logstash与filebeat组件的使用
原创
logstash
Logstash 作为 Elasicsearch 常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源;
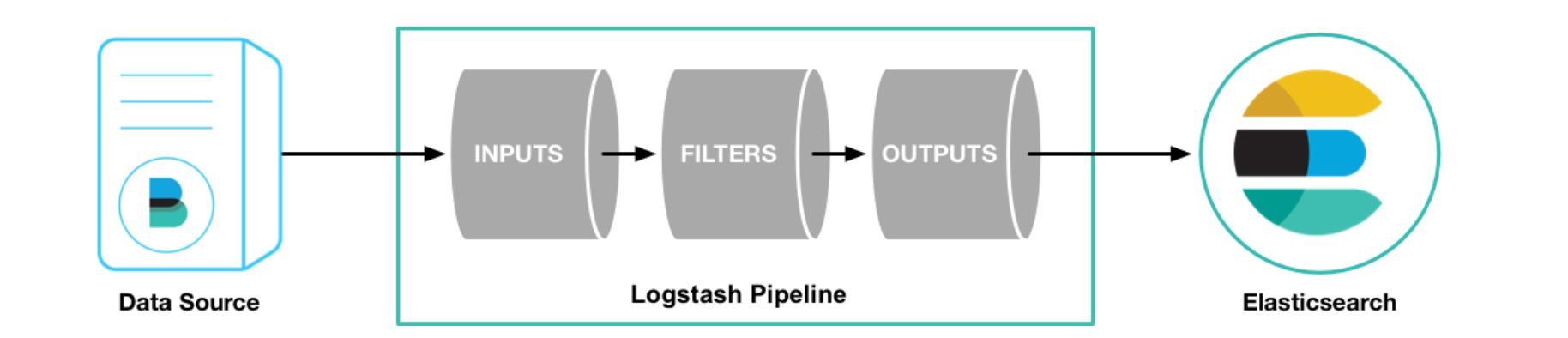
处理过程
Logstash 的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在 Inputs 和 Outputs 中可以使用 Codecs 对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义 pipeline 配置文件,设置需要使用的 input,filter,output, codec 插件,以实现特定的数据采集,数据处理,数据输出等功能
- Inputs:用于从数据源获取数据,常见的插件如 file, syslog, redis, beats 等
- Filters:用于处理数据如格式转换,数据派生等,常见的插件如 grok, mutate, drop, clone,geoip 等
- Outputs:用于数据输出,常见的插件如 elastcisearch,file, graphite, statsd 等
- Codecs:Codecs 不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如 json,multiline
执行模型
- 每个 Input 启动一个线程,从对应数据源获取数据
- input 会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失 Logstash 提供了两个特性:Persistent Queues:通过磁盘上的 queue 来防止数据丢失;Dead Letter Queues:保存无法处理的 event(仅支持 Elasticsearch 作为输出源)
- Logstash 会有多个 pipeline worker, 每一个 pipeline worker 会从队列中取一批数据,然后执行filter 和 output(worker 数目及每次处理的数据量均由配置确定)
配置文件说明
- pipelines.yml:配置 logstash 任务的任务参数;
- jvm.options:用于设置 logstash 运行的 JVM 堆内存大小以及 GC 参数。
- logstash-sample.conf:logstash 官方提供的任务 demo。所有的 logstash 任务均是 xxxx.conf 结尾。目录为 logstash 安装包的 config 目录下。
Logstash 性能调优主要参数
- pipeline.workers:设置启动多少个线程执行 fliter 和 output;当 input 的内容出现堆积而 CPU 使用率还比较充足时,可以考虑增加该参数的大小;
- pipeline.batch.size:设置单个工作线程在执行过滤器和输出之前收集的最大事件数,较大的批量大小通常更高效,但会增加内存开销。输出插件会将每个批处理作为一个输出单元。;例如,ES 输出会为收到的每个批次发出批量请求;调整pipeline.batch.size可调整发送到 ES 的批量请求(Bulk)的大小;
- pipeline.batch.delay:设置 Logstash 管道的延迟时间, 管道批处理延迟是 Logstash 在当前管道工作线程中接收事件后等待新消息的最长时间(以毫秒为单位);简单来说,当pipeline.batch.size不满足时,会等待pipeline.batch.delay设置的时间,超时后便开始执行 filter 和 output 操作。
filebeat
Filebeat 是用于转发和集中日志数据的轻量级传送工具。Filebeat 监视您指定的日志文件或位置,收集日志事件,并将它们转发到 Elasticsearch 或 Logstash 进行索引。
Filebeat 的工作方式
启动 Filebeat 时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于 Filebeat 所找到的每个日志,Filebeat 都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到 libbeat,libbeat 将聚集事件,并将聚集的数据发送到为 Filebeat 配置的输出。
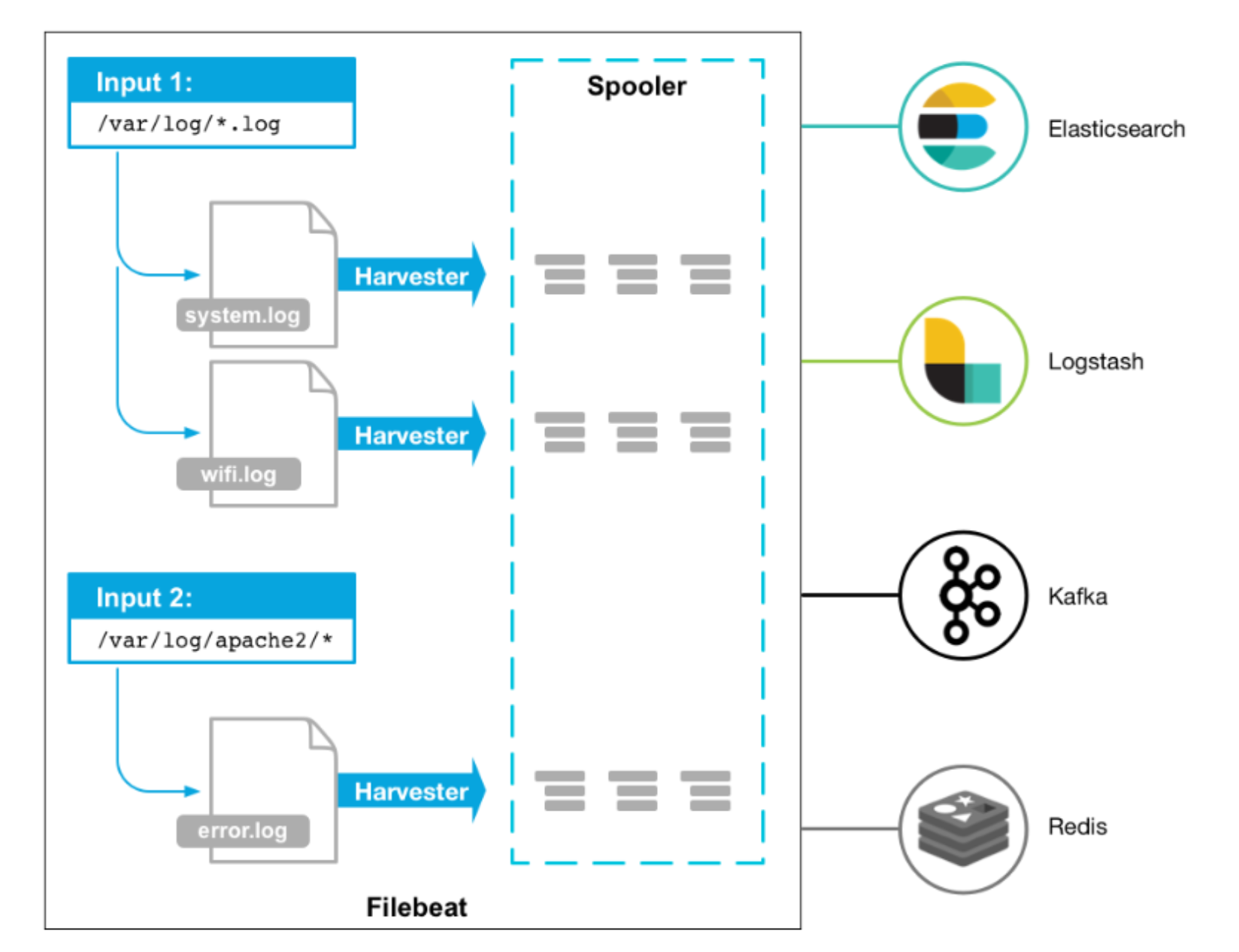
配置文件说明
filebeat.yml: 任务配置文件
配置文件参数值参考释义
- type: log #input 类型为 log enable:true #表示是该 log 类型配置生效 paths: #指定要监控的日志,目前按照 Go 语言的glob 函数处理。没有对配置目录做递归处理,比如配置的如果是:-/var/log/* /*.log #则只会去/var/log 目录的所有子目录中寻找以".log"结尾的文件,而不会寻找 /var/log 目录下以".log"结尾的文件。
- recursive_glob.enabled: #启用全局递归模式,例如/foo/**包括/foo, /foo/*, /foo/*/*。
- encoding:#指定被监控的文件的编码类型,使用 plain 和 utf-8 都是可以处理中文日志。
- exclude_lines: ['^DBG'] #不包含匹配正则的行。
- include_lines: ['^ERR', '^WARN'] #包含匹配正则的行。
- harvester_buffer_size: 16384 #每个 harvester 在获取文件时使用的缓冲区的字节大小。
- max_bytes: 10485760 #单个日志消息可以拥有的最大字节数。max_bytes 之后的所有字节都被丢弃而不发送。默认值为 10MB (10485760)。
- exclude_files: ['\.gz$'] #用于匹配希望 Filebeat 忽略的文件的正则表达式列表。
- ingore_older: 0 #默认为 0,表示禁用,可以配置 2h, 2m 等,注意 ignore_older 必须大于 close_inactive的值.表示忽略超过设置值未更新的文件或者文件从来没有被 harvester 收集。
- close_* #close_ *配置选项用于在特定标准或时间之后关闭 harvester。 关闭 harvester 意味着关闭文件处理程序。 如果在 harvester 关闭后文件被更新,则在 scan_frequency 过后,文件将被重新拾取。 但是,如果在 harvester 关闭时移动或删除文件,Filebeat 将无法再次接收文件,并且 harvester 未读取的任何数据都将丢失。
- close_inactive #启动选项时,如果在制定时间没有被读取,将关闭文件句柄读取的最后一条日志定义为下一次读取的起始点,而不是基于文件的修改时间如果关闭的文件发生变化,一个新的 harverster 将在 scan_frequency 运行后被启动建议至少设置一个大于读取日志频率的值,配置多个 prospector 来实现针对不同更新速度的日志文件使用内部时间戳机制,来反映记录日志的读取,每次读取到最后一行日志时开始倒计时使用 2h 5m来表示。
- close_rename #当选项启动,如果文件被重命名和移动,filebeat 关闭文件的处理读取。
- close_removed #当选项启动,文件被删除时,filebeat 关闭文件的处理读取这个选项启动后,必须启动 clean_removed。
- close_eof #适合只写一次日志的文件,然后 filebeat 关闭文件的处理读取。
- close_timeout #当选项启动时,filebeat 会给每个 harvester 设置预定义时间,不管这个文件是否被读取,达到设定时间后,将被关闭close_timeout 不能等于 ignore_older,会导致文件更新时,不会被读取如果 output 一直没有输出日志事件,这个 timeout 是不会被启动的,至少要要有一个事件发送,然后 haverter 将被关闭设置 0 表示不启动。
- clean_inactived #从注册表文件中删除先前收获的文件的状态设置必须大于 ignore_older+scan_frequency,以确保在文件仍在收集时没有删除任何状态配置选项有助于减小注册表文件的大小,特别是如果每天都生成大量的新文件,此配置选项也可用于防止在Linux上重用inode的Filebeat问题。
- clean_removed #启动选项后,如果文件在磁盘上找不到,将从注册表中清除 filebeat。如果关闭close removed,必须关闭 clean removed。
- scan_frequency #prospector 检查指定用于收获的路径中的新文件的频率,默认10s。
- tail_files:#如果设置为 true,Filebeat 从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,而不是从文件开始处重新发送所有内容。
- symlinks:#符号链接选项允许 Filebeat 除常规文件外,可以收集符号链接。收集符号链接时,即使报告了符号链接的路径,Filebeat 也会打开并读取原始文件。
- backoff: #backoff选项指定Filebeat如何积极地抓取新文件进行更新。默认 1s,backoff 选项定义Filebeat在达到EOF之后再次检查文件之间等待的时间。
- max_backoff: #在达到 EOF 之后再次检查文件之前 Filebeat 等待的最长时间。
- backoff_factor: #指定 backoff 尝试等待时间几次,默认是 2。
- harvester_limit:#harvester_limit选项限制一个prospector并行启动的harvester 数量,直接影响文件打开数。
- tags #列表中添加标签,用过过滤,例如:tags: ["json"]。
- fields #可选字段,选择额外的字段进行输出可以是标量值,元组,字典等嵌套类型,默认在 sub-dictionary位置。
- fields_under_root #如果值为 ture,那么 fields 存储在输出文档的顶级位置。
- multiline.pattern #必须匹配的 regexp 模式。
- multiline.negate #定义上面的模式匹配条件的动作是否定的,默认是 false。假如模式匹配条件'^b',默认是 false 模式,表示讲按照模式匹配进行匹配 将不是以 b 开头的日志行进行合并,如果是 true,表示将不以 b 开头的日志行进行合并。
- multiline.match # 指定 Filebeat 如何将匹配行组合成事件,在之前或者之后,取决于上面所指定的negate。
- multiline.max_lines #可以组合成一个事件的最大行数,超过将丢弃,默认 500。
- multiline.timeout #定义超时时间,如果开始一个新的事件在超时时间内没有发现匹配,也将发送日志,默认是 5s。
- max_procs #设置可以同时执行的最大 CPU 数。默认值为系统中可用的逻辑 CPU 的数量。
- name #为该 filebeat 指定名字,默认为主机的 hostname。
filebeat 与 logstash 的区别与使用场景
对比项 | logstash | filebeat |
|---|---|---|
内存 | 大 | 小 |
CPU | 大 | 小 |
插件 | 丰富 | 丰富 |
功能 | 从多种输入端实时采集并转换数据,然后输出到多个输出端。 | 仅做传输使用 |
轻重 | 重量级应用,运行于 JVM中 | 轻量级二进制文件,没有任何依赖 |
编写语言 | ruby | go |
进程 | 一个服务器只允许起一个 logstash进程,如果进程挂掉需要手动拉起。 | 消耗资源较少,更加稳定。 |
过滤能力 | 有强大的过滤能力 | 过滤能力较弱 |
原理 | Logstash 使用管道的方式进 行日志的搜集和输出,分为输 入 input-->处理 filter (不 是必须的) -->输出 output,每个阶段都有不同的 替代方式 | 开启进程后会启动一个或多 个探测器 (prospectors) 去检测指定的日志目录或文 件,对于探测器找出的每 个日志文件,filebeat启动收 割进程 (harvester),每 个收割进程读取一个日志文 件的新内容,并发送这些新 的日志数据到处理程序 (spooler),处理程序会集 合这些事件,最后 filebeat 会 发送集合的数据到你指定的 地点。 |
使用场景
- Logstash 是 ELK 组件中的一个,一般都是同 ELK 其它组件一起使用,更注重于数据的预处理。但Logstash 内部没有 persist queue,所以在异常情况下会出现数据丢失的问题。
- Filebeat 是一个轻量型日志采集工具,因为 Filebeat 是 Elastic Stack 的一部分,因此能够于 ELK 组件无缝协作。Filebeat 占用的内存要比 Logstash 小很多。性能比较稳健,很少出现宕机。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。