Windows server 2016——查询优化与事务处理
Windows server 2016——查询优化与事务处理

- 作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。?
- 公众号:网络豆
- ?座右铭:低头赶路,敬事如仪
- 个人主页:?网络豆的主页?????
写在前面
本系列文章将会讲解SQL server 中 查询优化与事务处理,了解使用索引工具,使用视图,存储过程,触发器等操作。
视频教程:Windows server 2016 查询优化与事务处理
介绍
SQL Server是由微软公司开发的关系型数据库管理系统,现在是全世界主流数据库之一。它具备方便使用、可伸缩性好、相关软件集成程度高等优势,能够从单一的笔记本上运行或以高倍云服务器集群为基础,或在这两者之间任何一种方式上运行。
?一.索引
1.索引是什么
索引是SQL Server编排数据内部方法,通过索引可以快速查找数据,而无需扫描整个表。
类似于字典的音节索引页似的,可以快速查找到,你所想要找到的字而无需一页一页翻。
?2.索引的分类
- 唯一索引:不允许两行具有相同的索引值,如果尝试插入一个已经存在的值,数据库将会拒绝这个操作。
- 主键索引:要求主键中的每个值是唯一的,主键索引通常用于唯一标识每一行,以便于快速查找和连接数据。
- 聚集索引:数据存放的物理顺序与索引顺序相同,聚集索引可以加快基于索引列的数据检索操作
- 非聚集索引:数据存放的物理顺序与索引顺序不相同
- 复合索引:将多个列组合而成的索引
- 全文索引:一种特殊类型的基于标记的功能性索引,全文索引通常用于处理大量文本数据,如文章、博客帖子或文档
3.唯一索引和主键索引的区别:
????? 主键索引一定是唯一索引,唯一索引不一定是主键索引。主键索引一定是聚集索引。唯一索引不一定是聚集索引。
4.选择索引的标准
- 频繁搜索的列
- 经常用作查询选择的列
- 经常排序、分组的列
- 经常用作连接的列(主键/外键)
- 大量数据
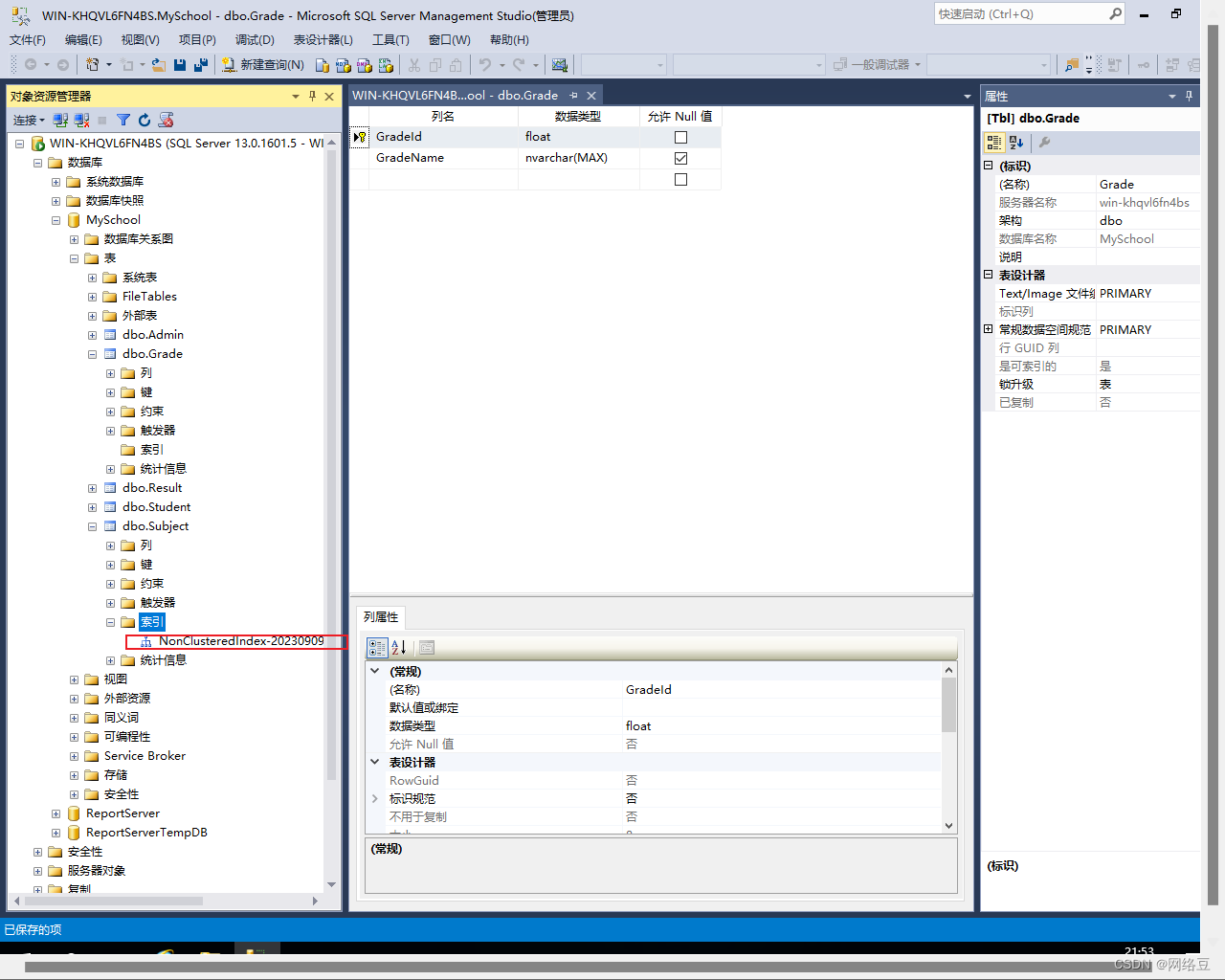
5.创建索引
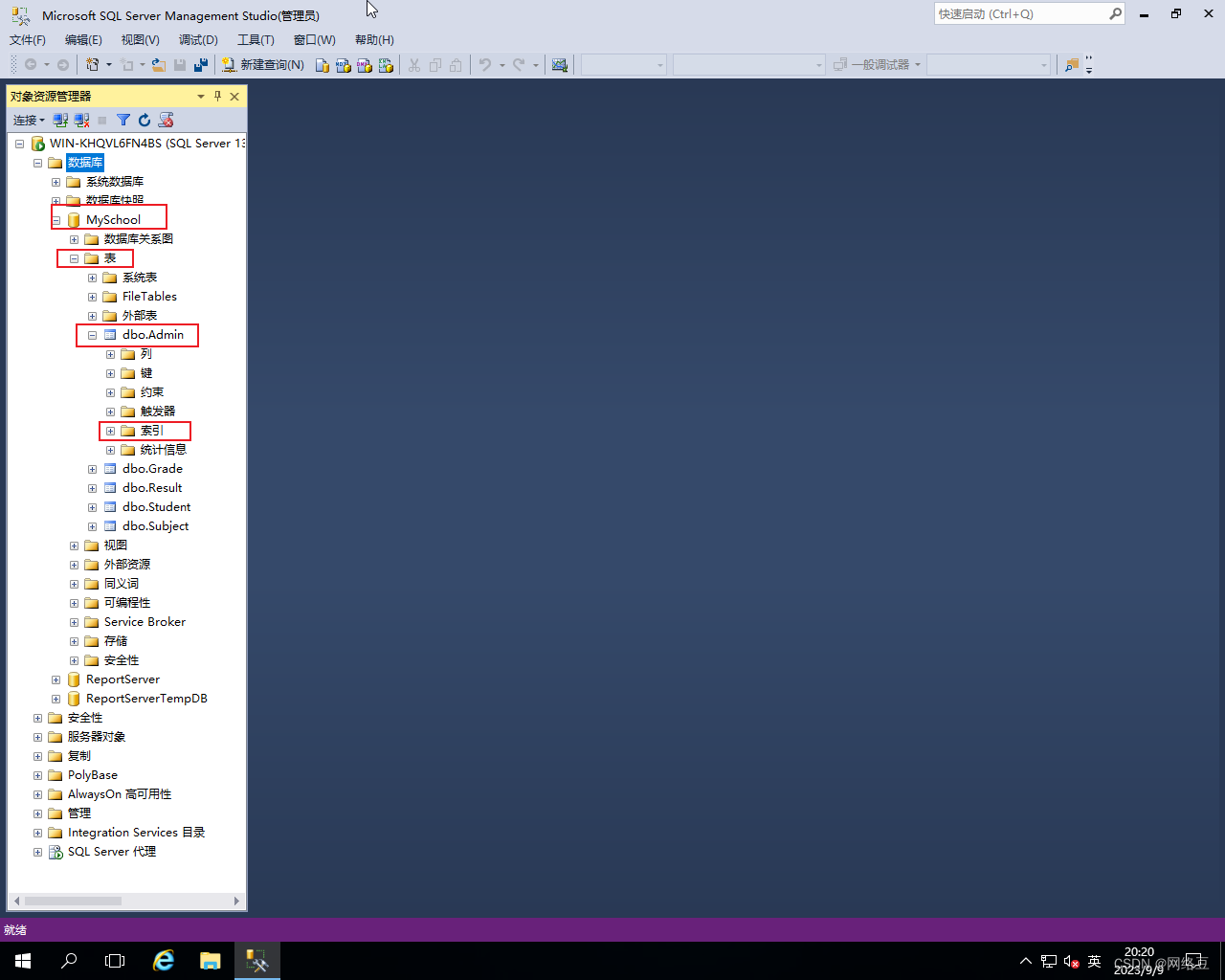
1.选中一张表,展开表,找到索引,右击索引——新建索引
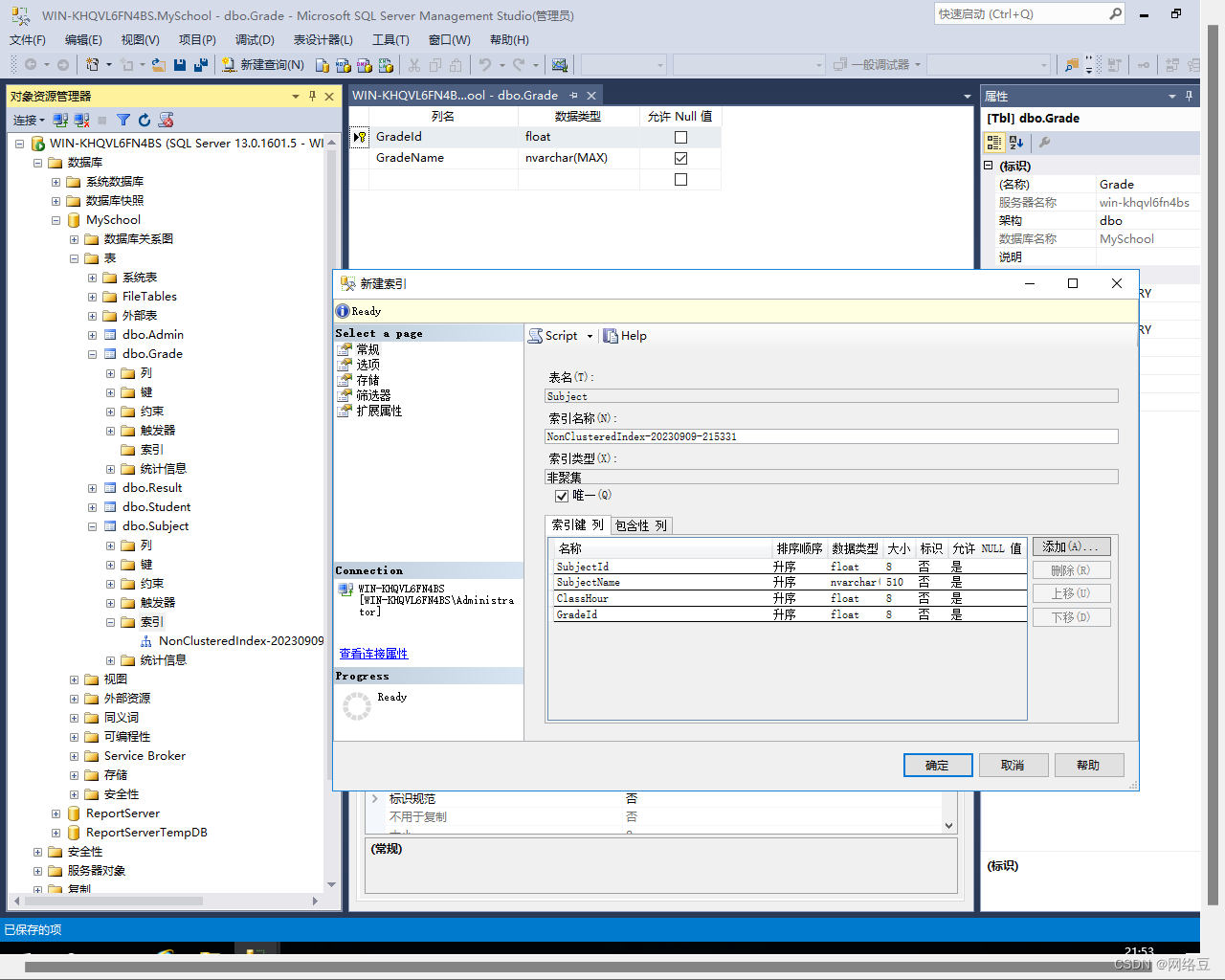
2.在新建索引对话框中,指定索引名称,可以选择给那一列创建索引,创建什么类型的索引,完成后点击确定,就创建好了一个新的索引。
二.视图
1.什么是视图
- 视图是一种虚拟表,通常是作为来自一个或多个表的行或列的子集创建的。
- 视图直接显示来自表中的数据,只供查看,无法修改。
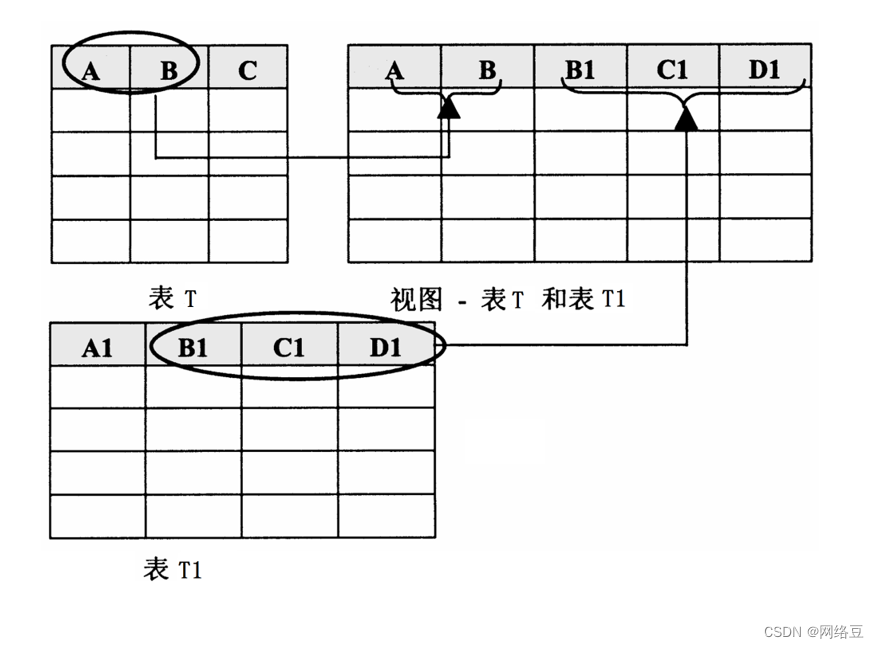
?视图的作用
- 筛选表中的数据
- 防止未经许可的用户访问敏感数据
- 将多个物理数据表抽象
使用视图的好处
- 对于最终的用户:结果更容易理解,获取数据更容易。
- 对于开发:限制数据检索更容易,维护应用程序更方便
创建视图:
?? 1.展开数据库——找到视图,右击视图——新建视图
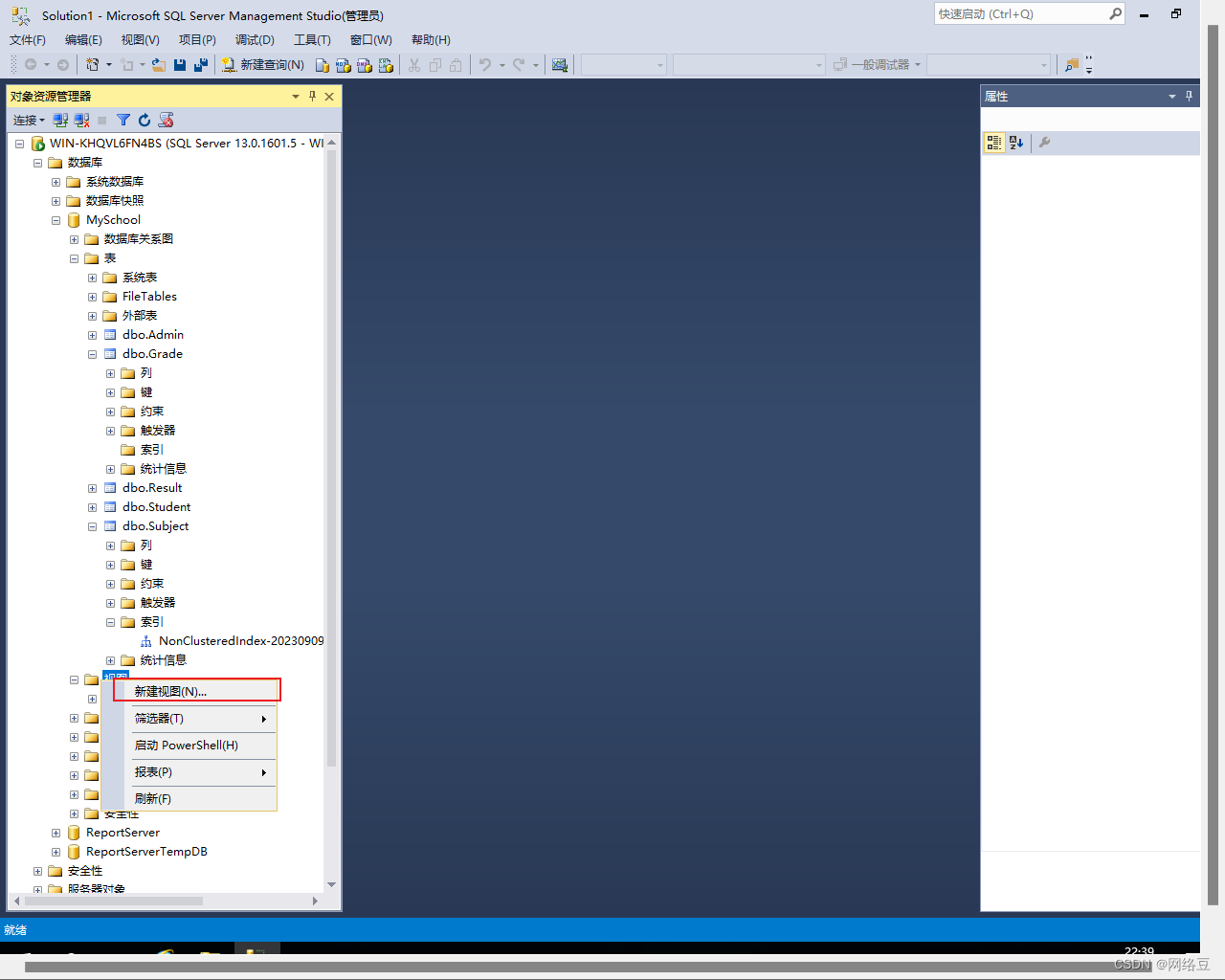
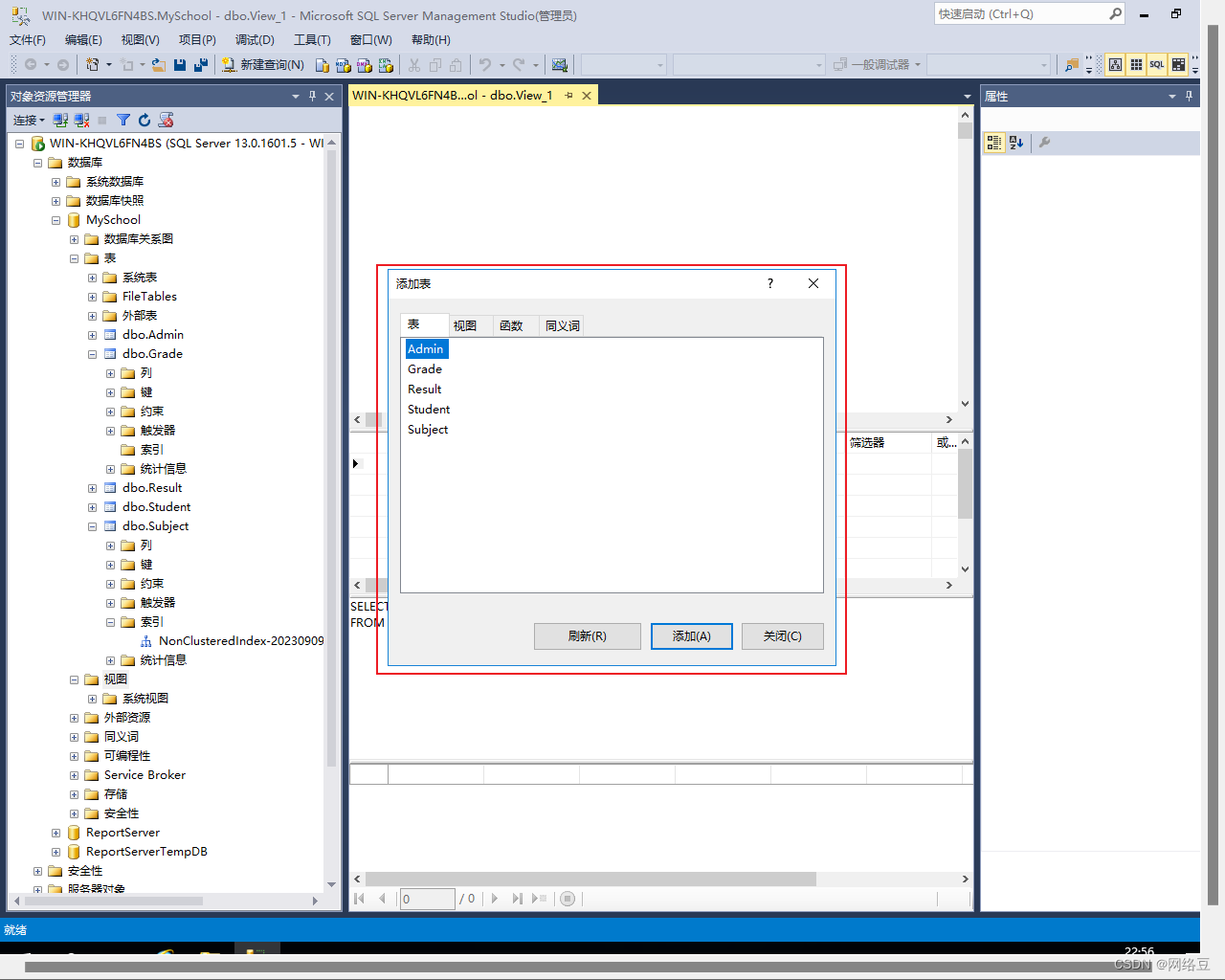
?2.选择要添加到视图中的表,选择表然后点击添加。可以添加多张表。添加完成后点击关闭。
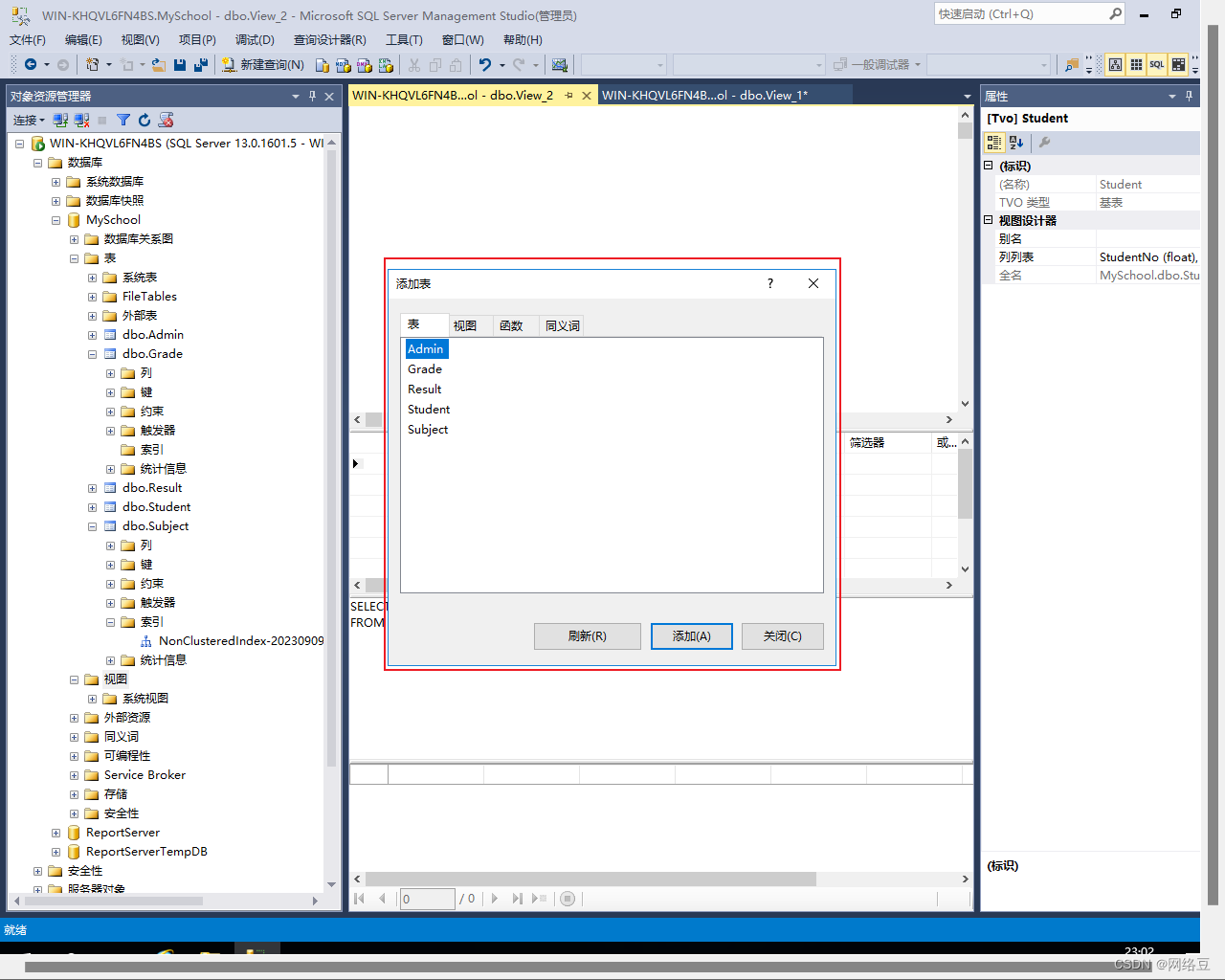
手动选择表之间的连接条件,并选择最终要在视图中显示的列。(在要显示的列前面打钩)
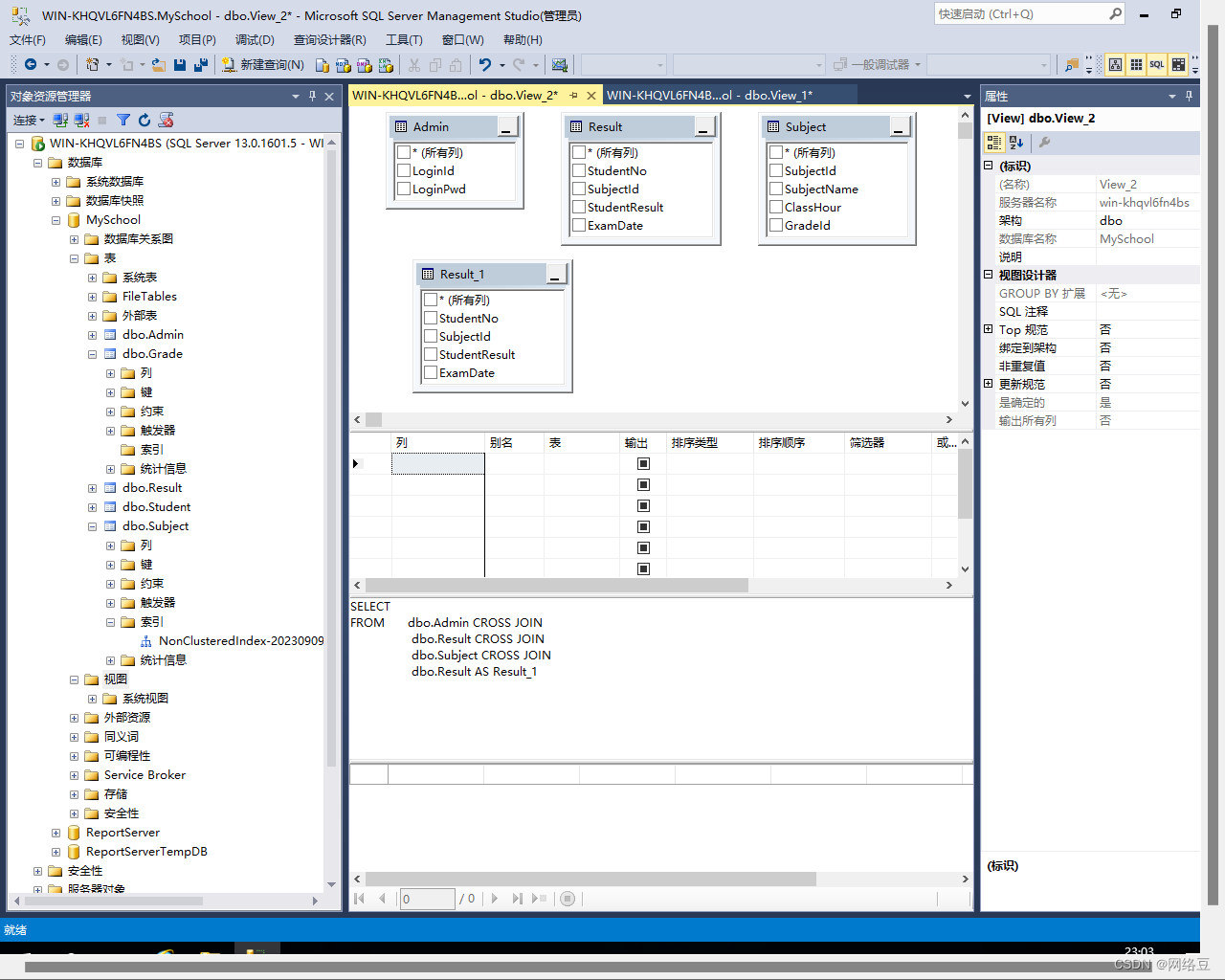
配置完后,点击保存
?三.存储过程
1.什么是存储过程
存储过程是SQL语句和控制语句的预编译集合,保存在数据库里,可由应用程序调用执行。
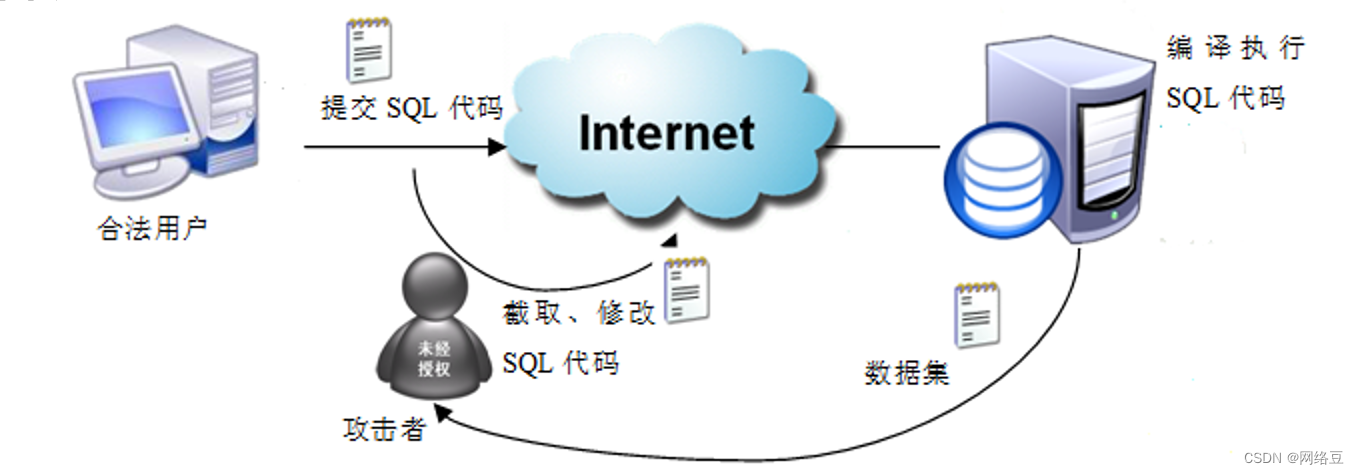
2.为什么需要存储过程
- 数据不安全
- 网络流量大
- 影响应用程序的运行性能
- 从客户端到网络服务器发送SQL代码并执行不妥当
3.使用存储过程的优点
- 模块化程序设计
- 执行速度快,效率高
- 减少网络流量
- 具有良好的安全性
4.存储过程分类
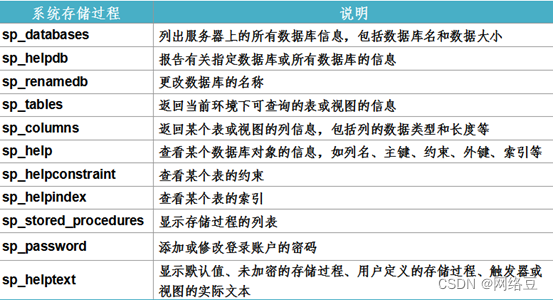
(1)系统存储过程
常用的系统存储过程(以“sp_”开头,存放在Resource数据库中)
?? 2.常用的扩展存储过程(以“xp_”开头,以DLL形式单独存在)

? 扩展存储过程默认被关闭,需要启用
(2)用户自定义的存储过程
调用执行存储过程:
EXEC[UTE] 存储过程名 [参数值]创建存储过程:
(使用T-SQL语句创建)
Create proc 存储过程名称
[@参数1 数据类型]
[@参数1 数据类型]
As
SQL 语句使用SSMS创建
?四. 触发器
1.什么是触发器
- 是在对表进行插入、更新或删除操作时自动执行的存储过程
- 用于强制业务规则,可以定义比用 CHECK 约束更为复杂的约束
- 通过事件触发而被执行的
2.分类
INSERT触发器:当向表中插入数据时触发
UPDATE触发器:当更新表中某列、多列时触发
DELETE触发器:当删除表中记录时触发
触发器涉及到两张表(delete表和inserted表)(由系统管理,用户不可以修改,仅做了解)
修改操作 | inserted表 | deleted表 |
|---|---|---|
增加(INSERT)记录时 | 存放新增的记录 | —— |
删除(DELETE)时 | —— | 存放被删除的记录 |
修改(UPDATE)时 | 存放用来更新的新记录 | 存放更新前的记录 |
3.触发器的作用
???? 强化约束(实现比CHECK语句更为复杂的约束)
???? 跟踪变化(侦测数据库内的操作,从而不允许数据库中未经许可的指定更新和变化)
???? 级联运行(侦测数据库内的操作,并自动地级联影响整个数据库的各项内容)
?4.创建触发器
(1)使用SSMS创建
(2)使用T-SQL语句创建触发器
Create trigger 触发器名称
On 执行触发器的表
[with encryption] #加密syscomments 表中包含create trigger语句文本的条目。
From [delete,insert,update]
As
SQL 语句实战案例
创建视图
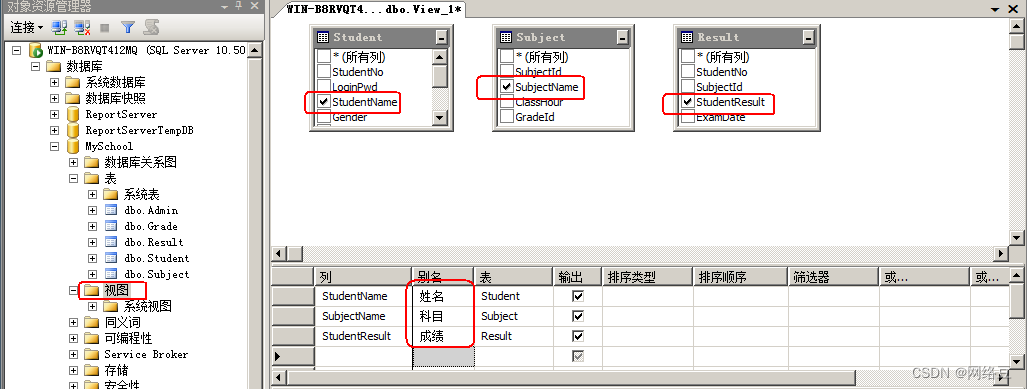
方法一:在图形界面下创建视图(以Myschool数据库为例)
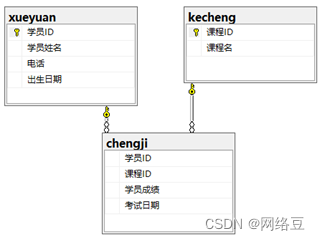
创建一个视图,分别来自三个表的三个列,并重命名列,生成的视图名为student_info,如下图所示:
实验案例一:验证索引的作用
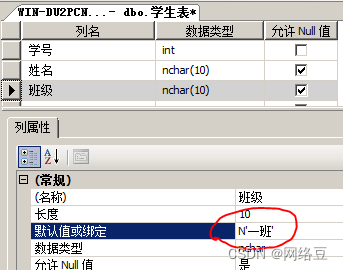
- 创建数据库test,再创建一个数据量大的表,名称为“学生表”,分别有三列,学号,姓名和班级,如下图所示,学号为自动编号,班级为默认值“一班”。
- 向表中插入大量数据,数据越多,验证索引的效果越好。
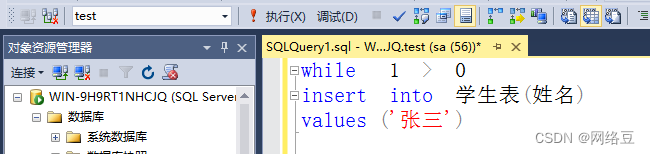
使用语句完成:While 1>0? Insert into 学生表(姓名)? values(‘张三’)
上面语句是一个死循环,除非强制结束,如果1大于0就会一直向表中插入姓名
如下图所示:
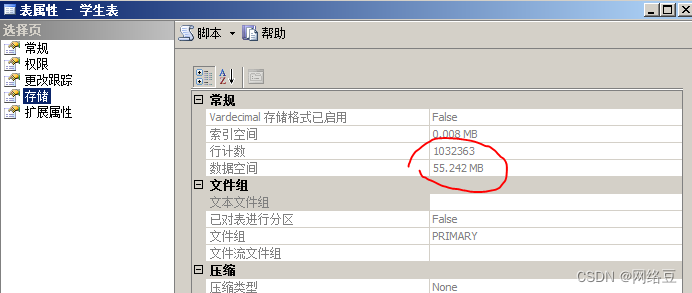
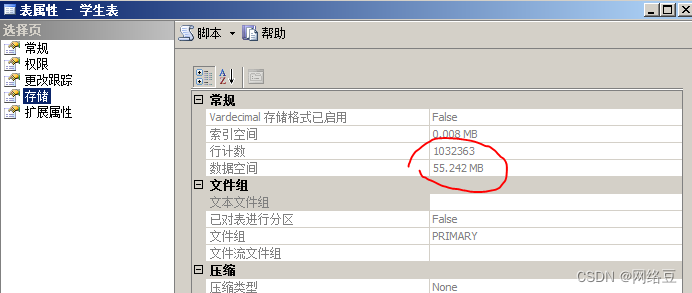
等待5分钟左右,打开表的属性,查看表的行数,当前为1032363,如下图所示:
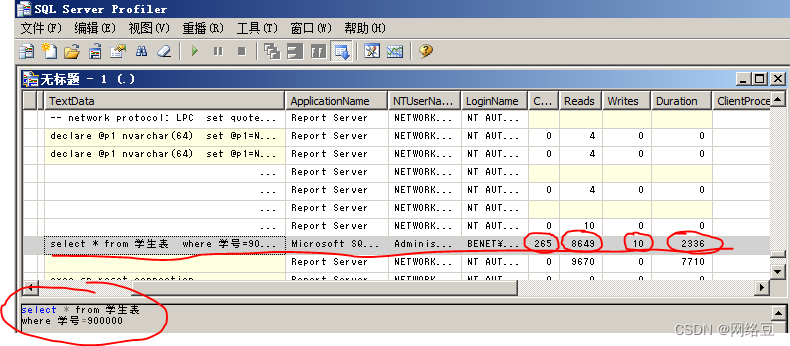
使用语句查询第900000行的数据,Select * from 学生表 Where 学号=900000

4、打开“sql server? 2016? profiler ”工具进行跟踪,如下图所示:
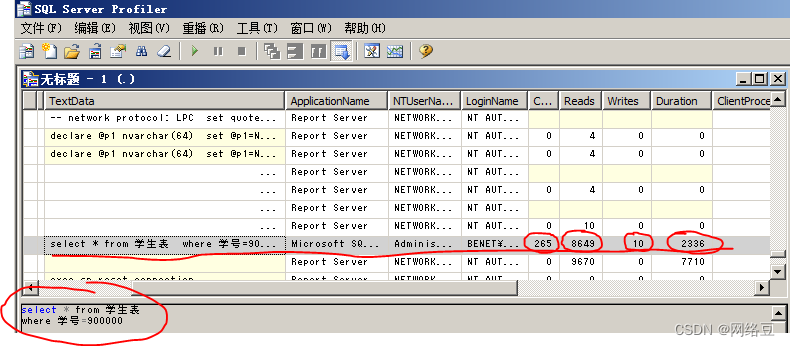
打开“sql server profiler ”工具查看跟踪的信息,发现查询时间很长,cpu工作了265毫秒,reads:读了8649次,writes:写了10次,duration:总计花费2336毫秒完成查询。
为了下面分析文件更准确,多执行几次Select * from 学生表 Where 学号=900000
然后把跟踪的结果保存在桌面上:
- 打开“SQL server 2016数据库引擎优化顾问”,添加跟踪文件,进行分析,发现索引建议,需要建立索引。
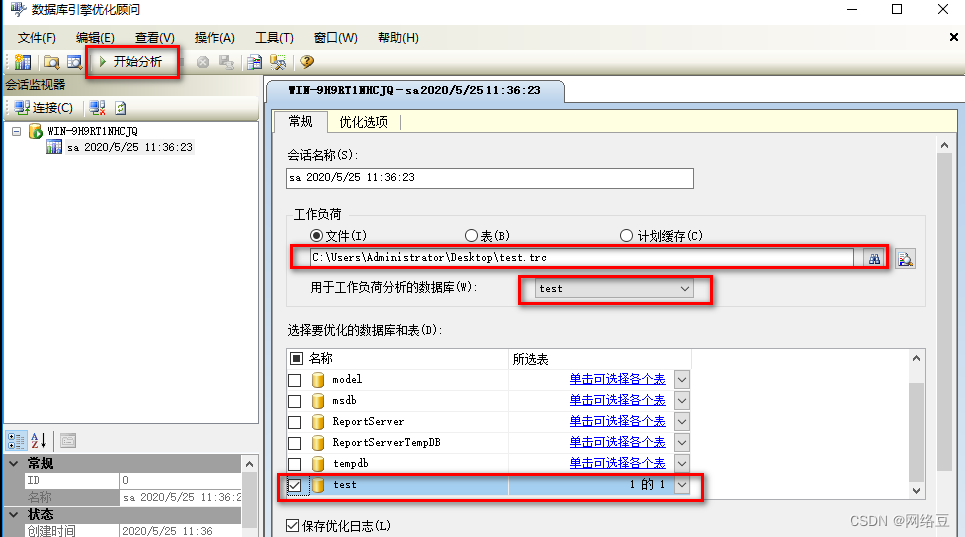
注意选择test数据库中的学生表,然后点击“开始分析”

索引类型为clusterd(聚集索引),索引列为“学号”。
- 按照“数据库引擎优化顾问”的索引建议建立聚集索引,并且选择“唯一”
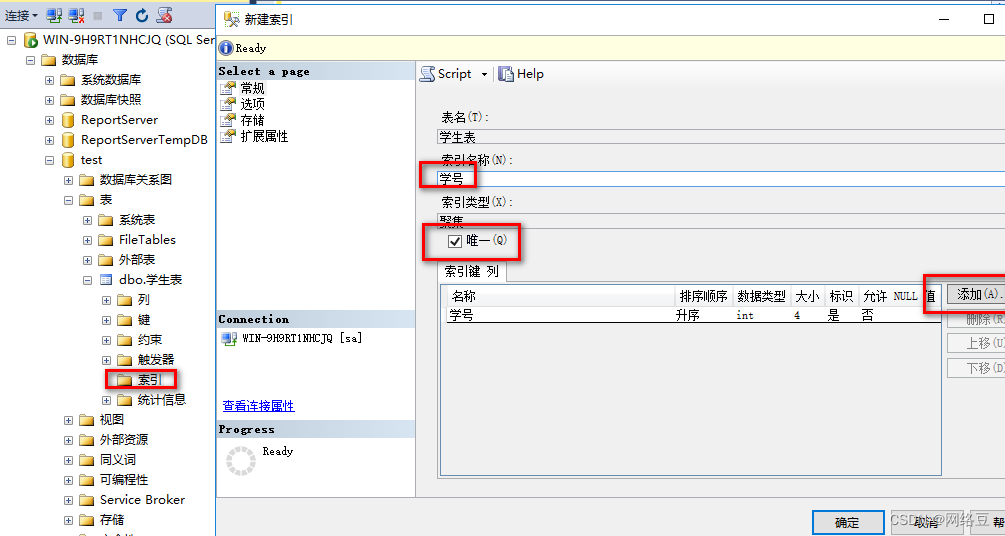
- 再次执行Select * from 学生表Where 学号=900000
- 打开sql server profiler查看跟踪的时间,发现查询时间大幅提升,说明索引可以提高查询速度。
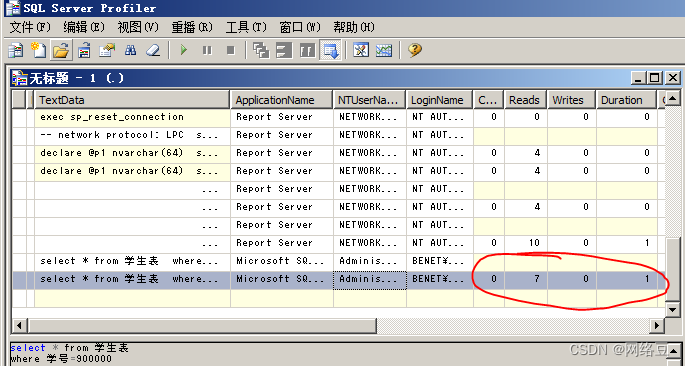
发现总计时间为1毫秒,几乎忽略不计
实验案例二:分别练习创建各种索引
- 创建聚集索引
目前tstudent表中没有任何索引也没有主键
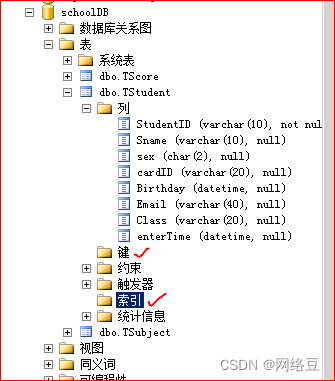
为tstudent表创建聚集索引
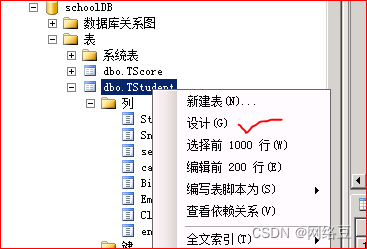
选中studentID,单击左上侧的主键按钮
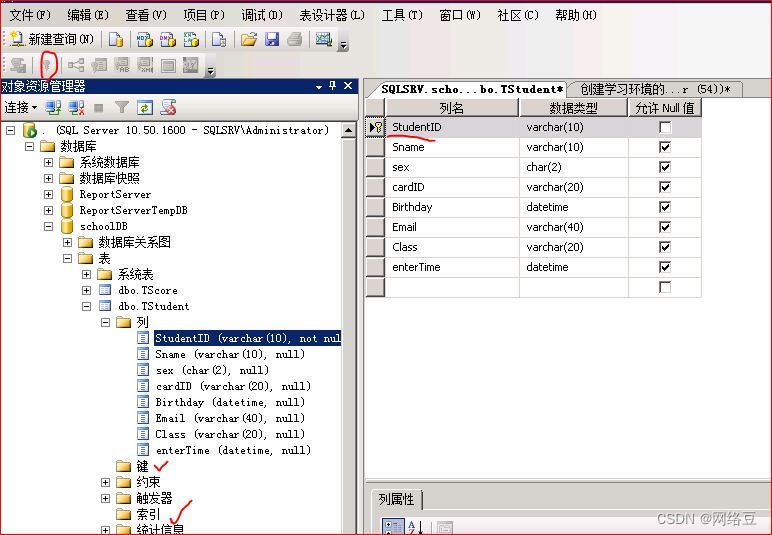
为Tstuden表的studentID创建主键就同时创建了聚集索引
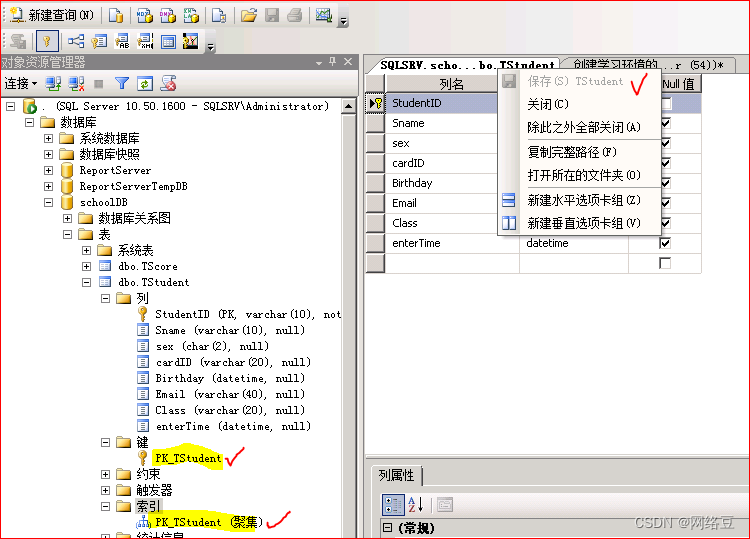
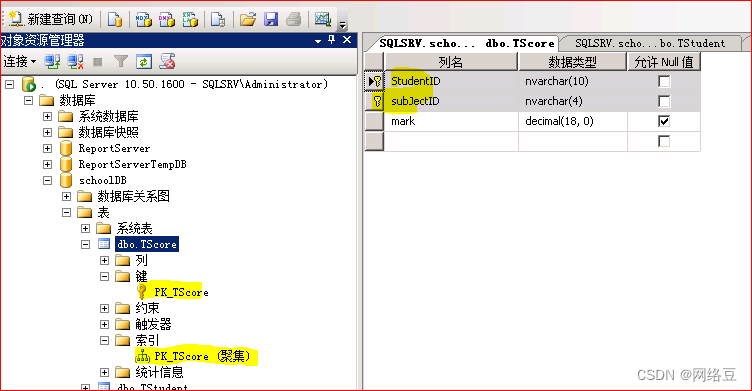
2、创建组合索引
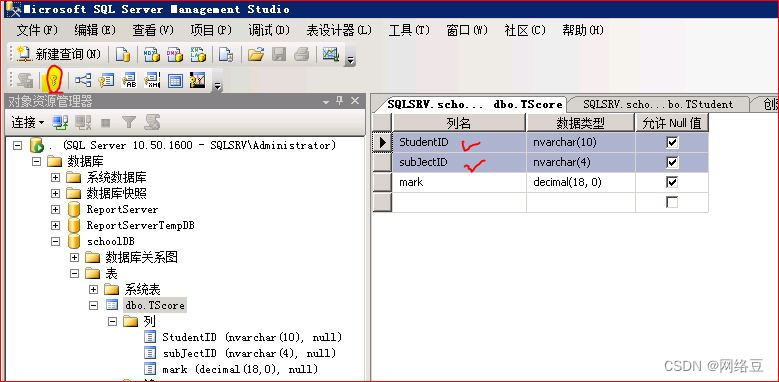
为成绩表创建组合索引,因为一个学生不能为一门学科录入两次成绩,所以将成绩表中的studentID和subjectID创建组合索引
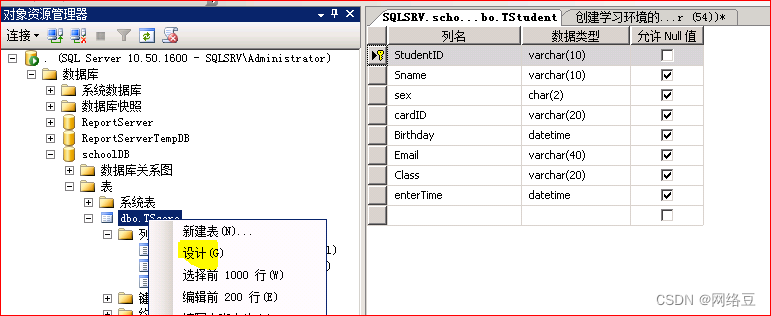
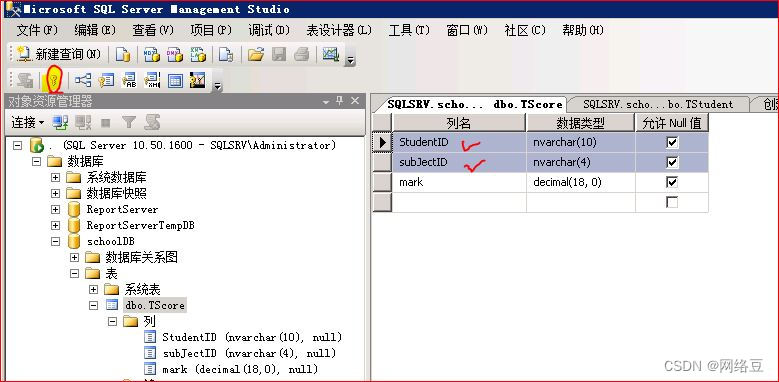
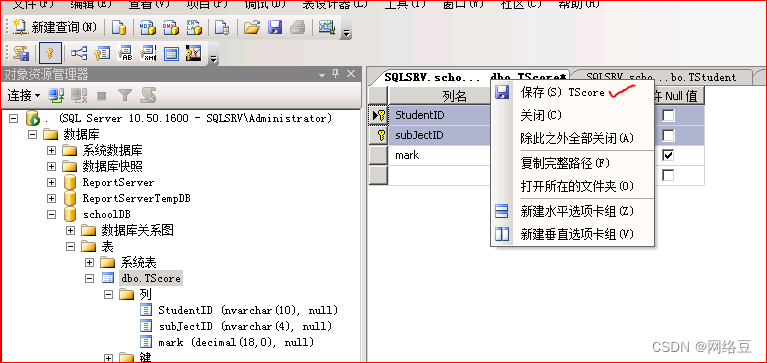
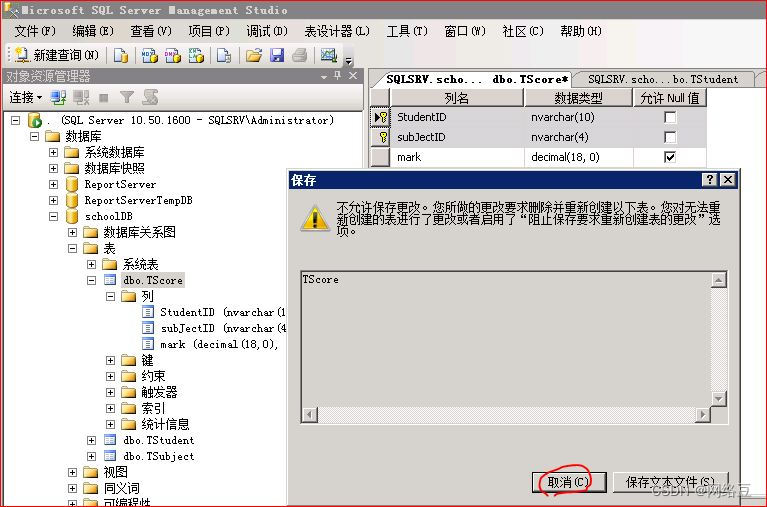
解决办法:
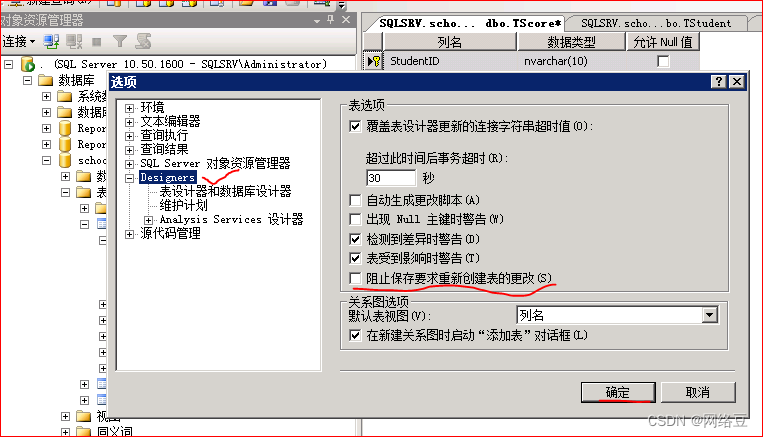
菜单栏----工具----选项
找到设计器(designers),将标记处的勾去掉,单击“确定”
这样组合索引就创建成功了。
3创建唯一索引
创建唯一性约束的时候就会创建唯一性索引,不能有重复值
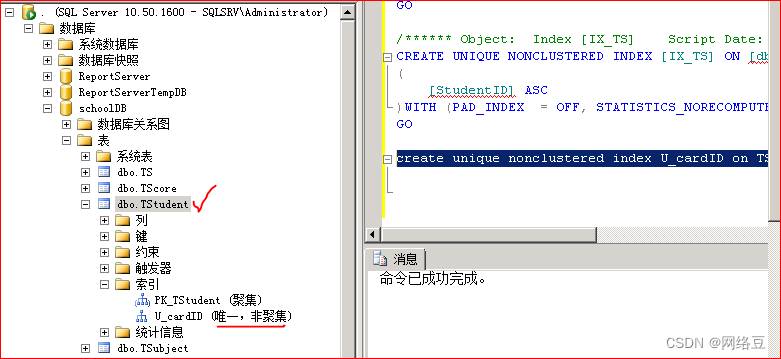
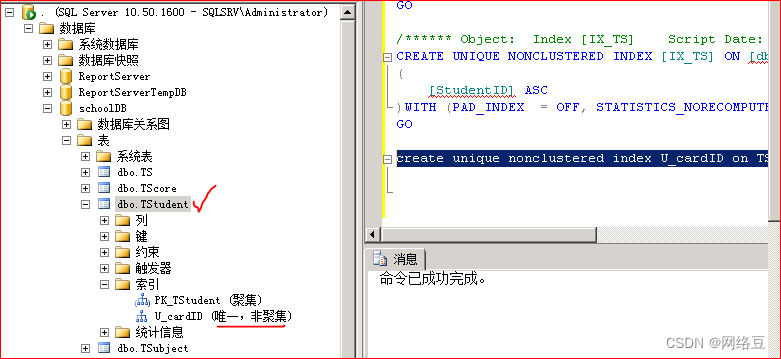
为Tstudent表创建唯一非聚集索引
create unique nonclustered index U_cardID on TStudent(cardID)
4、创建非聚集索引---可以有重复值
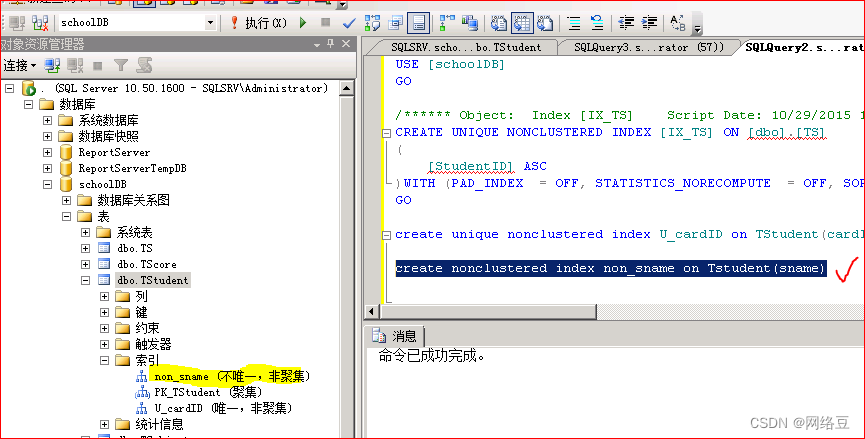
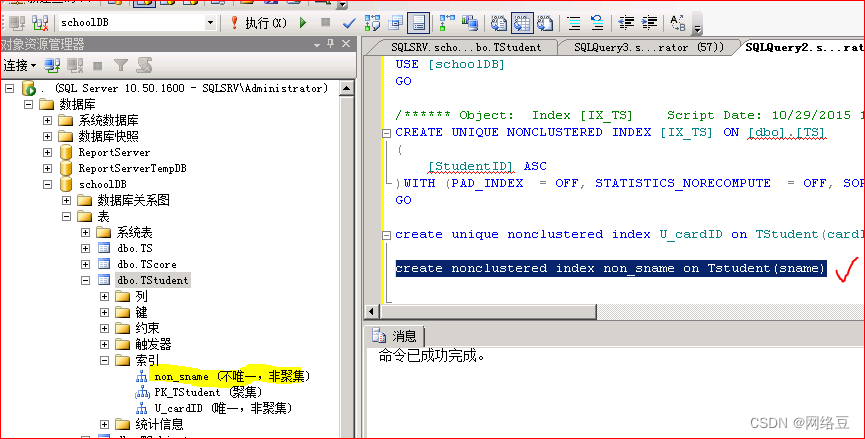
为Tstudent表的姓名列创建非聚集索引
create? nonclustered ??index? non_sname? on? tstudent(sname)
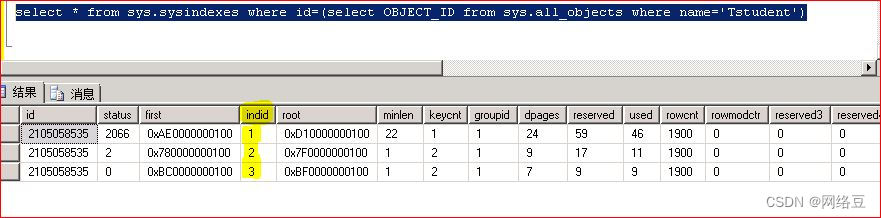
使用命令查看表上的索引
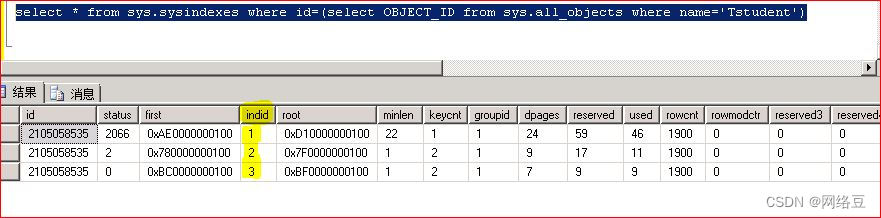
Select * from sys.sysindexes where id=(select object_id from sys.all_objects where name='Tstudent')
Indid中1代表聚集索引
Indid中2代表唯一非聚集索引
Indidz中3代表非聚集索引
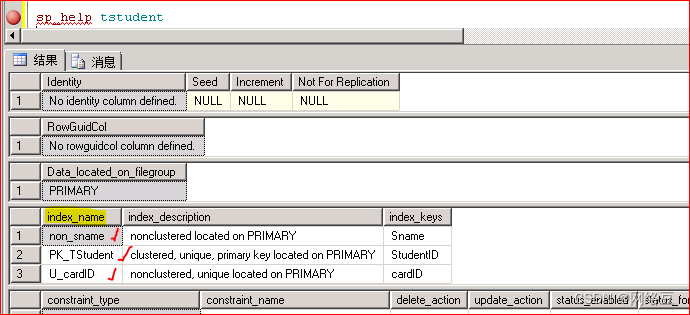
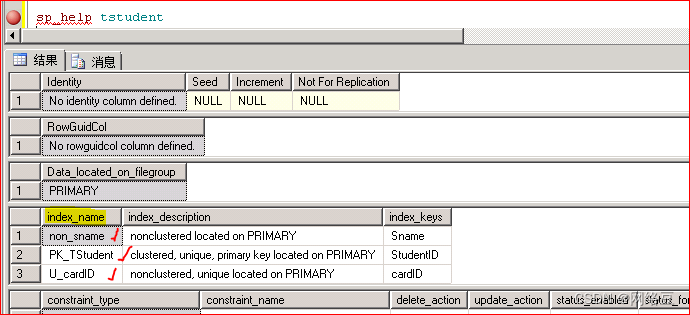
使用sp_help? Tstudent也可以查看到相关表的信息
sp_help? Tstudent
实验案例一:验证索引的作用
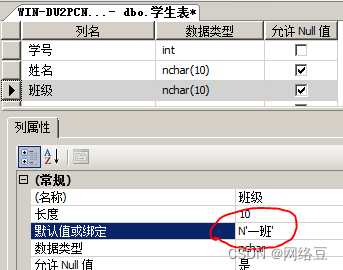
- 创建数据库test,再创建一个数据量大的表,名称为“学生表”,分别有三列,学号,姓名和班级,如下图所示,学号为自动编号,班级为默认值“一班”。
- 向表中插入大量数据,数据越多,验证索引的效果越好。
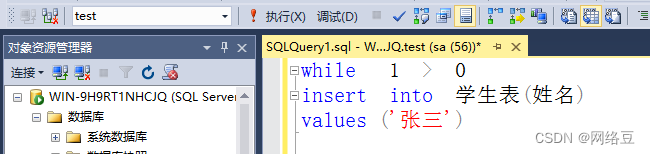
使用语句完成:While 1>0? Insert into 学生表(姓名)? values(‘张三’)
上面语句是一个死循环,除非强制结束,如果1大于0就会一直向表中插入姓名
如下图所示:
等待5分钟左右,打开表的属性,查看表的行数,当前为1032363,如下图所示:
使用语句查询第900000行的数据,Select * from 学生表 Where 学号=900000

4、打开“sql server? 2016? profiler ”工具进行跟踪,如下图所示:
打开“sql server profiler ”工具查看跟踪的信息,发现查询时间很长,cpu工作了265毫秒,reads:读了8649次,writes:写了10次,duration:总计花费2336毫秒完成查询。
为了下面分析文件更准确,多执行几次Select * from 学生表 Where 学号=900000
然后把跟踪的结果保存在桌面上:
- 打开“SQL server 2016数据库引擎优化顾问”,添加跟踪文件,进行分析,发现索引建议,需要建立索引。
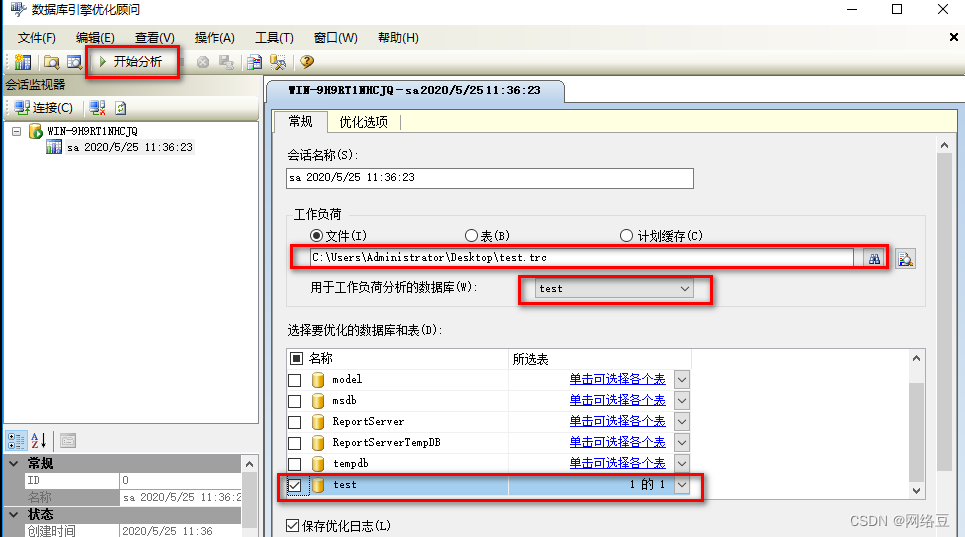
注意选择test数据库中的学生表,然后点击“开始分析”

索引类型为clusterd(聚集索引),索引列为“学号”。
- 按照“数据库引擎优化顾问”的索引建议建立聚集索引,并且选择“唯一”
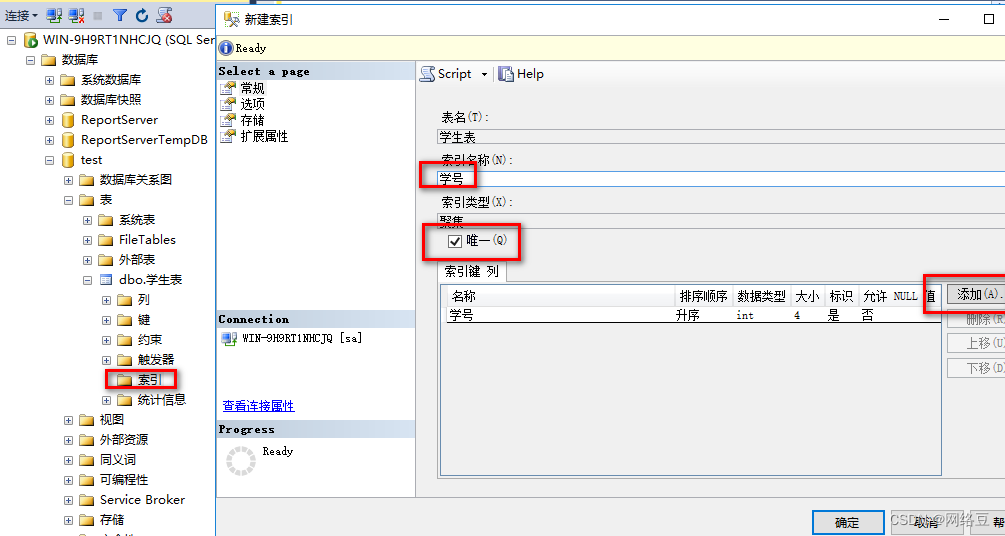
- 再次执行Select * from 学生表Where 学号=900000
- 打开sql server profiler查看跟踪的时间,发现查询时间大幅提升,说明索引可以提高查询速度。
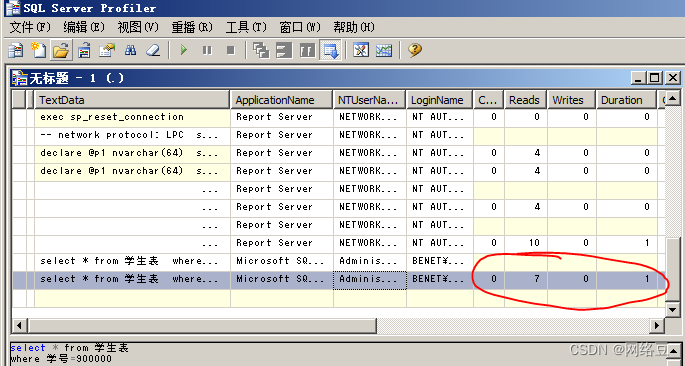
发现总计时间为1毫秒,几乎忽略不计
实验案例二:分别练习创建各种索引
- 创建聚集索引
目前tstudent表中没有任何索引也没有主键
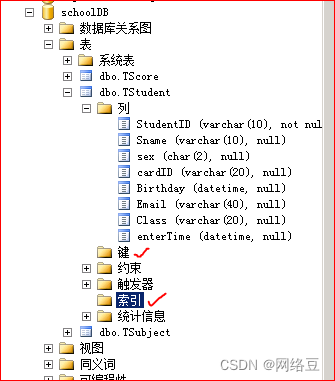
为tstudent表创建聚集索引
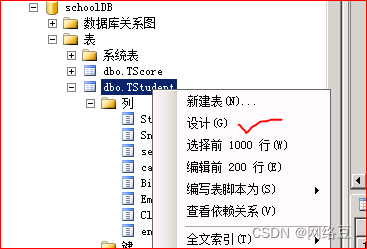
选中studentID,单击左上侧的主键按钮
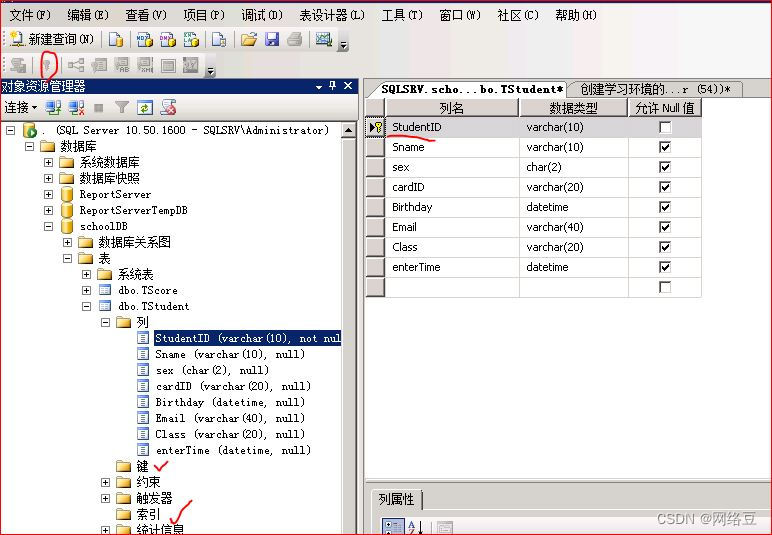
为Tstuden表的studentID创建主键就同时创建了聚集索引
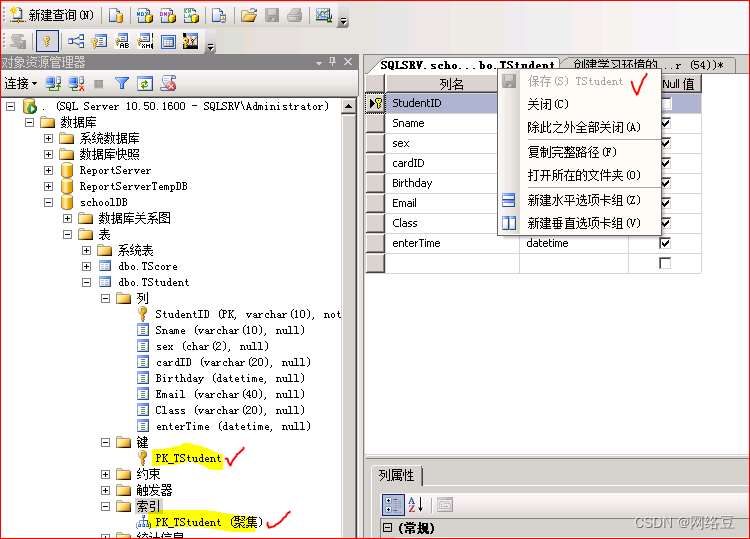
2、创建组合索引
为成绩表创建组合索引,因为一个学生不能为一门学科录入两次成绩,所以将成绩表中的studentID和subjectID创建组合索引
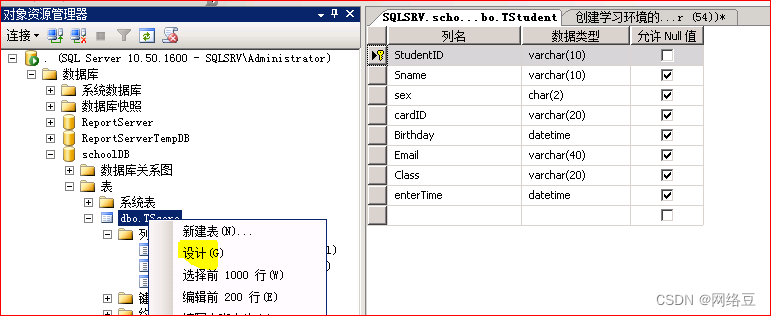
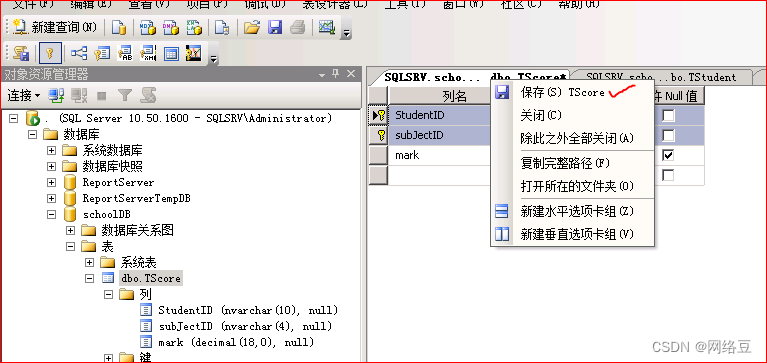
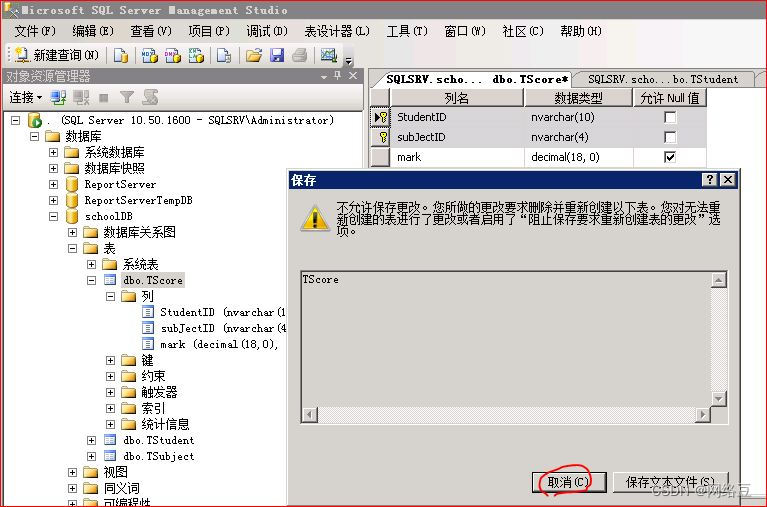
解决办法:
菜单栏----工具----选项
找到设计器(designers),将标记处的勾去掉,单击“确定”
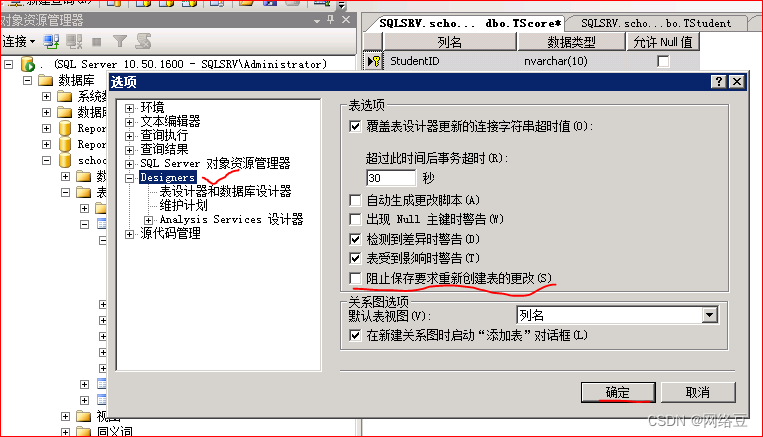
这样组合索引就创建成功了。
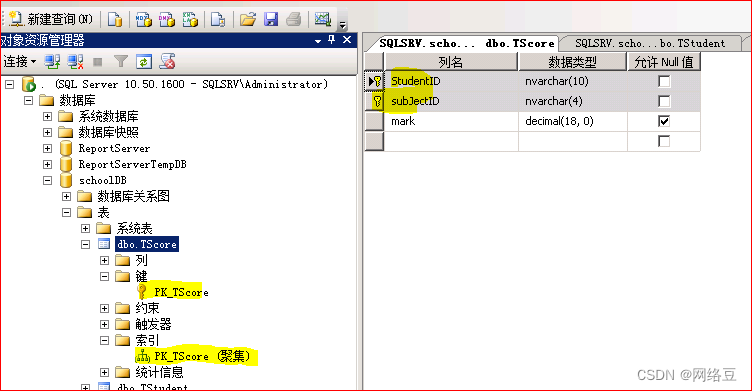
3创建唯一索引
创建唯一性约束的时候就会创建唯一性索引,不能有重复值
为Tstudent表创建唯一非聚集索引
create unique nonclustered index U_cardID on TStudent(cardID)
4、创建非聚集索引---可以有重复值
为Tstudent表的姓名列创建非聚集索引
create? nonclustered ??index? non_sname? on? tstudent(sname)
使用命令查看表上的索引
Select * from sys.sysindexes where id=(select object_id from sys.all_objects where name='Tstudent')
Indid中1代表聚集索引
Indid中2代表唯一非聚集索引
Indidz中3代表非聚集索引
使用sp_help? Tstudent也可以查看到相关表的信息
sp_help? Tstudent
实验案例三:创建视图??
方法一:在图形界面下创建视图(以Myschool数据库为例)
创建一个视图,分别来自三个表的三个列,并重命名列,生成的视图名为student_info,如下图所示:
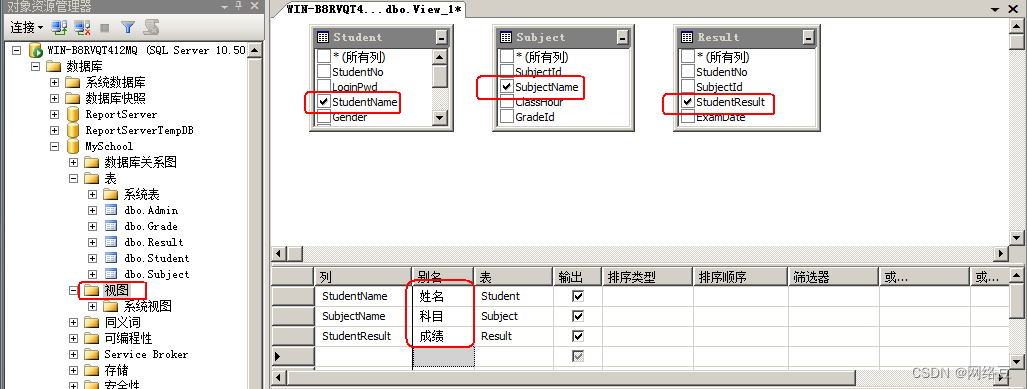
通过查询语句查看视图:select?? *??? from?? student_info
方法二:使用语句创建视图(以schoolDB数据库为例)
进行数据库设计的时候,一个表有很多列,我们可以在表上创建视图,只显示指定的列。
Select语句可以作为一个视图
select Sname,sex,Class from TStudent where Class='网络班'
- 创建视图,筛选行和列
(1)创建视图
create view netstudent
as
select Sname,sex,Class from dbo.TStudent where Class='网络班'
(2)从视图中查找数据:
select * from netstudent where sex='男'
2、创建视图,更改列的表头
(1)创建
create view V_Tstudent1
as
select StudentID 学号,Sname 姓名,sex 性别,cardID 身份证号码,Birthday 生日,Class 班级 from TStudent
(2)从视图中查找数据:
select * from V_Tstudent1
以后再去查询的时候就非常方便了。
实验案例四:存储过程
1、常用的系统存储过程
exec? sp_databases????? --列出当前系统中的数据库
use? MySchool
go
exec sp_tables?????????????????????? --当前数据库中可查询对象的列表
exec sp_columns student??????????? --查看表student中列的信息
exec? sp_help student?????????????? --查看表student的所有信息
exec sp_helpconstraint student?????? --查看表student表的约束
exec sp_stored_procedures????? --返回当前数据库中的存储过程列表
2、常用的扩展存储过程(在C盘下创建一个文件夹bank)
exec? xp_cmdshell? 'mkdir? c:\bank',no_output? --创建文件夹c:\bank
exec? xp_cmdshell? 'dir c:\bank\'?????????????? --查看文件
如果执行不了上面的语句,请开启下面的功能。然后再次执行上面的两条语句。
若xp_cmdshell作为服务器安全配置的一部分而被关闭,请使用如下语句启用:
exec sp_configure? 'show advanced options', 1?? --显示高级配置选项(单引号中的只能一个空格隔开)
go
reconfigure??????????????????????????????????? --重新配置
go
exec sp_configure? 'xp_cmdshell',1???????????????? --打开xp_cmdshell选项
go
reconfigure??????????????????????????????????? --重新配置
go
3、用户自定义的存储过程(以schoolDB数据库为例,计算网络管理专业的平均分)
use schoolDB
go
if exists ?(select? *? from? sysobjects where name='usp_getaverageresult')
drop ?procedure ?usp_getaverageresult
go
create ?procedure ?usp_getaverageresult
as
declare ?@subjectid ?nvarchar(4)
select? @subjectid=subjectid? from? dbo.TSubject where subJectName='网络管理'
declare ?@avg decimal (18,2)
select ?@avg=AVG(mark)? from ?dbo.TScore where subJectID=@subjectid
print? '网络管理专业平均分是:'+convert(varchar(5),@avg)
go
执行验证效果:
exec? usp_getaverageresult
实验案例五:触发器
(Myschool数据库为例)
创建触发器(禁止修改admin表中数据):
create? trigger? reminder
on ?admin
for? update
as
print? '禁止修改,请联系DBA'
rollback? transaction
go
执行语句,查看错误信息:
update Admin set? LoginPwd='123'? where? LoginId='benet'
select? *? from? Admin
实验案例六:事务
案例:完成转账的过程,如果转账1000会回滚,提示失败,如果转账800,提示成功。(参看书140页)
?要求:
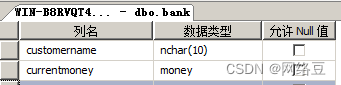
- 创建表名为bank,如图所示:
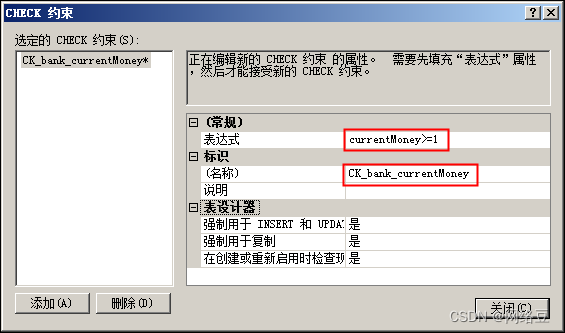
- Currentmoney列的Check约束:
(2)插入两条数据:
INSERT ?INTO ?bank(customerName,currentMoney) ?VALUES('张三',1000)
INSERT ?INTO ?bank(customerName,currentMoney) ?VALUES('李四',1)- 转账的过程代码参考书140页。(先执行转账1000,查看结果;之后转账800,查看结果)
print?? '查看转账事务前的余额'
select? *? from? bank
go
begin?? transaction
declare @errorsum? int
set? @errorsum=0
update? bank? set? currentmoney=currentmoney-1000
where? customername='张三'
set @errorsum=@errorsum+@@ERROR
update? bank? set? currentmoney=currentmoney+1000
where? customername='李四'
set @errorsum=@errorsum+@@ERROR
print? ' 查看转账事务过程中的余额'
select? *? from? bank
if? @errorsum <>0
??????? begin
???????????????? print '交易失败'
???????????????? rollback transaction
??????? end
else
??????? begin
???????????????? print '交易成功'
???????????????? commit? transaction
??????? end
go
print? ' 查看转账事务后的余额'
select? *? from? bank
go