MongoDB入门(四)
原创MongoDB入门(四)
原创
8. MongoDB 聚合
将记录按条件分组以后,然后再进行一系列操作,例如,求最大值、最小值、平均值,求和等操作。聚合操作还能够对记录进行复杂的操作,主要用于数理统计和数据挖掘。
aggregate() 方法的基本语法格式如下所示:
> db.COLLECTION_NAME.aggregate([
{<stage>},
...
])MongoDB 提供了非常强大的聚合操作,有三种方式:
- 聚合管道(Aggregation Pipeline)
- 单目的聚合操作(Single Purpose Aggregation Operation)
- MapReduce 编程模型
在本篇中,重点讲解聚合管道和单目的聚合操作,MapReduce 编程模型会在后续的文章中讲解。
8.1 聚合管道
聚合管道是 MongoDB 2.2版本引入的新功能。它由阶段(Stage)组成,文档在一个阶段处理完毕后,聚合管道会把处理结果传到下一个阶段。
聚合管道功能:
- 对文档进行过滤,查询出符合条件的文档
- 对文档进行变换,改变文档的输出形式
每个阶段用阶段操作符(Stage Operators)定义,在每个阶段操作符中可以用表达式操作符(Expression Operators)计算总和、平均值、拼接分割字符串等相关操作,直到每个阶段进行完成,最终返回结果,返回的结果可以直接输出,也可以存储到集合中。
MongoDB 中使用 db.COLLECTION_NAME.aggregate([{<stage>},...]) 方法来构建和使用聚合管道。
先看下官网给的实例,感受一下聚合管道的用法。
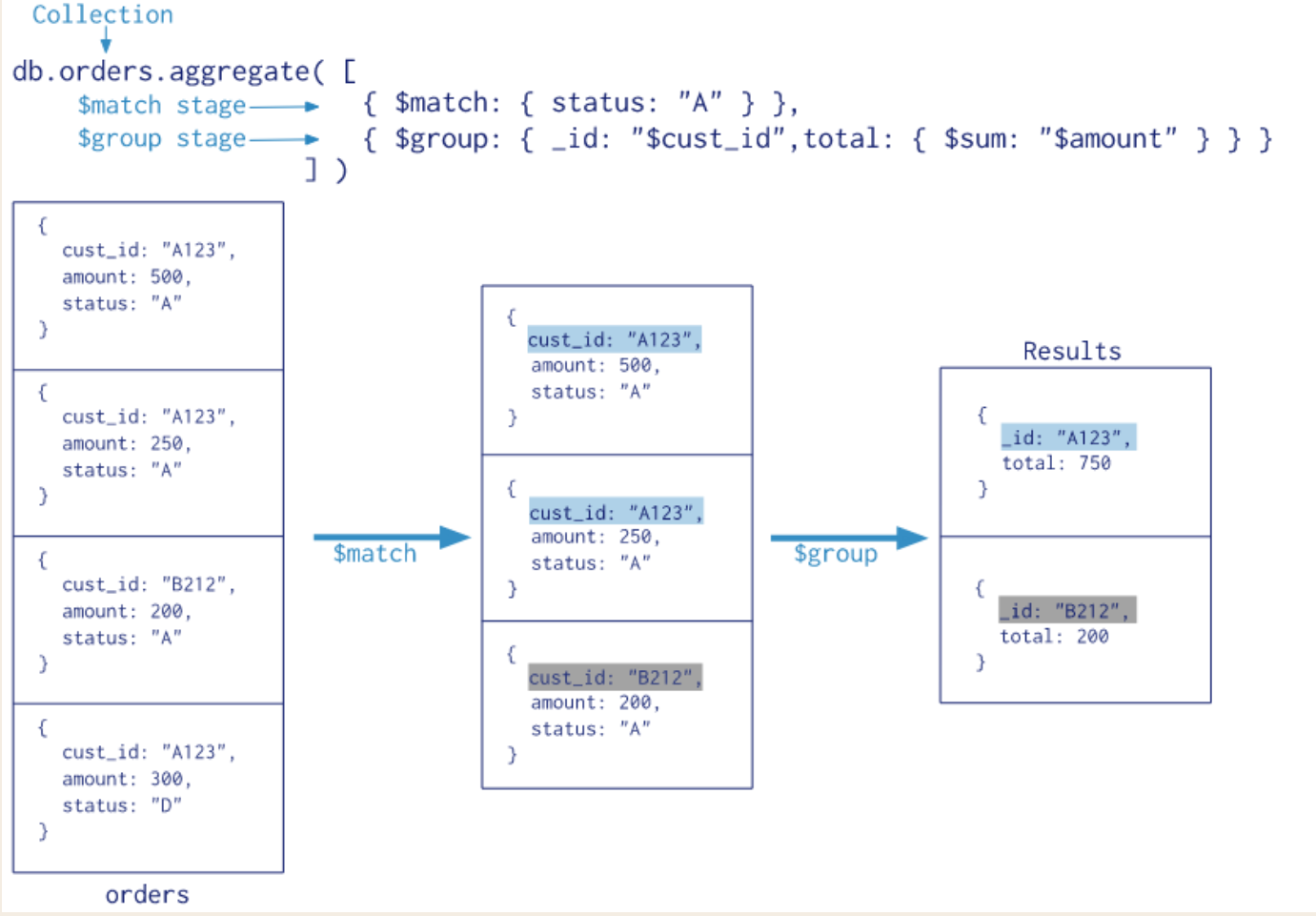
实例中,$match 用于获取 status = "A" 的记录,然后将符合条件的记录送到下一阶段 $group中根据cust_id进行分组并对amount进行求和计算,最后返回 Results。
其中,match、group 都是阶段操作符,而阶段 group 中用到的 sum 是表达式操作符。
8.1.1 阶段操作符
8.1.1 阶段操作符
使用阶段操作符之前,我们先看一下 article 集合中的文档列表,也就是范例中用到的数据。
>db.article.find().pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}$project:修改文档的结构,可以用来重命名、增加或删除文档中的字段。
示例1:
只返回文档中 title 和 author 字段
>db.article.aggregate([
{$project:{_id:0, title:1, author:1 }}
])
{ "title": "MongoDB Aggregate", "author": "liruihuan" },
{ "title": "MongoDB Index", "author": "liruihuan" },
{ "title": "MongoDB Query", "author": "eryueyang" }因为字段 id 是默认显示的,这里必须用 _id:0 把字段id过滤掉。
示例2 :
把文档中 pages 字段的值都增加10。并重命名成 newPages 字段。
>db.article.aggregate(
[
{
$project:{
_id:0,
title:1,
author:1,
newPages: {$add:["$Pages",10]}
}
},
]
)
{ "title": "MongoDB Aggregate", "author": "liruihuan", "newPages": 15 },
{ "title": "MongoDB Index", "author": "liruihuan", "newPages": 13 },
{ "title": "MongoDB Query", "author": "eryueyang", "newPages": 18 }其中,$add 是 加 的意思,是算术类型表达式操作符,具体表达式操作符,下面会讲到。
$match:用于过滤文档。用法类似于 find() 方法中的参数。 范例 查询出文档中 pages 字段的值大于等于5的数据。
>db.article.aggregate(
[
{
$match: {"pages": {$gte: 5}}
}
]
).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}注:
- 在 match 中不能使用 where 表达式操作符
- 如果 $match 位于管道的第一个阶段,可以利用索引来提高查询效率
- match 中使用 text 操作符的话,只能位于管道的第一阶段
- $match 尽量出现在管道的最前面,过滤出需要的数据,在后续的阶段中可以提高效率。
$group:将集合中的文档分组,可用于统计结果。
范例
从 article 中得到每个 author 的文章数,并输入 author 和对应的文章数。
db.article.aggregate(
[
{
$group:{_id:'$author',total:{$sum:1}}
}
]
)
{"_id" : "eryueyang", "total" : 1}
{"_id" : "liruihuan", "total" : 2}$sort:将集合中的文档进行排序。
范例
让集合 article 以 pages 升序排列
>db.article.aggregate(
[
{
$sort: {"pages": 1}
}
]
).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}如果以降序排列,则设置成 "pages": -1
$limit:限制返回的文档数量。
范例
返回集合 article 中前两条文档
>db.article.aggregate(
[
{
$limit: 2
}
]
).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": ['Mongodb', 'Database', 'Query'],
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
}$skip:跳过指定数量的文档,并返回余下的文档。
范例
跳过集合 article 中一条文档,输出剩下的文档
>db.article.aggregate([
{$skip: 1}
]).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7571")
"title": "MongoDB Index",
"author": "liruihuan",
"tags": ['Mongodb', 'Index', 'Query'],
"pages": 3,
"time" : ISODate("2017-04-09T11:43:39.236Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7572")
"title": "MongoDB Query",
"author": "eryueyang",
"tags": ['Mongodb', 'Query'],
"pages": 8,
"time" : ISODate("2017-04-09T11:44:56.276Z")
}$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
范例
把集合 article 中 title="MongoDB Aggregate" 的 tags 字段拆分
>db.article.aggregate(
[
{$match: {"title": "MongoDB Aggregate"}},
{$unwind: "$tags"},
]
).pretty()
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": "Mongodb",
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": "Database",
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
},
{
"_id": ObjectId("58e1d2f0bb1bbc3245fa7570")
"title": "MongoDB Aggregate",
"author": "liruihuan",
"tags": "Query",
"pages": 5,
"time" : ISODate("2017-04-09T11:42:39.736Z")
}注:
- $unwind 参数数组字段为空或不存在时,待处理的文档将会被忽略,该文档将不会有任何输出
- $unwind 参数不是一个数组类型时,将会抛出异常
- $unwind 所作的修改,只用于输出,不能改变原文档
8.1.2 表达式操作符
表达式操作符有很多操作类型,其中最常用的有布尔管道聚合操作、集合操作、比较聚合操作、算术聚合操作、字符串聚合操作、数组聚合操作、日期聚合操作、条件聚合操作、数据类型聚合操作等。
每种类型都有很多用法,这里就不一一举例了。
布尔管道聚合操作(Boolean Aggregation Operators)
名称 | 说明 |
|---|---|
$and | 仅当其所有表达式的计算结果为true时,才返回true。接受任意数量的参数表达式。 |
$or | 当其任何表达式的计算结果为true时,返回true。接受任意数量的参数表达式。 |
$not | 返回与其参数表达式相反的布尔值。接受单个参数表达式。 |
范例
假如有一个集合 mycol
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 }
{ "_id" : 2, "item" : "abc2", description: "product 2", qty: 200 }
{ "_id" : 3, "item" : "xyz1", description: "product 3", qty: 250 }
{ "_id" : 4, "item" : "VWZ1", description: "product 4", qty: 300 }
{ "_id" : 5, "item" : "VWZ2", description: "product 5", qty: 180 }确定 qty 是否大于250或者小于200
db.mycol.aggregation(
[
{
$project :
{
item : 1,
result :
{
$or:
[
{$gt:["$qty",250]},
{$lt:["$qty",200]}
]
}
}
}
]
)
{ "_id" : 1, "item" : "abc1", "result" : true }
{ "_id" : 2, "item" : "abc2", "result" : false }
{ "_id" : 3, "item" : "xyz1", "result" : false }
{ "_id" : 4, "item" : "VWZ1", "result" : true }
{ "_id" : 5, "item" : "VWZ2", "result" : true }集合操作(Set Operators)
用于集合操作,求集合的并集、交集、差集运算。
名称 | 说明 |
|---|---|
$setEquals | 相等集 如果输入集具有相同的不同元素,则返回'true'。接受两个或多个参数表达式。 |
$setIntersection | 交集 返回一个集合,其中的元素出现在所有输入集中。接受任意数量的参数表达式。 |
$setUnion | 并集 返回包含在任意输入集中出现的元素的集合。接受任意数量的参数表达式。 |
$setDifference | 差集 Returns a set with elements that appear in the first set but not in the second set; i.e. performs a relative complement of the second set relative to the first. Accepts exactly two argument expressions. |
$setIsSubset | 包含 如果第一个集合的所有元素都出现在第二个集合中,包括当第一个集合等于第二个集合时,返回'true';i、 不是严格的子集。只接受两个参数表达式。 |
$anyElementTrue | 如果集合的任意元素的值为true,则返回true;否则,返回'false'。接受单个参数表达式。 |
$allElementsTrue | 如果集合的没有元素的计算结果为'false',则返回'true',否则返回'false'。接受单个参数表达式。 |
范例
假如有一个集合 mycol
{ "_id" : 1, "A" : [ "red", "blue" ], "B" : [ "red", "blue" ] }
{ "_id" : 2, "A" : [ "red", "blue" ], "B" : [ "blue", "red", "blue" ] }
{ "_id" : 3, "A" : [ "red", "blue" ], "B" : [ "red", "blue", "green" ] }
{ "_id" : 4, "A" : [ "red", "blue" ], "B" : [ "green", "red" ] }
{ "_id" : 5, "A" : [ "red", "blue" ], "B" : [ ] }
{ "_id" : 6, "A" : [ "red", "blue" ], "B" : [ [ "red" ], [ "blue" ] ] }
{ "_id" : 7, "A" : [ "red", "blue" ], "B" : [ [ "red", "blue" ] ] }
{ "_id" : 8, "A" : [ ], "B" : [ ] }
{ "_id" : 9, "A" : [ ], "B" : [ "red" ] }求出集合 mycol 中 A 和 B 的交集
db.mycol.aggregate(
[
{ $project: { A:1, B: 1, allValues: { $setUnion: [ "$A", "$B" ] }, _id: 0 } }
]
)
{ "A": [ "red", "blue" ], "B": [ "red", "blue" ], "allValues": [ "blue", "red" ] }
{ "A": [ "red", "blue" ], "B": [ "blue", "red", "blue" ], "allValues": [ "blue", "red" ] }
{ "A": [ "red", "blue" ], "B": [ "red", "blue", "green" ], "allValues": [ "blue", "red", "green" ] }
{ "A": [ "red", "blue" ], "B": [ "green", "red" ], "allValues": [ "blue", "red", "green" ] }
{ "A": [ "red", "blue" ], "B": [ ], "allValues": [ "blue", "red" ] }
{ "A": [ "red", "blue" ], "B": [ [ "red" ], [ "blue" ] ], "allValues": [ "blue", "red", [ "red" ], [ "blue" ] ] }
{ "A": [ "red", "blue" ], "B": [ [ "red", "blue" ] ], "allValues": [ "blue", "red", [ "red", "blue" ] ] }
{ "A": [ ], "B": [ ], "allValues": [ ] }
{ "A": [ ], "B": [ "red" ], "allValues": [ "red" ] }比较聚合操作(Comparison Aggregation Operators)
名称 | 说明 |
|---|---|
$cmp | 比较 如果两个值相等,则返回“0”;如果第一个值大于第二个值,则返回“1”;如果第一个值小于第二个值,则返回“1”。 |
$eq | 比较 如果值相等,则返回'true'。 |
$gt | 大于 如果第一个值大于第二个值,则返回'true'。 |
$gte | 大于等于 |
$lt | 小于 如果第一个值小于于第二个值,则返回'true'。 |
$lte | 小于等于 |
$ne | 不等于 |
算术聚合操作(Arithmetic Aggregation Operators)
名称 | 说明 |
|---|---|
$abs | 返回数字的绝对值 |
$add | 添加数字以返回总和,或添加数字和日期以返回新日期。 如果添加数字和日期,则将数字视为毫秒。 接受任意数量的参数表达式,但最多一个表达式可以解析为一个日期。 |
$ceil | 向上取整 |
$divide | 返回第一个数除以第二个数的结果。 |
$exp | a的x次方 |
$floor | 向下取整 |
$ln | 计算数字的自然对数。 |
$log | 计算指定基数中某个数字的对数。 |
$log10 | 计算一个数字的对数基数10。 |
$mod | 返回第一个数除以第二个数的余数。 |
$multiply | Multiplies numbers to return the product. Accepts any number of argument expressions. |
$pow | 将数字相乘以返回结果。接受任意数量的参数表达式。 |
$sqrt | 计算平方根。 |
$subtract | 返回从第一个值减去第二个值的结果。 如果这两个值是数字,则返回差值。 如果这两个值是日期,则返回以毫秒为单位的差值。 如果这两个值是日期和毫秒数,则返回结果日期。 接受两个参数表达式。 如果这两个值是日期和数字,请首先指定日期参数,因为从数字中减去日期没有意义。 |
$trunc | 将数字截断为其整数。 |
范例
假如有一个集合 mycol
{ _id: 1, start: 5, ``end``: 8 }
{ _id: 2, start: 4, ``end``: 4 }
{ _id: 3, start: 9, ``end``: 7 }
{ _id: 4, start: 6, ``end``: 7 }求集合 mycol 中 start 减去 end 的绝对值
db.mycol.aggregate(
{
$project: {delta:{ $abs: {$subtract:["$start","$end"]}}}
}
)
{ "_id" : 1, "delta" : 3 }
{ "_id" : 2, "delta" : 0 }
{ "_id" : 3, "delta" : 2 }
{ "_id" : 4, "delta" : 1 }字符串聚合操作(String Aggregation Operators)
名称 | 说明 |
|---|---|
$concat | 连接任意数量的字符串。 |
$indexOfBytes | 在字符串中搜索子字符串的出现,并返回第一次出现的UTF-8字节索引。如果未找到子字符串,则返回“-1”。 |
$indexOfCP | 在字符串中搜索子字符串的出现,并返回第一次出现的UTF-8代码点索引。如果未找到子字符串,则返回“-1”。 |
$split | 根据分隔符将字符串拆分为子字符串。返回子字符串数组。如果在字符串中找不到分隔符,则返回包含原始字符串的数组。 |
$strLenBytes | 返回字符串中UTF-8编码的字节数。 |
$strLenCP | 返回字符串中UTF-8代码点的数目。 |
$strcasecmp | 执行不区分大小写的字符串比较并返回:如果两个字符串相等,则返回“0”;如果第一个字符串大于第二个字符串,则返回“1”;如果第一个字符串小于第二个字符串,则返回“1”。 |
$substrBytes | 返回字符串的子字符串。从字符串中指定的UTF-8字节索引(从零开始)处的字符开始,并持续指定的字节数。 |
$substrCP | 返回字符串的子字符串。从字符串中指定的UTF-8代码点(CP)索引(从零开始)处的字符开始,并按指定的代码点数继续。 |
$toLower | 将字符串转换为小写。接受单个参数表达式。 |
$toUpper | 将字符串转换为大写。接受单个参数表达式。 |
范例
假如有一个集合 mycol
{ "_id" : 1, "city" : "Berkeley, CA", "qty" : 648 }
{ "_id" : 2, "city" : "Bend, OR", "qty" : 491 }
{ "_id" : 3, "city" : "Kensington, CA", "qty" : 233 }
{ "_id" : 4, "city" : "Eugene, OR", "qty" : 842 }
{ "_id" : 5, "city" : "Reno, NV", "qty" : 655 }
{ "_id" : 6, "city" : "Portland, OR", "qty" : 408 }
{ "_id" : 7, "city" : "Sacramento, CA", "qty" : 574 }以 ',' 分割集合 mycol 中字符串city的值,
用 $unwind 拆分成多个文档,
匹配出城市名称只有两个字母的城市,
并求和各个城市中 qty 的值,
最后以降序排序。
db.mycol.aggregate([
{ $project : { city_state : { $split: ["$city", ", "] }, qty : 1 } },
{ $unwind : "$city_state" },
{ $match : { city_state : /[A-Z]{2}/ } },
{ $group : { _id: { "state" : "$city_state" }, total_qty : { "$sum" : "$qty" } } },
{ $sort : { total_qty : -1 } }
])
{ "_id" : { "state" : "OR" }, "total_qty" : 1741 }
{ "_id" : { "state" : "CA" }, "total_qty" : 1455 }
{ "_id" : { "state" : "NV" }, "total_qty" : 655 }数组聚合操作(Array Aggregation Operators)
名称 | 说明 |
|---|---|
$arrayElemAt | 返回指定数组索引处的元素。 |
$concatArrays | 连接数组以返回连接的数组。 |
$filter | 选择数组的子集以返回仅包含与筛选条件匹配的元素的数组。 |
$indexOfArray | 在数组中搜索指定值的出现,并返回第一次出现的数组索引。如果未找到子字符串,则返回“-1”。 |
$isArray | 确定操作数是否为数组。返回一个布尔值。 |
$range | 根据用户定义的输入输出包含整数序列的数组。 |
$reverseArray | 返回元素顺序相反的数组。 |
$reduce | 将表达式应用于数组中的每个元素,并将它们组合为单个值。 |
$size | 返回数组中的元素数。接受单个表达式作为参数。 |
$slice | 返回数组的子集。 |
$zip | 将两个列表合并在一起。 |
$in | 返回一个布尔值,指示指定值是否在数组中。 |
范例
假如有一个集合 mycol
{ "_id" : 1, "name" : "dave123", favorites: [ "chocolate", "cake", "butter", "apples" ] }
{ "_id" : 2, "name" : "li", favorites: [ "apples", "pudding", "pie" ] }
{ "_id" : 3, "name" : "ahn", favorites: [ "pears", "pecans", "chocolate", "cherries" ] }
{ "_id" : 4, "name" : "ty", favorites: [ "ice cream" ] }求出集合 mycol 中 favorites 的第一项和最后一项
db.mycol.aggregate([
{$project:{
name :1;
first:{$arrayElemAt:["$favorites",0]},
last: {$arrayElemAt:["$favorites",-1]}
}}
])
{ "_id" : 1, "name" : "dave123", "first" : "chocolate", "last" : "apples" }
{ "_id" : 2, "name" : "li", "first" : "apples", "last" : "pie" }
{ "_id" : 3, "name" : "ahn", "first" : "pears", "last" : "cherries" }
{ "_id" : 4, "name" : "ty", "first" : "ice cream", "last" : "ice cream" }日期聚合操作(Date Aggregation Operators)
名称 | 说明 |
|---|---|
$dayOfYear | 以介于1和366(闰年)之间的数字返回日期的日期。 |
$dayOfMonth | 以1到31之间的数字返回日期的月份日期。 |
$dayOfWeek | 以1(星期日)到7(星期六)之间的数字形式返回日期的星期几。 |
$year | 以数字形式返回日期的年份(例如2014年)。 |
$month | 将日期的月份返回为介于1(一月)和12(十二月)之间的数字。 |
$week | 将日期的周数作为介于0(一年中第一个星期日之前的部分周)和53(闰年)之间的数字返回。 |
$hour | 以0到23之间的数字返回日期的小时数。 |
$minute | 以0到59之间的数字形式返回日期的分钟。 |
$second | 以0到60之间的数字(闰秒)返回日期的秒数。 |
$millisecond | 以介于0和999之间的数字形式返回日期的毫秒数。 |
$dateToString | 以格式化字符串的形式返回日期。 |
$isoDayOfWeek | 返回ISO 8601格式的工作日编号,范围从“1”(星期一)到“7”(星期日)。 |
$isoWeek | 返回ISO 8601格式的周数,范围从'1'到'53'。周数从'1'开始,以包含一年中第一个星期四的一周(周一到周日)为单位。 |
$isoWeekYear | 返回ISO 8601格式的年份号。一年从第一周的星期一开始(ISO 8601),到最后一周的星期日结束(ISO 8601)。 |
范例
假如有一个集合 mycol
{
"_id" : 1,
"item" : "abc",
"price" : 10,
"quantity" : 2,
"date" : ISODate("2017-01-01T08:15:39.736Z")
}得到集合 mycol 中 date 字段的相关日期值
db.mycol.aggregate(
``[
``{
``$project:
``{
``year``: { $``year``: ``"$date"` `},
``month``: { $``month``: ``"$date"` `},
``day``: { $dayOfMonth: ``"$date"` `},
``hour``: { $``hour``: ``"$date"` `},
``minutes: { $``minute``: ``"$date"` `},
``seconds: { $``second``: ``"$date"` `},
``milliseconds: { $millisecond: ``"$date"` `},
``dayOfYear: { $dayOfYear: ``"$date"` `},
``dayOfWeek: { $dayOfWeek: ``"$date"` `},
``week: { $week: ``"$date"` `}
``}
``}
``]
)
{
``"_id"` `: 1,
``"year"` `: 2017,
``"month"` `: 1,
``"day"` `: 1,
``"hour"` `: 8,
``"minutes"` `: 15,
``"seconds"` `: 39,
``"milliseconds"` `: 736,
``"dayOfYear"` `: 1,
``"dayOfWeek"` `: 1,
``"week"` `: 0
}条件聚合操作(Conditional Aggregation Operators)
名称 | 说明 |
|---|---|
$cond | 三元运算符,对一个表达式求值,并根据结果返回其他两个表达式之一的值。接受有序列表中的三个表达式或三个命名参数。 |
$ifNull | 返回第一个表达式的非空结果,如果第一个表达式的结果为空,则返回第二个表达式的结果。Null结果包含未定义值或缺少字段的实例。接受两个表达式作为参数。第二个表达式的结果可以为null。 |
$switch | 计算一系列大小写表达式。当它找到一个计算结果为“true”的表达式时,“$switch”执行指定的表达式并中断控制流。 |
范例
假如有一个集合 mycol
{ "_id" : 1, "item" : "abc1", qty: 300 }
{ "_id" : 2, "item" : "abc2", qty: 200 }
{ "_id" : 3, "item" : "xyz1", qty: 250 }如果集合 mycol 中 qty 字段值大于等于250,则返回30,否则返回20
db.mycol.aggregate(
[
{
$project:
{
item: 1,
discount:
{
$cond: { if: { $gte: [ "$qty", 250 ] }, then: 30, else: 20 }
}
}
}
]
)
{ "_id" : 1, "item" : "abc1", "discount" : 30 }
{ "_id" : 2, "item" : "abc2", "discount" : 20 }
{ "_id" : 3, "item" : "xyz1", "discount" : 30 }数据类型聚合操作(Data Type Aggregation Operators)
名称 | 说明 |
|---|---|
$type | 返回字段的BSON数据类型。 |
范例
假如有一个集合 mycol
{ _id: 0, a : 8 }
{ _id: 1, a : [ 41.63, 88.19 ] }
{ _id: 2, a : { a : "apple", b : "banana", c: "carrot" } }
{ _id: 3, a : "caribou" }
{ _id: 4, a : NumberLong(71) }
{ _id: 5 }获取文档中 a 字段的数据类型
db.mycol.aggregate([{
$project: {
a : { $type: "$a" }
}
}])
{ _id: 0, "a" : "double" }
{ _id: 1, "a" : "array" }
{ _id: 2, "a" : "object" }
{ _id: 3, "a" : "string" }
{ _id: 4, "a" : "long" }
{ _id: 5, "a" : "missing" }8.1.3 聚合管道优化
默认情况下,整个集合作为聚合管道的输入,为了提高处理数据的效率,可以使用一下策略:
- 将 match 和 sort 放到管道的前面,可以给集合建立索引,来提高处理数据的效率。
- 可以用 match、limit、$skip 对文档进行提前过滤,以减少后续处理文档的数量。
当聚合管道执行命令时,MongoDB 也会对各个阶段自动进行优化,主要包括以下几个情况:
- sort + match 顺序优化 如果 match 出现在 sort 之后,优化器会自动把 match 放到 sort 前面
- skip + limit 顺序优化 如果 skip 在 limit 之后,优化器会把 limit 移动到 skip 的前面,移动后 limit的值等于原来的值加上 skip 的值。 例如:移动前:{skip: 10, limit: 5},移动后:{limit: 15, skip: 10}
8.1.4 聚合管道使用限制
对聚合管道的限制主要是对 返回结果大小 和 内存 的限制。
返回结果大小
聚合结果返回的是一个文档,不能超过 16M,从 MongoDB 2.6版本以后,返回的结果可以是一个游标或者存储到集合中,返回的结果不受 16M 的限制。
内存
聚合管道的每个阶段最多只能用 100M 的内存,如果超过100M,会报错,如果需要处理大数据,可以使用 allowDiskUse 选项,存储到磁盘上。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。