无需人力标注!悉尼大学华人团队提出「GPT自监督标注」范式,完美解决标注成本、偏见、评估问题
无需人力标注!悉尼大学华人团队提出「GPT自监督标注」范式,完美解决标注成本、偏见、评估问题

新智元报道
编辑:好困
【新智元导读】最近,来自悉尼大学的研究人员提出了一种GPT自监督注释方法,能够将数据注释为简洁摘要,并在各种注释任务中展现出卓越的性能。
一直以来,数据标注都在深度学习流程中扮演了基础且重要的角色。
优质的数据标注直接影响到模型的学习效果,而这无疑是实现高效深度学习的最原始且关键的一步。
与此同时,标注的数据作为groundtruth,也直接影响了后续的训练,验证,测试。
然而,业界和学界不得不面临数据标注任务成本较高、存在偏见、难以评估,以及标注难度等问题。
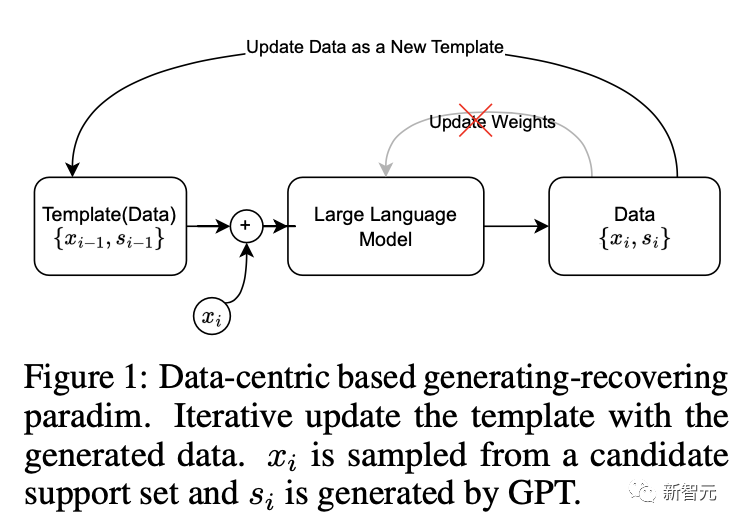
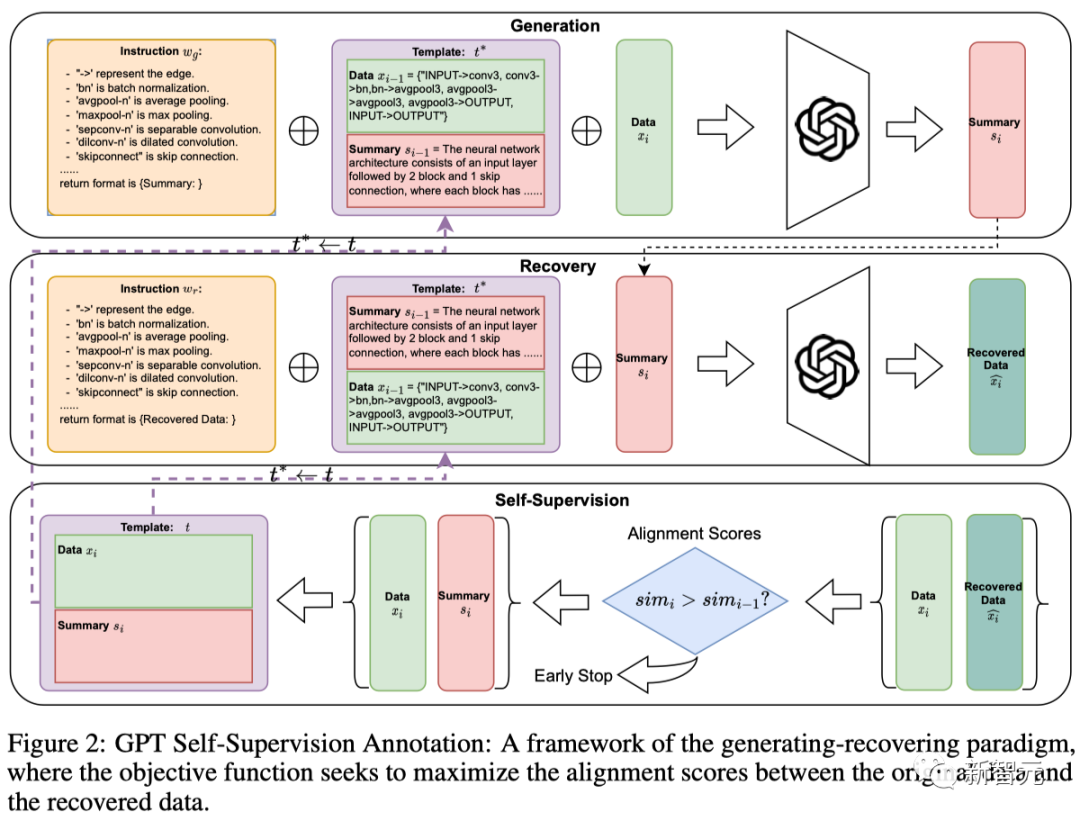
最近,来自悉尼大学的研究团队提出了一种通过大语言模型自监督生成标注的框架。首次利用基于生成-还原循环标注的GPT自监督方法,解决了上述问题。

论文链接:https://arxiv.org/pdf/2306.04349.pdf
其核心思想是,利用大语言模型作为一个黑盒优化优器,构造了一个循环:
模版质量越高,生成的数据-标注对质量越高;生成的数据标注对质量越高,用当前质量更高的数据对替换上一轮的模版。以此往复迭代,滚雪球式循环提升标注质量。
数据标注困难重重
1. 成本较高:
无论是在哪个国家或公司,数据标注都是一项成本高昂的工作,需要大量的人力和时间投入。
在美国,数据标注员的平均年薪约为39,000美元,最高可达49,803美元[2]。即使在印度,数据标注员的平均年薪约为2.0 Lakhs卢比,约合2,670美元[3]。
其次,数据标注的成本也影响了其评估的困难。
例如,由于成本的差异,许多公司选择将数据标注任务外 包到人力成本较低的国家[4]。
然而,这种跨文化的标注可能导致一些细微的语义差异被忽视,从而影响了模型的学习效果。
2. 存在偏见:
数据标注在机器学习和人工智能的应用中扮演着重要的角色。
然而,研究显示[5],人类在标注过程中可能会引入偏见,这些偏见可能会影响机器学习模型的训练和性能。
研究发现,标注员可能会按照数据集创建者编写的指令中的模式进行标注,这种现象被称为「指令偏见」。
这些指令可能会导致某些标注在数据中过度表示,从而使得AI系统对这些标注产生偏见。
3. 难以评估:
研究表明[6]大语言模型本身可以直接通过设计prompt标注数据。
然而,评估这些模型对数据标注的质量和效果十分困难, 因为如何评判生成的数据质量是一个主观的问题。
比如,在生物医学领域,深度学习模型已经显示出在从DNA序列中预测调控效应的巨大潜力。
但人类本身并未完全理解模型输出的内容,因此用模型标注的质量难以被人类评判。
4. 标注难度:
即使对专业从业者,一些结构化数据标注难度仍然太大。
比如,在神经网络计算图数据中,结点表述操作符,有向边表示。
一个表示网络结构的graph列表多达上千个结点对,人工数结点和嵌套的block序列将耗费大量时间和精力。
全新标注方法
团队提出的标注方法包含了one-shot阶段和生成阶段。
其中,one-shot阶段的目标是迭代寻找最优的{数据-标注}数据对作为模板。
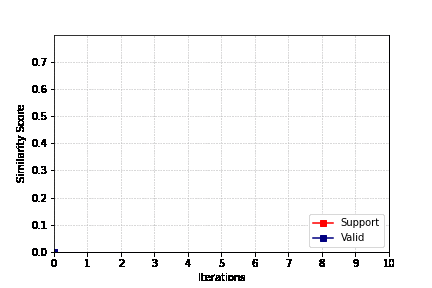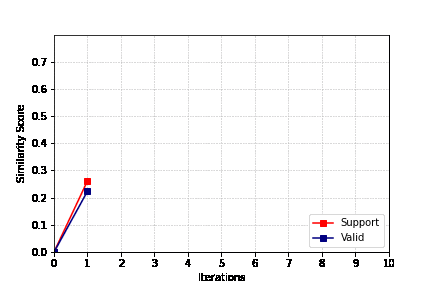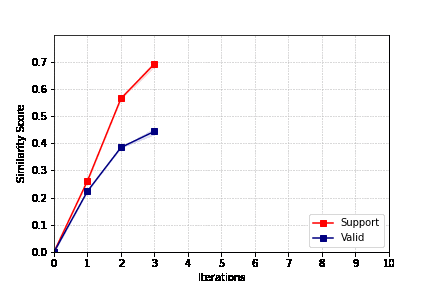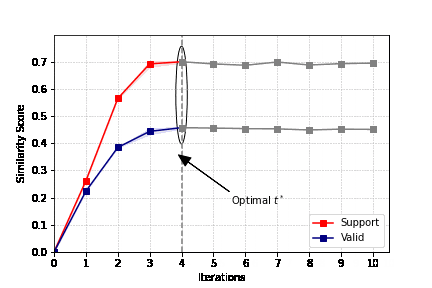
迭代过程:
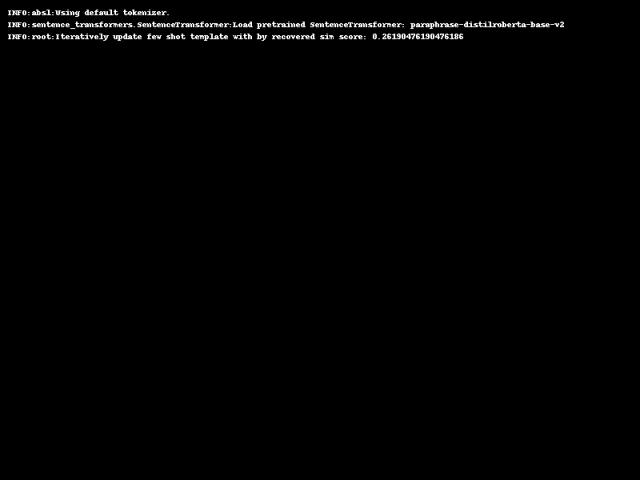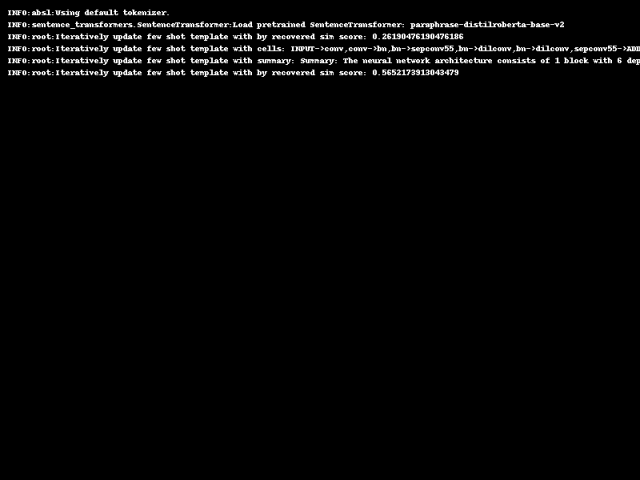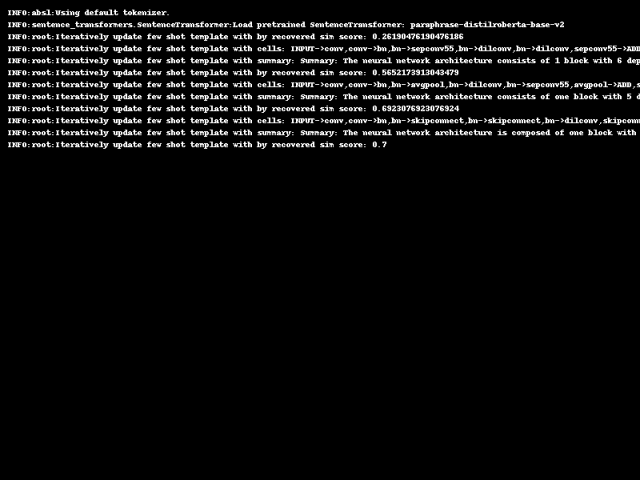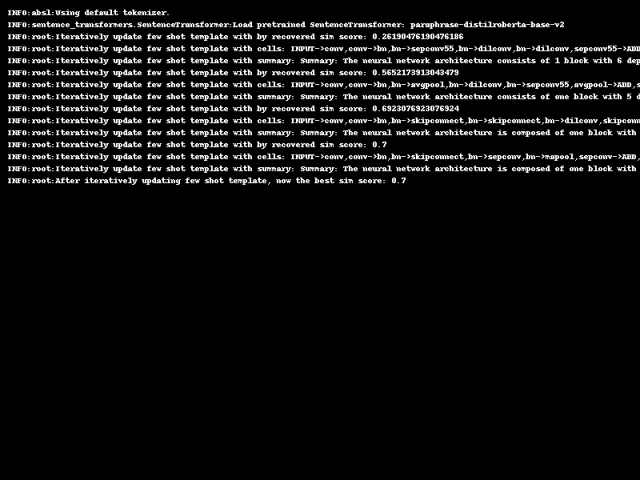
初始化一个简单数据对作为初始模版,利用GPT生成标注,生成的标注和原始数据形成一个新的数据对。
然后,通过比较从标注中还原出来的数据和原始数据,评估这个新数据对作为模板的潜力。
如果还原数据与原数据的相似度得分有所提高,就用当前的新数据对直接作为新的模板进行一轮数据生成。
因此,这种自我对齐机制会迭代调整one-shot模板,为下一轮生成做好准备。one-shot阶段搜索到的最优模板随后用于对数据集进行标注。
作者通过调整不同的预训练奖励模型来评估标注的质量,并引入不同的评价指标来间接评估摘要的还原能力。
作者在三个具有挑战性的数据集上进行了大量实验,并从各种角度进行了详细的消融研究。
结果表明,这种自我监督范式在奖励模型和还原数据能力的得分的评估中始终表现出很高的性能。
另外,作者应用该框架生成了两个新的数据集,对基于不同计算操作符的神经网络架构进行的描述。
作者通过调用OpenAI的API在各种类型的GPT模型上进行了基准测试。
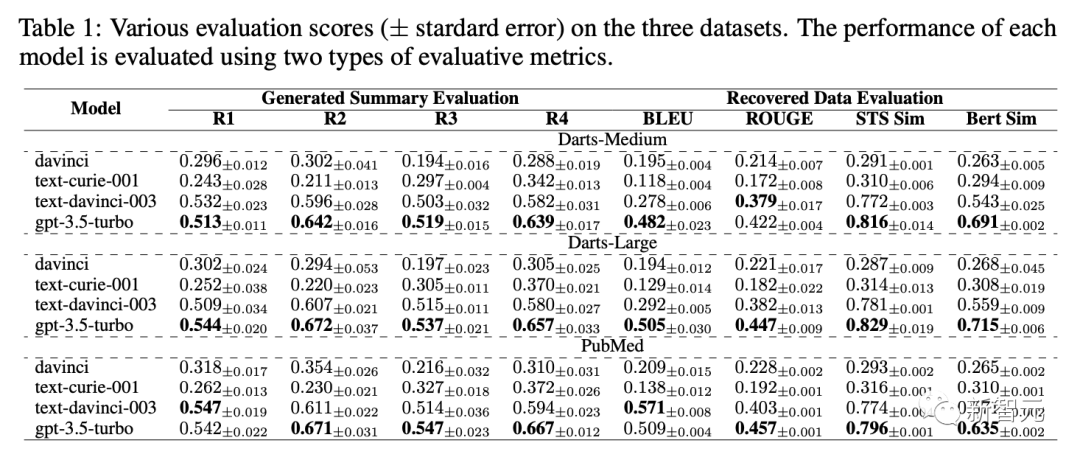
表1展示了davinci,text-curie-001,text-davinci-003,gpt-3.5-turbo在不同评估标准下标注数据质量的得分。
作者在论文中还探讨如下消融实验:
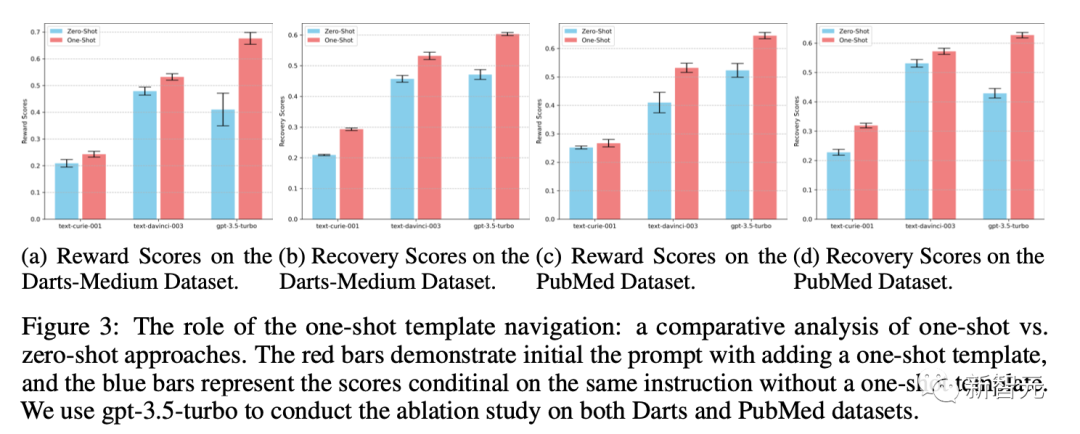
Q1. 迭代后的one-shot模板在整个过程中扮演什么角色?我们是否能通过zero-shot方法(仅通过设计的指令instruction-tuning生成摘要), 来达到同样的效果?
A1. 与以相同指令为条件的零样本生成相比,引入样本模板提高了标注质量, 实验细节如图所示。
此外,作者还在文中还探讨了如下问题:
对还原数据和原数据之间的相似度测量评估标准方法会对标注有什么影响?模板的初始化如何影响自监督标注迭代的结果?GPT模型本身的超参数是否会影响搜索出来的标注模版