论文研读 - share work - QPipe:一种并行流水线的查询执行引擎
论文研读 - share work - QPipe:一种并行流水线的查询执行引擎

QPipe:一种并行流水线的查询执行引擎
QPipe: A Simultaneously Pipelined Relational Query Engine
关系型数据库通常独立执行并发的查询,每个查询都需执行一系列相关算子。为了充分利用并发查询中的数据扫描与计算,现有研究提出了丰富的技术:从缓存磁盘页以构建物化视图到优化多查询。然而,现有研究所提出的思想本质上受现代以查询为中心的引擎设计哲学所限制。理想状态下,查询引擎应该主动协调并发查询中相同运算符的执行以充分利用内存及磁盘的共同访问和中间计算的共同结果。
本文引入on-demand simultaneous pipelining(osp,按需并行流水线),一种新的查询评估范式,用于并发查询执行时最大化共享数据。通过将操作符的结果并行传输到多个父节点,实现主动、动态操作符共享。本文提出QPipe,一个以操作为中心的新型引擎,支持OSP。每个关系操作符封装到一个微引擎中,该引擎为队列中的查询任务提供服务。TPC-H实验结果表明,构建到BerkeleyDB中的QPipe,比商业关系数据库性能高2倍。
背景
现代执行引擎中运行时共享受每个查询独立执行一组运算符的范例所限制,如果缓存和缓冲池提前回收数据页,则可能错过共享机会。Qpipe在运行时识别并利用共有子表达式,不会等待有足够的查询后才进行批量优化。
传统数据库查询引擎设计遵循“单个查询,多个算子的模型”,是以查询为中心。优化器生成的执行计划驱动查询执行的过程。查询计划是树结构,每个节点都是一个算子,每个叶子都是输入点(文件扫描或索引扫描)。
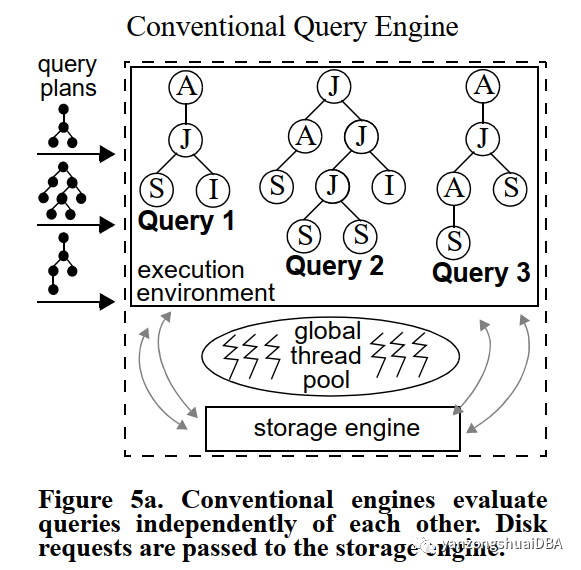
上图通用执行引擎,由两个部件构成:查询执行环境和存储引擎。查询将请求分发给磁盘子系统(存储引擎),存储引擎通过一些算法决定哪些页该缓存哪些页该驱逐,以优化资源管理。所有操作都是再没有积累了解当前查询状态下执行的,传统引擎无法充分利用查询之间的数据个工作共享机会。
QPipe引擎
1)QPipe中每个算子被提升为独立的微引擎(uEngine)。
2)微引擎以包的形式接收请求,并从队列中取出为之服务。例如,Sort 微引擎仅接收一个表的排序请求。该请求必须指定对什么进行排序,结果需要放到哪个元组缓冲区。
3)一个查询将所有微引擎独立工作组合起来的方法是将一个微引擎的输出作为下一个的输入。因此在微引擎之间有生产者-消费者的关系。
4)QPipe的输入是预编译的查询计划。查询计划通过包分发器,将执行计划转换成包作为查询树的节点,并将他们分发给不同的微引擎。
5)每个微引擎都有一个队列来缓存即将到来的请求。
6)每个微引擎都有一个线程从队列中拿出一个包并进行处理。包主要指定输出和输出元组缓存和算子操作的参数(排序属性、谓词等)。微引擎并行执行该查询。评估模型类似基于Push的执行设计。每个算子独立产生元组直到填充满父节点的输入缓冲。如果一个算子比较慢,导致输出就会有很大延迟,然后中间缓冲就会调节数据流。
7)由于QPipe涉及多个本地线程池(每个微引擎一个),所以一个高效的调度策略就显得非常重要。我们使用两级调度方法。高级别上,调度器选择下一个运行的微引擎以及在哪个CPU上执行。每个微引擎内部,又有一个本地调度器,决定工作线程的调度。本文使用轮询的调度机制,每个微引擎固定数量CPU。操作系统为工作线程提供抢占式处理器共享。由于这个简单的策略保证了系统始终都在执行,所有查询的响应时间都很低。未来会研究自适应调度策略。
8)QPipe通过将相同性值的请求分组在一起,并使用专用微引擎处理每组类似的请求,从而可以实现比传统引擎更好的资源利用率。同样,当磁盘IO收到大量请求时,他性能会更好。
QPipe并行流水线
QPipe中一个查询包表示一个给定微引擎上需要执行的查询。每当一个新包进入微引擎队列后,我们都会扫描下这个队列检查下是否有可以共享的工作。这时对每个包的参数链表进行的快速检测(当查询传到包分发器时产生的包)。比较的结果是:是否存在一个匹配以及当前操作可以重用的阶段(一个排序的文件,读取排序的文件等)。每个微引擎采用不公的贡献机制,依赖于封装的关系操作(3.2节共享机会的描述)
每个微引擎都有2个部件:OSP协调器和死锁检测器。OSP协调器为新书举报连接到正在运行的查询的数据包上奠定基础,并使算子的输出同时pipeline到所有参与的查询中。OSP协调器处理增量请求,对原始请求的执行进行必要调整。
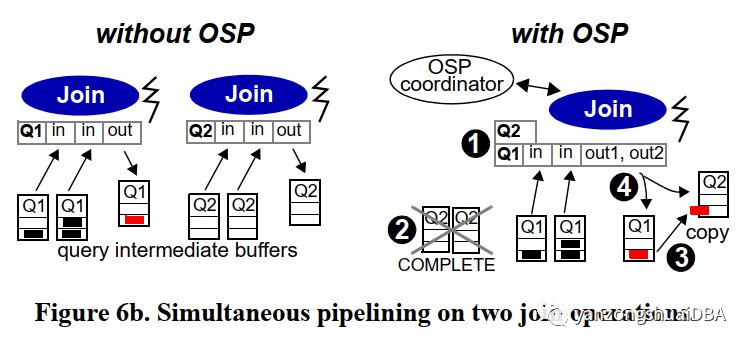
没有协调者时,Q2需要重复相同操作。而有协调者时,仅需将Q1的结果拷贝到Q2的结果缓冲中即可。此时形成一个生产者,多个消费者的关系。任何一个消费者比生产者慢时,所有查询最终都会调整成最慢消费者的处理速度。
参考
http://paragon.cs.northwestern.edu/papers/2006_QPipe_poster_ICDE.pdf
http://nms.csail.mit.edu/~stavros/pubs/demo_qpipe.pdf
本文分享自 yanzongshuaiDBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与?腾讯云自媒体分享计划? ,欢迎热爱写作的你一起参与!