可观测平台-2: 开源解决方案
原创
概述
构建一个复杂应用系统的监控和告警系统,涉及到从前端、各类后端语言的 API、网关、消息队列(MQ)、缓存(Cache)以及数据库(DB)等多个组件。自动绘制应用系统的组件拓扑图并关联对应组件的状态是一个复杂的过程,通常需要以下几个步骤:
- 数据收集和集成 首先,需要确保所有组件(前端、后端服务、API网关、MQ、Cache、DB等)都能产生监控数据。 使用如 Prometheus、Graphite 等工具来收集这些组件的监控数据。 对于日志数据,可以使用 ELK Stack(Elasticsearch, Logstash, Kibana)或 Fluentd 等进行收集和分析。
- 服务发现和拓扑自动绘制 使用服务发现工具(如 Consul、Zookeeper、Etcd)来动态识别系统中的各个组件。 利用监控工具中的服务发现机制(如 Prometheus 的服务发现功能)来自动识别和监控新的或变更的服务。 使用专门的工具(如 Dynatrace、Datadog)或自定义脚本来绘制应用的组件拓扑图。
- 性能监控和告警 在监控工具中(如 Prometheus、Grafana)配置性能监控和告警规则。 确保每个组件的关键性能指标(如响应时间、错误率、吞吐量等)都被监控并设置了合理的告警阈值。 对于告警的管理,可以使用 Alertmanager 或其他告警管理工具来配置告警路由、重复抑制和通知方式。
- 状态关联和展示 在 Grafana 或类似的可视化工具中,创建仪表板来展示各组件的状态和性能指标。 利用拓扑图来展示组件之间的依赖关系,并在图中直观地反映出组件的健康状态。 通过集成日志和性能数据,可以在单个界面中提供更全面的系统视图。
- 链路追踪 对于分布式系统中的请求流程,使用链路追踪工具(如 Jaeger、Zipkin)来追踪和记录请求在各服务间的流转。 链路追踪数据可以帮助识别性能瓶颈和故障点。
- 测试和优化 在部署监控和告警系统后,进行充分的测试,以确保所有组件的状态能够准确监控并及时告警。 根据实际运行情况调整监控策略和告警阈值,确保监控系统的有效性和准确性。 通过这些步骤,可以构建一个全面的监控和告警系统,不仅能自动绘制并更新应用系统的组件拓扑图,还能实时关联并展示每个组件的状态,从而有效地支持复杂应用系统的运维工作。
开源软件集成
针对上述讨论的监控和告警系统,存在多种开源软件选择,这些软件可以支持构建一个全面的监控解决方案。以下是一些主要的开源工具:
ClickHouse、Neo4j、VectorDB、PromQL、LogQL、OpenTracing、Prometheus、Grafana、AlertManager 和 DeepFlow 等开源工具。
这些工具可以相互集成,构建一个全面的监控和告警系统,从而覆盖从前端到后端、从应用层到数据层的各个方面。选择合适的工具组合,取决于具体的应用场景、技术栈和性能需求。 开源的可观察性平台解决方案通过 GitHub Actions 自动交付创建服务。
项目链接:https://github.com/open-source-solution-design/ObservabilityPlatform.git
架构图

该解决方案使用以下开源软件:
- 数据收集:使用 Prometheus、OpenTelemetry,Deepflow-agent,Promtail,cloudquery 等工具从系统组件、应用程序和云账户数据同步
- 数据存储:使用 ClickHouse、Neo4j、VectorDB 等工具存储观测数据。
- 数据分析:使用 Prometheus、Grafana 等工具分析观测数据。
- 数据可视化:使用 Grafana 等工具以可视化的方式呈现观测数据。
可以提供资源状态系统或应用程序的性能和可靠性, 诊断和解决问题, 优化系统或应用程序的性能和功能分析等,包括以下应用场景:
优势
- 开源:该解决方案使用开源工具,因此成本低廉。
- 可扩展:该解决方案使用可扩展的技术栈,因此可以满足各种需求。
- 自动化:该解决方案使用 GitHub Actions 自动交付创建服务,因此可以快速部署和维护。
CICD
流水线配置文件
配置文件位于 .github/workflows/pipeline.yaml 由四个阶段组成:
- 构建测试:此阶段从源代码构建 APP, 并运行测试套件,以确保APP 正常工作。
- Docker 镜像:此阶段构建一个包含 APP 的 Docker 镜像。
- 设置 K3s:此阶段在远程服务器上设置 K3s 集群。
- 部署应用:此阶段将 APP 部署到 K3s 集群。
Playook 角色说明
- 可观察性平台配置库由以下角色组成:
- 容器集群相关相关的 Ansible playbook roles
- k3s: 提供管理 k3s 集群的任务。
- k3s-addon: 部署 k3s 附加组件。
- k3s-reset: 将 k3s 集群重置为初始状态。
- secret-manger: 部署 secret-manager 来管理敏感数据。
- cert-manager: 部署 cert-manager 以颁发 TLS 证书。
- clickhouse: 部署 Clickhouse 以存储和分析时序数据。
- observability-agent: 在 k3s 节点上部署可观察性代理。
- observability-server: 部署可观察性服务器组件。
- mysql: 部署 MySQL 以存储 Deepflow数据以及Grafana配置信息。
- alerting: 存储 Prometheus Alertmanager Rules 。
- 非容器集群相关的 Ansible playbook roles
- node-exporter: 部署 node_exporter 来收集系统指标。
- prometheus-transfer: 转发 Prometheus 将指标传输到远程存储。
- promtail-agent: 部署 Promtail 从节点收集日志。
- 容器集群相关相关的 Ansible playbook roles
触发器
管道由以下事件触发:
- 当打开或更新拉取请求时。
- 当代码推送到主分支时。
- 当工作流程手动调度时。
环境变量
在YAML文件或CI/CD流水线配置中定义的ENV变量:
- TZ: Asia/Shanghai:设置时区为Asia/Shanghai。
- REPO: "artifact.onwalk.net":指定一个存储库的URL或标识符。
- IMAGE: base/${{ github.repository }}:基于GitHub存储库构建一个容器镜像名称。
- TAG: ${{ github.sha }}:将镜像标签设置为GitHub存储库的提交SHA。
- DNS_AK: ${{ secrets.DNS_AK }}:使用GitHub的密钥设置阿里云DNS访问密钥。
- DNS_SK: ${{ secrets.DNS_SK }}:使用GitHub的密钥设置阿里云DNS密钥。
- DEBIAN_FRONTEND: noninteractive:将Debian前端设置为非交互模式,这在自动化脚本中很有用,可防止交互提示。
- HELM_EXPERIMENTAL_OCI: 1:启用Helm中的实验性OCI(Open Container Initiative)支持,允许Helm与OCI镜像一起使用。
如需在自己的账号运行这个Demo,只需要将 https://github.com/open-source-solution-design/ObservabilityPlatform.git 这个仓库Fork 到你自己的Github账号下,同时在
Settings -> Actions secrets and variables: 添加流水线需要定义的 secrets 变量
Server 相关 secrets 变量
- HELM_REPO_USER Artifact 仓库认证用户名
- HELM_REPO_REGISTRY Artifact 仓库认证地址
- HELM_REPO_PASSWORD Artifact 仓库认证密码
- HOST_USER 部署K3S的主机OS登陆用户名
- HOST_IP 部署K3S的主机IP地址
- HOST_DOMAIN 部署K3S的主机域名
- SSH_PRIVATE_KEY 访问K3S的主机的SSH 私钥
- DNS_AK 阿里云DNS 服务 AK (用于自动签发SSL证书和更新解析记录,发布ingress )
- DNS_SK 阿里云DNS 服务 SK (用于自动签发SSL证书和更新解析记录,发布ingress )
客户端相关 secrets 变量
- APP_HOST_USER 部署APP集群的master 主机OS登陆用户名
- APP_HOST_IP 部署APP集群的master 主机IP地址
- APP_HOST_DOMAIN 部署APP集群的master 主机IP域名
一切就绪后,就可以看到。在这个CI工作流中,自动的完成镜像并推送到自定义的仓库,打包,并完成K3S集群的初始化,以及完成APP部署到K3S集群中。
部署后配置
服务端配置
- 数据源配置 以 https://grafana.onwalk.net 为例, 以 admin 身份登录,data sources -> Add new data sources 可以根据需要,选择对应数据源类型接入
- 导入自定义 Dashboard, 上传 Dashboard Json 模版文件,选择对应数据源 ObservabilityPlatform 仓库提供了几个来自社区供参考的面板 https://github.com/open-source-solution-design/ObservabilityPlatform/blob/main/charts/server/example/dashboard/ Grafana 社区提供很多的面板,可以根据需要选择,
- 配置多集群中 deepflow-agent 配置,需要首先在Server端,利用 deepflow-ctl domain create 获取一个 K8sClusterID:
unset CLUSTER\_NAME
CLUSTER\_NAME="k8s-1" # FIXME: K8s cluster name
cat << EOF | deepflow-ctl domain create -f -
name: $CLUSTER\_NAME
type: kubernetes
EOF
deepflow-ctl domain list $CLUSTER\_NAME # Get K8sClusterID- 采集端
配置更多集群接入,执行步骤2,记录 K8sClusterID 和 deepflowserverip 写入 playbook/init_observability-agent 然后执行 .github/workflows/setup-agent.yaml 流水线
demo 示例
日志查询

Node 节点资源状态
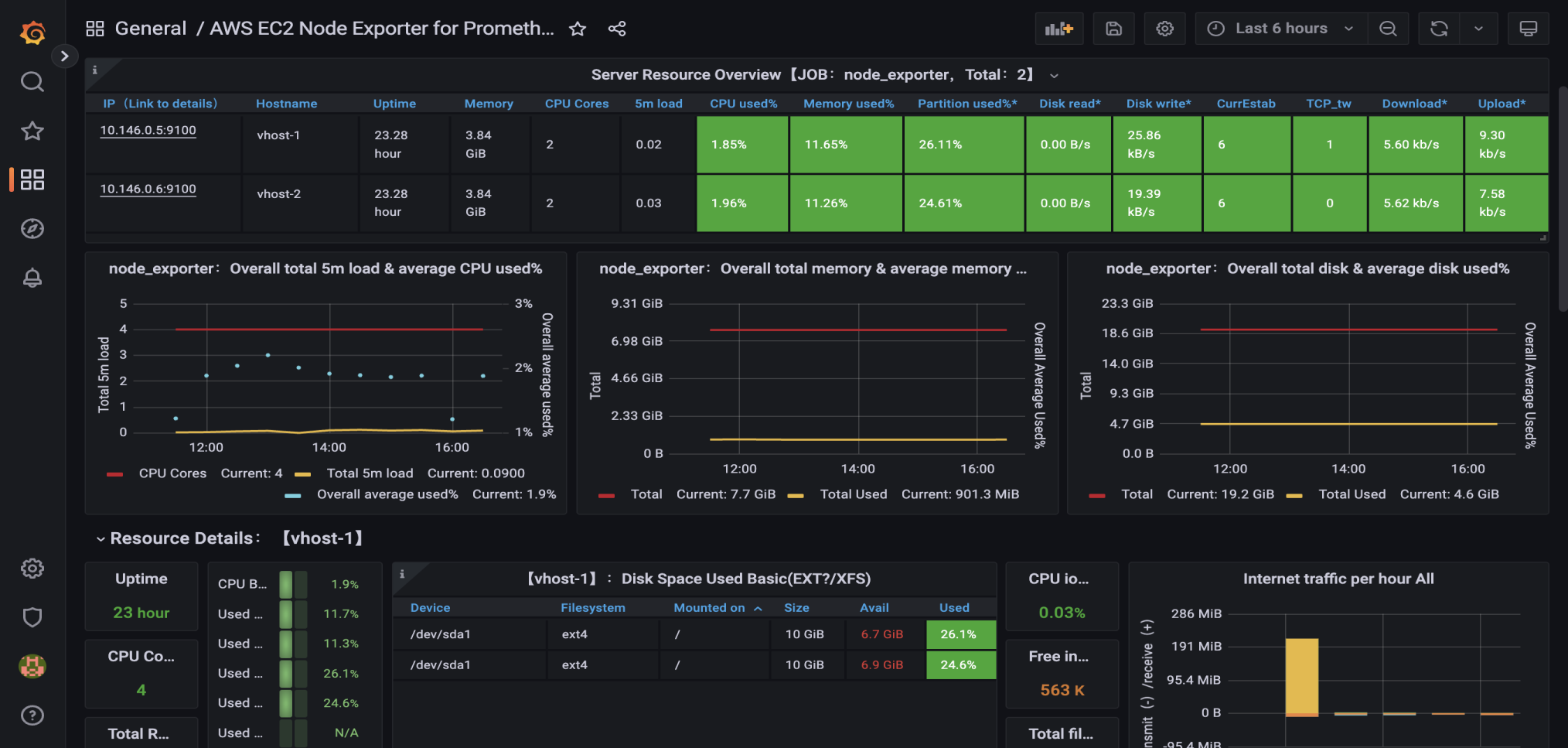
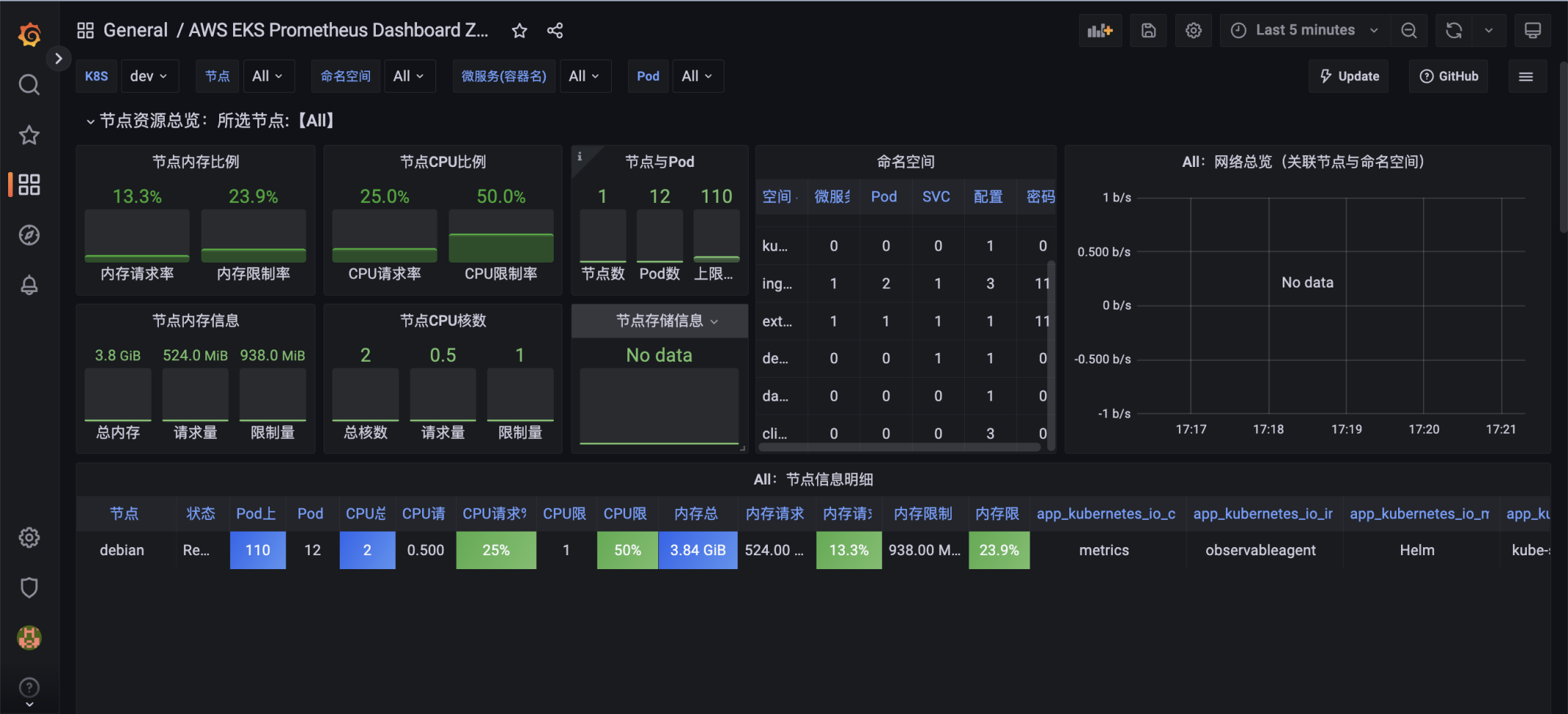
集群应用资源状态
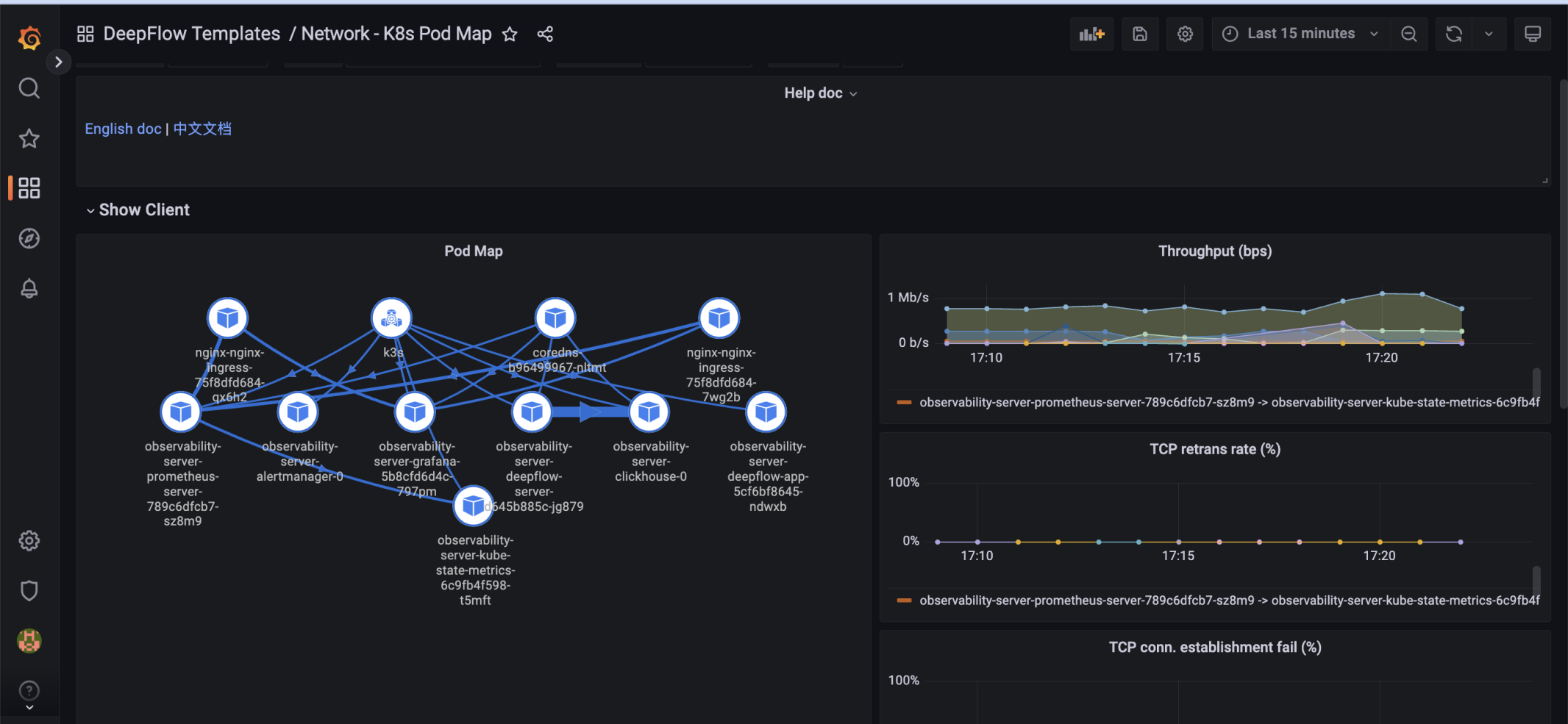
资源拓扑图
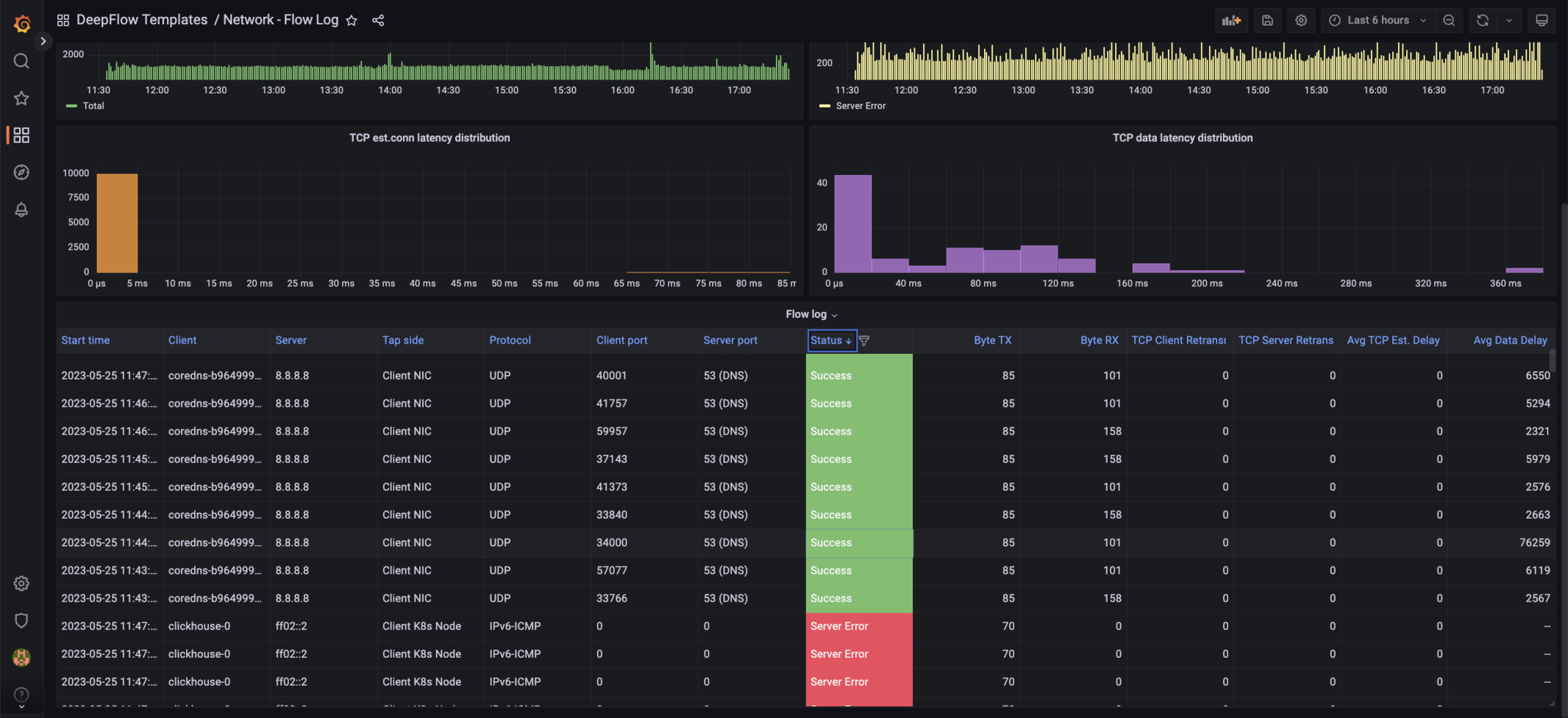
网络性能观测
服务监可用性监控

参考部分
API Endpoint
name | URI |
|---|---|
querying(promql, logql, tempo) | http://data-gateway.<domian> |
metrics_query | https://prometheus.<domian>/api/v1/query |
metrics_remote_write | https://prometheus.<domian>/api/v1/remote/write |
logql_remote_write | https://data-gateway.<domian>/loki/api/v1/push |
traces_tempo_push | https://data-gateway.<domian>/tempo/api/push |
traces_zipkin_push | https://data-gateway.<domian>/api/v2/spans |
traces_oltp_push | https://data-gateway.<domian>/v1/traces |
致谢
- 开源社区:没有开源社区的共享,是无法独立完成一个复杂的技术方案。感谢开源社区的所有贡献者,他们的辛勤工作为我们提供了宝贵的资源和知识。
- Prometheus:Prometheus 是领先的开源监控系统。我们使用 Prometheus 来收集和存储可观察性数据。
- Grafana:Grafana 是领先的开源可视化工具。我们使用 Grafana 来可视化可观察性数据。
- AlertManager:AlertManager 是领先的开源告警系统。我们使用 AlertManager 来发送可观察性数据告警。
- DeepFlow:DeepFlow 是云杉科技开源的基于eppf 应用可观察性分析软件。
- GCP Cloud: 没有 Google 慷慨的300$ 额度免费测试资源,无法完成方案验证
- 腾讯开发者平台:腾讯开发者平台为我们提供了分享平台,感谢腾讯开发者平台为我们提供的支持。
我正在参与2023腾讯技术创作特训营第三期有奖征文,组队打卡瓜分大奖!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。