Prometheus部署与体验
原创
Prometheus是一款开源的监控系统,用于记录和查询应用程序和系统的指标,在云原生时代中是标配的监控系统。
Prometheus的介绍
Prometheus最初由SoundCloud开发,旨在监控其基础设施和应用程序。随着时间的推移,它变得越来越流行,成为云原生时代的监控系统。Prometheus是一款分布式系统,它使用pull模型从应用程序和系统中收集指标,并使用PromQL(Prometheus Query Language)进行查询和分析。Prometheus还提供了丰富的可视化和报警功能,可以帮助我们更好地理解应用程序和系统的状态。
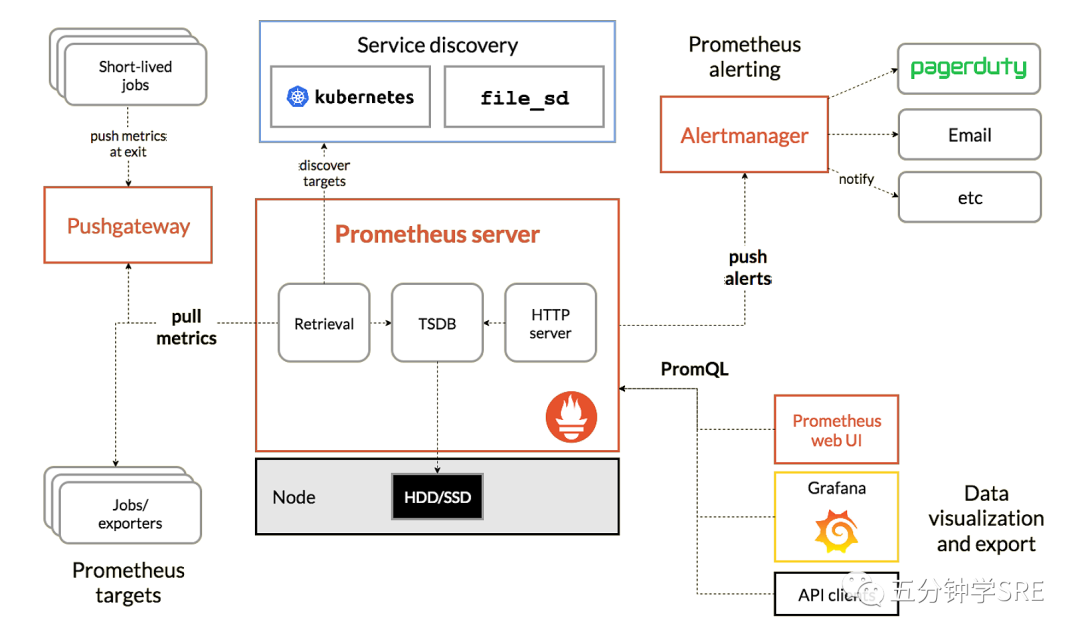
Prometheus的架构
Prometheus的架构可以分为四层:Targets、Exporters、Prometheus Server和Client Libraries。
Targets
Targets是需要监控的应用程序或系统组件。Prometheus使用pull模型从这些目标中收集指标。Targets可以是HTTP服务器,JMX服务器或者任何支持Prometheus的指标格式的服务器。
Exporters
Exporters是一个连接目标和Prometheus的适配器。它可以将不同的应用程序或系统组件的指标转换为Prometheus的指标格式。Prometheus支持许多Exporter,例如Node Exporter、Blackbox Exporter和JMX Exporter。
Prometheus Server
Prometheus Server负责收集、存储和查询指标。它使用HTTP协议与Targets和Exporters通信,并存储指标数据。Prometheus Server还提供了PromQL,这是一种用于查询和分析指标数据的查询语言。
Client Libraries
Client Libraries是用于将指标数据公开到Prometheus的库。它们可用于Java、Go、Python和其他编程语言,使应用程序开发人员可以将自定义指标数据添加到Prometheus中。
下面我们将从实践入手,来深入的学习Prometheus。
Prometheus部署
解压安装包
mkdir -p /data/prometheus
tar xf prometheus-2.42.0.linux-amd64.tar.gz
cp -far prometheus-2.42.0.linux-amd64/* /data/prometheus/Prometheus的启动参数的解释
usage: prometheus [<flags>]
The Prometheus monitoring server
Flags:
-h, --help 查看命令帮助
--version 查看版本信息
--config.file="prometheus.yml"
Prometheus配置文件路径
--web.listen-address="0.0.0.0:9090"
监听地址
--web.read-timeout=5m 超时读取请求并关闭空闲连接之前的最大持续时间
--web.max-connections=512 最大同时连接数
--web.external-url=<URL> 可从外部访问Prometheus的URL,(例如,如果Prometheus是通过反向代理提供的)。
用来生成返回到Prometheus本身的相对和绝对路径。如果该网址包含路径部分,它将是
用于为Prometheus服务的所有HTTP端点添加前缀。 如果省略,将导出相关的URL组件
自动。
--web.route-prefix=<path> Web端点内部路由的前缀。 默认为--web.external-url的路径。
--web.user-assets=<path> 静态资源目录位于:/user.
--web.enable-lifecycle 启用关机并通过HTTP请求重新加载.
--web.enable-admin-api 为管理员控制操作启用API端点.
--web.console.templates="consoles"
控制台模板目录的路径位于:/consoles.
--web.console.libraries="console_libraries"
控制台库目录的路径.
--web.page-title="Prometheus Time Series Collection and Processing Server"
Prometheus实例的文档标题.
--web.cors.origin=".*" 用于CORS来源的正则表达式:'https?://(domain1|domain2)\.com'
--storage.tsdb.path="data/"
指标存储的基本路径.
--storage.tsdb.retention.time=STORAGE.TSDB.RETENTION.TIME
将样品保存多长时间。 设置此标志后,它将覆盖“ storage.tsdb.retention”。 如果未设置此标志,“ storage.tsdb.retention”或“ storage.tsdb.retention.size”,则保留时间默认为15d。 支持的单位:y,w,d,h,m,s,ms。
--storage.tsdb.retention.size=STORAGE.TSDB.RETENTION.SIZE
EXPERIMENTAL]可以为块存储的最大字节数。 需要一个单位,受支持的单位:B,KB,MB,GB,TB,PB,EB。 例如:“ 512MB”。 该标志是试验性的,可以在将来的版本中进行更改。
--storage.tsdb.no-lockfile
不要在数据目录中创建锁文件。
--storage.tsdb.allow-overlapping-blocks
[EXPERIMENTAL]允许重叠的块,从而启用垂直压缩和垂直查询合并。
--storage.tsdb.wal-compression
压缩tsdb WAL。
--storage.remote.flush-deadline=<duration>
关闭或配置重新加载时等待冲洗样品的时间
--storage.remote.read-sample-limit=5e7
在单个查询中要通过远程读取接口返回的最大样本总数。 0表示没有限制。 对于流式响应类型,将忽略此限制。
--storage.remote.read-concurrent-limit=10
并发远程读取调用的最大数目。 0表示没有限制。
--storage.remote.read-max-bytes-in-frame=1048576
编组之前用于流式传输远程读取响应类型的单个帧中的最大字节数。 请注意,客户端也可能会限制帧大小。 默认为protobuf建议的1MB。
--rules.alert.for-outage-tolerance=1h
容忍普罗米修斯中断以恢复警报“ for”状态的最大时间。
--rules.alert.for-grace-period=10m
警报和恢复的“ for”状态之间的最短持续时间。 仅对于配置的“ for”时间大于宽限期的警报,才保持此状态。
--rules.alert.resend-delay=1m
重新发送警报到Alertmanager之前等待的最短时间
--alertmanager.notification-queue-capacity=10000
等待的Alertmanager通知的队列容量。
--alertmanager.timeout=10s
向Alertmanager发送警报的超时。
--query.lookback-delta=5m 在表达式评估和联合期间用于检索指标的最大回溯持续时间。
--query.timeout=2m 查询中止之前可能要花费的最长时间。
--query.max-concurrency=20
并发执行的最大查询数。
--query.max-samples=50000000
单个查询可以加载到内存中的最大样本数。 请注意,如果查询尝试将更多的样本加载到内存中,则查询将失败,因此这也限制了查询可以返回的样本数。
--log.level=info 仅记录具有给定严重性或更高严重性的消息。 下列之一:[调试,信息,警告,错误]
--log.format=logfmt 日志消息的输出格式。 下列之一:[logfmt,json]加载到系统管理
cat <<EOF >/etc/cat <<EOF >/etc/systemd/system/prometheus.service
[Unit]
Description="prometheus"
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/data/prometheus/prometheus --config.file=/data/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data --web.enable-lifecycle --enable-feature=remote-write-receiver --query.lookback-delta=2m --web.enable-admin-api
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=prometheus
[Install]
WantedBy=multi-user.target
EOF
systemd/system/prometheus.service[Unit]Description="prometheus"Documentation=https://prometheus.io/After=network.target[Service]Type=simpleExecStart=/data/prometheus/prometheus --config.file=/data/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data --web.enable-lifecycle --enable-feature=remote-write-receiver --query.lookback-delta=2m --web.enable-admin-apiExecReload=/bin/kill -HUP $MAINPIDRestart=on-failureSuccessExitStatus=0LimitNOFILE=65536StandardOutput=syslogStandardError=syslogSyslogIdentifier=prometheus[Install]WantedBy=multi-user.targetEOF
启动
systemctl enable prometheus
systemctl start prometheus
systemctl status prometheus启动参数的解释
--config.file=/data/prometheus/prometheus.yml
指定 Prometheus 的配置文件路径
--storage.tsdb.path=/data/prometheus/data
指定 Prometheus 时序数据的硬盘存储路径
--web.enable-lifecycle
启用生命周期管理相关的 API,比如调用 /-/reload 接口就需要启用该项
--enable-feature=remote-write-receiver
启用 remote write 接收数据的接口,启用该项之后,categraf、grafana-agent 等 agent 就可以通过 /api/v1/write 接口推送数据给 Prometheus
--query.lookback-delta=2m
即时查询在查询当前最新值的时候,只要发现这个参数指定的时间段内有数据,就取最新的那个点返回,这个时间段内没数据,就不返回了
--web.enable-admin-api
启用管理性 API,比如删除时间序列数据的 /api/v1/admin/tsdb/delete_series 接口Promtheus热加载
Prometheus的时序数据库在存储了大量的数据后,每次重启Prometheus进程的时间会越来越慢。Prometheus提供了在运行时热加载配置信息的功能。有两种热加载的方式:
1,查看Prometheus的进程id,发送SIGHUP信号:
kill -HUP <pid>2,发送一个POST请求到/-/reload,需要在启动时给定–web.enable-lifecycle选项
curl -X POST http://localhost:9090/-/reload如果配置热加载成功,Prometheus会打印出下面的log:
... msg="Loading configuration file" filename=prometheus.yml ...数据查看
????在启动之后我们可以来看下,Prometheus的使用。Prometheus 默认会在 9090 端口监听,访问这个端口就可以看到 Prometheus 的 Web 页面
执行PromQL可以查询到一些监控的数据
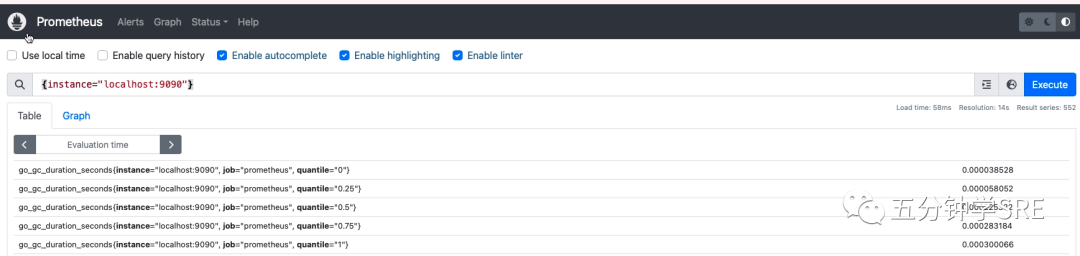
可能你会比较好奇我们还没有上报数据,为什么就有监控数据产生。原因是 Prometheus 自己抓取自己的,Prometheus 会在 /metrics 接口暴露监控数据,我们可以curl下看看数据:
/data/prometheus# curl http://127.0.0.1:9090/metrics | head -10
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.8528e-05
go_gc_duration_seconds{quantile="0.25"} 5.8052e-05
go_gc_duration_seconds{quantile="0.5"} 9.3403e-05
go_gc_duration_seconds{quantile="0.75"} 0.000236001
go_gc_duration_seconds{quantile="1"} 0.000300066
go_gc_duration_seconds_sum 0.001351161
go_gc_duration_seconds_count 9
# HELP go_goroutines Number of goroutines that currently exist.
100 8026 0 8026 0 0 7837k 0 --:--:-- --:--:-- --:--:-- 7837k
curl: (23) Failed writing body (0 != 2048)而且同时 Prometheus 在配置文件里也配置了抓取规则,可以查看prometheus.yml 配置
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]配置解读
localhost:9090 是暴露监控数据的地址,没有指定接口路径,默认使用 /metrics,没有指定 scheme,默认使用 HTTP,所以实际请求的是 http://localhost:9090/metrics。
Node-Exporter 部署
Prometheus设计的其主要任务是负责数据的收集,存储并且对外提供数据查询支持,而不是直接监控机器。
我们来部署下机器监控的exporter,Prometheus监控机器只需要在机器上部署对应的exporter,然后在拉取规则中配置exporter的地址即可。
Node-exporter 下载
https://prometheus.io/download/#node_exporter

解压部署
mkdir?/data/node_exporter
tar vzxf node_exporter-1.5.0.linux-amd64.tar.gz
cp -arp node_exporter-1.5.0.linux-amd64/* /data/node_exporter/
chown -R prometheus:prometheus /data/node_exporter/node_exporter常用命令参数详解
用法:node_exporter [<flags>]
标志:
-h,--help显示上下文相关的帮助(也可以尝试--help-long和--help-man)。
--collector.cpu.info启用指标cpu_info
--collector.diskstats.ignored-devices =“ ^(ram | loop | fd |(h | s | v | xv)d [a-z] | nvme \\ d + n \\ d + p)\\ d + $”
设备的正则表达式,忽略diskstats。
--collector.filesystem.ignored-mount-points =“ ^ /(dev | proc | sys | var / lib / docker /.+)($ | /)”
对于文件系统收集器,要忽略的安装点正则表达式。
--collector.filesystem.ignored-fs-types =“ ^(autofs | binfmt_misc | bpf | cgroup2?| configfs | debugfs | devpts | devtmpfs | fusectl | hugetlbfs | iso9660 | mqueue | nsfs | overlay | proc | procfs | pstore | rpc_pipefs | securityfs | selinuxfs | squashfs | sysfs | tracefs)$“
文件系统收集器忽略的文件系统类型的正则表达式。
--collector.netclass.ignored-devices =“ ^ $”
Netclass收集器忽略的网络设备的正则表达式。
--collector.netdev.device-blacklist = COLLECTOR.NETDEV.DEVICE-BLACKLIST
净设备正则表达式到黑名单(相互排斥于设备白名单)。
--collector.netdev.device-whitelist = COLLECTOR.NETDEV.DEVICE-WHITELIST
将网络设备的正则表达式添加到白名单(相互排斥于设备黑名单)。
--collector.netstat.fields =“ ^(。* _(InErrors | InErrs)| Ip_Forwarding | Ip(6 | Ext)_(InOctets | OutOctets)| Icmp6?__(InMsgs | OutMsgs)| TcpExt_(Listen。* | Syncookies。* | TCPSynRetrans)| Tcp_(ActiveOpens | InSegs | OutSegs | PassiveOpens | RetransSegs | CurrEstab)| Udp6?_(InDatagrams | OutDatagrams | NoPorts | RcvbufErrors | SndbufErrors))$“
Regexp字段返回以返回netstat收集器。
--collector.ntp.server =“ 127.0.0.1”
用于ntp收集器的NTP服务器
--collector.ntp.protocol-version = 4
NTP协议版本
--collector.ntp.server-is-local
确认collector.ntp.server地址不是公共ntp服务器
--collector.ntp.ip-ttl = 1发送NTP查询时要使用的IP TTL
--collector.ntp.max-distance = 3.46608s
到根的最大累积距离
--collector.ntp.local-offset-tolerance = 1ms
本地时钟和本地ntpd时间之间的偏差可以容忍
--path.procfs =“ / proc”挂载点。
--path.sysfs =“ / sys” sysfs挂载点。
--path.rootfs =“ /” rootfs安装点。
--collector.perf.cpus =“”应该从中收集性能指标的CPU列表
--collector.perf.tracepoint = COLLECTOR.PERF.TRACEPOINT ...
应收集的性能跟踪点
--collector.powersupply.ignored-supplies =“ ^ $”
电源正则表达式对于powersupplyclass收集器将被忽略。
--collector.qdisc.fixtures =“”
用于qdisc收集器端到端测试的测试夹具
--collector.runit.servicedir =“ / etc / service”
Runit服务目录的路径。
--collector.supervisord.url =“ http:// localhost:9001 / RPC2”
XML RPC端点。
--collector.systemd.unit-whitelist =“。+”
将系统单位的正则表达式列入白名单。单元必须同时与白名单匹配,并且与黑名单不匹配。
--collector.systemd.unit-blacklist =“。+ \\。(自动安装|设备|安装|范围|切片)”
将系统单位的正则表达式列入黑名单。单元必须同时与白名单匹配,并且与黑名单不匹配。
--collector.systemd.enable-task-metrics
启用服务单元任务指标unit_tasks_current和unit_tasks_max
--collector.systemd.enable-restarts-metrics
启用服务单位指标service_restart_total
--collector.systemd.enable-start-time-metrics
启用服务单位指标unit_start_time_seconds
--collector.textfile.directory =“”
用于读取带有度量标准的文本文件的目录。
--collector.vmstat.fields =“ ^(oom_kill | pgpg | pswp | pg。* fault)。*”
用于vmstat收集器返回的字段的正则表达式。
--collector.wifi.fixtures =“”
测试装置以用于wifi收集器指标
--collector.arp启用arp收集器(默认值:启用)。
--collector.bcache启用bcache收集器(默认值:启用)。
--collector.bonding启用绑定收集器(默认值:启用)。
--collector.btrfs启用btrfs收集器(默认值:启用)。
--collector.buddyinfo启用buddyinfo收集器(默认值:禁用)
--collector.conntrack启用conntrack收集器(默认值:启用)。
--collector.cpu启用cpu收集器(默认值:启用)。
--collector.cpufreq启用cpufreq收集器(默认值:启用)。
--collector.diskstats启用diskstats收集器(默认值:启用)。
--collector.drbd启用drbd收集器(默认值:禁用)。
--collector.edac启用edac收集器(默认值:启用)。
--collector.entropy启用熵收集器(默认值:启用)。
--collector.filefd启用filefd收集器(默认值:启用)。
--collector.filesystem启用文件系统收集器(默认值:启用)。
--collector.hwmon启用hwmon收集器(默认值:启用)。
--collector.infiniband启用infiniband收集器(默认值:启用)。
--collector.interrupts启用中断收集器(默认值:禁用)。
--collector.ipvs启用ipvs收集器(默认值:启用)。
--collector.ksmd启用ksmd收集器(默认值:禁用)。
--collector.loadavg启用loadavg收集器(默认值:启用)。
--collector.logind启用登录的收集器(默认值:禁用)。
--collector.mdadm启用mdadm收集器(默认值:启用)。
--collector.meminfo启用meminfo收集器(默认值:启用)。
--collector.meminfo_numa启用meminfo_numa收集器(默认值:禁用)。
--collector.mountstats启用mountstats收集器(默认值:禁用)。
--collector.netclass启用netclass收集器(默认值:启用)。
--collector.netdev启用netdev收集器(默认值:启用)。
--collector.netstat启用netstat收集器(默认值:启用)。
--collector.nfs启用nfs收集器(默认值:启用)。
--collector.nfsd启用nfsd收集器(默认值:启用)。
--collector.ntp启用ntp收集器(默认值:禁用)。
--collector.perf启用性能收集器(默认值:禁用)。
--collector.powersupplyclass
启用powersupplyclass收集器(默认值:启用)。
--collector.pressure启用压力收集器(默认值:启用)。
--collector.processes启用进程收集器(默认值:禁用)。
--collector.qdisc启用qdisc收集器(默认值:禁用)。
--collector.rapl启用rapl收集器(默认值:启用)。
--collector.runit启用runit收集器(默认值:禁用)。
--collector.schedstat启用schedstat收集器(默认值:启用)。
--collector.sockstat启用sockstat收集器(默认值:启用)。
--collector.softnet启用softnet收集器(默认值:启用)。
--collector.stat启用统计信息收集器(默认值:启用)。
--collector.supervisord启用受监管的收集器(默认值:禁用)。
--collector.systemd启用systemd收集器(默认值:禁用)。
--collector.tcpstat启用tcpstat收集器(默认值:禁用)。
--collector.textfile启用文本文件收集器(默认值:启用)。
--collector.thermal_zone启用thermal_zone收集器(默认值:启用)。
--collector.time启用时间收集器(默认值:启用)。
--collector.timex启用timex收集器(默认值:启用)。
--collector.udp_queues启用udp_queues收集器(默认值:启用)。
--collector.uname启用uname收集器(默认值:启用)。
--collector.vmstat启用vmstat收集器(默认值:启用)。
--collector.wifi启用wifi收集器(默认值:禁用)。
--collector.xfs启用xfs收集器(默认值:启用)。
--collector.zfs启用zfs收集器(默认值:启用)。
--web.listen-address =“:9100”
公开指标和Web界面的地址。
--web.telemetry-path =“ / metrics”
公开指标的路径。
--web.disable-exporter-metrics
排除有关导出器本身的指标(promhttp _ *,process _ *,go_ *)。
--web.max-requests = 40并行抓取请求的最大数量。使用0禁用。
--collector.disable-defaults
将所有收集器默认设置为禁用。
--web.config =“” [EXPERIMENTAL]可以启用TLS或身份验证的配置yaml文件的路径。
--log.level = info仅记录具有给定严重性或更高严重性的消息。下列之一:[调试,信息,警告,错误]
--log.format = logfmt日志消息的输出格式。下列之一:[logfmt,json]
--version 查看版本信息加载到系统管理
cat <<EOF >/etc/systemd/system/node_exporter.service
[Unit]
Description=node_export
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/data/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF启动
systemctl enable node_exporter.service
systemctl start node_exporter.service
systemctl status node_exporter.service
netstat -talunp| grep 9100
tcp6 0 0 :::9100 :::* LISTEN 25684/node_exporter????Node-Exporter 默认的监听端口是 9100,访问http://localhost:9100/metrics, 就可以获取到机器的所有的监控数据
# HELP node_disk_reads_completed_total The total number of reads completed successfully.
# TYPE node_disk_reads_completed_total counter
node_disk_reads_completed_total{device="sda"} 2.316812e+06
node_disk_reads_completed_total{device="sdb"} 743
# HELP node_disk_reads_merged_total The total number of reads merged.
# TYPE node_disk_reads_merged_total counter
node_disk_reads_merged_total{device="sda"} 66453
node_disk_reads_merged_total{device="sdb"} 0可以看到在指标数据之前都会有两个注释,HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。
配置数据采集
把 Node-Exporter 的地址配置到 prometheus.yml 中就可以让Prometheus server获取到机器的监控数据。修改了配置之后我们需要reload 给Prometheus发送个HUP 信号,修改之后的配置:
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9100"]????其中 targets 是个数组,如果要监控更多机器,就在 targets 中写上多个 Node-Exporter 的地址,用逗号隔开。
reload Prometheus
systemctl reload prometheus.service监控数据查看
点击web界面的Status -> Targets 就可以看到最新的Targets了
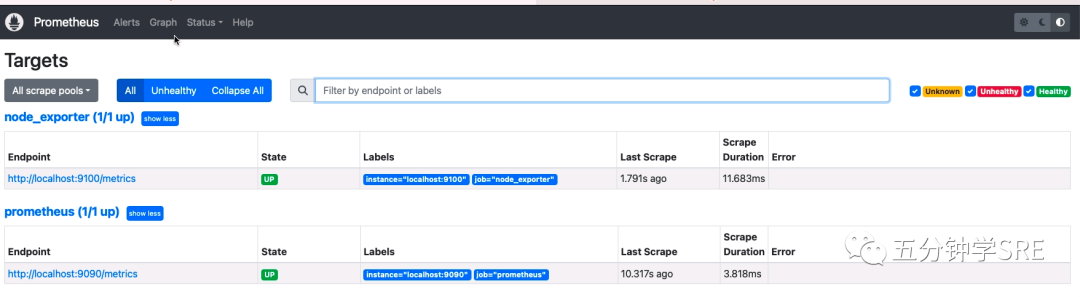
这个时候我们在监控数据查询框数据node,可以看到很多以node开头指标,这些就是node_exporter 上报的指标
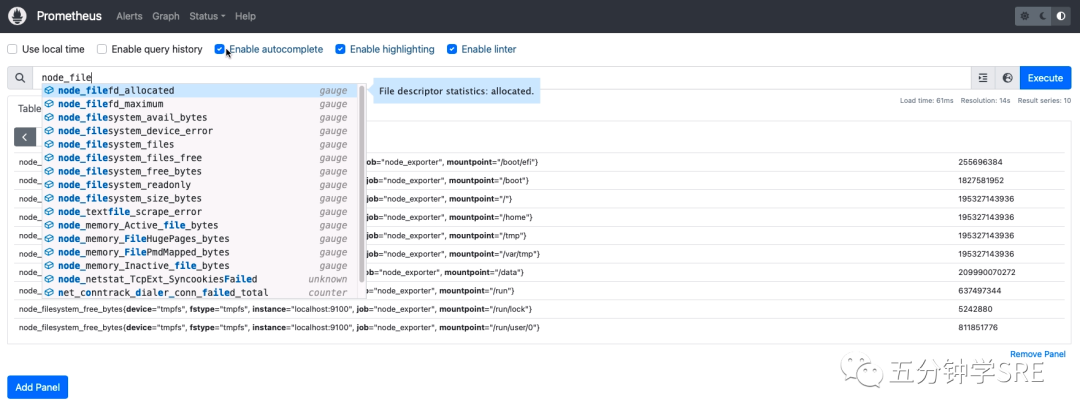
通过Graph面板,我们直接使用PromQL实时查询监控数据:
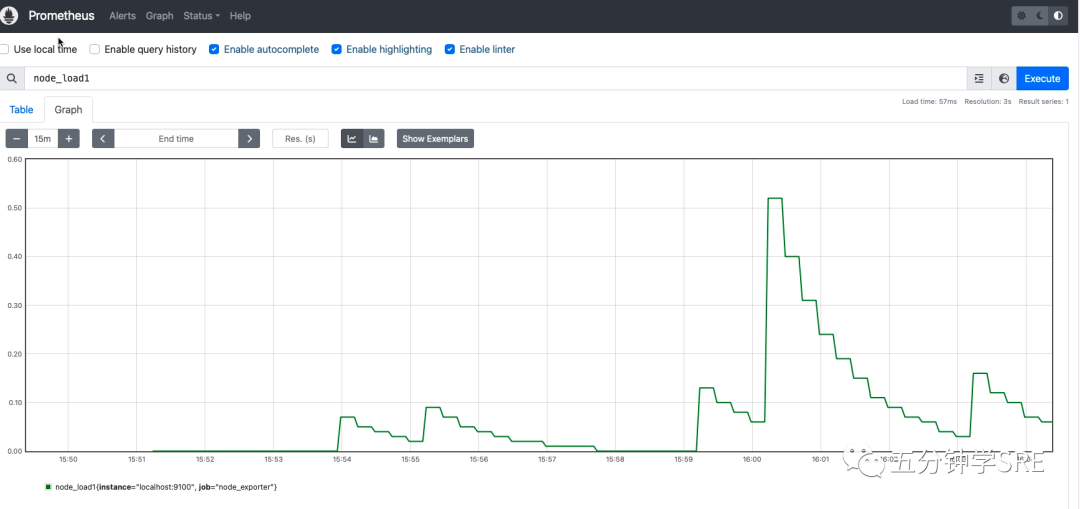
通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。关于promQL我们在后面详细的讲解。
Node-Exporter 默认内置了很多 collector(可以到官网查看:https://github.com/prometheus/node_exporter#collectors),比如 cpu、loadavg、filesystem 等,可以通过命令行启动参数来控制这些 collector,比如要关掉某个 collector,使用 --no-collector.,如果要开启某个 collector,使用 --collector.。有了上面的数据之后,我们在下个文章介绍下Prometheus的监控规则的配置与监控的实战。
可以查看原文:
关注公众号获取更多sre博文:五分钟学SRE
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。