基于Pytorch构建LeNet网络对cifar-10进行分类
基于Pytorch构建LeNet网络对cifar-10进行分类

python与大数据分析
发布于 2023-09-03 21:19:48
发布于 2023-09-03 21:19:48
LeNet5诞生于1994年,是最早的卷积神经网络之一,是Yann LeCun等人在多次研究后提出的最终卷积神经网络结构,是一种用于手写体字符识别非常高效的网络。一般LeNet即指代LeNet5。LeNet5 这个网络虽然很小,但是它包含了深度学习的基本模块:卷积层,池化层,全连接层,是其他深度学习模型的基础。
LeNet5由七层组成(不包括输入层),每一层都包含可训练权重。通过卷积、池化等操作进行特征提取,最后利用全连接实现分类识别。
LeNet5包含 3 个卷积层,2 个池化层,1 个全连接层。其中所有卷积层的所有卷积核都为 5x5,步长 strid=1,池化方法都为全局 pooling,激活函数为 Sigmoid。
下面是他的网络结构示意图:
CIFAR-10数据集由10个类别的60000张32x32彩色图像组成,每个类别有6000张图像。有50000个训练图像和10000个测试图像。
数据集分为五个训练批次和一个测试批次,每个批次有10000张图像。测试批次包含从每个类别中随机选择的1000幅图像。训练批包含随机顺序的剩余图像,但一些训练批可能包含一个类中的图像多于另一个类的图像。在它们之间,训练批次包含每个类别的正好5000个图像。
以下是数据集中的类,以及每个类的10张随机图像:

第一步,导入torch、numpy、matplotlib等包
import timeimport torchimport matplotlib.pyplot as pltimport numpy as npimport torch.nn.functional as Fimport torchvisionfrom torch import nn, optimfrom torchvision.datasets import CIFAR10from torchvision.transforms importCompose, ToTensor, Normalize, Resizefrom torch.utils.data importDataLoaderimport torchvision.transforms as transformsfrom sklearn.metrics import accuracy_score
第二步,定义全局参数
# 定义全局参数model_name='LeNet'# 定义模型名称BATCH_SIZE = 64# 批次大小EPOCHS = 20# 迭代轮数Loss= [] # 计算损失率Accuracy= [] # 计算准确率# 设备DEVICE = 'cuda'if torch.cuda.is_available() else'cpu'
第三步,数据转换设置,并进行数据加载
# 数据转换transformers = Compose(transforms=[ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 数据装载# MNIST 包含 0~9的手写数字, 共有 60000个训练集和 10000个测试集. 数据的格式为单通道 28*28的灰度图.dataset_train = CIFAR10(root='./data', train=True, download=True, transform=transformers)dataset_test = CIFAR10(root='./data', train=False, download=True, transform=transformers)dataloader_train = DataLoader(dataset=dataset_train, batch_size=BATCH_SIZE, shuffle=True)dataloader_test = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=True)classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
第四步,图片显示设置
# 显示图片def imshow(img):img = img / 2+ 0.5# unnormalizenpimg = img.numpy()# np.transpose 交换坐标轴,即将图片色素进行坐标翻转plt.imshow(np.transpose(npimg, (1, 2, 0)))
第五步,定义LeNet网络
# 定义LeNet网络classLeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5) # 3表示输入是3通道# in_channels = 3输入图片通道数# out_channels = 6人为设定# kernel_size 卷积核的尺寸# stride=1卷积步长,就是卷积操作时每次移动的格子数# padding=0原图周围需要填充的格子行(列)数# output_padding=0输出特征图边缘需要填充的行(列)数,一般不设置# groups=1分组卷积的组数,一般默认设置为1,不用管# bias=True卷积偏置,一般设置为False,True的话可以增加模型的泛化能力# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (32- 5+ 2*0)/1+ 1= 28# 输出为:6* 28* 28= 4704self.relu = nn.ReLU()self.maxpool1 = nn.MaxPool2d(2, 2)# output_size = 28/ 2= 14self.conv2 = nn.Conv2d(6, 16, 5)# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (14- 5+ 2*0)/1+ 1= 10# 输出为:16* 10* 10= 4704self.maxpool2 = nn.MaxPool2d(2, 2)# output_size = 10/ 2= 5# 定义全连接层self.fc1 = nn.Linear(16*5*5, 120)# 定义全连接层self.fc2 = nn.Linear(120, 84)# 定义全连接层self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.conv1(x) # 卷积x = self.relu(x) # 激活函数x = self.maxpool1(x) # 池化x = self.conv2(x) # 卷积x = self.maxpool2(x) # 池化x = x.view(-1, 16*5*5) # 调整尺寸x = F.relu(self.fc1(x)) # 全连接 + 激活函数x = F.relu(self.fc2(x)) # 全连接 + 激活函数x = self.fc3(x) # 全连接output = F.log_softmax(x, dim=1) # 激活函数return output
第六步,定义损失函数和优化器
# 定义模型输出模式,GPU和CPU均可model = LeNet().to(DEVICE)# 定义损失函数criterion = nn.CrossEntropyLoss()# 定义优化器# 使用 SGD(随机梯度下降)优化,学习率为 0.001,动量为 0.9optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
第七步,定义模型训练过程函数和模型验证过程函数
# 定义模型输出模式,GPU和CPU均可# 定义模型训练过程def train_runner(model, device, trainloader, optimizer, epoch):#训练模型, 启用 BatchNormalization和 Dropout, 将BatchNormalization和Dropout置为Truemodel.train()total = 0correct =0.0# enumerate迭代已加载的数据集,同时获取数据和数据下标for i, data in enumerate(trainloader, 0):inputs, labels = data# 把模型部署到device上inputs, labels = inputs.to(device), labels.to(device)# 初始化梯度optimizer.zero_grad()# 保存训练结果outputs = model(inputs).to(device)# 计算损失和# 多分类情况通常使用cross_entropy(交叉熵损失函数), 而对于二分类问题, 通常使用sigmodloss = F.cross_entropy(outputs, labels)# 获取最大概率的预测结果# dim=1表示返回每一行的最大值对应的列下标predict = outputs.argmax(dim=1)total += labels.size(0)correct += (predict == labels).sum().item()# 反向传播loss.backward()# 更新参数optimizer.step()if i % 1000== 0:# loss.item()表示当前loss的数值print("Train Epoch{} \t Loss: {:.6f}, accuracy: {:.6f}%".format(epoch, loss.item(), 100*(correct/total)))Loss.append(loss.item())Accuracy.append(correct/total)return loss.item(), correct/total# 定义模型验证过程def test_runner(model, device, testloader):# 模型验证, 必须要写, 否则只要有输入数据, 即使不训练, 它也会改变权值# 因为调用eval()将不启用 BatchNormalization和 Dropout, BatchNormalization和Dropout置为Falsemodel.eval()# 统计模型正确率, 设置初始值correct = 0.0test_loss = 0.0total = 0# torch.no_grad将不会计算梯度, 也不会进行反向传播with torch.no_grad():for data, label in testloader:data, label = data.to(device), label.to(device)output = model(data).to(device)test_loss += F.cross_entropy(output, label).item()predict = output.argmax(dim=1)# 计算正确数量total += label.size(0)correct += (predict == label).sum().item()# 计算损失值print("test_avarage_loss: {:.6f}, accuracy: {:.6f}%".format(test_loss/total, 100*(correct/total)))
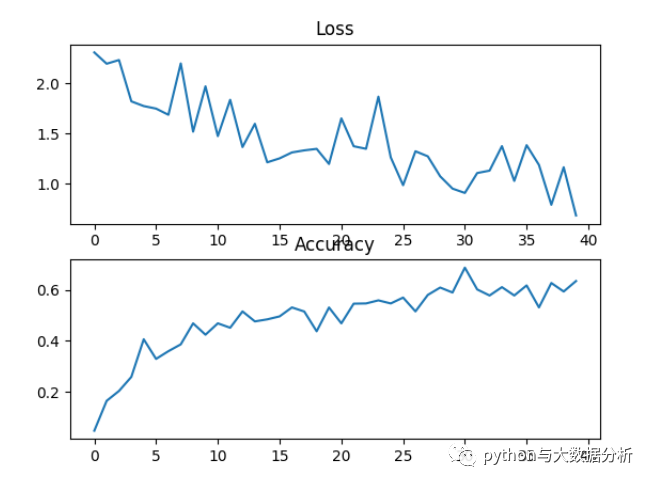
以下为训练了20轮次的效果,可以看出准确率只有59%左右,还有很大的提升空间!
start_time 2023-08-1501:09:02TrainEpoch1Loss:2.308738, accuracy:4.687500%test_avarage_loss:0.035032, accuracy:19.680000%end_time:2023-08-1501:09:18...start_time 2023-08-1501:18:02TrainEpoch20Loss:1.165504, accuracy:59.375000%test_avarage_loss:0.017934, accuracy:59.450000%end_time:2023-08-1501:18:36
第八步,进行20轮次的训练和验证
# 根据EPOCHS开展训练for epoch in range(1, EPOCHS+1):print("start_time",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))loss, acc = train_runner(model, DEVICE, dataloader_train, optimizer, epoch)Loss.append(loss)Accuracy.append(acc)test_runner(model, DEVICE, dataloader_test)print("end_time: ",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'\n')# LeNet网络结构# LeNet(# (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))# (relu): ReLU()# (maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)# (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))# (maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)# (fc1): Linear(in_features=400, out_features=120, bias=True)# (fc2): Linear(in_features=120, out_features=84, bias=True)# (fc3): Linear(in_features=84, out_features=10, bias=True)# )torch.save(model, f'./model/cifar10_{model_name}.pkl') #保存模型print('Finished Training')
第九步,显示训练过程中的损失函数和准确率
fig = plt.figure()plt.subplot(2,1,1)plt.plot(Loss)plt.title('Loss')plt.subplot(2,1,2)plt.plot(Accuracy)plt.title('Accuracy')plt.show()
通过matplotlib显示训练过程中的损失函数和准确率的曲线
第十步,对具体数据开展验证工作
dataiter = iter(dataloader_test)images, labels = dataiter.__next__()# 显示图片imshow(torchvision.utils.make_grid(images))print('GroundTruth: ', ' '.join('%5s'% classes[labels[j]]for j in range(BATCH_SIZE)))plt.show()outputs = model(images.to(DEVICE).to(DEVICE))# 输出是10个标签的能量。一个类别的能量越大,神经网络越认为它是这个类别。所以让我们得到最高能量的标签_, predicted = torch.max(outputs, 1)print('Predicted: ', ' '.join('%5s'% classes[predicted[j]]for j in range(BATCH_SIZE)))
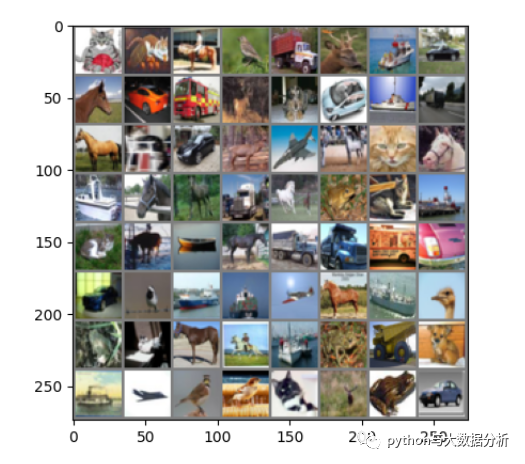
以下为前64张图片的预测和实际值
GroundTruth: cat cat horse bird truck deer ship car horse car truck deer dog car ship truck horse cat car deer plane horse cat horse ship horse deer truck horse frog cat ship cat horse ship horse truck truck truck car car bird ship ship plane horse ship bird frog cat horse horse ship frog truck dog ship plane bird bird cat deer frog carPredicted: cat dog truck bird truck deer ship car horse car truck deer cat car ship plane horse dog car deer plane horse frog dog ship plane deer bird cat frog truck ship bird cat ship horse truck truck truck horse car bird ship ship plane horse ship bird cat cat cat deer ship frog frog frog plane plane bird horse plane bird frog car
以下为前64张图片的实际图片,可以看出来由于算法原因,以及本身图片的质量问题,导致预测结果不是十分理想!
不过这是基于深度学习开展图像识别的一个开始,后续将对一代一代的深度学习算法开展验证和测试,也帮助自己消化和理解深度学习。
本文参与?腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2023-08-15,如有侵权请联系?cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录