个就互补,见一下就可以了
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// 修改前一个节点的跨度,但是这个节点本身也算一个系欸但,所以要加1
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
// 前面我们只修改了同层,上面的每一层因为中间多了一个,所以跨度加一
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 修改x的前继指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x; // 只修改最下面一层的
else
zsl->tail = x; //把x放在最后
zsl->length++;
return x;
}删除节点
/* Delete an element with matching score/element from the skiplist.
* The function returns 1 if the node was found and deleted, otherwise
* 0 is returned.
*
* If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise
* it is not freed (but just unlinked) and *node is set to the node pointer,
* so that it is possible for the caller to reuse the node (including the
* referenced SDS string at node->ele). */
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
// 这里再将新增的时候讲过了
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
// 进行节点删除,并且把关联系欸但进行修改
zslDeleteNode(zsl, x, update);
if (!node)
// 把空间释放
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}解决连锁反应
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}原创声明:本文系作者授权晃晃云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权晃晃云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。