干货 | 基于生态环境行业文本大数据的智能助手训练与应用
干货 | 基于生态环境行业文本大数据的智能助手训练与应用


以下内容整理自2023年夏季学期大数据能力提升项目《大数据实践课》同学们所做的期末答辩汇报。大家好,我们小组的题目是基于生态环境行业文本大数据的智能助手训练与应用。本次汇报共分为四个部分。
首先是项目背景与目标。生态环境管理和污染治理领域存在数据量巨大的自然语言文本数据。由于这些文本语言数据格式繁多、逻辑性强,传统技术难以对其内含信息进行深度的挖掘和利用。项目组总结了以下用户痛点及潜在需求:
1)文本大数据难以分析挖掘:如历史存档的环境污染分析报告,难以结构化分析利用,如需提取特定信息,需要人工查找归纳,耗时耗力;
2)文本大数据难以快速检索:针对存档政策文件、法律法规,难以快速对其信息进行检索,如有需要,必须人工翻阅;
3)文本大数据难以综合利用:传统方法难以利用已有文本数据,整合最新数据信息,实现自动化文本生成。
随着深度学习自然语言处理技术的快速发展,基于大量非结构化的文本数据的信息提取、整合、推理以及内容生成成为可能。我们的项目目标是利用自然语言模型搭建框架,构建一个自然语言的语料库,最后搭建一个生态环境管理和污染治理领域的智能对话系统。

上图是目前相关技术综述,目前大语言模型的底层技术原理基本是以Transformer为主,主流的开源项目有清华的ChatGLM系列,Meta AI的LLaMA系列以及Baichuan和MOSS等。集成框架与生态有Huggingface、Langchain和FastChat,我们使用的评测平台是C-Eval。
在交互式系统设计方面,我们参考的是ChatGPT和NewBing这两个比较成功的案例,分析了它们前后端的设计方案。下图列出了Web应用程序设计框架的调研结果,选择了四个主流的应用框架及其各自特点和优缺点。考虑到项目特点及未来可扩展性,最终选择了Django+Bootstrap前后端结合的实践方案。

在项目初期我们拟定了一版技术路线图,主要的贡献就是把前后端拆解分步设计,然后把智能对话系统和大语言模型开发作为两个模块分块给不同的团队成员。随着项目的深入进行,我们的前后端需要融合打通,最后又重新讨论打通,细化了最终版本前后端融合的方案路线。
在交互式系统功能与页面设计过程中,我们首先确定了系统的核心功能及功能下的架构层次,然后对用户页面与交互流程设计层次进行了比较详细的设计,为后续的工作做好了充分的准备。

之后是大语言模型的选择与集成,我们大模型的选型原则主要考虑性能、中文支持度、参数大小、开源程度和可扩展性,根据以上五点我们最终的选型结果是ChatGLM2-6b,集成框架是Langchain。

之后是语料库的搜集与构建。我们的语料库主要有两个来源,第一个是企业方提供的环境领域文档,主要有100多篇,以txt文档为主;还有我们爬取其他环境领域内的网站收集预料共4021篇,均存储为Json格式,方便与MongoDB数据库对接。速度和稳定性问题目前均已解决,现在主要问题是pdf到Json格式转换,再text-split+embedding建立从格式到数据库的统一管道。
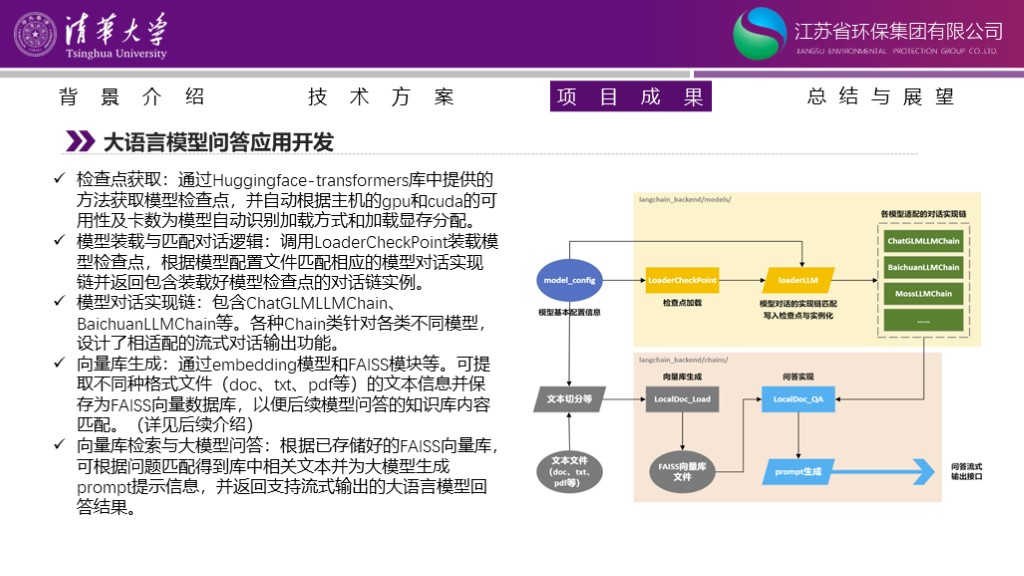
大语言模型问答应用开发的成果如下图所示。包括检查点获取、模型装载与匹配对话逻辑、模型流式对话链实现、向量库生成与存储、向量库检索与知识库问答。我们介绍核心的几点。
第一个是embedding建立知识向量库。目前大部分开源解决方案没有向量库截断存储功能,而且多个文档存储在一个向量文件里,不方便单个文档的新增与删除。所以我们做了两个改进,第一是利用非结构化数据库对向量文件进行存储和管理,第二是对于单个文档生成单个向量文件,这样可以便捷实现单篇文档的新增与删除。第二个核心功能是流式对话。Langchain原始的UI界面是gradio生成,无法进行产品化应用。因此前端我们使用了Django进行搭建,基于JavaScript脚本进行前后端交互,可以在不重新加载整个页面的前提下更新部分网页。我们也对后端启动流程进行了调整,可以实现LLM和embedding模型分开启动。对知识库检索回答的调用逻辑进行了调整,实现把生成的内容实时流式传回到前端。
下面是系统演示部分。首先再对话框输入“您好”,系统会进行较快回复。输入问题之后可以按下回车键或者点击发送键都可以发送到后台,生成对话以流式生成到前端,避免等待时间过长。当对话内容溢出界面,会自动滚动到最下方,也可以通过右侧进度条上下调整查看对话。附加功能包括加载知识库信息、查看历史对话、查看用户信息、查看知识库配置、新建公共知识库。
本项目基于通用大模型搭建了一个生态环境领域智能问答系统,通过爬虫等技术构建了生态环境语料库,目前项目所用模型为开源模型,与Langchain对接,整体框架都在开源代码基础上调整,技术创新性有待提升。系统也存在一些性能和安全隐私方面的不足,这些是由于时间和技术方面的限制,还未深入研究,未来进行推广使用还需企业进一步完善。以上就是本次汇报的全部内容。
编辑:文婧
校对:林亦霖