WAF防火墙数据接入腾讯云ES最佳实践(上)
原创
说明
本文描述问题及解决方法适用于 腾讯云 Elasticsearch Service(ES)。
另外使用到:腾讯云 Logstash
由于篇幅问题,本文会分两部分展开,下半部分请移步:WAF防火墙数据接入腾讯云ES最佳实践(下)
一、需求背景
WAF是个简称,中文全称为Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称: WAF)。
客户在不同云厂商的WAF日志需要统一接入一个平台,集中管理,最终客户选择了腾讯云ES。
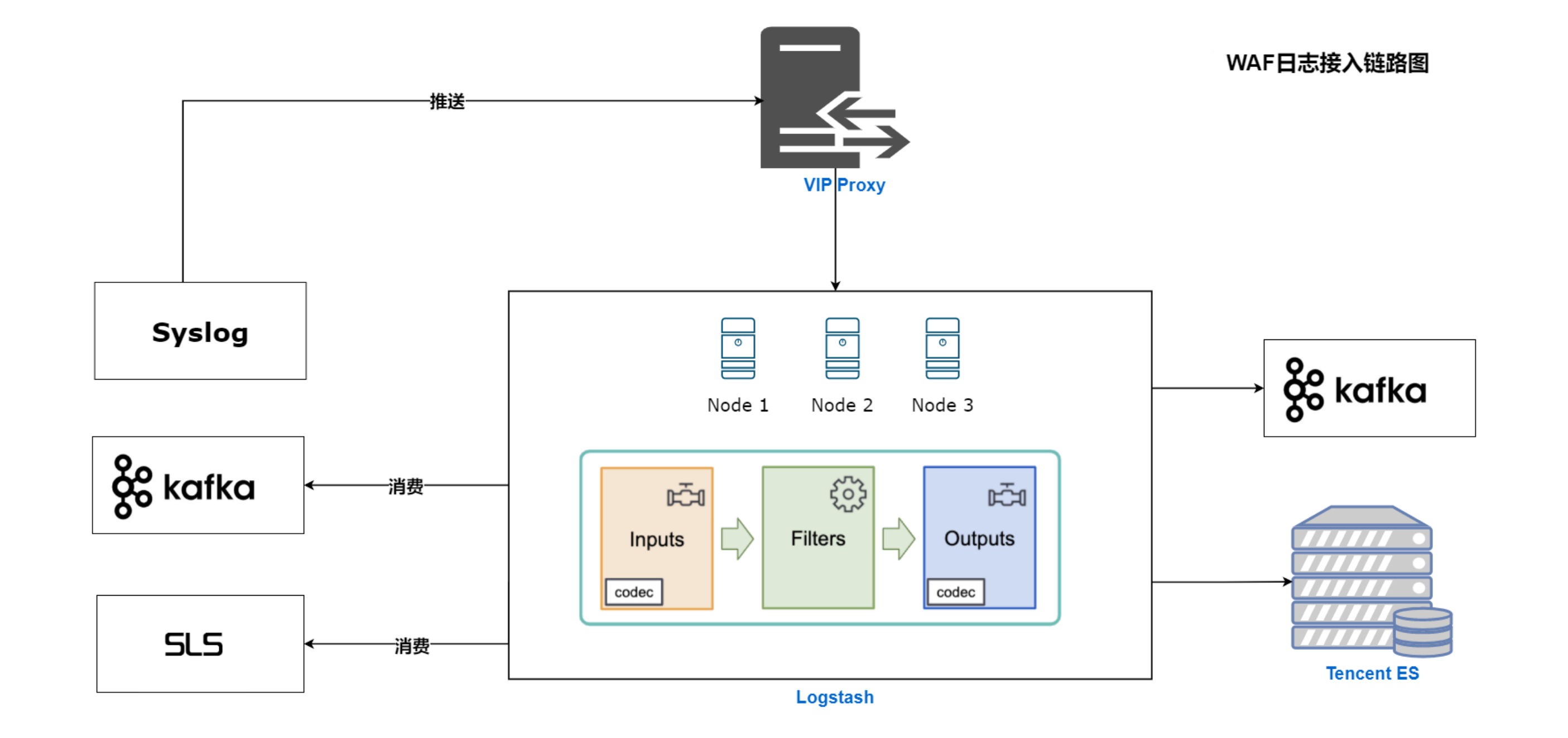
二、数据接入链路
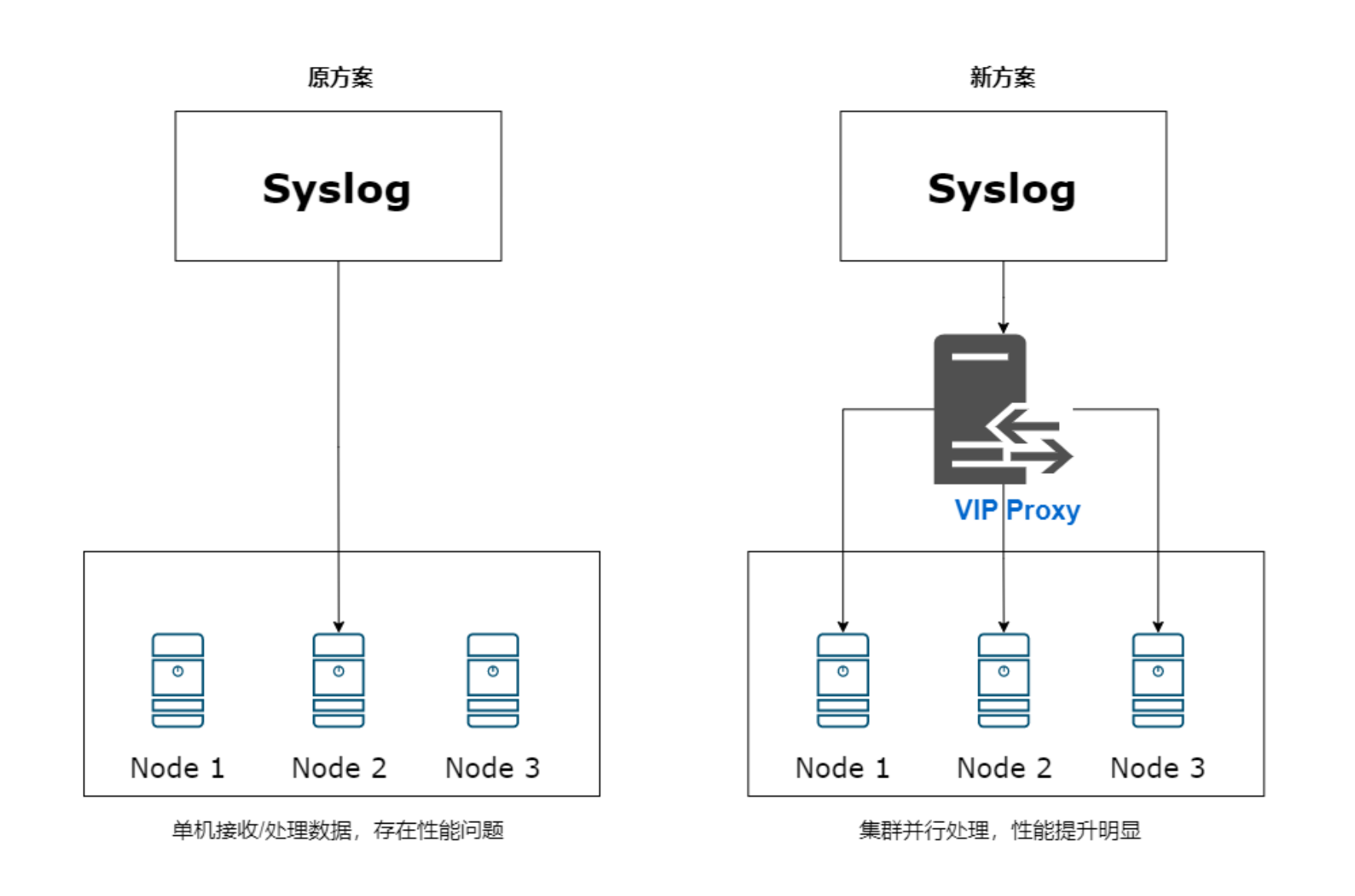
链路上遇到的问题:
由于syslog只能往单节点推送,而腾讯云logstash又是多节点的logstash集群,这样就导致syslog无法利用到多台logstash进行数据同步,造成资源浪费。

解决方案:
Syslog?→ Logstash VIP → Logstash RS → ES
- 创建一个private link(vip),指向logstash实例下的所有RS节点,并绑定1024以上的端口,比如8888;
- logstash实例启动8888端口,接收数据;
- 对客户暴露这个vip:8888,让客户的syslog往vip推送数据;
- logstash实例的RS轮流接收到syslog数据推送,并消费到ES
WAF日志接入链路图:
SLS说明:
数据管道,阿里云的日志服务,提供日志类数据采集、加工等操作。
三、Logstash介绍
Logstash是 Elastic 公司提供的一款专门用于应用程序日志、事件的传输、处理、管理的产品。
我们可以通过Logstash完成跨ES集群的数据迁移工作,也可以使用logstash接入多种数据源做数据的同步,小红书WAF日志就是通过logstash进行接入的。
1.?logstash安装
注:腾讯云ES提供了logstash产品,无需安装配置,下面简单介绍下logstash的安装方式
1)下载并安装公共签名密钥
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch2)配置yum源
[logstash-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md3)安装
yum install logstash2.?logstash插件说明
Logstash是插件式工作模式,他的插件主要分为3种 input/filter/output
INPUT PLUGIN # 收集数据 FILTER PLUGIN # 数据清洗、数据转化 OUTPUT PLUGIN # 数据输出
2.1 Input配置
- Beats:从beat采集
input {
beats {
port => 5044
}
}- Syslog:从syslog采集
input {
syslog {
port => 5144
syslog_field => "syslog"
}
}- File:从文件采集
input {
file {
path => "/var/log/*/*.log"
}
}- Elasticsearch:从es集群采集数据
input {
elasticsearch {
hosts => "localhost"
query => '{ "query": {"match": { "statuscode": 200 } }, "sort": ["_doc" ] }'
}
}- Kafka:从kafka获取数据
input {
kafka {
bootstrap_servers =>"xxxxx:9992 "
topics => ["test"]
codec => "json"
security_protocol =>"SASL_PLAINTEXT"
sasl_mechanism => "PLAIN"
jaas_path =>"/etc/logstash/kafka-client-jaas.conf"
consumer_threads => 2
group_id => "logstash-bigdata"
auto_offset_reset => "latest"
max_poll_records => "500"
max_poll_interval_ms =>"30000"
session_timeout_ms => "30000"
request_timeout_ms => "60000"
auto_commit_interval_ms =>"5000"
check_crcs => "false"
heartbeat_interval_ms =>"9000"
partition_assignment_strategy =>"org.apache.kafka.clients.consumer.RoundRobinAssignor"
}
}- Jdbc:从数据库采集数据
input {
jdbc {
jdbc_driver_library =>"mysql-connector-java-5.1.36-bin.jar"
jdbc_driver_class =>"com.mysql.jdbc.Driver"
jdbc_connection_string =>"jdbc:mysql://localhost:3306/mydb"
jdbc_user => "mysql"
parameters => {"favorite_artist" => "Beethoven" }
schedule => "* * * * *"
statement => "SELECT * from songswhere artist = :favorite_artist"
}
}- S3:从对象存储采集数据
input {
s3 {
"access_key_id" => "xxx"
"secret_access_key" => "xxxxx"
"endpoint" => "https://cos.ap-guangzhou.myqcloud.com"
"bucket" => "my-bucket"
"region" => "ap-guangzhou"
}
}2.2?Output配置
- Elasticsearch:输出至ES集群
output {
if [log_type] == "tomcat" and([department] == "zxbi" or [department] == "jfbi") {
elasticsearch {
hosts =>["https://rjjd-node01:9200"]
index =>"jfbi.prd-%{+YYYY.MM}"
user => "beatuser"
password =>"xxxxx"
http_compression => "true"
sniffing => "false"
ssl => true
ssl_certificate_verification =>"true"
cacert => "/etc/ssl/xxx_ca.crt"
id => "zxbi"
}
}
}- File:输出至文件
output {
file {
path => “/tmp/stdout.log”
codec => line {
format => "customformat: %{message}"
}
}
}- Stdout:输出至控制台
output {
stdout { codec => json }
}2.3?Filter配置
其中filter插件较为复杂,filter插件中实现了很多插件提供使用。
aggregate | Aggregates information from several events originating with a single task | logstash-filter-aggregate |
|---|---|---|
alter | Performs general alterations to fields that the mutate filter does not handle | logstash-filter-alter |
bytes | Parses string representations of computer storage sizes, such as "123 MB" or "5.6gb", into their numeric value in bytes | logstash-filter-bytes |
cidr | Checks IP addresses against a list of network blocks | logstash-filter-cidr |
cipher | Applies or removes a cipher to an event | logstash-filter-cipher |
clone | Duplicates events | logstash-filter-clone |
csv | Parses comma-separated value data into individual fields | logstash-filter-csv |
date | Parses dates from fields to use as the Logstash timestamp for an event | logstash-filter-date |
de_dot | Computationally expensive filter that removes dots from a field name | logstash-filter-de_dot |
dissect | Extracts unstructured event data into fields using delimiters | logstash-filter-dissect |
dns | Performs a standard or reverse DNS lookup | logstash-filter-dns |
drop | Drops all events | logstash-filter-drop |
elapsed | Calculates the elapsed time between a pair of events | logstash-filter-elapsed |
elasticsearch | Copies fields from previous log events in Elasticsearch to current events | logstash-filter-elasticsearch |
environment | Stores environment variables as metadata sub-fields | logstash-filter-environment |
extractnumbers | Extracts numbers from a string | logstash-filter-extractnumbers |
fingerprint | Fingerprints fields by replacing values with a consistent hash | logstash-filter-fingerprint |
geoip | Adds geographical information about an IP address | logstash-filter-geoip |
grok | Parses unstructured event data into fields | logstash-filter-grok |
http | Provides integration with external web services/REST APIs | logstash-filter-http |
i18n | Removes special characters from a field | logstash-filter-i18n |
java_uuid | Generates a UUID and adds it to each processed event | core plugin |
jdbc_static | Enriches events with data pre-loaded from a remote database | logstash-integration-jdbc |
jdbc_streaming | Enrich events with your database data | logstash-integration-jdbc |
json | Parses JSON events | logstash-filter-json |
json_encode | Serializes a field to JSON | logstash-filter-json_encode |
kv | Parses key-value pairs | logstash-filter-kv |
memcached | Provides integration with external data in Memcached | logstash-filter-memcached |
metricize | Takes complex events containing a number of metrics and splits these up into multiple events, each holding a single metric | logstash-filter-metricize |
metrics | Aggregates metrics | logstash-filter-metrics |
mutate | Performs mutations on fields | logstash-filter-mutate |
prune | Prunes event data based on a list of fields to blacklist or whitelist | logstash-filter-prune |
range | Checks that specified fields stay within given size or length limits | logstash-filter-range |
ruby | Executes arbitrary Ruby code | logstash-filter-ruby |
sleep | Sleeps for a specified time span | logstash-filter-sleep |
split | Splits multi-line messages, strings, or arrays into distinct events | logstash-filter-split |
syslog_pri | Parses the PRI (priority) field of a syslog message | logstash-filter-syslog_pri |
threats_classifier | Enriches security logs with information about the attacker’s intent | logstash-filter-threats_classifier |
throttle | Throttles the number of events | logstash-filter-throttle |
tld | Replaces the contents of the default message field with whatever you specify in the configuration | logstash-filter-tld |
translate | Replaces field contents based on a hash or YAML file | logstash-filter-translate |
truncate | Truncates fields longer than a given length | logstash-filter-truncate |
urldecode | Decodes URL-encoded fields | logstash-filter-urldecode |
useragent | Parses user agent strings into fields | logstash-filter-useragent |
uuid | Adds a UUID to events | logstash-filter-uuid |
wurfl_device_detection | Enriches logs with device information such as brand, model, OS | logstash-filter-wurfl_device_detection |
xml | Parses XML into fields | logstash-filter-xml |
详细用法见:https://www.elastic.co/guide/en/logstash/7.14/filter-plugins.html
logstash常用插件说明
其中我们最常用的插件为:grok、date、drop、geoip、json、kv、ruby、mutate,下面简单介绍下这些常用的插件。
- Date
日期过滤器用于解析字段中的日期,然后使用该日期或时间戳作为事件的logstash时间戳。
filter {
date {
match => ["[creatime]", # 时间字段
"yyyy-MM-dd HH:mm:ss", #
"yyyy-MM-dd HH:mm:ss Z", #
"MMM dd, yyyy HH:mm:ss aa", # Oct 16, 2020 11:59:53 PM
"yyyy-MM-dd HH:mm:ss.SSS",
"ISO8601", # 2018-06-17T03:44:01.103Z ( Z 后面可以有 "08:00" 也可以没 )
"UNIX", # UNIX时间戳格式记录的是从 1970 年起始至今的总秒数
"UNIX_MS" # 从 1970 年起始至今的总毫秒数
]
target => "@timestamp" # 目标字段
timezone => "Asia/Shanghai" # 时区设置
}
}- Drop
当不需要某些数据的时候,可以使用drop插件丢弃,例如:
filter {
if [loglevel] == "debug" {
drop { }
}
}- Geoip
GeoIP过滤器根据Maxmind GeoLite2数据库中的数据添加有关IP地址的地理位置的信息。 配置表达式:
filter {
geoip {
database =>"/usr/local/GeoLite2-City/GeoLite2-City.mmdb"
fields => ["ip","longitute","city_name"]
source => "ip"
target => "geoip"
}
}其中database文件需要手动下载:https://www.maxmind.com/en/accounts/436070/geoip/downloads,该站点需要注册登录。
- Json
默认情况下,它会将解析后的JSON放在Logstash事件的根(顶层)中,但可以使用配置将此过滤器配置为将JSON放入任意任意事件字段 target。
当在解析事件期间发生不良事件时,此插件有一些回退场景。如果JSON解析在数据上失败,则事件将不受影响,并将标记为 _jsonparsefailure; 然后,您可以使用条件来清理数据。您可以使用该tag_on_failure选项配置此标记。
如果解析的数据包含@timestamp字段,则插件将尝试将其用于事件@timestamp,如果解析失败,则字段将重命名为,_@timestamp并且事件将使用标记 _timestampparsefailure。
filter {
json {
source => "message"
}
}- Kv
此过滤器有助于自动解析各种消息(或特定事件字段)类似foo=bar。
例如,如果您有一条包含的日志消息ip=1.2.3.4 error=REFUSED,则可以通过配置来自动解析这些消息。
filter {
kv {
default_keys => [“host”,”ip”]
exclude_keys => [“times”]
field_split => “&?”
}
}支持的参数:
https://www.elastic.co/guide/en/logstash/6.8/plugins-filters-kv.html
- Ruby
执行ruby代码。此过滤器接受内联ruby代码或ruby文件。这两个选项是互斥的,具有稍微不同的工作方式。
例如:
filter {
ruby {
code => "event.set('eventHappenedAt',event.get('createdDateTime').to_i*1000)"
}
ruby {
id => "135453"
path => "/usr/local/rubyCode/rubyLogParse.rb"
}
}其中引用的ruby脚本如下:
def filter(event)
#取出日志信息
logdata=event.get('message')
if (logdata.include?'reqMessage' )
#解析日志级别和请求时间,并保存到event对象中
logleve=logdata[(logdata.index('[')+1)...logdata.index(']')]
event.set('logleve',logleve)
event.set('requestTime',logdata[0,logdata.index(' - [')])
#如果是rest接口json日志
if(logdata.include?'restJson')
parseJsonLog event,logdata
else
parseXmlLog event,logdata
end
end
return [event]
#解析json格式日志
def parseJsonLog(event,logdata)
#获取日志内容
loginfo=logdata[(logdata.index('] ')+2)...(logdata.rindex('}')+1)]
#转成json对象
logInfoJson=JSON.parse loginfo
#获取流水号
event.set('transactionID',logInfoJson['transactionID'])
event.set('channel',logInfoJson['reqMessage']['channel'])
#获取返回报文
event.set('respMessage',logInfoJson['respMessage'].to_json)
#获取请求报文
event.set('reqMessage',logInfoJson['reqMessage'].to_json)
?
.....................省略部分代码
?
#设置标示位
event.set('tags','log_success')
end- Mutate
强大的mutate过滤器,可以对数据进行增删改查。支持的语法多,且效率高
按照执行顺序排列: coerce:null时默认值 rename:重命名字段 update:更新数据 replace:替换字段值 convert:转换字段类型 gsub:替换字符 uppercase:转为大写的字符串 capitalize:转换大写字符串 lowercase:转为小写的字符串 strip:剥离字符空白 remove:移除字段 split:分离字段 join:合并数组 merge:合并多个数组 copy:复制字段
例如:
filter {
mutate {
split => ["hostname","."]
add_field => {"shortHostname" => "%{hostname[0]}" }
}
mutate {
rename =>["shortHostname", "hostname" ]
}
} 原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。