软件绘制 & 硬件加速绘制 【DisplayList & RenderNode】
原创软件绘制 & 硬件加速绘制 【DisplayList & RenderNode】
原创
Android4.0以后,系统默认开启硬件加速来渲染视图
异同点
共同点
两者都是从SF获取一块内存,绘制都是在APP端,绘制好后都是通知SF去进行合成图层
真正的区别
真正的区别:绘制是通过CPU还是GPU完成的视图绘制。
对应区别在代码中的体现是ViewRootImpl中:
private void draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
//是否使用硬件加速 在前面setView的时候已经创建好了mAttachInfo.mHardwareRenderer
if (mAttachInfo.mHardwareRenderer != null?&&?mAttachInfo.mHardwareRenderer.isEnabled()) {
dirty.setEmpty();
mBlockResizeBuffer = false;
//硬件加速绘制 使用HardwareRenderer进行绘制
mAttachInfo.mHardwareRenderer.draw(mView, mAttachInfo, this);
} else {
//软件绘制
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {
return;
}如果开启了硬件加速则调用mHardwareRenderer.draw绘制;
没有开启则只是调用drawSoftware方法
软件绘制:
drawSoftware:利用Surface的lockCanvas向SF申请一块匿名共享内存,并获取一个普通的SkiaCanvas之后方便使用Skia库图形绘制,onDraw中对这个Canvas的操作就是对那块匿名共享内存的操作,使用之前的Skia图形库进行渲染接着SF之后去这块内存中拿到图层数据进行合成。
大致线路:
- 获取匿名共享内存\ canvas = mSurface.lockCanvas(dirty);
- 对共享内存进行操作,之后通过Ski\ mView.draw(canvas);
- 通知SurfaceFlinger进行合成图层Layer\ surface.unlockCanvasAndPost(canvas);
软件绘制的Skia图形库渲染是CPU工作完成;8.0之后,Skia间接调用OpenGl,OpenGL间接操作GPU可降低CPU压力
硬件加速绘制:
- 构建阶段:确定需要绘制的脏区域及如何绘制(绘制指令如何保存)
- 绘制阶段,单独渲染线程,取出保存的绘制指令转换为OpenGl指令
- 通过swapBuffer让GPU绘制
- 向SF发起合成的操作
构建阶段
大致流程:
- 递归遍历所有视图获取视图绘制操作,每个绘制的操作都是一个DrawOP
比如drawText,DrawLine会被抽象成drawTextOp,DrawLineOp
- 而View是一个RenderNode节点存储着当前View和子View的DrawOp,递归所有视图获取所有RenderNode的DrawOp,也叫DisplayList;通知RenderThread渲染
具体流程:
- 在View的构造方法中会创建RenderNode,硬件加速中用来标识这个View
- RenderNode进行调用canvas的操作时,会申请一个DisplayListCanvas并把具体的操作缓存到里面,也叫这个View的DrawOp树
如果是ViewGroup则递归调用子View来缓存子View的DrawOp树
- 接着将View缓存中的DrawOp树同步到RenderNode中,递归所有View执行这个操作,那么就可以知道当前根视图树的所有绘制操作也叫DisplayList。
- 向RenderThread发送一个执行DrawFrameTask的任务进行渲染(RenderThread是一个单例线程)
绘制阶段:
构建完所有的DrawOp后,交给RenderThrea去处理,区别来了:软件绘制是在主线程,硬件加速是在单独的RenderThread中去完成绘制的
摘一个网上的图:

大致流程
- DrawOp树合并
- 绘制特殊Layer:调用GPU进行绘制,GPU向共享内存写内容
- 将填充好的rawBuffer提交给SF合成
获取共享内存
DrawOp树最后是缓存在了DisplayList中,不像软件绘制是直接将绘制数据同步到匿名共享内存中。
获取时机
在performTraversals中提前获取共享内存,不像软件绘制那样等到performDraw再lockCanvas获取。
多个Surface的情况渲染线程先渲染哪个呢?
通过EGL Api获取一个EGLSurface封装原Surface的绘图数据,并设定为当前渲染窗口绑定到RenderThread中,RenderThread就会渲染绑定的Surface。
后续操作
- 进行DrawOp的合并
这里感觉像是和离屏渲染那个差不多,合并绘制纹理阴影之类的,因为画家算法是从远到近绘制的,绘制完之后如果之后的图层会影响之前的图层是无法进行操作的,所以礼品渲染将这块需要稍后可能会处理的图层单独放到一个离屏缓冲区中之后再添加。
- 特殊Layer的绘制 ;
Layer就是Surface,比如SurfaceView和TextureView
- 使用OPENGL绘制后通知SurfaceFliger进行Layer图层的合成操作
OpenGl利用GPU操作渲染数据,并将数据同步给SF
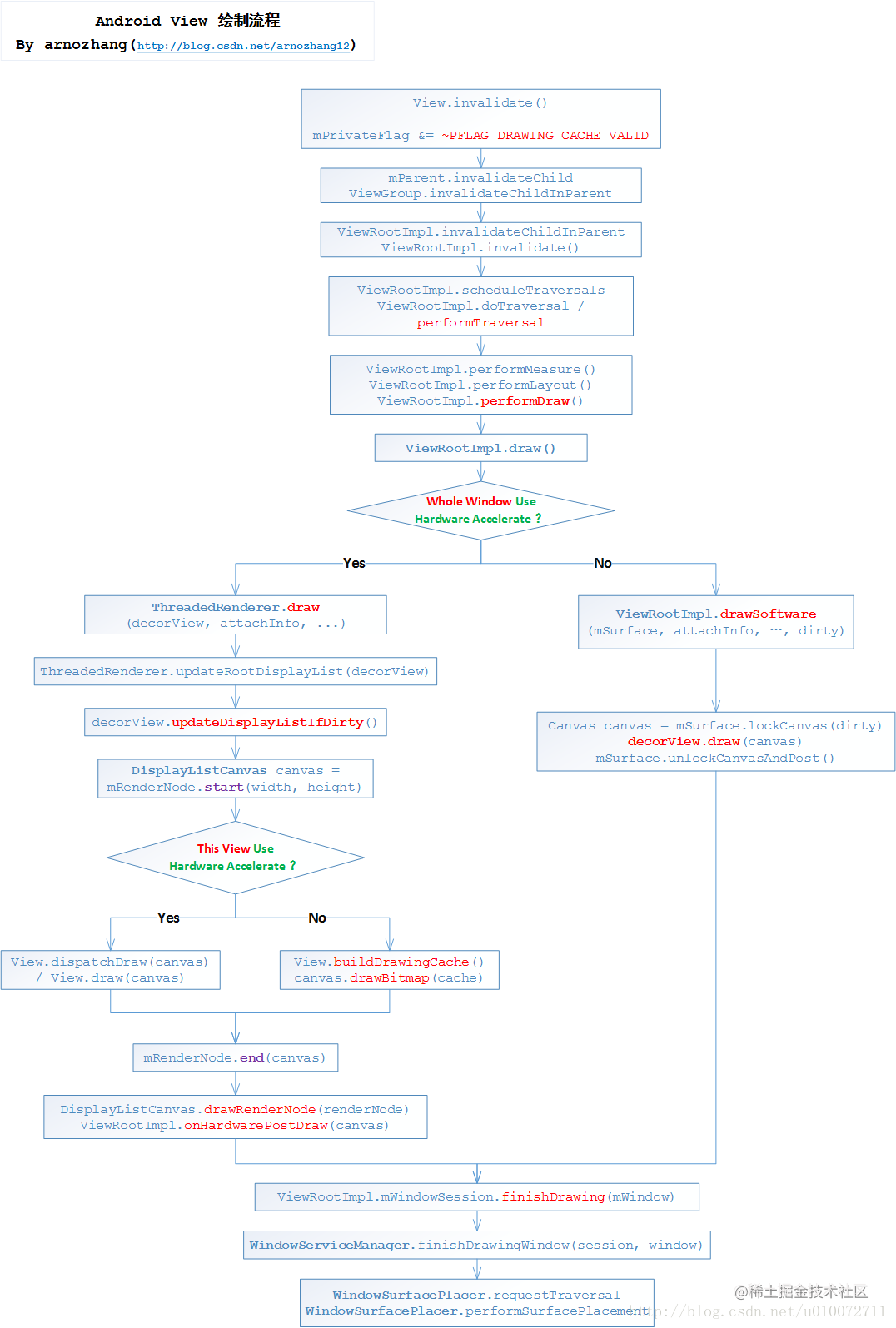
绘制流程

参考文章
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。