tdengine入门详解
tdengine入门详解

TDengine是什么?
TDengine 是一款开源、高性能、云原生的时序数据库(Time Series Database, TSDB), 它专为物联网、车联网、工业互联网、金融、IT 运维等场景优化设计,基于C语言开发。
什么是时序数据库?时序数据产生的背景是什么?
https://db-engines.com/
基础知识
采集量
采集量是指传感器、设备或其他类型采集点采集的物理量,比如电流、电压、温度、压力、GPS 位置等,是随时间变化的,数据类型可以是整型、浮点型、布尔型,也可是字符串。随着时间的推移,存储的采集量的数据量越来越大。智能电表示例中的电流、电压、相位就是采集量。
标签
标签是指传感器、设备或其他类型采集点的静态属性,不是随时间变化的,比如设备型号、颜色、设备的所在地等,数据类型可以是任何类型。
数据采集点
数据采集点是指按照预设时间周期或受事件触发采集物理量的硬件或软件。一个数据采集点可以采集一个或多个采集量,但这些采集量都是同一时刻采集的,具有相同的时间戳。
表
TDengine 采用传统的关系型数据库模型管理数据,需要先创建库,然后创建表,之后才能插入或查询数据。TDengine 采取一个数据采集点一张表的策略,该策略会影响TDengine整体表结构的设计。
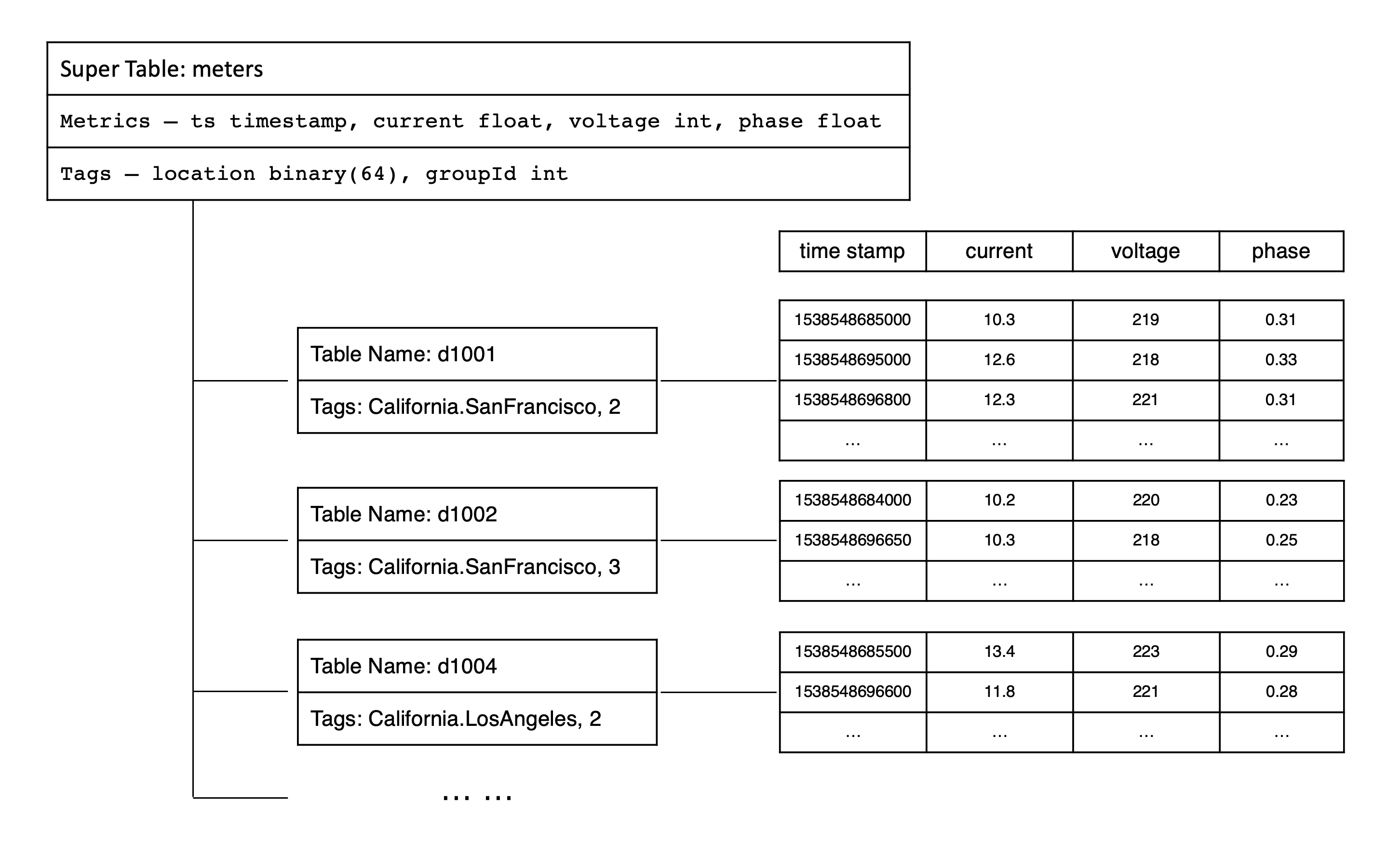
超级表
由于一个数据采集点一张表,导致表的数量巨增,难以管理,而且应用经常需要做采集点之间的聚合操作,聚合的操作也变得复杂起来。在 TDengine 的设计里,表用来代表一个具体的数据采集点,超级表用来代表一组相同类型的数据采集点集合。
子表
以超级表为模板创建的表
库
库是指一组表的集合。TDengine 容许一个运行实例有多个库,而且每个库可以配置不同的存储策略。不同类型的数据采集点往往具有不同的数据特征,包括数据采集频率的高低,数据保留时间的长短,副本的数目,数据块的大小,是否允许更新数据等等。
TDengine一些独特的设计点:
- 超级表,在 TDengine 的设计里,表用来代表一个具体的数据采集点(一个设备),超级表用来代表一组相同类型的数据采集点集合。
Device ID | Timestamp | 采集指标 | 标签 | |||
|---|---|---|---|---|---|---|
current | voltage | phase | location | groupid | ||
d1001 | 1538548685000 | 10.3 | 219 | 0.31 | California.SanFrancisco | 2 |
d1002 | 1538548684000 | 10.2 | 220 | 0.23 | California.SanFrancisco | 3 |
d1003 | 1538548686500 | 11.5 | 221 | 0.35 | California.LosAngeles | 3 |
d1004 | 1538548685500 | 13.4 | 223 | 0.29 | California.LosAngeles | 2 |
d1001 | 1538548695000 | 12.6 | 218 | 0.33 | California.SanFrancisco | 2 |
d1004 | 1538548696600 | 11.8 | 221 | 0.28 | California.LosAngeles | 2 |
d1002 | 1538548696650 | 10.3 | 218 | 0.25 | California.SanFrancisco | 3 |
d1001 | 1538548696800 | 12.3 | 221 | 0.31 | California.SanFrancisco | 2 |
为充分利用其数据的时序性和其他数据特点,TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表,上述表格中的 d1001,d1002,d1003,d1004 都需单独建表),用来存储这个数据采集点所采集的时序数据。这种设计有几大优点:
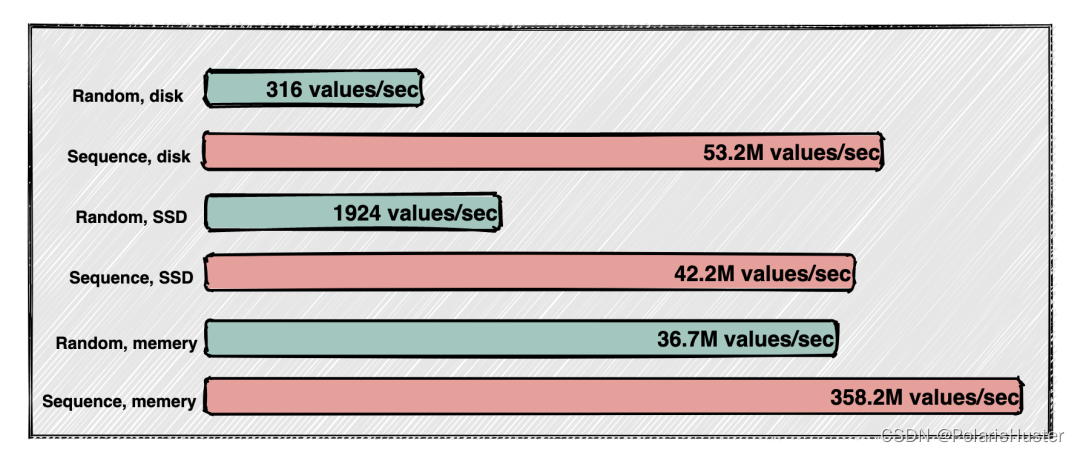
- 无锁写入:由于不同数据采集点产生数据的过程完全独立,每个数据采集点的数据源是唯一的,一张表也就只有一个写入者,这样就可采用无锁方式来写,写入速度就能大幅提升。
- 追加式写入:对于一个数据采集点而言,其产生的数据是按照时间排序的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。
- 减少随机操作:一个数据采集点的数据是以块为单位连续存储的。如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度。
- 针对性压缩:一个数据块内部,采用列式存储,对于不同数据类型,采用不同压缩算法,而且由于一个数据采集点的采集量的变化是缓慢的,压缩率更高
功能点
建立连接方式
连接器建立连接的方式,TDengine 提供两种:
- 通过 taosAdapter 组件提供的 REST API 建立与 taosd 的连接,这种连接方式简称“REST 连接”,
- 通过客户端驱动程序 taosc 直接与服务端程序 taosd 建立连接,这种连接方式简称“原生连接”。这种方式对驱动的匹配性要求较严。
- 优点:跨平台性好,不需要创建的docker镜像涵盖taosd驱动 缺点:性能比原生连接慢,性能降幅在30%左右。
查询数据
- 标准 SQL,含嵌套查询
- 时序数据特色函数
- 时序数据特色查询,例如降采样、插值、累加和、时间加权平均、状态窗口、会话窗口等
- 用户自定义函数(UDF)
多列模型与单列模型
- 多列模型适用于设备对应属性同时采集的场景(最初版本的内置网关),这样可以有较高的插入效率与存储效率
- 单列模型适用于设备对应属性不一定同时采集的场景(现在的内置网关采集模式)
查询功能
TDengine 支持如下查询功能:
- 单列、多列数据查询
- 标签和数值的多种过滤条件:>, <, =, <>, like 等
- 聚合结果的分组(Group by)、排序(Order by)、约束输出(Limit/Offset)
- 时间窗口(Interval)、会话窗口(Session)和状态窗口(State_window)等窗口切分聚合查询
- 数值列及聚合结果的四则运算
- 时间戳对齐的连接查询(Join Query: 隐式连接)操作
- 多种聚合/计算函数: count, max, min, avg, sum, twa, stddev, leastsquares, top, bottom, first, last, percentile, apercentile, last_row, spread, diff 等
实例SQL演示
- 建库
create database if not exists meter vgroups 10 buffer 10 keep 30d;
- 统计指定时间范围数据量
select _wstart, _wend,count(*) from meter.meters
where id = '89c64310-7bf0-36ba-8c16-ef9648ef88f2' interval(10m);
- 获取设备属性最新值/最老值
select last(*) from meter.meters where id = '89c64310-7bf0-36ba-8c16-ef9648ef88f2';
select first(*) from meter.meters where id = '89c64310-7bf0-36ba-8c16-ef9648ef88f2';
- 插入记录时自动建表
insert into meter.meters_89c64310-7bf0-36ba-8c16-ef9648ef88f2 using meter.meters tags('89c64310-7bf0-36ba-8c16-ef9648ef88f2') values(now(), 15, 222, 0.5);
- 同时向多个表写入数据
insert into meter.meters_89c64310-7bf0-36ba-8c16-ef9648ef88f2 using meter.meters tags('89c64310-7bf0-36ba-8c16-ef9648ef88f2')
values(now(), 15, 222, 0.5)
meter.meters_cdf2373e-457b-312c-8553-36d6c1a09c93 using meter.meters tags('cdf2373e-457b-312c-8553-36d6c1a09c93')
values(now(), 18, 235, 0.46);
- 流计算-https://docs.taosdata.com/taos-sql/stream/
create stream if not exists s1 fill_history 1 into meter.st1 as select count(*) from meter.meters interval(1h);
select * from meter.st1 ;
// 删除流
DROP STREAM IF EXISTS s1 ;
- 数据切分查询(PARTITION BY part_list)
select location,max(current),count(*) from test.meters partition by location;
- 时间窗口切分查询
select _wstart,count(*) from meter.meters
where id = 'cdf2373e-457b-312c-8553-36d6c1a09c93' and ts > '2023-07-30 13:00:00'
interval(10m);
- 状态窗口查询
select * from meter.status;
SELECT COUNT(*), FIRST(ts), status FROM meter.status STATE_WINDOW(status);
整体架构
主要逻辑单元
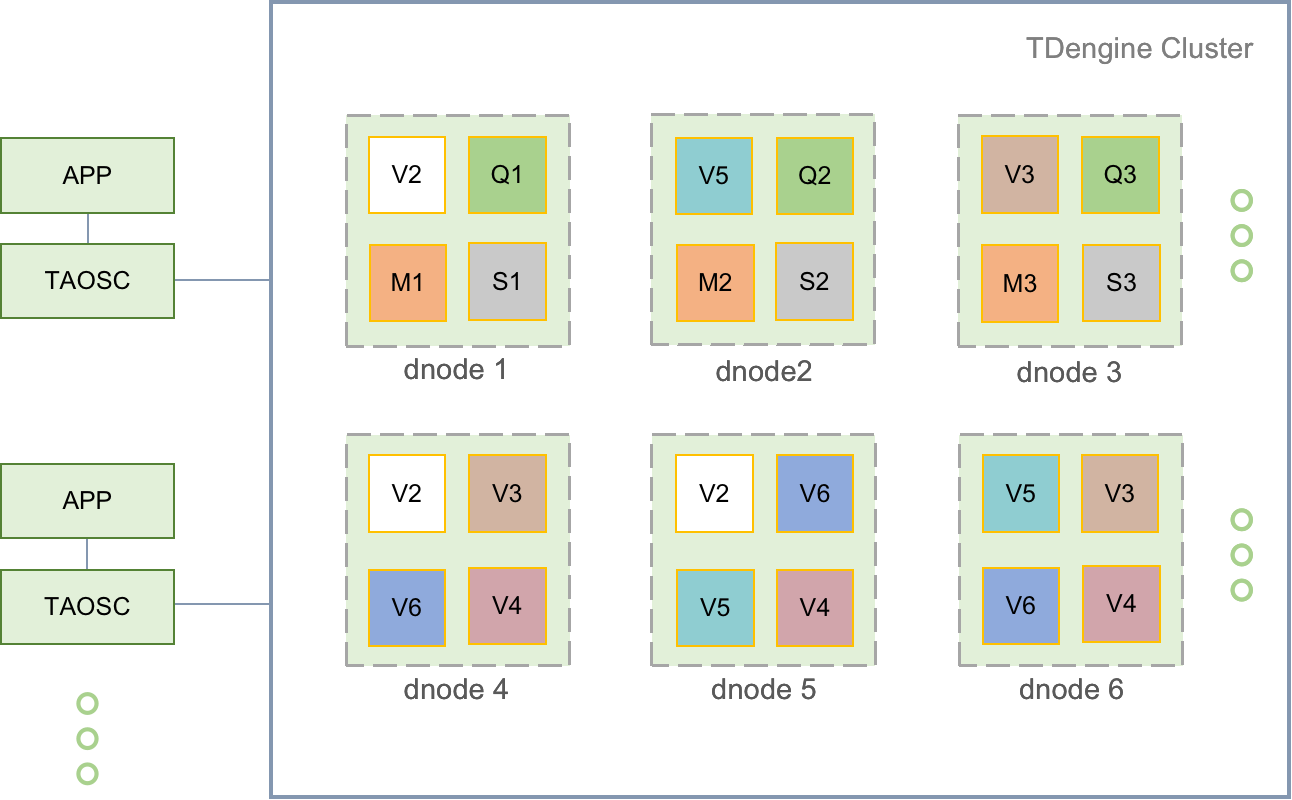
物理节点(pnode): pnode 是一独立运行、拥有自己的计算、存储和网络能力的计算机,可以是安装有 OS 的物理机、虚拟机或 Docker 容器。
数据节点(dnode): dnode 是 TDengine 服务器侧执行代码 taosd 在物理节点上的一个运行实例,一个工作的系统必须有至少一个数据节点。dnode 包含零到多个逻辑的虚拟节点(vnode),零或者至多一个逻辑的管理节点(mnode),零或者至多一个逻辑的弹性计算节点(qnode),零或者至多一个逻辑的流计算节点(snode)。
虚拟节点(vnode): 为更好的支持数据分片、负载均衡,防止数据过热或倾斜,数据节点被虚拟化成多个虚拟节点(vnode,图中 V2,V3,V4 等)。每个 vnode 都是一个相对独立的工作单元,是时序数据存储的基本单元,具有独立的运行线程、内存空间与持久化存储的路径。
管理节点(mnode): 一个虚拟的逻辑单元,负责所有数据节点运行状态的监控和维护,以及节点之间的负载均衡(图中 M)。同时,管理节点也负责元数据(包括用户、数据库、超级表等)的存储和管理,因此也称为 Meta Node。mnode 支持多副本,采用 RAFT 一致性协议,保证系统的高可用与高可靠,任何数据更新操作只能在 Leader 上进行。
计算节点(qnode): 一个虚拟的逻辑单元,运行查询计算任务,也包括基于系统表来实现的 show 命令(图中 Q)。集群中可配置多个 qnode,在整个集群内部共享使用(图中 Q1,Q2,Q3)。qnode 不与具体的 DB 绑定,即一个 qnode 可以同时执行多个 DB 的查询任务。每个 dnode 上至多有一个 qnode,由所属的数据节点的 EP 来唯一标识。
流计算节点(snode): 一个虚拟的逻辑单元,只运行流计算任务(图中 S)。集群中可配置多个 snode,在整个集群内部共享使用(图中 S1,S2,S3)。snode 不与具体的 stream 绑定,即一个 snode 可以同时执行多个 stream 的计算任务。
虚拟节点组(VGroup): 不同数据节点上的 vnode 可以组成一个虚拟节点组(vgroup),采用 RAFT 一致性协议,保证系统的高可用与高可靠。写操作只能在 leader vnode 上进行,系统采用异步复制的方式将数据同步到 follower vnode,这样确保了一份数据在多个物理节点上有拷贝。
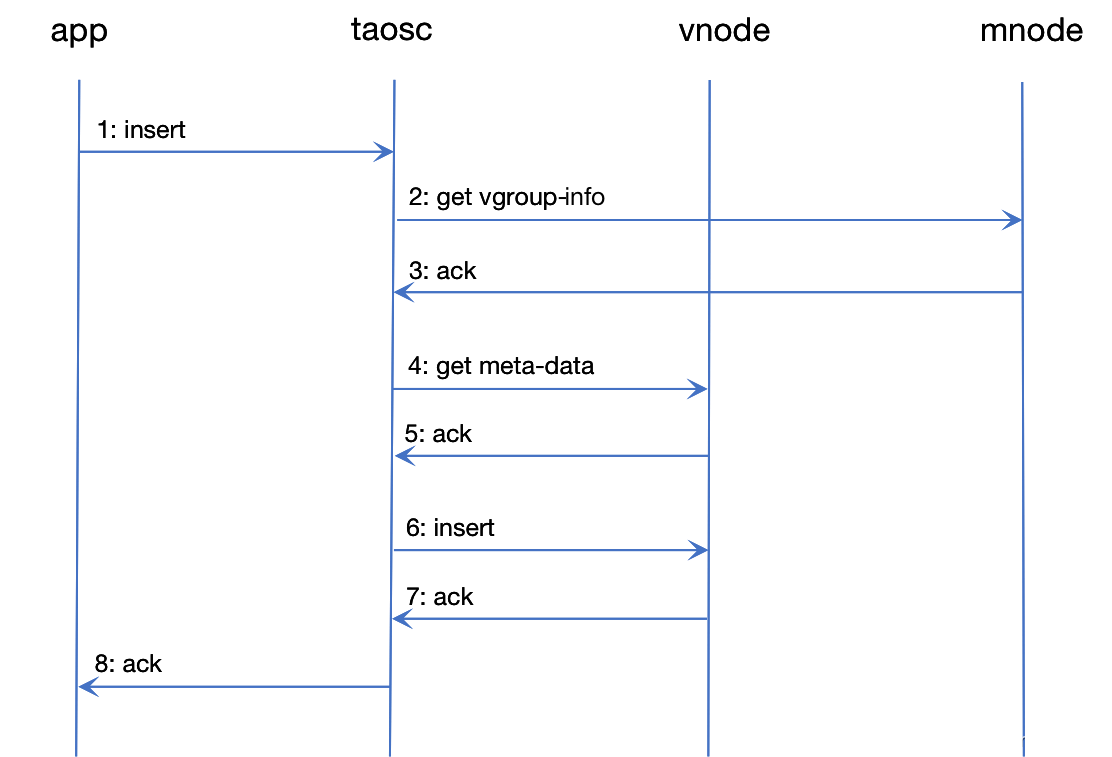
Taosc taosc 是 TDengine 给应用提供的驱动程序(driver),负责处理应用与集群的接口交互,用都是通过 taosc 而不是直接连接集群中的数据节点与整个集群进行交互的。这个模块负责获取并缓存元数据;将插入、查询等请求转发到正确的数据节点;在把结果返回给应用时,还需要负责最后一级的聚合、排序、过滤等操作。
存储模型
TDengine 存储的数据包括采集的时序数据以及库、表相关的元数据、标签数据等,这些数据具体分为三部分:
- 时序数据:存放于 vnode 里,由 data、head 和 last 三个文件组成,数据量大,查询量取决于应用场景。容许乱序写入,但暂时不支持删除操作。
- 数据表元数据:包含标签信息和 Table Schema 信息,存放于 vnode 里的 meta 文件,支持增删改查四个标准操作。支持多核多线程并发查询。只要计算内存足够,元数据全内存存储,千万级别规模的标签数据过滤结果能毫秒级返回。在内存资源不足的情况下,仍然可以支持数千万张表的快速查询。
- 数据库元数据:存放于 mnode 里,包含系统节点、用户、DB、STable Schema 等信息,支持增删改查四个标准操作。这部分数据的量不大,可以全内存保存,而且由于客户端有缓存,查询量也不大。
与典型的 NoSQL 存储模型相比,TDengine 将标签数据与时序数据完全分离存储,它具有两大优势:
- 能够极大地降低标签数据存储的冗余度:一般的 NoSQL 数据库或时序数据库,采用的 K-V 存储,其中的 Key 包含时间戳、设备 ID、各种标签。
- 能够实现极为高效的多表聚合查询:做多表之间聚合查询时,先把符合标签过滤条件的表查找出来,然后再查找这些表相应的数据块,这样大幅减少要扫描的数据集,从而大幅提高查询效率。
数据分片
TDengine 是通过 vnode 来实现数据分片的,通过一个时间段一个数据文件来实现时序数据分区的。
vnode(虚拟数据节点)负责为采集的时序数据提供写入、查询和计算功能。为便于负载均衡、数据恢复、支持异构环境,TDengine 将一个数据节点根据其计算和存储资源切分为多个 vnode。这些 vnode 的管理是 TDengine 自动完成的,对应用完全透明。
数据分区
TDengine 除 vnode 分片之外,还对时序数据按照时间段进行分区。每个数据文件只包含一个时间段的时序数据,时间段的长度由 DB 的配置参数 days 决定。这样分区便于高效实现数据的保留策略,只要数据文件超过规定的天数(系统配置参数 keep),将被自动删除。
负载均衡
每个 dnode 都定时向 mnode(虚拟管理节点)报告其状态(包括硬盘空间、内存大小、CPU、网络、虚拟节点个数等),因此 mnode 了解整个集群的状态。基于整体状态,当 mnode 发现某个 dnode 负载过重,它会将 dnode 上的一个或多个 vnode 挪到其他 dnode。
多级存储
多级存储功能仅企业版支持,
生态

使用注意事项
- 时间戳:
- 所有表的第一列都必须是时间戳类型,且为其主键,TDengine 要求插入的数据必须要有时间戳
- 时间戳不同的格式语法会有不同的精度影响。字符串格式的时间戳写法不受所在 DATABASE 的时间精度设置影响;而长整形格式的时间戳写法会受到所在 DATABASE 的时间精度设置影响。例如,时间戳"2021-07-13 16:16:48"的 UNIX 秒数为 1626164208。则其在毫秒精度下需要写作 1626164208000,在微秒精度设置下就需要写为 1626164208000000,纳秒精度设置下需要写为 1626164208000000000。
- 一次插入多行数据时,不要把首列的时间戳的值都写 NOW。否则会导致语句中的多条记录使用相同的时间戳,于是就可能出现相互覆盖以致这些数据行无法全部被正确保存。其原因在于,NOW 函数在执行中会被解析为所在 SQL 语句的客户端执行时间,出现在同一语句中的多个 NOW 标记也就会被替换为完全相同的时间戳取值。
- 允许插入的最老记录的时间戳=now - KEEP 值,超过该范围无法插入
- json格式,目前版本json只支持tag,不支持其他数据列
- 长度调整,只支持调大,不支持调小
- 同一条sql写入vnode,彼此间执行结果不影响
这是因为多个子表可能分布在不同的 VNODE 上,客户端将 INSERT 语句完整解析后,将数据发往各个涉及的 VNODE 上,每个 VNODE 独立进行写入操作。如果某个 VNODE 因为某些原因(比如网络问题或磁盘故障)导致写入失败,并不会影响其他 VNODE 节点的写入。
性能对比
TDengine vs Cassandra性能对比 https://www.taosdata.com/engineering/573.html
扩展阅读
- https://db-engines.com/en/blog_post/71 时序数据库产生的背景