Top-Down性能分析方法(原理篇):揭秘代码运行瓶颈
Top-Down性能分析方法(原理篇):揭秘代码运行瓶颈

引
写完代码调试的时候,如果我们能够了解代码的执行过程往往能帮助我们更好的进行调试;而如果我们的代码性能出现了问题,我们又该如何处理呢?也许我们会想知道执行机上到底发生了什么,于是我们尝试通过perf、ebpf这样的工具来获取一些数据,比如了解这台机器上到底发生了多少次cache-miss;在获取到咋这么多数据后,我们又该如何判断性能的瓶颈究竟在哪里呢?
今天我们来介绍一种由intel的工程师提出的Top-Down性能分析方法,本文主要由以下部分组成:
Top-Down的产生背景Top-Down方法介绍Top-Down计算方法
背景
在进行性能优化的时候,往往需要先去寻找性能瓶颈,这一部分决定了性能优化的效果。在寻找瓶颈的时候,可以借助PMU这样的计数器来观测系统发生了什么。可是现代的CPU暴露了数百上千个性能事件,这些事件可能分布在系统的各个维度(CPU、内存、网络等),很难直接了当的通过PMU的数据来发现系统的性能瓶颈,或者说很难了解到底是什么浪费了时钟周期。
此外,现代的CPU为了能够尽可能的提高IPC(instruction per cycle),采取了诸多技术:
- 乱序执行
- 分支预测
- 超标量
- 硬件预取
这些技术非常好的提高了CPU的理论上限,但是也增加了我们分析微架构数据的难度。
在开始介绍Top-Down之前,我们先尝试一些CPU的微架构知识,如下是Intel IceLake的微架构图片:
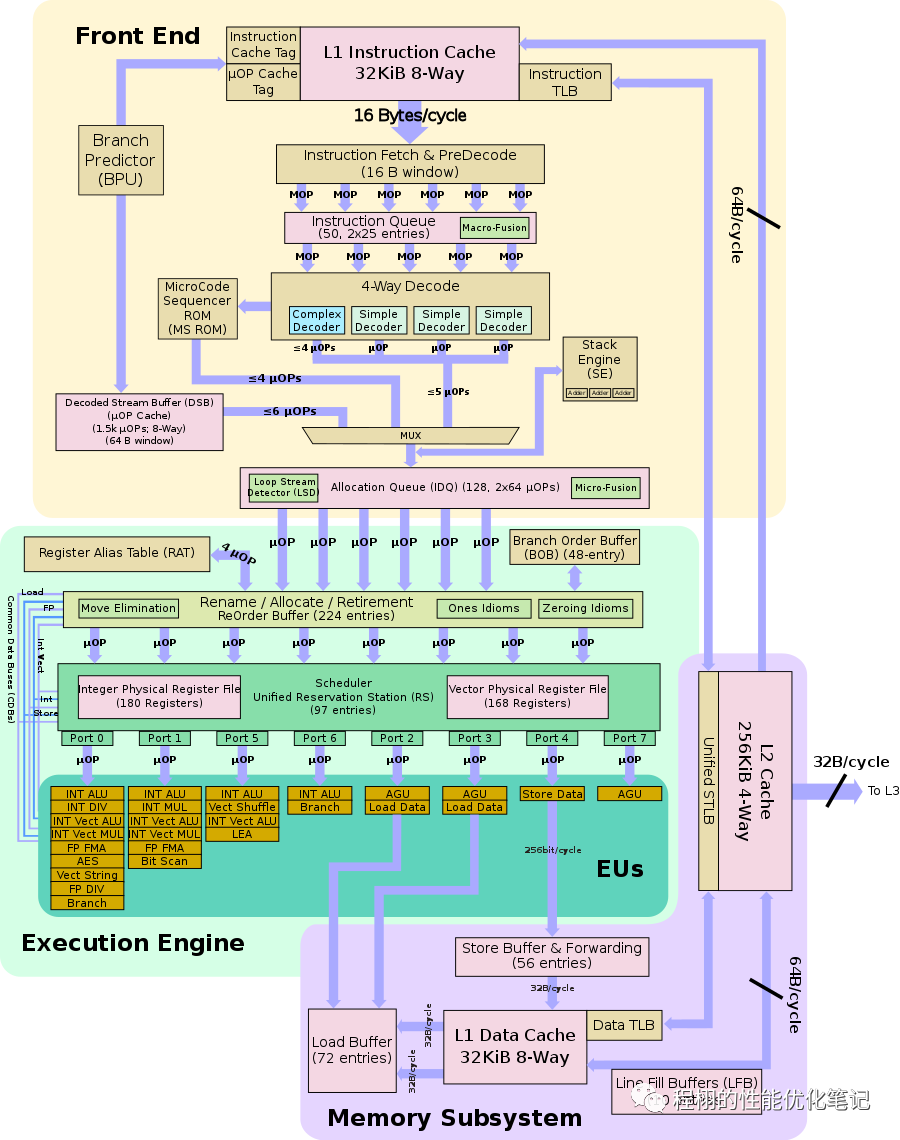
将其简化成如下的鸟瞰图:

我们可以简单的将这个微架构图划分为两个部分:Frontend(前端)与Backend(后端)。前端负责从内存中取出指令,并将他们转换成uOps(微指令)。在CISC指令集中,因为指令的复杂性,可能会导致硬件执行关键路径过长而影响性能,所以会将指令先翻译成微指令,再去执行。后端则负责调度前端生成的微指令并执行,最后提交(Commit)这些微指令,让他们退休(Retired)。为了平衡前端和后端,两者之间存在这一个微指令队列,前端生成的微指令会经由这里被送到后端。
在一些传统的方法中,我们可以通过如下的方式模拟阻塞(Stalls)给系统带来的损耗:
例如分支预测失败会带来两个时钟的损耗,通过多少次分支预测失败这个事件就可以计算损耗的时钟数。然后再算上别的性能事件,就可以得到一共损耗的时钟周期了。这个方法看起来是好用的,但是在现代乱序CPU中,由于如下的一些问题,这个方法失效了:
- 超标量带来的Stalls误差(
Stalls overlap):在现代超标量处理器中,CPU可以同时发射或执行多条指令,一条流水线阻塞不代表整条流水线阻塞; - 投机执行(
Speculative Execution):投机执行的指令效率比不投机指令的效率还要低; - 阻塞叠加影响:多个阻塞会互相叠加;
- 遗漏预定义事件:通过累加计算损耗就需要目标事件集合,但是这个集合可能会出现遗漏的情况
Top-Down方法
因此,Top-Down分析方法应运而生。其目的在于准确快捷的发现系统性能瓶颈。正如这个名字所表达的一样,Top-Down分析方法是一种自顶向下,逐步分解的性能分析方法。它能够指导使用者逐步的分解问题,并聚焦到真正影响性能的问题上去。
Top-Down性能分析方法的思想是简单直白的:将CPU执行的时间进行划分,选择其中值得关注的部分进行聚焦。接着对这部分继续划分,再选择其中值得关注的部分进行聚焦,依次往下,直到找到这样一棵CPU执行时间树的叶子节点为止。

执行树
如上图所示,我们假设CPU就是a节点,当我们进入到d节点时,就可以看到f和g节点,这时候我们选择占比较高的节点f继续进入,如此往复,直到找到节点h,那么h就是目前最可能的性能瓶颈。
如下是Top-Down的层次结构:
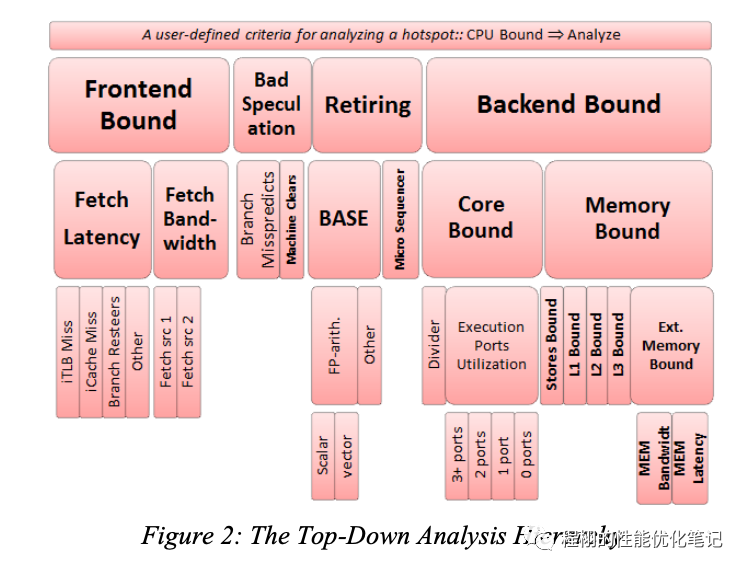
Top-Down层次划分
我们首先将CPU执行时间划分为了四个大的部分:Frontend Bound、Bad Speculation、Retiring和Backend bound。我们通过一个例子来讲解Top-Down的决策流程:我们假定一个业务的瓶颈在data cache部分。使用Top-Down方法分析:
1、首先会发现瓶颈在Backend Bound部分,下钻分析到Backend Bound;
2、Backend Bound被划分为了Core Bound和Memory Bound。Top-Down方法会标记Memory Bound。下钻到Memory Bound中;
3、在Memory Bound会看到Stores Bound、L1 Bound、L2 Bound、L3 Bound和Ext. Memory Bound,聚焦到到L1 Bound上;
4、考虑L1 Bound可能的原因并优化。
Top-Down层次结构能够带来的天然的安全性。正如我们前面说的,Top-Down是一棵决策树,这里面可能会有多个内部节点被标记,无论它们的父节点是否被标记。例如一个除法操作可能在Ext.Memory Bound和Divider两个地方被标记,尽管Divider可能看起来问题更大,但是如果其父节点没有被标记的话,我们就需要将其忽略。这是因为我们是自顶向下的,所以我们只需要关注从根结点到叶子节点都被标记的部分。
例如在下图中,我们遵循Top-Down的流程,看到的会是a->d->f->h的路径,而不会关注到e节点。

安全性
值得注意的一点是,每一层的占比都是相对于它的上一层来说的,例如Backend Bound的两个组成部分Core Bound和Memory Bound的占比和应该为100%,这是因为它们的分母是Backend Bound。因此,当我们比较占比时,我们只能比较兄弟节点,而不能比较任意的两个节点。
顶层划分
在Top-Down最开始的时候,我们需要考虑如何做最顶层的划分。Top-Down方法按照如下的方式对微指令做划分:

Top Level breakdown flowchart
对于一个已经被发射的微指令,那么它最终只有两个结果:Retired或者Cancelled。因此,这条指令要么被计入到Retiring阶段或者Bad Speculation阶段。反过来,对于一个还没有分配的微指令,如果出现了Backend Stall,后端由于一些原因无法处理相关的指令,则计入到Backend Bound;反之则将其计入到Frontend Bound。
Frontend Bound
前端主要承担以下工作:
- 基于分支预测取出下一条地址
- 取出
cache line解析指令 - 将指令解析成微指令
处理前端的问题会有一些困难,因为它们出现在流水线的最开始,这些短暂的问题可能并不是导致问题的真正原因。因此,我们只需要在Frontend Bound被标记的时候进行下钻分析即可。Top-Down更进一步的将Frontend Bound划分成为延时(latency)和带宽(bandwidth)两个维度。icache miss 、 iTLB miss 和 Branch Resteers 都属于Frontend Latency问题,而前端解码器的效率问题会被划分到Frontend Bandwidth维度。Branch Resteers记录了流水线冲刷(pipeline flush)
Top-Down更进一步的将带宽按照取指(Fetch)单元做了划分。一般的取指单元会被划分到Fetch src 1,而涉及到像CPUID这样复杂指令的解析,可能会使用到Fetch src 2。
Bad Speculation
Bad Speculation反映了流水线槽(slots)因为错误的投机预测而被浪费的情况。Bad Speculation包含两种情况:因为错误的投机操作执行最终不会Retired的指令,如Branch Misspredicts;或者流水线因为前面的投机操作而被阻塞。比如在分支预测窗口里被丢弃的指令就会被计入到这里面。
注意分支预测的第三种可能的处理会和获取正确的目标的速度有关。如果其会导致其他的前端阻塞的话,会被计入到Frontend Bound中的Branch Resteers中。
Bad Speculation是Top-Down分析中很重要的一部分。其能够帮助我们了解到预测错误对工作的影响,从而反过来决定其他几个部分的准确性。Bad Speculation 进一步分成了 Branch Mispredict 和 Machine Clears ,后者的情况导致的问题与 pipeline flush 类似:
Branch Mispredict关注如何使程序控制流对分支预测更友好Machine Clears指出一些异常情况,例如清除内存排序机(Memory Ordering Nukes clears)、自修改代码(self modifying code)或者非法地址访问(certain loads to illegal address ranges)
Retiring
Retiring的部分表示了所谓的好指令,也就是正常跑完的指令。理想状态下,我们希望所有的指令都能够Retiring,这样的话就可以完全的发挥CPU的作用。假设每条指令会生成一条微指令,在一个四发射机器上如果能有50%的Retiring率,那么相应的IPC就是2。
但是,很高的Retiring率并不意味着就没有性能优化空间了。例如:
Micro Sequencer指标中的Floating Point操作就对性能不友好,我们应该尽量避免使用;- 对于非向量操作而言,很高的
Retiring率意味着我们可以尝试将其修改为向量操作;
Backend Bound
Backend Bound表明了后端并没有足够的资源能够处理发送的微指令的情况。基于执行单元我们将Backend Bound分成了Memory Bound和Core Bound。前者更多的偏向于访存操作,而后者偏向于计算操作。如果想要更好的IPC表现的话,我们应该尽可能的让执行模块处于忙碌中,或者说流水线尽可能忙碌。否则我们将这些周期称为执行停顿(Execution Stalls)。

流水线
Memory Bound通常和内存子系统的阻塞有关。这些阻塞通常会导致执行单元一小段时间的饥饿现象。
Core Bound反映了短的执行饥饿周期或者执行端口利用率不佳,例如一个长延迟的除法操作可能会序列化执行,导致一个周期内只有少量的执行端口被使用。这会让执行单元造成压力,并且缺少指令集并行。
Core Bound 的问题一般可以通过更优秀的代码来解决。编译器也可以通过更好的指令调度来缓解。同时,矢量化(Vectorization)也可以缓解 Core Bound 问题。
Memory Bound
现代CPU实现了三级缓存结构。在Intel CPU中,第一级缓存实现了数据缓存(L1D),第二级缓存是核心共享的数据缓存和指令缓存,第三级则是在多个核上共享的缓存。
为了处理叠加的影响,Top-Down尝试引入了一种启发式的方法来确定内存访问的惩罚。优秀的乱序执行CPU可以通过使用不依赖内存访问的微指令来填满CPU从而避免内存访问带来的阻塞。因此内存访问真正的惩罚是调度器没有准备好微指令给执行模块执行,这些微指令要么在等待内存访问,要么就依赖于其他未执行的微指令。下图表示了如何区分缓存带来的停顿:
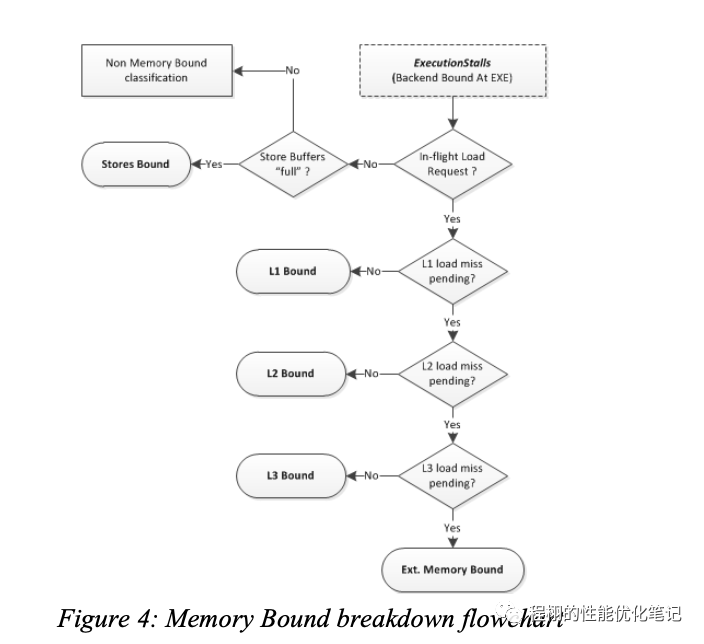
Memory Bound breakdown flowchart
例如,L1D缓存拥有和ALU阻塞媲美的短延迟。但是在实际场景中, load 操作被阻塞,无法将数据从早先的 store 转发到一个相同的地址可能会导致较高的延迟操作。这种情况会被归类到图中的L1 Bound中去。
在乱序执行的CPU上,存储(Store)操作会被缓存并在指令Retiring之后进行。多数情况下这些操作对性能没有影响,但是我们也不能因此而忽视它。所以定义了Stores Bound,这种情况下执行端口利用率会很低,并且有很多的存储缓存。
数据TLB miss可以被归类到对应的内存范畴子节点下。例如L1D的TLB未命中会被归类到L1 Bound下。
最后,Top-Down使用了一种启发式的方法来区分Ext.Memory Bound下的Memory BandWidth和Memory Latency。首先统计有多少请求依赖从内存中获取数据,如果该数值超过一个阈值,则定义为Memory Bandwidth,否则就归类为Memory Latency。
原理
Top-Down的数据底层是系统的PMU数据。除了8个新的PMU事件,其他的都已存在在现代的CPU中。基础的Top-Down通用事件如下图所示:

硬件事件
基于表一的事件,我们可以计算如下的监控指标:

指标计算

指标计算
参考资料
- Ahmad Yasin, A Top-Down Method for Performance Analysis and Counters Architecture
- 《A Top-Down Method for Performance Analysis and Counters Architecture》阅读笔记(2020). Available at: https://andrewei1316.github.io/2020/12/20/top-down-performance-analysis/ (Accessed: 12 July 2023).
- Intel Top-down方法学综述 (2023). Available at: https://zhuanlan.zhihu.com/p/638160179 (Accessed: 12 July 2023).