「ES 排障指南」之 Elasticsearch 集群异常状态分析 —— 集群 YELLOW
原创「ES 排障指南」之 Elasticsearch 集群异常状态分析 —— 集群 YELLOW
原创
说明
本文描述问题及解决方法同样适用于 腾讯云 Elasticsearch Service(ES)。
本文延续上一篇文章 Elasticsearch集群异常状态(RED、YELLOW)原因分析
前言
在上一篇文章中,我们初步了解了 ES 在异常状态下的排查思路,以及 ES 在哪些情况下会发生分片异常。本文将继续展开,进一步介绍集群异常状态的排查与处理方案。
异常状态分析
我们已经了解了 ES 集群异常状态分为 YELLOW 和 RED。
YELLOW:主分片可用,但是副本分片不可用。这种情况 Elasticsearch 集群所有的主分片已经分配了,但至少还有一个副本是未分配的。不会有数据丢失,所以搜索结果依然是完整的。不过,集群高可用性在某种程度上会被弱化。可以把 yellow 想象成一个需要关注的 warnning,该情况不影响索引读写,一般会自动恢复。
RED:存在不可用的主分片。此时执行查询虽然部分数据仍然可以查到,但实际上已经影响到索引读写,需要重点关注。这种情况 Elasticsearch 集群至少一个主分片(以及它的全部副本)都在缺失中。这意味着索引已缺少数据,搜索只能返回部分数据,而分配到这个分片上的请求都返回异常。
本文我们将讲解集群在 YELLOW 异常状态下的处理思路,以及哪些情况下无需人工干预,哪些情况下需要人工干预。
YELLOW 异常
yellow 异常是 ES 最常见的集群异常,当负载较高时,集群往往会长时间陷入 yellow 状态无法脱离,其表现则是:
- 无需人工干预,副本分片恢复缓慢,大部分副本分片处于排队等待初始化
- 需要人工干预,副本分片无法分配
无需人工干预
场景1:写入触发索引创建(INDEX_CREATED)
ES 支持在索引不存在的情况下发起对该索引的写入,当对不存在的索引发起写入时,ES 会自动创建该索引,并开始自动映射(put-mapping)不存在的索引字段,这是个很重的操作,会对元数据造成较大压力。
尤其当有大量写入或者集群本身元数据较大时,ES 会延迟分配副本分片,进入 pending_task 队列,这则会导致集群陷入 yellow 状态。这时即便副本分片开始初始化,也会因为索引有大量写入而需要同步主分片数据,进而导致副本初始化缓慢。
整体表现就是集群长时间处于 yellow 状态,短时间无法脱离,但这种情况都会自动恢复,当副本分片初始化完成后,yellow 状态也就变为 green 了。

如图:当 URGENT Task过多时,则会导致 HIGH Task 排队,进入 pending 状态
优化建议:
业务提前预创建索引,而不是让 bulk request 自动触发索引创建(create-index)。
场景2:节点临时离线(NODE_LEFT)
我们假设集群当中所有索引都有冗余副本分片,且只有一个节点宕机下线,那么集群这时会进入 yellow 状态。由于索引目前还有主分片在线,对业务的使用不会造成影响。如果节点是因为短时间压力过大而导致节点脱离,则一般会自动恢复,这种情况无需人工干预:
[o.e.c.r.a.AllocationService] [1699879628011021732] failing shard [failed shard, shard [.ds-cdwch-2023.11.13-000404][23], node[vAnpreEnTaSWY-QYV3GGWg], [R], recovery_source[peer recovery], s[INITIALIZING], a[id=r48vj2pQRmauAuXKm-qX9g], unassigned_info[[reason=NODE_LEFT], at[2023-11-14T06:58:10.583Z], delayed=true, details[node_left [vAnpreEnTaSWY-QYV3GGWg]], allocation_status[no_attempt]], message [failed recovery], failure [RecoveryFailedException[[.ds-cdwch-2023.11.13-000404][23]: Recovery failed from {1675171390003468332}{QUotMJ0DRsiM442JPtqlmA}{2aWADQvMRjSKRRsFg-Abrw}{10.1.0.47}{10.1.0.47:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800007, xpack.installed=true, set=800007, transform.node=true, ip=9.15.118.138, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8} into {1670988404000091932}{vAnpreEnTaSWY-QYV3GGWg}{-vaCwjbhSpG1iGEY18Wz4A}{10.0.128.45}{10.0.128.45:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800006, xpack.installed=true, set=800006, transform.node=true, ip=9.15.104.46, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8}]; nested: RemoteTransportException[[1675171390003468332][10.1.0.47:9300][internal:index/shard/recovery/start_recovery]]; nested: ScpRecoveryIsRunningException[Another recovery task is running for same replica and node. Existing recovery: RecoveryKey{shard: [.ds-cdwch-2023.11.13-000404][23], target:vAnpreEnTaSWY-QYV3GGWg, recovery:101021}, New recovery: RecoveryKey{shard: [.ds-cdwch-2023.11.13-000404][23], target:vAnpreEnTaSWY-QYV3GGWg, recovery:101026}]; ], markAsStale [true]]
org.elasticsearch.indices.recovery.RecoveryFailedException: [.ds-cdwch-yuogefjn-es-let66hx8-space-mk4wn5x5-2023.11.13-000404][23]: Recovery failed from {1675171390003468332}{QUotMJ0DRsiM442JPtqlmA}{2aWADQvMRjSKRRsFg-Abrw}{10.1.0.47}{10.1.0.47:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800007, xpack.installed=true, set=800007, transform.node=true, ip=9.15.118.138, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8} into {1670988404000091932}{vAnpreEnTaSWY-QYV3GGWg}{-vaCwjbhSpG1iGEY18Wz4A}{10.0.128.45}{10.0.128.45:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800006, xpack.installed=true, set=800006, transform.node=true, ip=9.15.104.46, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8}
at org.elasticsearch.indices.recovery.PeerRecoveryTargetService$RecoveryResponseHandler.handleException(PeerRecoveryTargetService.java:786) ~[elasticsearch-7.14.2.jar:7.14.2]
at org.elasticsearch.transport.TransportService$ContextRestoreResponseHandler.handleException(TransportService.java:1324) ~[elasticsearch-7.14.2.jar:7.14.2]
at org.elasticsearch.transport.TransportService$ContextRestoreResponseHandler.handleException(TransportService.java:1324) ~[elasticsearch-7.14.2.jar:7.14.2]
at org.elasticsearch.transport.InboundHandler.lambda$handleException$3(InboundHandler.java:335) ~[elasticsearch-7.14.2.jar:7.14.2]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:673) ~[elasticsearch-7.14.2.jar:7.14.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) [?:?]
at java.lang.Thread.run(Thread.java:834) [?:?]
Caused by: org.elasticsearch.transport.RemoteTransportException: [1675171390003468332][10.1.0.47:9300][internal:index/shard/recovery/start_recovery]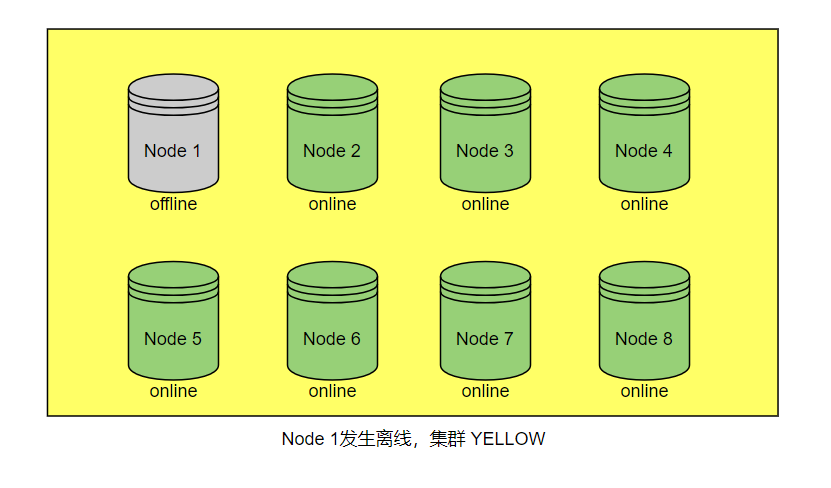
优化建议:
节点一般不会无故离线,如果发生节点偶现脱离,则要进一步排查 ES 是否存在资源瓶颈。
场景3:集群发生熔断(ALLOCATION_FAILED)
什么是熔断
Elasticsearch Service 提供了多种官方的熔断器(circuit breaker),用于防止内存使用过高导致 ES 集群因为 OutOfMemoryError 而出现问题。Elasticsearch 设置有各种类型的子熔断器,负责特定请求处理的内存限制。此外,还有一个父熔断器,用于限制所有子熔断器上使用的内存总量。
熔断器介绍
父熔断器(Parent circuit breaker) 父熔断器限制所有子熔断器上使用的内存总量,当触发父熔断器熔断时,可能的日志信息如下:
Caused by: org.elasticsearch.common.breaker.CircuitBreakingException: [parent] Data too large, data for [<transport_request>] would be [1749436147/1.6gb], which is larger than the limit of [1622605824/1.5gb], real usage: [1749435872/1.6gb], new bytes reserved: [275/275b]Field data 熔断器(Field data breaker) 当对 text 字段聚合或排序时,会产生 Field data 数据结构。Field data 熔断器会预估有多少数据被加载到内存中。当预估的数据占用内存到达 Field data 熔断器阈值时,会触发 Field data 熔断器熔断。此时可能的日志信息如下:
org.elasticsearch.common.breaker.CircuitBreakingException: [fielddata] Data too large, data for [_id] would be [943928680/900.2mb], which is larger than the limit of [255606128/243.7mb]In flight 请求熔断器(In flight requests circuit breaker) In flight 请求熔断器限制了在 transport 和 HTTP 层的所有当前传入的请求所使用的内存。当触发 In flight 请求熔断器时,可能的日志信息如下:
[o.e.x.m.e.l.LocalExporter] [1611816935001404932] unexpected error while indexing monitoring documentorg.elasticsearch.xpack.monitoring.exporter.ExportException: RemoteTransportException[[1611816935001404732][9.10.153.16:9300][indices:data/write/bulk[s]]]; nested: CircuitBreakingException[[in_flight_requests] Data too large, data for [<transport_request>] would be [19491363612/18.1gb], which is larger than the limit of [17066491904/15.8gb]];优化建议:
出现熔断说明当前节点 JVM 使用率过高,通过熔断保护进程不会 OOM。可以通过适当降低读写、清理内存等方法降低节点负载,也可以通过升级节点内存规格来提高 JVM 大小。
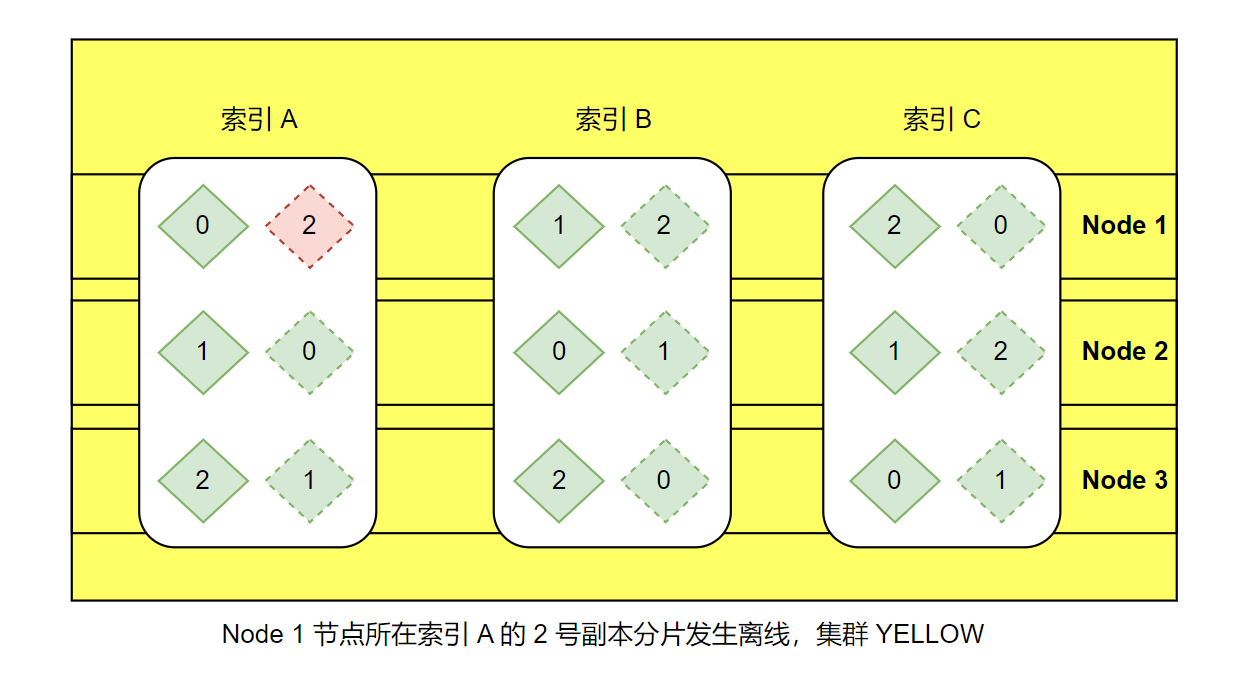
场景4:增加副本分片( REPLICA_ADDED)
ES 副本可以给业务带来查询性能吞吐的提升,同时可以增加数据的高可用。每增加1个副本,索引数据可承受节点离线数量也就加1,这也就意味着副本分片对于 ES 来说是多么重要。
然而我们在 add replicas 的时候,集群会立即进入 YELLOW 状态,这是因为 ES 集群状态的判定是分片级别。也就是说但凡有一块分片不是 ready 状态,都会影响 cluster health。这时我们只需耐心等待即可,待副本分片初始化完成,集群就会恢复 GREEN 状态。
建议:
add replicas 有一定性能开销,建议在业务低峰期进行。
场景5:进行快照恢复(NEW_INDEX_RESTORED)
快照恢复是个例外,我们知道,ES 集群状态的判定是分片级别。也就是说但凡有一块分片不是 ready 状态,都会影响 cluster health,那么 ES 在发起快照恢复时,主分片一定不是 ready 状态,但这个不会造成集群 RED,只会导致集群发生 YELLOW,直到快照数据恢复完成。

建议:
快照操作有一定性能开销,建议在业务低峰期进行。
需要人工干预
场景1:磁盘水位问题(ALLOCATION_FAILED)
磁盘水位过高会导致 ES 新生分片无法分配,更严重甚至会导致节点离线。
- 集群所有节点都达到磁盘低水位,导致副本分片不允许分配
- 磁盘写满而导致节点永久脱离
这两种情况都会导致集群 YELLOW,不同的是,如果只是个别节点磁盘写满导致节点离线,达到阈值之后,会强制分配副本到其他节点(unassigned.node_left.delayed_timeout),但如果所有节点都达到磁盘低水位,那么副本分片将无法再分配,直到人为干预:
[o.e.c.r.a.DiskThresholdMonitor] [1655733980000740332] low disk watermark [85%] exceeded on [4s2ulawjTSSvt-QQlqsDPQ][1655800410000987332][/data1/containers/1655800410000987332/es/data/nodes/0] free: 70.1gb[14.2%], replicas will not be assigned to this node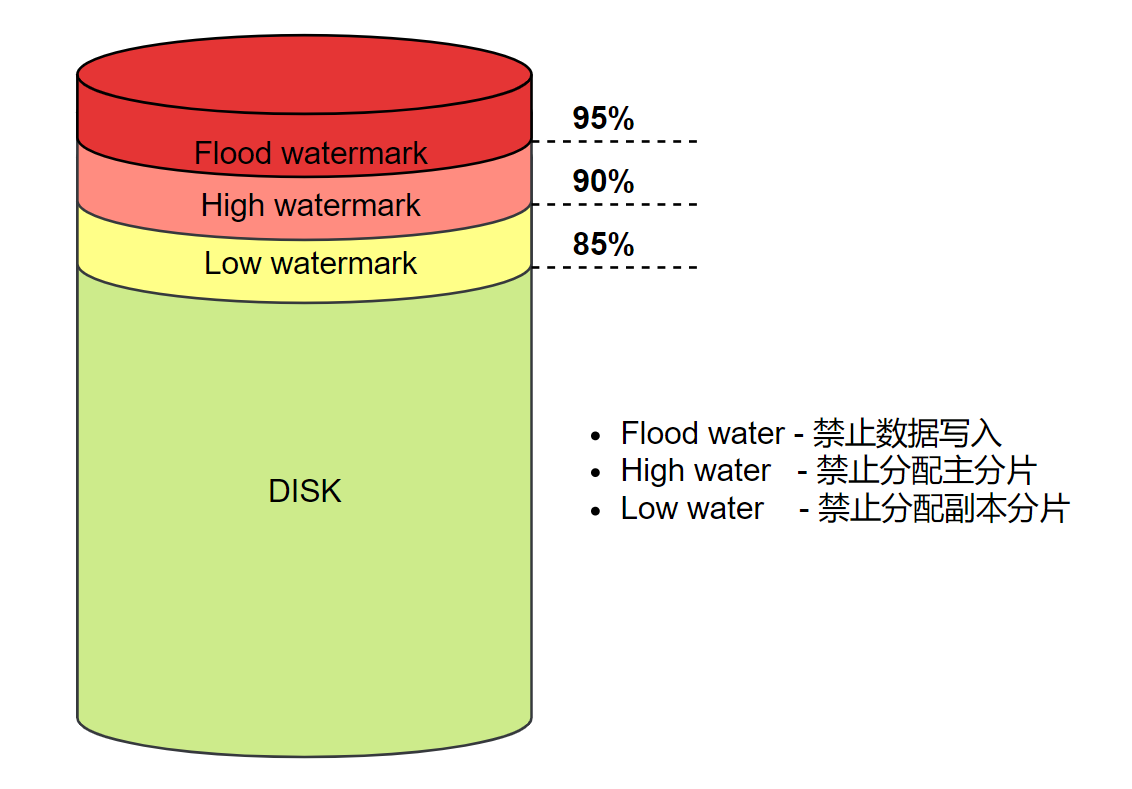
优化建议:
- 订阅集群告警,及时发现集群水位,保持集群磁盘水位在健康状态。
- 制定 ILM(索引生命周期管理)策略,定期清理过期数据,保持健康水位。
场景2:节点永久离线(NODE_LEFT)
我们同样假设集群当中所有索引都有冗余副本分片,且只有一个节点宕机下线,只不过因为一些原因,这个节点不会再加回集群,那么集群这时会进入 yellow 状态。如果不人为干预,则会在 delayed_timeout 达到阈值后强制分配到其他节点,当然,这也就会降低 ES 的整体性能:
[o.e.c.r.a.AllocationService] [1699879628011021732] failing shard [failed shard, shard [.ds-cdwch-2023.11.13-000404][23], node[vAnpreEnTaSWY-QYV3GGWg], [R], recovery_source[peer recovery], s[INITIALIZING], a[id=r48vj2pQRmauAuXKm-qX9g], unassigned_info[[reason=NODE_LEFT], at[2023-11-14T06:58:10.583Z], delayed=true, details[node_left [vAnpreEnTaSWY-QYV3GGWg]], allocation_status[no_attempt]], message [failed recovery], failure [RecoveryFailedException[[.ds-cdwch-2023.11.13-000404][23]: Recovery failed from {1675171390003468332}{QUotMJ0DRsiM442JPtqlmA}{2aWADQvMRjSKRRsFg-Abrw}{10.1.0.47}{10.1.0.47:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800007, xpack.installed=true, set=800007, transform.node=true, ip=9.15.118.138, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8} into {1670988404000091932}{vAnpreEnTaSWY-QYV3GGWg}{-vaCwjbhSpG1iGEY18Wz4A}{10.0.128.45}{10.0.128.45:9300}{hilrst}{ml.machine_memory=67168968704, rack=cvm_8_800006, xpack.installed=true, set=800006, transform.node=true, ip=9.15.104.46, ml.max_open_jobs=512, ml.max_jvm_size=34326183936, region=8}]; nested: RemoteTransportException[[1675171390003468332][10.1.0.47:9300][internal:index/shard/recovery/start_recovery]]; nested: ScpRecoveryIsRunningException[Another recovery task is running for same replica and node. Existing recovery: RecoveryKey{shard: [.ds-cdwch-2023.11.13-000404][23], target:vAnpreEnTaSWY-QYV3GGWg, recovery:101021}, New recovery: RecoveryKey{shard: [.ds-cdwch-2023.11.13-000404][23], target:vAnpreEnTaSWY-QYV3GGWg, recovery:101026}]; ], markAsStale [true]]
优化建议:
节点一般不会无故离线,如果发生节点偶现脱离,则要进一步排查 ES 是否存在资源瓶颈。
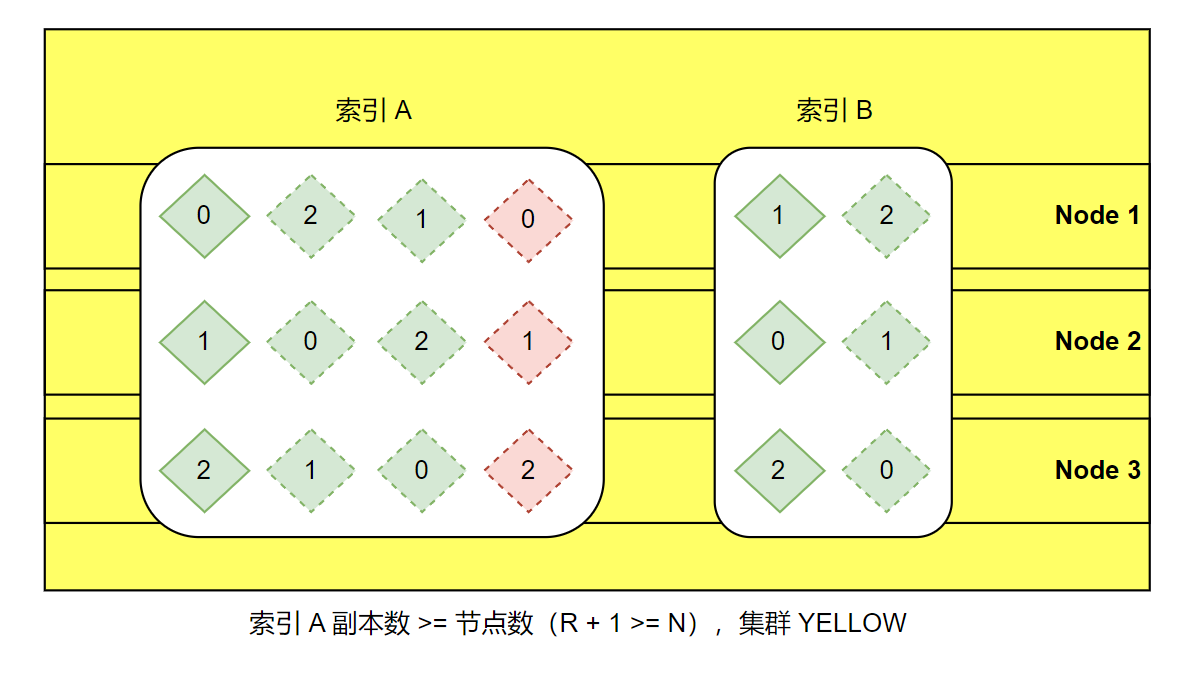
场景3:副本分片过多(ALLOCATION_FAILED)
对于 ES 相同一个节点,无法分配同一块副本分片,这也就意味着,索引的最大副本数(Replicas) = Date Node 数量 - 1,当 Replicas >= Date Node nums 时,则会发生副本无法继续分配的情况,要避免此问题,请按照以下公式,确保每个索引的每个副本分片少于群集中节点的数量:
N >= R + 1其中 N 是 ES 集群中节点的数量,R 是索引的副本数量(num_of_replicas)。
总结
YELLOW 状态可能会降低集群读写性能,当然,除此之外,YELLOW 对业务无其他负面影响,但是有一点格外重要 —— task schedule。
我们知道,ES 的 task 调度有优先级,其中 allocation replicas shards 的优先级就比 relocation 要高,也就是说,当集群处于 yellow 状态时,ES 默认是不会触发 rebalance 的,这一点很可怕。
正因为 ES 有 shards rebalance 的机制,才能做到尽可能的负载均衡,以充分发挥分布式计算的性能。试想一下,当 rebalance 无法触发时,ES 将会是什么状态?我想大家很容易想到的就是:热点瓶颈、负载不均,甚至读写拒绝。好在是 ES 在设计之初想到了这点,所以提供了一个动态参数以供调整:
PUT _cluster/settings
{
"transient": {
"cluster.routing.allocation.allow_rebalance": "indices_primaries_active"
}
}always- 任何情况都可触发 rebalance,包括集群 REDindices_primaries_active- 主分片 Ready 即可触发 rebalance,包括集群 YELLOWindices_all_active- (默认)所有分片都 Ready 才能触发 rebalance,也就是集群 GREEN
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。