白话讲解最佳论文提名: 如何在推荐场景中缓解离线强化学习带来的马太效应
白话讲解最佳论文提名: 如何在推荐场景中缓解离线强化学习带来的马太效应

TLDR: 本篇将介绍如何在真实推荐决策场景上进行建模,介绍离线强化学习的工作流程,并指出其在推荐中造成的一个普遍问题:马太效应(强者越强,弱者越弱)。最后介绍我们如何用直观的方式来缓解马太效应。文章的最后会讲一些题外话。
序:
我们的论文获得了SIGIR 2023的最佳论文提名奖(Best Paper Honorable Mention)。本次投稿一投就中还拿了奖,这对于日常被拒麻了的我,绝对是人生的意外。本篇博文目的是科普,并展现本工作的思想部分,并不会大摆公式,推理论,讲细节。感兴趣的朋友请查看原文。
首先附上信息,本次论文是中科大何向南组与快手策略算法部江鹏组的合作产出。

论文:arxiv.org/abs/2307.04571 代码:github.com/chongminggao/DORL-codes
本工作的设定,遵循的是我们的上一篇解决研讨推荐中的信息茧房的工作CIRS[1],当时兴冲冲地投了多次顶会,每次均包含较高的评审评价,但最后均被少数评审质疑实验设定给拒了,拖了很久后中了期刊TOIS,最后关注量寥寥无几。
我自己很喜欢目前做的设定:将推荐系统场景考虑为一个序列决策过程,其目标是追求用户的累计满意度(而非仅仅拟合用户的偏好),故需要用强化学习来进行决策(而非用监督学习来预测)。
追求用户满意度的设定在工业界是标配,但在学术界中举步维艰。最大原因在于难以对策略进行评测(evaluation),毕竟最具有说服力的结果来自于在线用户的直接反馈,并计算在线指标涨跌,这对于拿着离线数据集研究的学者们是不可能的。于是目前推荐学者们还在用离线的指标进行评测,这貌似是唯一可行的方案了。而我们的设定,则是在离线数据上进行长期满意度评测,这种设定比较小众,但符合真实的推荐场景。值得一提的是,随着最近ChatGPT这样的决策模型的崛起,人们才知道该如何正确评测决策模型:看用户满意度,而非生成标准答案的能力。从这个角度,我们的学习与评测流程均与ChatGPT一致。
- 序:
- 一、推荐中的用户的满意度
- 二、长期满意度的离线评测
- 三、离线强化学习(Offline RL)思想
- 四、Offline RL的保守思想在推荐中的危害
- 五、Offline RL中缓解马太效应的直观思路
- 六、实验设定与实验结果
- 后记
- 参考文献
一、推荐中的用户的满意度
现如今的大多数推荐系统场景(如电商推荐、短视频推荐场景),都不是早期电影评分那样的单点的、独立的交互了,而是一个动态且持续的交互序列。以下图的短视频推荐场景为例:系统会向用户推荐一系列商品,而用户会对其做出各种反馈,包括观看时长、点赞、收藏、转化等。

那么在这个过程中,我们应该优化什么?这个问题的答案根据现状可分为两类:
1. 在工业界,算法工程师们将会优化大盘中的某个或某类指标。什么是大盘?大盘就是一个像股票交易市场中的大屏幕,里面充满滚动的红绿色的数字,红色代表涨,绿色代表跌。只不过大盘里的数字代表的不是股票,而是App后台各种在线指标的实时数据。以短视频场景为例,这些在线指标包括:活跃用户数目、人均App使用时长、用户次日留存概率、视频平均播放时长、视频平均完成播放概率、视频点赞/收藏/转发概率、用户观看视频多样性,等等。通常来说,现在所有商业推荐系统都已经做得很完善,故数字有涨有跌,每次优化只能侧重某方面的指标,做不到全盘皆涨。

如何得到自己算法的指标从而计算涨跌呢?用A/B test。比如让全局流量的10%走自己算法的推荐系统,然后与大盘90%的流量下的推荐结果进行对比,就可以知道本次新算法的成效,从而明确迭代方向。
这里有一个关键点:指标的上涨下跌,均来自用户的直接反馈计算而来。对于工程师,你可以做任何决策,都能看到该决策带来的影响。
2. 在学术界,事情就非常棘手。最大的困难源于评测(evaluation)。学者们开发新模型,只能用现有的离线数据集。众所周知,推荐数据高度稀疏,数据密度通常在1%以下。这带来一个问题,如何说明我们现在开发的模型性能是好的呢?
一个简单粗暴但直观有效的方案:看我们的模型能否把“标准答案”推荐出来且排在前面。什么是标准答案呢?自然是划分出的测试集(test set)中包含的用户良好反馈的商品。至于那些99%的没有观测到反馈的商品呢?Who cares? 拿预测商品与标准答案的对比,就可以用诸如Recall、NDCG、Hit Rate这样的指标计算。
问题来了!请思考:预测的准 = 好的推荐系统吗?这个答案在现实的推荐场景来说,大部分是否定的。预测的准只是基本功,而问题关键是让用户满意!举个例子,当下一众NLP大模型都有着非常高的事实预测精准度以及语言生成流畅性,为什么唯独ChatGPT能脱颖而出?这是因为ChatGPT的回答最让用户满意。
推荐过程是一个决策问题,而不是单纯的预测问题。 什么叫预测?我猜测你喜欢喝奶茶,我信心十足,于是我开始疯狂输出,三句话不离奶茶,奶茶奶茶奶茶。什么是决策?我刚刚给你提过奶茶了,你也开心地喝过了,开始陷入糖分焦虑了,于是我现在不提奶茶了,我们来讨论健身餐和运动。
推荐场景这样的决策问题非常多,举些例子:
- 信息茧房(filter bubble):短时间内,重重复复推荐相似商品,且不带换,用户会烦。所以工业界里算法工程师会手工加入一些规则(手工决策),来让推荐结果不那么单调。当然这个决策过程可以让算法来完成,详见我们前文工作[1]。

- 锚点效应(anchoring effect): 考虑两种决策:第一种:之前一直给你推便宜的东西,现在推正常价格的A,你会觉得,怎么这么贵。第一种:之前一直给你推的是贵的东西,现在推个正常价格的A,你会觉得性价比很高。故后者可能比前者更好一些。

这些决策场景的例子中,一个单纯的基于监督学习的预测模型,是搞不定的。现实场景用户的满意度,不是测试集中的“正确答案”能够刻画出来的,否则工程师们也不用费力进行A/B test再不停迭代了,直接给定一个“正确答案”集合,拼命拟合就行了。
说完这些, 再来看传统推荐、传统序列推荐中的评测机制,就能看出问题了。如下图:

其中(a)中的传统静态推荐是对一个用户推荐top-k的商品,与测试集合中的“标准答案”进行对比,而序列推荐仅仅是在建模方式上将用户的一系列行为作为输入,其工作方式还是在与测试集中的“正确答案”的轨迹进行商品的逐一比对。这就好比规定一个NLP的语言模型,必须要逐字逐句生成某句话才能算正确,其他结果都是错的。
而在我们工作中坚持用的,始终是(b)中的评测方式:即开放式地进行生成和评测,每一步生成结果都对应一个奖励(reward)信号。而我们关心的是整个轨迹的累计收益。
用户长期满意,才是真的满意!
二、长期满意度的离线评测(offline evaluation)
在线场景很好评测用户累计满意度,A/B test就可以。离线场景怎么才能进行累计收益的评测呢?离线场景的痛点在于:我们没法知道用户对于随意一个推荐动作的反馈。离线数据很稀疏,空缺值代表的用户满意度,我们无从得知。
离线场景的累计满意度评测的两种方式:
1. Offline A/B testing
详见这篇论文《Offline A/B testing for Recommender Systems》[2],其使用off-policy的方式来计算当前策略的累计收益。其基本思想大致是:
对于某一条在测试集中的轨迹
,计算其归一化阶段重要性采样(normalized capped importance sampling, NCIS)下的累计收益。其公式如下:
其中
是
的截断(capped)版本,而
,用了重要性采样(importance sampling)的思想中的概率比值,其刻画了当前策略
在状态–动作对
的概率
与旧策略
在
处的概率
的相异程度。直观来看,好的策略应该放大轨迹
中的高奖励的概率,而缩小轨迹中的低奖励的概率,这样才能使得累计收益相比起旧策略有所提升。
这种方式依然要求相对高的数据质量:测试数据必须是行为序列数据,而且要有足够的数据量,才能保证重要性采样的有效性。
故我们更加推崇的是下面的方式,即用户模拟器的方式。
2. 用户模拟器评测
其思路直观,直接将用户的满意度模拟出来。对于待测的目标模型来说,模拟器是和真实用户一样,都是黑箱。获得模拟器的方式也很简单:
- 第一步:用任意一个推荐模型,先把测试数据中没有观测到的交互值预测出来,作为用户的内在偏好。
- 第二步,我们可以根据需求,对这些偏好进行一定的调整,比如加入一些随机噪声,或者加入一些特殊偏好,比如用户的年龄、性别、地域等分类对其影响。或者加入外部因素,例如天气、节假日等对消费行为的影响。亦或是上述提到的重复的推荐对用户耐心的消耗。
- 第三步,综合以上因素,模拟用户的行为,评测任意一个目标模型策略。我们可以用这种方式来模拟现实用户的所有行为,包括点击、购买、评分行为等,并计算整个交互轨迹的用户累积满意度。
本文中的“Feel bored then quit”机制:
在本文中,我们使用用户模拟器评测的方式。思想非常简单:
用一个矩阵分解模型,将测试数据中所有未观测到的用户-商品交互评分预测出来,作为内在偏好。在推荐中加上一个 "Feel bored then quit" 的机制:若当前推荐商品与前序
个商品的相似度超过一定阈值,则认为用户会觉得无聊,不会再继续推荐,而是退出。
而我们计算的是整个交互的累计收益,这既要求单轮的高满意度,又要求整个交互过程尽量长。推荐策略需要考虑这两者的平衡才能取得高收益。举两个极端的例子:若用完全随机的策略推荐,则交互长度可以很长,但每轮收益很低;反之,若每次都推用户最喜欢的的商品,单轮收益可以很高,但交互会在我们的退出机制下很快结束。两者均不能取得很好的累计收益。

三、离线强化学习(Offline RL)思想
一个公认的事实是,我们必须利用离线数据进行策略学习。传统的强化学习是在线学习的,其要求智能体(agent)与用户不断进行交互,收集一定量的交互数据后进行更新。推荐系统中,没有公司能够接受直接让真实用户来从头训练一个策略;同样地,自动驾驶中,也不可能让汽车直接上路进行策略学习。于是乎,离线强化学习(Offline RL)成为近几年的研究热点,三大会每年都会接收不少这方面的论文。
Offline RL的核心思想是:利用离线(offline)收集到的数据,学习一个策略,使得这个策略在真实环境中的累计收益最大化。关于Offline RL,这里推荐Sergey Levine组的综述和教程《Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems》[3]。
基于模型的离线强化学习框架
在我们的工作中,我们将在线强化学习扩展为离线强化学习,所用方式为下图:

比起原始(a)图中的在线强化学习框架,我们采用(b)图中的离线框架,区别主要在于学习的数据来自于历史交互。我们的学习方式与ChatGPT的RLHF模式类似,其分为两阶段:
阶段一: 用监督学习的方式学习一个用户偏好模型,称为用户模型(user model)
。
阶段二: 用学习好的用户模型
产生rewards,对推荐策略
进行训练。
在学习好推荐策略
后,这个策略就可以部署到真实环境中进行推荐了。当然,论文中我们没有做上线这一步骤,而是用上一章提到的用户模拟器评测法,作为真实环境的代替来评测策略的好坏。
Offline RL的共性问题
这个流程简单而美妙!然而,只要是Offline RL,就必然碰到Offline RL的一个共有问题:数据分布偏移(distribution shift)。这个问题的本质是:训练集与测试集的数据分布不同,即训练集无法覆盖测试集的所有情况。在这种情况下,用传统强化学习进行策略学习,就会在缺乏值的地方碰到值函数的高估问题(overestimation of the value function)。
Scott Fujimoto在ICML 2019年中发表的《Off-Policy Deep Reinforcement Learning without Exploration》[4]对这一现象进行了很好的展示,如下图:

此处不对这一现象进行过多的解释,感兴趣的读者可以参考上述论文。我们只需要知道,值高估的现象往往发生在历史数据缺乏或稀疏的区域,这会导致策略学习的性能大幅下降,这也是目前Offline RL这个研究方向的核心挑战,也是绝大多数Offline RL论文的研究核心动机。
该问题的最主流解决思路
解决这个问题的主流方式也很直接:既然值函数在学习中被高估了,那只需要在学习中对它进行约束,不让它被高估即可。换言之,我们可以在学习中引入保守思想(Conservatism)或者悲观思想(Pessimism)。

如上图所示,在AAAI 2022的论文《Offline Reinforcement Learning as Anti-Exploration》[5]中将这种保守思想总结为一种general的形式,即一个惩罚项
,其是对奖励函数
的惩罚,也等效为对值函数
的惩罚。
而图中的曲线来源于AViral Kumar的博文[6]。左边直接用离线数据学习的Q值函数,会在不确定区域将值函数进行高估。其右边的蓝色曲线展现出了在保守思想的约束下,Q值函数的高估部分得到了有效的压制,最终的Q分布更接近于真正的Q分布。
以上便是目前学者们解决Offline RL中挑战的核心思路。这种思路很有效,使得强化学习的策略能在离线数据中也能正常学习。
本文采用的Offline RL算法:MOPO
本工作中,我们选取了直观的MOPO算法作为我们Offline RL模型的基模型,其由Tianhe Yu在NeurIPS 2020的《MOPO: Model-based Offline Policy Optimization》[7]中被提出。MOPO算法的核心思路是在学习过程中,对估计出来的奖励信号进行惩罚,从而达到让策略变得保守这一目的,其核心公式如下:
其中
是模型估计出来的奖励信号,MOPO的核心贡献在于添加上去的惩罚项(penalty term)
,
是一个超参数,用于控制惩罚的程度。为达到保守的目的,这个惩罚项
被实现为动态模型中的不确定度(uncertainty)。即,不确定度越高的学习区域,我们对奖励信号惩罚力度越大。
四、Offline RL的保守思想在推荐系统中的危害
前面三章都是预备知识,现在正式进入本文的核心motivation。
推荐中的马太效应
Offline RL中保守思想有效性已经被证明。说白了,就是让学习到的策略重点偏向训练数据中高频且收益高的区域,而不是去探索那些低频的数据区域(因为这些低频数据区域是不可信的,容易造成值函数高估)。在很多领域,这种思想很奏效,比如自动驾驶中,我们就按照高频的驾驶行为来学习策略,而不去探索那些低频的、稀奇古怪的驾驶行为方式。然而,在推荐系统中,这种保守思想将造成马太效应,即
“富者越富,穷者越穷(The rich gets richer and the poor gets poorer)”。
这种现象在推荐系统中太常见了,任意一个推荐模型都会有这样的趋势。我们分别在传统静态推荐模型和基于MOPO的强化学习推荐模型上进行了实验。
1. 静态推荐模型中的马太效应
例如用传统静态推荐模型DeepFM算法在KuaiRand-Pure数据集[8]上进行实验,并对商品类目进行可视化,结果如下图所示:

KuaiRand-Pure数据集的测试集(Test set)完全由随机曝光的视频组成,而训练数据(Training set)中的视频来源于快手推荐策略中收集的交互。可以看出相比起随机收集的交互数据,这部分数据已经开始强调推荐主流的视频类目(蓝色)了。而在DeepFM的模型训练过后,对其推荐结果再次统计视频类目,可见主流视频类目(蓝色)更加被放大,这就是很明显的马太效应。
2. 离线强化学习策略中的马太效应
那么上文介绍的Offline RL模型MOPO在推荐中表现如何呢?我们在KuaiRand-Pure数据集上进行了实验,结果如下图所示:

随着MOPO算法中的
增大(x轴),策略变得更加保守。从蓝色线的结果来看,评测中单轮的满意度逐渐上升,这说明保守策略确实带来了更加准确的兴趣拟合。然而,从右边的Majority Category Domination (MCD)指标来看,随着
的增大,推荐结果中主流类目的占比逐渐上升,这说明保守策略带来了更加严重的马太效应。
那么,马太效应对用户体验的什么影响?我们在视频数据集KuaiRand-27K与音乐数据集LFM-1b上进行了实验,两个数据集均是大小几十GB的用户交互logs。马太效应会造成推荐的重复,而我们就探究了推荐商品级别与类目级别的重复,会与用户的次留率(第二天上线的概率)有着什么样的统计关系。
为了去除混杂因子的影响,我们对用户的活跃度进行了划分,对不同活跃度的用户群体分别进行统计,结果展现为下图中不同形状与颜色的点。

可以看到,对于两个数据集,对于所有群体,皆有一个共有现象:当天的推荐结果重复率越高,用户第二天上线的概率越低!这说明马太效应确实会损害用户体验!
五、Offline RL中缓解马太效应的直观思路
例子:不同离线数据分布下的马太效应
要来解决这个问题,来看下图中一个直观的例子:

横轴代表所有可推荐商品的空间,用户对于商品的真实偏好(ground-truth preference)是蓝线分布,红线是历史推荐结果的分布,即离线数据集的分布。(a)中假设历史推荐策略产生的推荐分布是一个高斯分布(Gaussian distribution),那么将利用保守思想的Offline RL策略在这样的离线数据中进行学习,估计出来的用户偏好(estimated preference)是绿色的分布。由于其在低频数据区域(横轴两端)的学习受到了保守思想的压制,不能很好地学习真实偏好,导致最终估计出的高偏好会集中在较窄的区域。这就是马太效应的由来。
而(b)中,假设生成离线数据的历史推荐策略师一个完全随机的策略,按照均匀分布(uniform distribution)产生数据。那么按照直觉,这种数据不会给策略的学习带来任何偏差,也不会触发Offline RL的保守性压制,故不会产生马太效应。
我们希望离线数据能够像(b)中这样随机,这显然是不现实的。然而,这个例子能够启发我们修改Offline RL模型的学习过程,使得其保守思想造成的马太效应得到缓解。
缓解Offline RL中马太效应的启发式方案
从上图可得,离线数据分布越接近随机(熵越大),从中学习得到的马太效应越小。基于这个发现,一个启发式的解决思路诞生了:去惩罚Offline RL学习中使得历史状态变得更单调的动作。如何评价这个单调程度呢,用离线数据中该动作出现的熵(entropy)来刻画。
实现在签署的Offline RL的MOPO模型上,其表现为在估计出的奖励
上增加的额外一项关于熵的鼓励,新的奖励函数变为了:
其中
是MOPO原有的保守思想对不确定度(uncertainty)的惩罚,而
就是本文工作中加入的一项实现为熵(entropy)的鼓励项。
而
的具体实现如下图,其可由当前时刻的前序推荐列表在离线数据中,推出的下一个位置的熵算得。如图中,这个前序列表可以是
时刻的商品
,或者
时刻的商品
,或者
时刻的商品
。那
举例,如果在离线数据中,
后面所紧跟的商品比较随机,则
位置处的熵比较大,这种情况我们应该适当加大学习力度,因为这种情况下的学习更加无偏。我们将不同长度的前序序列对应的下一个位置的熵进行求和,即可得到最终的
。

DORL模型架构
至此,变介绍了本文核心思路的来龙去脉,接下来就是我们提出的DORL(Debiased model-based Offline RL)模型的架构,如下图。由于本博文的主要目的在于介绍思想,不想将繁杂的细节放上来,于是先不对每一模块进行深入讲解,感兴趣的朋友请看原文。

六、实验设定与实验结果
我们采用第二部分介绍的 “Feel bored then quit” 机制,在两个数据集上进行模拟评测,两个数据集链接分别为:
- KuaiRec数据集:KuaiRec | 快手发布首个稠密度高达99%的推荐数据集, 可用于多种推荐系统方向研究
- KuaiRand数据集:KuaiRand: 快手–中科大发布含随机曝光的无偏推荐数据集, 完美支持多种前沿研究

接下来直接放实验结果。结论如图所示,就暂时不多费口舌解释了。指的注意的是,在强化学习的评测中,学者们最关心的都是累计收益,一般都用画图的方式可视化累计收益随着训练epoch的变化趋势。我们也沿用这种方式。
我们不仅可视化出了累计收益,且可视化了每一轮的平均收益,以及轨迹平均长度。
主实验结果:

探究:熵惩罚项的强度对消除马太效应的帮助
我们用实验证明了增大
后,交互更不容易退出,轨迹变长、而且推荐的主流结果的MCD指标下降,说明马太效应确实有所缓解。

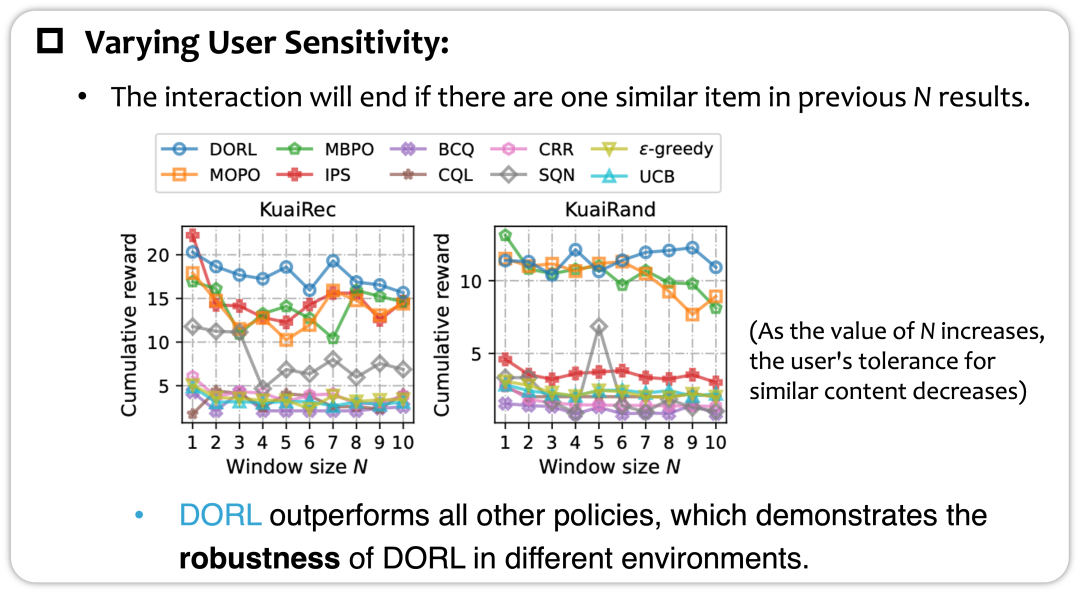
探究:不同退出阈值下策略的鲁棒性表现
最后,我们探究了在不同的用户敏感度条件下,算法的表现。这里变量是 “Feel bored then quit” 机制中的窗口长度
,即当前推荐商品与前
个推荐商品相似程度达到一定阈值,就马上退出交互。这里
越大,用户越容易退出。
实验表明了我们的DORL在不同条件下都有不错的表现,从而展现了其鲁棒性。
后记
看到这里的朋友,感谢你的耐心。
我花了很多功夫描写了交互式推荐的评测,是希望这种方式能够得到更多学者的了解与关注。从前大家受限于离线场景,受限于没有数据。如今我们收集创造了KuaiRec、KuaiRand这种密集的交互数据、提出了 “Feel bored then quit” 这种交互式评测环境。目的很简单,想让学界的推荐模型更加贴近与业界的环境。这样下来,整个流程肯定比短平快的监督模型的训练与评测复杂很多。我相信,随着ChatGPT的兴起,大家终将会体会到决策模型的优势,从而体会到这一套流程的必要性。毕竟追求用户的长期满意,才是我们的根本目标。
最后,祝愿祖国早日统一,人民生活幸福安康。
参考文献
- https://zhuanlan.zhihu.com/p/530441122
- https://arxiv.org/abs/1801.07030
- https://arxiv.org/abs/2005.01643
- https://arxiv.org/abs/1812.02900
- https://arxiv.org/abs/2106.06431
- https://bair.berkeley.edu/blog/2020/12/07/offline
- https://arxiv.org/abs/2005.13239
- https://zhuanlan.zhihu.com/p/566393720