基于Pytorch构建AlexNet网络对cifar-10进行分类
基于Pytorch构建AlexNet网络对cifar-10进行分类

AlexNet网络是CV领域最经典的网络结构之一了,在2012年横空出世,并在当年夺下了不少比赛的冠军。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。AlexNet和LeNet的设计非常类似,但AlexNet的结构比LeNet规模更大。
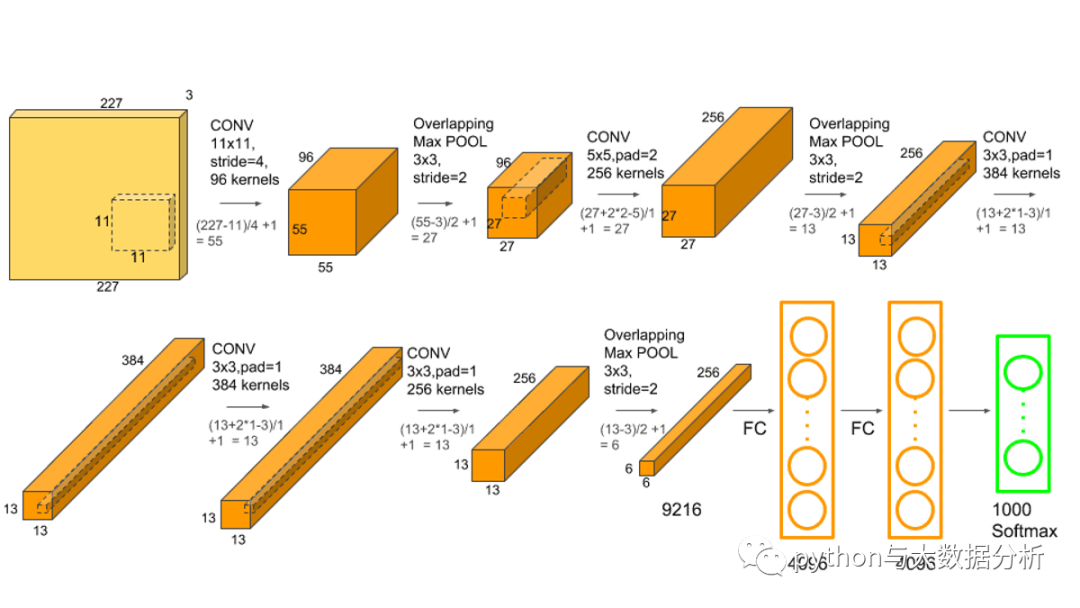
AlexNet的结构比LeNet规模更大,AlexNet包含8层变换,其中包含5层卷积和2层全连接隐藏层,以及最后的一个全连接的输出层。
在AlextNet中,第一层中的卷积核的size为1111.第二层中的卷积核的size为55,之后的卷积核的size全部为33.此外,第1,2,5个卷积层的之后都使用了size为33,步长为2的最大池化。
紧接着最后一个卷积层是两个输出个数位4096的全连接层。
AlexNet采用了丢弃法来控制全连接层的模型复杂度。而LeNet没有使用丢弃。
AlexNet引入了大量的图像变换,如旋转,裁剪,颜色变换等等,进一步扩大了数据集来缓解数据过拟合的问题
AlexNet网络:
(1).激活函数使用ReLU替代Tanh或Sigmoid加快训练速度,解决网络较深时梯度弥散问题。
(2).训练时使用Dropout随机忽略一部分神经元,以避免过拟合。
(3).使用重叠最大池化(Overlapping Max Pooling),避免平均池化时的模糊化效果;并且让步长比池化核的尺寸小,提升特征丰富性。filter的步长stride小于filter的width或height。一般,kernel(filter)的宽和高是相同的,深度(depth)是和通道数相同的。
(4).使用LRN对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经元,增强了模型泛化能力。LRN只对数据相邻区域做归一化处理,不改变数据的大小和维度。
(5).数据扩充(Data Augmentation):训练时随机地从256*256的原始数据中截取227*227大小的区域,水平翻转;光照变换。增加了数据量,大大减少过拟合,提升泛化能力。
(6).多GPU并行运算。
AlexNet输入是一种属于1000种不同类别的一张BGR图像,大小为227*227,输出是一个向量,大小为1000。输出向量的第i个元素值被解释为输入图像属于第i类的概率。因此,输出向量的所有元素的总和为1。

AlexNet架构:
5个卷积层(Convolution、ReLU、LRN、Pooling)+3个全连接层(InnerProduct、ReLU、Dropout),predict时对各层进行说明:参照https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/deploy.prototxt
(1).输入层(Input):图像大小227*227*3。如果输入的是灰度图,它需要将灰度图转换为BGR图。训练图大小需要为256*256,否则需要进行缩放,然后从256*256中随机剪切生成227*227大小的图像作为输入层的输入。
(2).卷积层1+ReLU+LRN:使用96个11*11的filter,stride为4,padding为0,输出为55*55*96,96个feature maps,训练参数(11*11*3*96)+96=34944。
(3).最大池化层:filter为3*3,stride为2,padding为0,输出为27*27*96,96个feature maps。
(4).卷积层2+ReLU+LRN:使用256个5*5的filter,stride为1,padding为2,输出为27*27*256,256个feature maps,训练参数(5*5*96*256)+256=614656。
(5).最大池化层:filter为3*3,stride为2,padding为0,输出为13*13*256,256个feature maps。
(6).卷积层3+ReLU:使用384个3*3的filter,stride为1,padding为1,输出为13*13*384,384个feature maps,训练参数(3*3*256*384)+384=885120。
(7).卷积层4+ReLU:使用384个3*3的filter,stride为1,padding为1,输出为13*13*384,384个feature maps,训练参数(3*3*384*384)+384=1327488。
(8).卷积层5+ReLU:使用256个3*3的filter,stride为1,padding为1,输出为13*13*256,256个feature maps,训练参数(3*3*384*256)+256=884992。
(9).最大池化层:filter为3*3,stride为2,padding为0,输出为6*6*256,256个feature maps。
(10).全连接层1+ReLU+Dropout:有4096个神经元,训练参数(6*6*256)*4096=37748736。
(11).全连接层2+ReLU+Dropout:有4096个神经元,训练参数4096*4096=16777216。
(12).全连接层3:有1000个神经元,训练参数4096*1000=4096000。
(13).输出层(Softmax):输出识别结果,看它究竟是1000个可能类别中的哪一个。
当然在实践中,不能完全照搬这个模型的相关参数设置,需要根据不同数据源规格进行调整,而且网上的代码千差万别,参数设置不同,组合方式也不同,需要消化吸收!
本次代码在原有代码的基础上追加了导出网络图的功能,此外变更了模型,预置条件:
1、安装graphviz应用
2、pip install torchviz
第一步,导入torch、numpy、matplotlib等包
import timeimport torchimport matplotlib.pyplot as pltimport numpy as npimport torch.nn.functional as Fimport torchvisionfrom torch import nn, optimfrom torchvision.datasets import CIFAR10from torchvision.transforms importCompose, ToTensor, Normalize, Resizefrom torch.utils.data importDataLoaderfrom torchviz import make_dotimport torchvision.transforms as transformsfrom sklearn.metrics import accuracy_score
第二步,定义全局参数
# 定义全局参数model_name='AlexNet'# 定义模型名称BATCH_SIZE = 64# 批次大小EPOCHS = 20# 迭代轮数Loss= [] # 计算损失率Accuracy= [] # 计算准确率# 设备DEVICE = 'cuda'if torch.cuda.is_available() else'cpu'
第三步,数据转换设置,并进行数据加载
# 数据转换transformers = Compose(transforms=[ToTensor(), Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 数据装载# MNIST 包含 0~9的手写数字, 共有 60000个训练集和 10000个测试集. 数据的格式为单通道 28*28的灰度图.dataset_train = CIFAR10(root='./data', train=True, download=True, transform=transformers)dataset_test = CIFAR10(root='./data', train=False, download=True, transform=transformers)dataloader_train = DataLoader(dataset=dataset_train, batch_size=BATCH_SIZE, shuffle=True)dataloader_test = DataLoader(dataset=dataset_test, batch_size=BATCH_SIZE, shuffle=True)classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
第四步,图片显示设置
# 显示图片def imshow(img):img = img / 2+ 0.5# unnormalizenpimg = img.numpy()# np.transpose 交换坐标轴,即将图片色素进行坐标翻转plt.imshow(np.transpose(npimg, (1, 2, 0)))
第五步,定义AlexNet网络
# 定义AlexNet网络classAlexNet(nn.Module):def __init__(self):super(AlexNet, self).__init__()# 定义每一个就卷积层self.layer1 = nn.Sequential(# 卷积层 #输入图像为3*32*32nn.Conv2d(3, 32, kernel_size=3, padding=1),# stride默认为1# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (32- 3+ 2*1)/1+ 1= 32# 输出为:32* 32* 32= 32768# 池化层nn.MaxPool2d(kernel_size=2, stride=2), # 池化层特征图通道数不改变,每个特征图的分辨率变小# padding默认为0# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (32- 2+ 2*0)/2+ 1= 16# 输出为:32* 16* 16= 8192# 激活函数Relunn.ReLU(inplace=True),)self.layer2 = nn.Sequential(nn.Conv2d(32, 64, kernel_size=3, padding=1),# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (16- 3+ 2*1)/1+ 1= 16# 输出为:64* 16* 16= 16384nn.MaxPool2d(kernel_size=2, stride=2),# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (16- 2+ 2*0)/2+ 1= 8# 输出为:64* 8* 8= 4096nn.ReLU(inplace=True),)self.layer3 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, padding=1),# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (8- 3+ 2*1)/1+ 1= 8# 输出为:128* 8* 8= 8192)self.layer4 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3, padding=1),# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (8- 3+ 2*1)/1+ 1= 8# 输出为:256* 8* 8= 16384)self.layer5 = nn.Sequential(nn.Conv2d(256, 256, kernel_size=3, padding=1),# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (8- 3+ 2*1)/1+ 1= 8# 输出为:256* 8* 8= 16384nn.MaxPool2d(kernel_size=3, stride=2),# output_size公式计算非整数时,向下取整# output_size=(input_size - kernel_size + 2*padding) / stride + 1= (8- 3+ 2*0)/2+ 1= 3# 输出为:256* 3* 3= 2034nn.ReLU(inplace=True),)# 定义全连接层self.fc1 = nn.Linear(256* 3* 3, 1024)# 2304- > 1024self.fc2 = nn.Linear(1024, 512)# 1024- > 512self.fc3 = nn.Linear(512, 10)# 512- > 10# 对应十个类别的输出def forward(self, x):x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.layer5(x)x = x.view(-1, 256* 3* 3)x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return x
第六步,定义损失函数和优化器
# 定义模型输出模式,GPU和CPU均可model = AlexNet().to(DEVICE)# 定义损失函数criterion = nn.CrossEntropyLoss()# 定义优化器# 使用 SGD(随机梯度下降)优化,学习率为 0.001,动量为 0.9optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
第七步,定义模型训练过程函数和模型验证过程函数
# 定义模型输出模式,GPU和CPU均可# 定义模型训练过程def train_runner(model, device, trainloader, optimizer, epoch):#训练模型, 启用 BatchNormalization和 Dropout, 将BatchNormalization和Dropout置为Truemodel.train()total = 0correct =0.0# enumerate迭代已加载的数据集,同时获取数据和数据下标for i, data in enumerate(trainloader, 0):inputs, labels = data# 把模型部署到device上inputs, labels = inputs.to(device), labels.to(device)# 初始化梯度optimizer.zero_grad()# 保存训练结果outputs = model(inputs).to(device)# 计算损失和# 多分类情况通常使用cross_entropy(交叉熵损失函数), 而对于二分类问题, 通常使用sigmodloss = F.cross_entropy(outputs, labels)# 获取最大概率的预测结果# dim=1表示返回每一行的最大值对应的列下标predict = outputs.argmax(dim=1)total += labels.size(0)correct += (predict == labels).sum().item()# 反向传播loss.backward()# 更新参数optimizer.step()if i % 1000== 0:# loss.item()表示当前loss的数值print("Train Epoch{} \t Loss: {:.6f}, accuracy: {:.6f}%".format(epoch, loss.item(), 100*(correct/total)))Loss.append(loss.item())Accuracy.append(correct/total)return loss.item(), correct/total# 定义模型验证过程def test_runner(model, device, testloader):# 模型验证, 必须要写, 否则只要有输入数据, 即使不训练, 它也会改变权值# 因为调用eval()将不启用 BatchNormalization和 Dropout, BatchNormalization和Dropout置为Falsemodel.eval()# 统计模型正确率, 设置初始值correct = 0.0test_loss = 0.0total = 0# torch.no_grad将不会计算梯度, 也不会进行反向传播with torch.no_grad():for data, label in testloader:data, label = data.to(device), label.to(device)output = model(data).to(device)test_loss += F.cross_entropy(output, label).item()predict = output.argmax(dim=1)# 计算正确数量total += label.size(0)correct += (predict == label).sum().item()# 计算损失值print("test_avarage_loss: {:.6f}, accuracy: {:.6f}%".format(test_loss/total, 100*(correct/total)))
以下为训练了20轮次的效果,可以看出在CPU笔记本上运行了4个多小时,但在6G显卡的GPU上训练只要6分钟,而且准确率提升到74%左右,比LeNet网络提升了15%!
start_time 2023-08-1501:09:02TrainEpoch1Loss: 2.308738, accuracy: 4.687500%test_avarage_loss: 0.035032, accuracy: 19.680000%end_time: 2023-08-1501:09:18...start_time 2023-08-1519:44:20TrainEpoch1Loss: 2.312408, accuracy: 7.812500%test_avarage_loss: 0.034595, accuracy: 21.690000%end_time: 2023-08-1519:46:41...start_time 2023-08-1600:01:57TrainEpoch20Loss: 0.608510, accuracy: 70.312500%test_avarage_loss: 0.011993, accuracy: 74.830000%end_time: 2023-08-1600:06:05
第八步,进行20轮次的训练和验证
# 根据EPOCHS开展训练for epoch in range(1, EPOCHS+1):print("start_time",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))loss, acc = train_runner(model, DEVICE, dataloader_train, optimizer, epoch)Loss.append(loss)Accuracy.append(acc)test_runner(model, DEVICE, dataloader_test)print("end_time: ",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'\n')# AlexNet网络结构# AlexNet(# (layer1): Sequential(# (0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))# (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)# (2): ReLU(inplace=True)# )# (layer2): Sequential(# (0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))# (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)# (2): ReLU(inplace=True)# )# (layer3): Sequential(# (0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))# )# (layer4): Sequential(# (0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))# )# (layer5): Sequential(# (0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))# (1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)# (2): ReLU(inplace=True)# )# (fc1): Linear(in_features=2304, out_features=1024, bias=True)# (fc2): Linear(in_features=1024, out_features=512, bias=True)# (fc3): Linear(in_features=512, out_features=10, bias=True)# )torch.save(model, f'./model/cifar10_{model_name}.pkl') #保存模型print('Finished Training')
第九步,显示训练过程中的损失函数和准确率
fig = plt.figure()plt.subplot(2,1,1)plt.plot(Loss)plt.title('Loss')plt.subplot(2,1,2)plt.plot(Accuracy)plt.title('Accuracy')plt.show()
通过matplotlib显示训练过程中的损失函数和准确率的曲线

第十步,对具体数据开展验证工作,红色代码为新增代码
dataiter = iter(dataloader_test)images, labels = dataiter.__next__()# 显示图片imshow(torchvision.utils.make_grid(images))print('GroundTruth: ', ' '.join('%5s'% classes[labels[j]]for j in range(BATCH_SIZE)))plt.show()outputs = model(images.to(DEVICE).to(DEVICE))# torchviz 可视化模型model_pic = make_dot(outputs.mean(), params=dict(model.named_parameters()))model_pic.format="png"model_pic.directory = "data"model_pic.view()model_pic.save(f'{model_name}_Digraph.png')# 输出是10个标签的能量。一个类别的能量越大,神经网络越认为它是这个类别。所以让我们得到最高能量的标签_, predicted = torch.max(outputs, 1)print('Predicted: ', ' '.join('%5s'% classes[predicted[j]]for j in range(BATCH_SIZE)))

以下为前64张图片的预测和实际值
GroundTruth: plane cat truck dog frog bird horse cat bird frog cat truck truck frog frog horse horse plane car horse deer frog cat ship plane frog deer cat dog horse deer horse ship truck bird truck car cat frog ship bird deer dog car car dog plane bird horse plane plane horse horse plane deer horse frog bird truck deer truck cat ship truckPredicted: plane cat truck cat frog bird horse cat bird frog frog truck truck frog frog horse horse plane car horse deer frog dog ship plane bird deer cat dog truck deer horse ship truck bird truck car horse frog ship dog deer dog car car cat plane dog horse plane plane horse dog ship deer horse frog dog truck deer truck cat ship ship
以下为前64张图片的实际图片,比LeNet网络提升了15%!

这是基于深度学习开展图像识别的第二个模型,有了一定的提升,后续也多少有了更大的信心。