使用YOLOv8进行工业视觉缺陷检测,基于Aidlux完成本地终端部署
原创使用YOLOv8进行工业视觉缺陷检测,基于Aidlux完成本地终端部署
原创
1. 引言
工业视觉缺陷检测系统是一种利用计算机视觉技术,通过分析生产过程中的图像和视频数据,来检测工业产品是否存在缺陷或质量问题的系统。有幸参与到Aidlux夏令营活动中,跟着东哥做了医疗注射器缺陷检测系统项目,在这个过程中我收获到了很多之前没有接触到的算法和实践。本项目旨在开发一种高效的工业视觉缺陷检测系统,利用YOLOv8模型进行目标检测,并基于AidLux平台完成本地终端部署推理,以满足工业生产中对产品质量控制的需求。
2. 项目背景
工业生产中,产品质量的保证是至关重要的,而传统的质量检测方法通常需要大量的人力和时间成本,且容易受主观因素影响。因此,利用计算机视觉技术来自动化进行缺陷检测已成为一种重要的解决方案。本项目旨在开发一种高效且易于部署的医疗注射器缺陷检测系统,以提高生产效率和产品质量。
3. 项目目标
本项目的主要目标是设计、开发和部署一种医疗注射器缺陷检测系统,具体目标如下:
使用YOLOv8模型进行目标检测,检测对象包括胶塞、推杆尾部、针尾部、针嘴、螺口、小胶塞,并且需要额外检测歪嘴情况。
(1)实现本地终端部署推理,以满足实时性要求。
(2)提供可扩展性,支持常用模型的部署,同时能够灵活应对新模型的更新。
(3)提供简单的部署代码,支持Python和C++多语言开发,适用于更多的工业级产品。
(4)保持系统小巧、安装方便,具有高环境耐受性。
(5)持续维护和迭代系统,确保产品的质量和性能不断提升。
在满足上述多样化需求的考虑下,我们选择Aidlux平台作为项目的核心基础。Aidlux平台不仅简洁,而且功能完善,能够满足我们这个项目的各项要求。此外,我们还注意到,在使用Aidlux进行图片推理预测时,其速度表现也相当迅速,进一步确保了系统的高效性。通过选择Aidlux平台,我们能够更好地实现项目目标,提高工业视觉缺陷检测的效率和准确性。
4. 技术架构
4.1. YOLOv8模型选择和改进
为了实现目标检测,本项目选择了YOLOv8模型,该模型集成了多种功能,包括分类、实例分割、目标检测、关键点检测等。针对项目需求,我们对YOLOv8模型进行了一些改进,其中包括slimNeck和VoVGSCSPC。其中为了进一步改进模型性能,我们引入了SIou(Scale-Invariant Intersection over Union)作为一项关键的模型改进。SIou不仅保留了其他Iou(Intersection over Union)方法的优点,还加入了角度的计算,从而在多目标检测和缺陷检测中带来了以下优势:
(1)模型收敛速度更快:SIou的引入使得模型更容易学习目标的准确位置和角度,从而加速了训练过程。
(2)提高训练的速度:SIou的角度计算有助于模型更好地理解目标的方向,进而提高了检测速度。
(3)提高模型精度:SIou综合考虑了目标的位置和角度信息,因此在缺陷检测中能够更准确地识别缺陷,提高了模型的精度。
通过引入SIou,我们进一步提高了YOLOv8模型的性能,使其更适用于工业视觉缺陷检测任务。SIoU的综合性能优势将有助于提高检测准确性,特别是在具有不同角度和方向的目标检测中,所以很适合我们这个医疗注射器缺陷检测系统。
class VoVGSCSP(nn.Module):
# VoVGSCSP module with GSBottleneck
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.gsb = nn.Sequential(*(GSBottleneck(c_, c_, e=1.0) for _ in range(n)))
self.res = Conv(c_, c_, 3, 1, act=False)
self.cv3 = Conv(2 * c_, c2, 1)
def forward(self, x):
x1 = self.gsb(self.cv1(x))
y = self.cv2(x)
return self.cv3(torch.cat((y, x1), dim=1))
class VoVGSCSPC(VoVGSCSP):
# cheap VoVGSCSP module with GSBottleneck
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2)
c_ = int(c2 * 0.5) # hidden channels
self.gsb = GSBottleneckC(c_, c_, 1, 1)?4.2. 模型导出与部署
? 当进行模型转换时,我们需要将本地基于YOLOv8模型训练得到的"best.pt"模型文件转换为ONNX文件格式,以便在不同平台上进行部署和使用。这是项目中一个重要的步骤,为了使更多人能够更加理解我们的项目,下面我们对模型转换的代码进行一下解释:
我们在训练了多次,多次调整参数,选择训练预测识别效果最好的一次训练结果将其转换为onnx模型,所以我们选择了当迭代训练次数为100轮是训练出来的模型进行转换,因为当迭代次数超过120轮之后由于数据集过少,导致训练过于拟合了,反而预测的效果不好。训练结果图片如下:

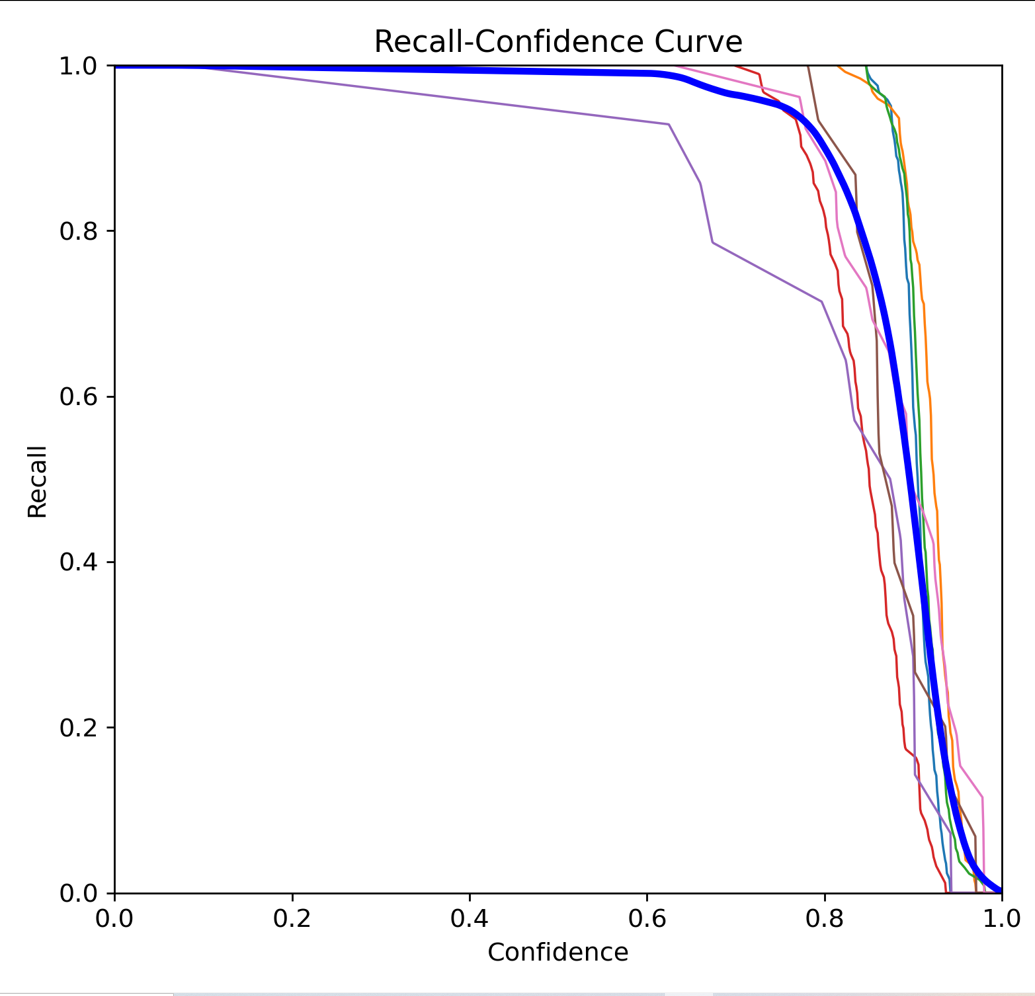


???在项目中,我们使用了YOLOv8模型来进行医疗注射器缺陷检测模型。为了将这个模型转换成ONNX格式,我们采用了以下的转换代码:
if mode=="onnx" :
model = YOLO('D:\\gongye\\yolov8-main\\gongye.pt')
model.export(format="onnx",opset=11,simplify=True)
# path = model.export(format="onnx",opset=13,half=True,simplify=True)
# path = model.export(format="onnx",opset=13,half=True,simplify=True)上述代码首先创建了一个YOLOv8模型实例,并加载了本地训练得到的"gongye.pt"权重文件。然后,通过调用模型的export方法,将模型转换为ONNX格式。在这个过程中,我们选择了opset=11的算子版本。这个选择考虑了目标部署平台的广泛支持,稳定性以及社区支持。opset=11是一个相对较早的ONNX操作集版本,更多的深度学习框架和硬件加速器通常都支持这个版本,这有助于确保模型能够在不同平台上正确运行。
? 这个模型转换的步骤是非常关键的,因为它允许我们将训练好的模型转化为一种通用的格式,以便在不同的环境中进行使用。这为工业视觉缺陷检测项目提供了跨平台部署的便利,并有助于确保项目的成功实施。
4.3. 部署代码
? 在本项目中,东哥还提供了一套完整的模型部署代码,该代码包括了多个关键步骤,如模型加载、图像预处理、推理过程、后处理和结果保存等。这些代码以Python为基础,并借助相关的第三方库,旨在支持各种工业应用场景中的模型部署需求。
具体而言,给出的部署代码具有以下特点:
- 模型加载:?部署代码能够轻松加载TFLite和DLC模型,确保在不同平台上实现无缝的模型部署。
- 图像预处理: 部署代码包括图像预处理步骤,以确保输入图像与模型的期望输入格式一致。这有助于提高模型的准确性和稳定性。
- 推理过程:?同时我们的代码实现了高效的推理过程,能够在实时性要求下完成缺陷检测任务。这对于工业应用中的快速响应至关重要。
- 后处理: 模型输出需要进行后处理,以解析检测结果并执行进一步的操作。我们的代码包括了这一关键步骤,以确保输出结果的准确性。
- 结果保存: 最终,我们的代码能够将检测结果保存到指定位置,以便后续分析和记录。
?此外,我们的模型部署系统非常小巧,易于迁移,并具有出色的环境耐受性。这意味着我们的系统可以适应各种工业环境,无论是在车间、生产线还是其他现场场景中,都能够可靠运行。
通过东哥提供这一完整的部署解决方案,我们能够确保了项目的可用性和实用性,使其能够满足广泛的工业视觉缺陷检测需求。
5. 部署步骤
?5.1. 模型转换

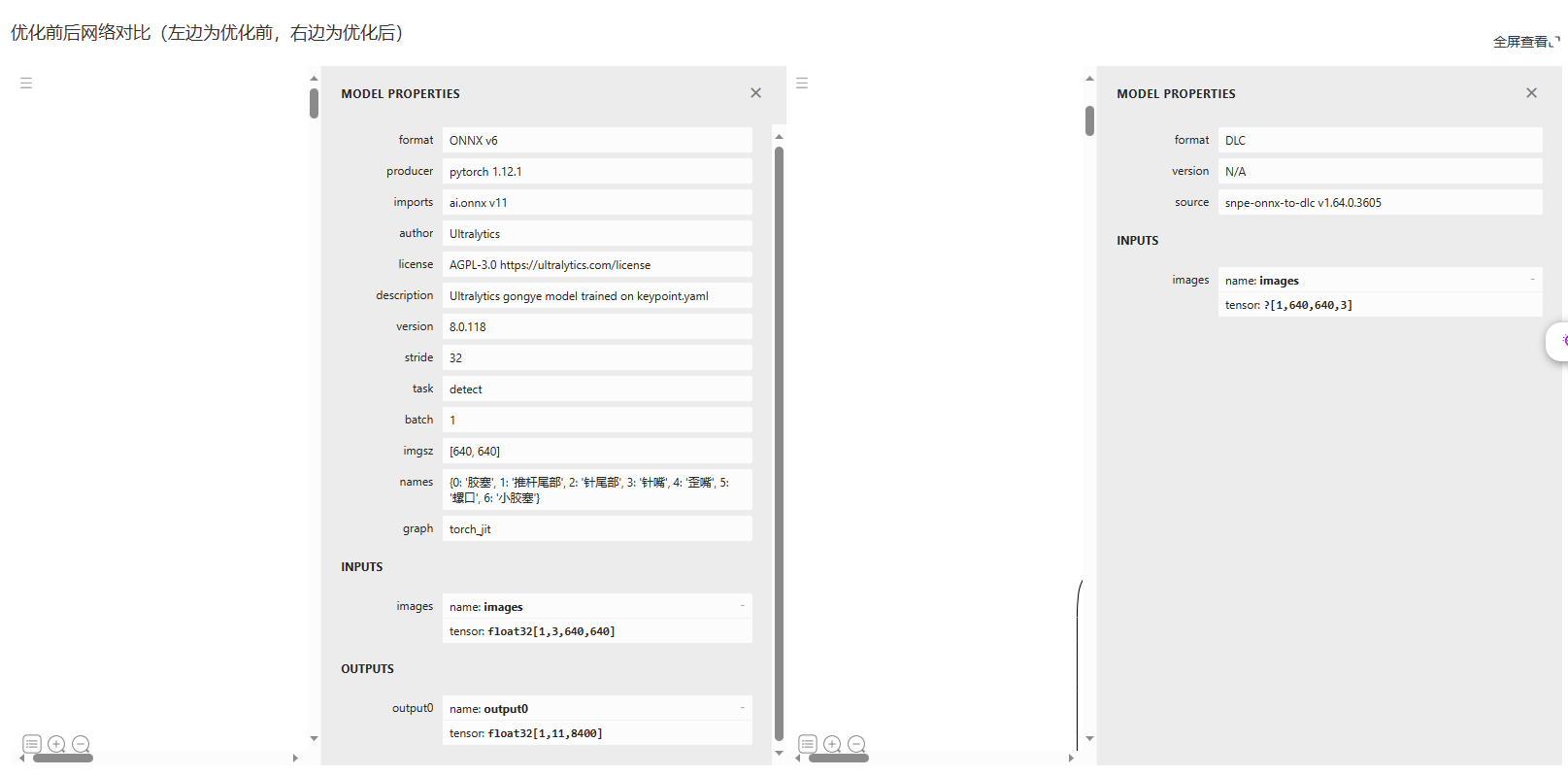
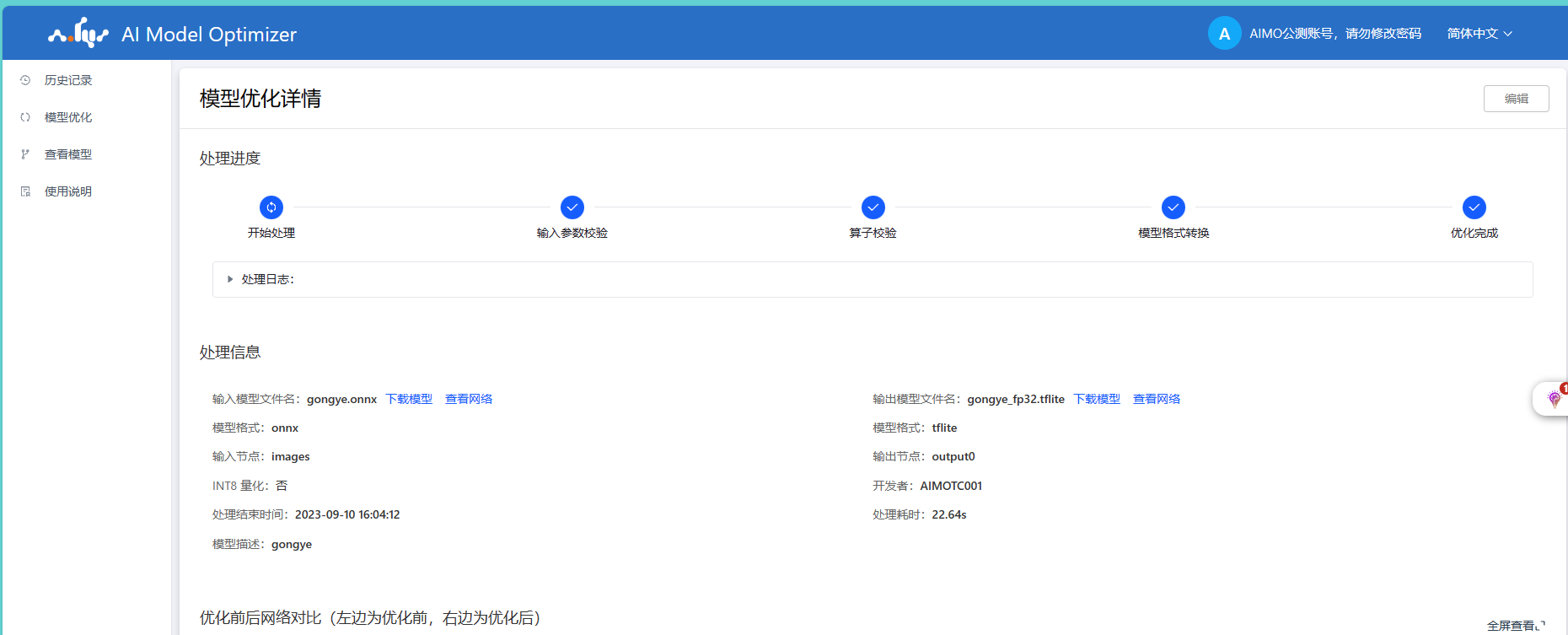

在成功将pt模型文件导出为onnx模型文件后,接下来的关键步骤是使用Aidlux平台自带的AI Model Optimizer平台将onnx模型转换为TFLite(TensorFlow Lite)和DLC(Deep Learning Container)模型,以便在不同的平台上进行部署和推理。
?为了转换为TFLite模型,我们选择了opset=11的算子版本。这一选择的原因是确保了模型在不同硬件平台上的更广泛兼容性,从而使得我们的模型能够更灵活地应用于各种部署场景。
?TFLite模型的导出和转换过程旨在优化模型的推理性能,使其适用于移动设备和嵌入式系统等资源有限的环境。这样,我们可以确保在各种应用场景下都能够高效地执行缺陷检测任务。
?此外,我们还将onnx模型转换为DLC模型,以便在Aidlux平台上进行部署。DLC模型具有高度优化的部署性能,适用于工业视觉应用,能够在Aidlux平台上实现快速而准确的缺陷检测。
?通过这些模型转换步骤,我们能够确保我们的模型在不同的部署环境中都能够顺利运行,并且能够高效地完成工业视觉缺陷检测任务。这也为我们提供了更多的灵活性,以适应不同的应用需求。
5.2. 模型代码部署
import aidlite_gpu
import cv2
from cvs import *
import numpy as np
import os
import time
model_path = "/home/gongye/tflite/gongye.tflite"
image_path = "/home/gongye/test"
NUMS_CLASS = 7
confThresh = 0.3
NmsThresh = 0.45
# 输入格式 (8400,11)
def postProcess(pres, confThresh, NmsThresh):
boxes_out = []
scores_out = []
class_out = []
for pred in pres:
pred_class = pred[4:]
box_ = pred[0:4]
# pred_class=(pred_class-min(pred_class))/(max(pred_class)-min(pred_class))
class_index = np.argmax(pred_class)
if pred_class[class_index] > 0.3:
# box=np.array([round(pred[2]-0.5*pred[0]),round(pred[3]-0.5*pred[1]),round(pred[0]),round(pred[1])])
box_ = pred[0:4] # w,h,xc,yc
box = np.array([round((pred[2] / 2 - pred[0])), round((pred[3] / 2 - pred[1])), round(pred[0] * 2),
round(pred[1] * 2)])
boxes_out.append(box)
score = pred_class[class_index]
scores_out.append(score)
class_out.append(class_index)
result_boxes = cv2.dnn.NMSBoxes(boxes_out, np.array(scores_out), confThresh, NmsThresh)
# detections=[]
boxes = []
scores = []
classes = []
for result_box in result_boxes:
index = int(result_box)
box = boxes_out[index]
score = scores_out[index]
class_type = class_out[index]
boxes.append(box)
scores.append(score)
classes.append(class_type)
return boxes, scores, classes
def draw(img, xscale, yscale, boxes, scores, classes):
width = img.shape[1]
w1 = 1620
w2 = 2350
w3 = width
S1 = []
S2 = []
S3 = []
S1_res = [False for i in range(NUMS_CLASS)]
S2_res = [False for i in range(NUMS_CLASS)]
S3_res = [False for i in range(NUMS_CLASS)]
S_res = [S1_res, S2_res, S3_res]
img_ = img.copy()
# 遍历所有box,按照分割区域将box归类
for i in range(len(boxes)):
# boxes=[x1,y1,w,h]
box = boxes[i]
score = scores[i]
class_ = int(classes[i])
# class_text=label[class_]
# detect=[round(box[0]*xscale),round(box[1]*yscale),round((box[0]+box[2])*xscale),round((box[1]+box[3])*yscale)]
detect = [round(box[0] * xscale), round(box[1] * yscale), round(box[0] * xscale + (box[2]) * xscale),
round(box[1] * yscale + (box[3]) * yscale)]
text = "{}:{:.2f}".format(label[class_], float(score))
img_ = cv2.rectangle(img_, (detect[0], detect[1]), (detect[2], detect[3]), (0, 255, 0), 2)
cv2.putText(img_, text, (detect[0], detect[1] + 10), cv2.FONT_HERSHEY_COMPLEX, 2, (0, 0, 255), 1)
# 分割为三块
if (detect[0] <= w1):
p1 = []
p1.append(detect)
p1.append(class_)
p1.append(score)
S1.append(p1)
elif (w1 < detect[0] <= w2):
p2 = []
p2.append(detect)
p2.append(class_)
p2.append(score)
S2.append(p2)
elif (w2 < detect[0] <= w3):
p3 = []
p3.append(detect)
p3.append(class_)
p3.append(score)
S3.append(p3)
# 判断每个分割图像中的结果
index = 0
for S in [S1, S2, S3]:
for i in range(len(S)):
p1 = S[i]
box_temp = p1[0]
class_temp = p1[1]
score_temp = p1[2]
S_res[index][class_temp] = True
index += 1
# 最终分割输出结果true or false
S_out = [False, False, False]
index_out = 0
for s_r in S_res:
c0 = s_r[0]
c1 = s_r[1]
c2 = s_r[2]
c3 = s_r[3]
c4 = s_r[4]
c5 = s_r[5]
c6 = s_r[6]
if (c0 & c1 & c2 & c3 & (~c4) & (~c5) & (~c6)):
S_out[index_out] = True
elif (c0 & c1 & c2 & (~c3) & (~c4) & c5 & (~c6)):
S_out[index_out] = True
index_out += 1
# 打印分割结果
cv2.putText(img_, "OK" if S_out[0] == True else "NG", (w1 - 200, 100), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 1)
cv2.putText(img_, "OK" if S_out[1] == True else "NG", (w2 - 200, 100), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 1)
cv2.putText(img_, "OK" if S_out[2] == True else "NG", (w3 - 200, 100), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 1)
return img_
label = ["rubber stopper", "push rod tail", "needle tail", "mouth", "crooked mouth", "screw mouth", "small rubber plug"]
if __name__ == "__main__":
# 1.初始化aidlite类并创建aidlite对象
aidlite = aidlite_gpu.aidlite()
print("ok")
# 2.加载模型
value = aidlite.ANNModel(model_path, [640 * 640 * 3 * 4], [8400 * 11 * 4], 4, 0)
print("gpu:", value)
# file_names=os.listdir(image_path)
# root,dirs,files = os.walk(image_path)
for root, dirs, files in os.walk(image_path):
num = 0
for file in files:
file = os.path.join(root, file)
frame = cv2.imread(file)
x_scale = frame.shape[1] / 640
y_scale = frame.shape[0] / 640
img = cv2.resize(frame, (640, 640))
# img_copy=img.co
img = img / 255.0
img = np.expand_dims(img, axis=0)
img = img.astype(dtype=np.float32)
print(img.shape)
# 3.传入模型输入数据
aidlite.setInput_Float32(img)
# 4.执行推理
start = time.time()
aidlite.invoke()
end = time.time()
timerValue = 1000 * (end - start)
print("infer time(ms):{0}", timerValue)
# 5.获取输出
pred = aidlite.getOutput_Float32(0)
# print(pred.shape)
pred = np.array(pred)
print(pred.shape)
pred = np.reshape(pred, (8400, 11))
# pred=np.reshape(pred,(11,8400)).transpose()
print(pred.shape) # shape=(8400,11)
# 6.后处理,解析输出
boxes, scores, classes = postProcess(pred, confThresh, NmsThresh)
# 7.绘制保存图像
ret_img = draw(frame, x_scale, y_scale, boxes, scores, classes)
ret_img = ret_img[:, :, ::-1]
num += 1
image_file_name = "/home/gongye/result/tfl_res" + str(num) + ".jpg"
# 8.保存图片
cv2.imwrite(image_file_name, ret_img)- 无论是TFLite还是DLC模型,都需要进行后处理来解析模型的输出结果,并提取检测到的物体框、置信度分数和类别信息。
- TFLite模型的后处理可能与DLC模型有所不同,因为模型输出的格式可能会有差异。在后处理阶段,我们需要根据模型的输出结构来解析结果。
?虽然基于TFLite和DLC的YOLOv8模型部署流程相似,但它们之间的不同之处在于模型加载和后处理步骤。TFLite模型通常更容易在不同平台上部署,而DLC模型则适用于Aidlux平台的特定需求,如需要指定处理器为高通的处理器,因此,在选择模型格式时,需要根据项目的部署要求和目标平台来进行考虑。这两种格式都为医疗注射器缺陷检测项目提供了高效的部署解决方案。
6. 实验和验证
?由于我的手机是天玑芯片,不支持dlc模型推理预测,所以这个项目中我们使用Aidlux名下的基于高通855模组改造的7T算力的边缘计算设备来进行推理预测,在使用过程中推理速度也是非常的快,所以很适合我们进行边缘终端开发。


?在模型部署完成后,我们进行了一系列实验和验证,以验证系统在实际工业生产中的性能和准确性。这些实验包括对test文件夹内的照片进行预测,并保存预测结果的照片。
使用Aidlux完成本地终端的模型推理预测视频如下:使用Aidlux平台自带的AI Model Optimizer平台将onn模型转换为tflite模型和dlc模型文件后进行推理预测_哔哩哔哩_bilibili
7. 结论
?本项目成功设计、开发和部署了一种高效的医疗注射器缺陷检测系统,使用YOLOv8模型进行目标检测,并基于AidLux平台完成本地终端部署推理。该系统具有多样性、便捷性、高质量的产品与服务以及成本效益等特点,适用于工业生产中的质量控制和缺陷检测需求。
8. 未来展望
?在训练过程中,我遇到了中文字体在验证时不能在验证图片上正常标注的问题,经过了将近一星期的解决,将网络上尽可能找到的方法都试了一遍也没有找到解决方法,最后迫不得已只能先使用英文进行代替,我初步判断可能是YOLOv8这个模型中存在的一个问题,所以在后期的实践优化中我会陆续改进这个问题,为了进一步提升系统性能,未来可考虑引入更先进的模型和算法,以及优化模型训练过程。同时,持续维护和更新系统以满足不断变化的需求,并拓展到更多工业应用领域。
9. 参考文献
[1] YOLOv8官方文档:ultralytics/ultralytics: NEW - YOLOv8 ? in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com)
[2] AidLux平台官方网站: www.aidlux.com
[3] TensorFlow Lite官方文档: www.tensorflow.org/lite
[4] DLC模型部署指南: https://docs.aidlux.com/#/intro/ai/examples/ai-examples-snpe%26more?id=snpedlc%E6%A8%A1%E5%9E%8B%E4%BD%BF%E7%94%A8%E6%A1%88%E4%BE%8B
作者:远方上 链接:https://juejin.cn/spost/7277390540851740727 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
附录
我们项目代码以完全开源只Github上,有需要的同胞可以自取
部署代码示例:yuanfangshang888/yiliao (github.com)
部署模型文件:yiliao/tflite at main · yuanfangshang888/yiliao (github.com)
实验数据和结果:yiliao/result at main · yuanfangshang888/yiliao (github.com)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。