【腾讯云云上实验室】用向量数据库在金融信数据库分析中的实战运用
原创【腾讯云云上实验室】用向量数据库在金融信数据库分析中的实战运用
原创
一、前言
这篇文章将带领读者探索数据库的多样化解决方案及其演进历程,特别关注向量数据库的重要性和在实际项目中的应用。
通过深入剖析腾讯云向量数据库及其在金融信用数据库分析中的实战运用,为读者提供全面而实用的指南,帮助他们理解、应用和掌握这一技术领域的关键要点。
二、数据库的分类种类
现代数据库发展呈现多样化趋势,从传统的关系型和NoSQL数据库到云数据库、云原生数据库和向量数据库,每种都针对特定需求提供定制化解决方案。随着技术不断进步,数据库领域持续创新,满足不断变化的需求。
2.1 演进中的数据库:多样化解决方案应对不断变化的需求
当谈到数据库时,我们可以看到不断的演变和创新。传统自建数据库常常是基于关系型数据库(如MySQL、PostgreSQL)或者NoSQL数据库(比如MongoDB、Cassandra)构建的。这些数据库早期主要用于存储结构化数据,并且在企业和应用程序中广泛使用。
随着云计算的兴起,云数据库应运而生,它们为用户提供了更灵活、可扩展和易管理的解决方案。云数据库包括各种服务,例如Amazon RDS、Google Cloud SQL和Azure Database,它们可以自动化管理和调整数据库的容量和性能,并且提供了高可用性和灾难恢复功能。
而云原生数据库则更专注于在云原生环境下构建和部署的数据库解决方案。这些数据库通常是容器化的,利用了云原生技术(如Kubernetes)来实现更高的弹性、可扩展性和可靠性。
另一个重要的趋势是向量数据库的兴起。这些数据库专注于高维度和复杂数据的处理,比如图像、文本和音频等数据。向量数据库(如Milvus、Faiss)采用向量索引技术,可以更高效地处理和查询大规模的向量数据,这在人工智能、机器学习和大数据分析领域有着广泛的应用。
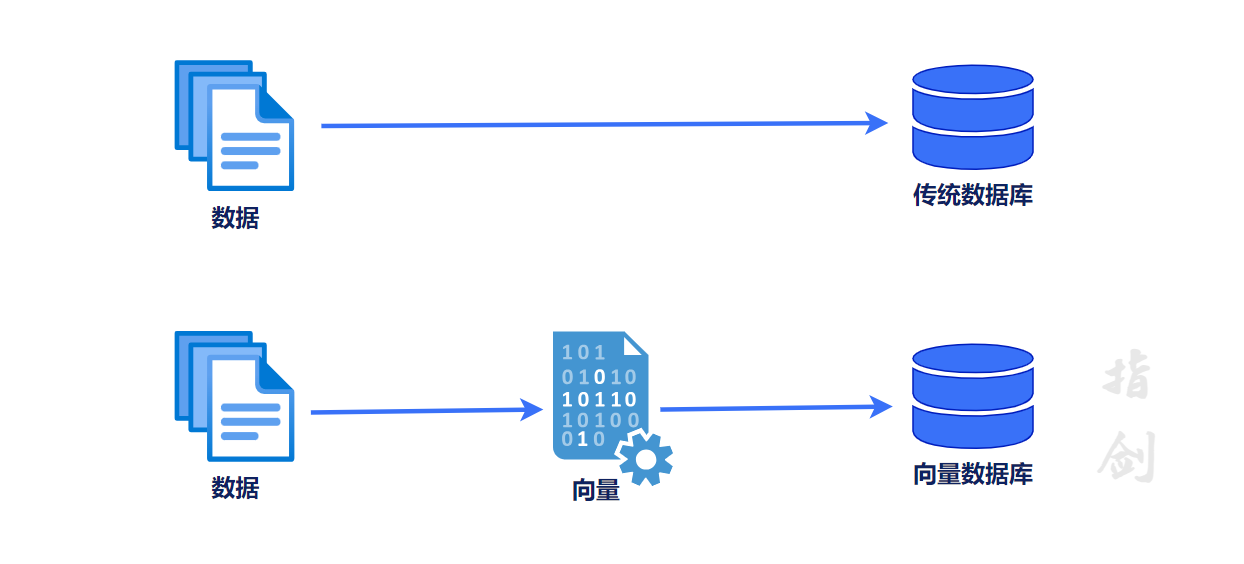
2.2 什么是向量数据库
(需要更加完善一下,更具体一点)
向量数据库是一种专门用于处理高维度向量数据的数据库类型。它们设计用于存储、索引和高效查询包含向量信息的数据集。这些向量可能代表文本、图像、音频等非结构化或半结构化数据,也可能是从机器学习和深度学习模型中提取的特征。
向量数据库通常采用特定的向量索引结构和算法,以便高效地存储和检索向量数据。它们的设计目标是使得在高维空间中进行相似度搜索或者聚类等操作更加高效,并且能够应对大规模的向量数据集。
这些数据库在人工智能、推荐系统、图像识别、自然语言处理等领域有着广泛的应用。它们可以加速相似向量的快速搜索,从而支持诸如推荐算法、相似图片搜索、文本相似度匹配等应用。 Milvus 和 Faiss 是一些知名的向量数据库。
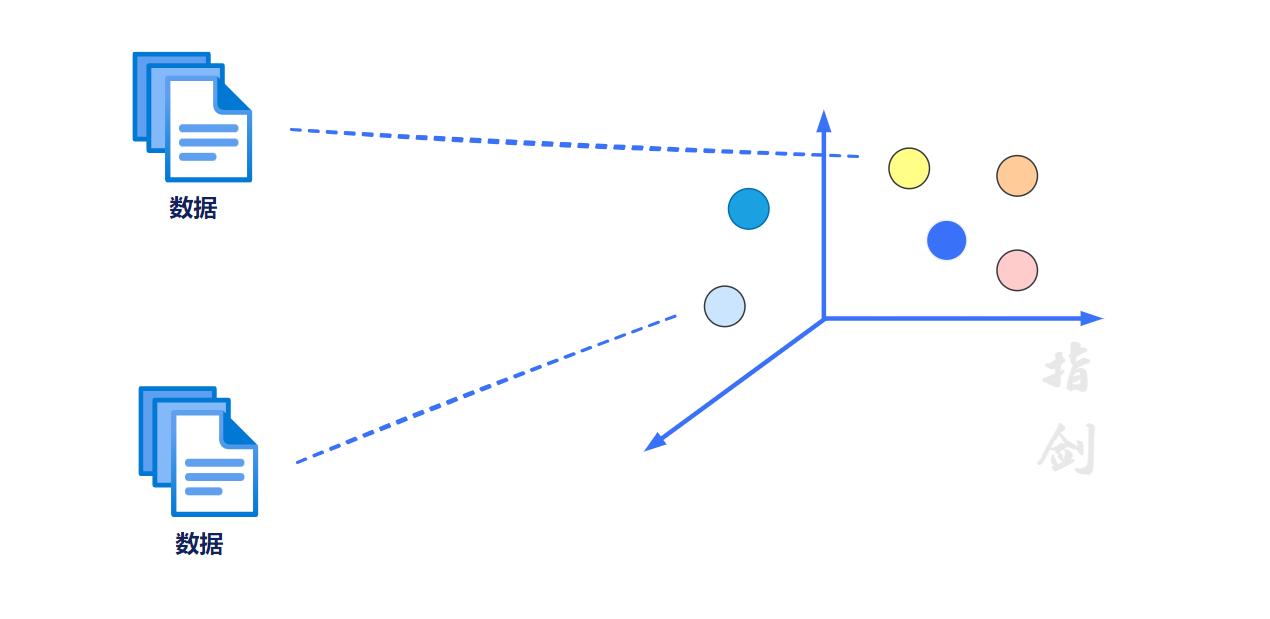
矢量数据库的重要性源于它们处理大规模高维数据集和执行快速相似性搜索的能力。传统的关系数据库由于结构不灵活且缺乏针对相似性搜索而定制的专门索引技术,因此不适合此类数据。
相比之下,矢量数据库采用一系列专门设计的索引结构和算法,旨在有效处理高维数据并实现快速的最近邻搜索。
2.3 为什么向量数据库如此重要呢?
首先,开发人员能够将生成的嵌入向量索引到向量数据库中。这一举措使得通过查询相似向量来找到相关资产成为可能。
此外,向量数据库提供了一种使嵌入模型高效运行的途径。它利用了复杂的查询语言,整合了资源管理、安全控制、可扩展性、容错能力以及高效信息检索等数据库功能,从而提升了应用程序开发的效率。
更重要的是,向量数据库对于开发人员创造独特的应用体验至关重要。举例来说,用户可以通过在智能手机上拍摄照片来搜索相似的图像,这得益于向量数据库的支持。
此外,开发人员能够利用其他类型的机器学习模型,从图像和扫描文档等内容中自动提取元数据。他们可以将这些元数据与向量一同编入索引,以实现对关键字和向量的混合搜索。而通过将语义理解纳入相关性排名中,也能够改善搜索结果。
举个例子,像ChatGPT这样的新模型属于生成式人工智能的创新范畴。这些模型不仅可以生成文本,还能够管理复杂的人类对话。有些模型甚至可以在多种模式下运行,比如有些模型可以根据用户描述的场景生成符合描述内容的图像。
然而,生成式模型容易造成幻觉,这可能会导致聊天机器人向用户传递错误信息。这时,向量数据库就可以弥补生成式人工智能模型的这一缺陷。它为生成式人工智能聊天机器人提供了外部知识库,确保它们提供的信息是可信赖的。
2.4 向量数据库是如何工作的?
我们都大致了解传统数据库是如何工作的——它们将字符串、数字和其他类型的标量数据存储在行和列中。然而,向量数据库则基于向量操作,因此它的优化和查询方式有着很大的不同。
在传统数据库中,通常我们会查询数据库中数值与我们查询条件完全匹配的行。而在向量数据库中,我们会应用相似度度量来寻找与我们查询条件最相似的向量。
向量数据库采用了一系列不同的算法,这些算法都参与了近似最近邻(ANN)搜索。这些算法通过哈希、量化或基于图的搜索来优化搜索过程。
这些算法被组装成一个流水线,能够快速准确地检索查询向量的邻居。由于向量数据库提供的是近似结果,我们需要权衡的主要是准确性和速度。结果越准确,查询速度就越慢。然而,一个良好的系统可以在几乎完美的准确性下提供超快速的搜索。
以下是向量数据库的常见流程:

向量数据库流程
- 索引: 向量数据库使用诸如 PQ、LSH 或 HNSW 等算法对向量进行索引。这一步将向量映射到数据结构,以加速搜索过程。
- 查询: 向量数据库将索引的查询向量与数据集中的索引向量进行比较,通过特定索引使用的相似性度量来确定最近的邻居。
- 后处理: 在某些情况下,向量数据库从数据集中检索最终的最近邻居,并对其进行后处理以返回最终结果。此步骤可能包括使用不同的相似性度量对最近邻居进行重新排序。
三、腾讯云向量数据库
腾讯云向量数据库免费试用:https://curl.qcloud.com/deqmCnLM
腾讯云向量数据库免费试用:https://curl.qcloud.com/deqmCnLM
腾讯云向量数据库免费试用:https://curl.qcloud.com/deqmCnLM
3.1 什么是腾讯云向量数据库
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。
腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
3.2 腾讯云向量数据库优势
腾讯云向量数据库(Tencent Cloud VectorDB)作为一种专门存储和检索向量数据的服务提供给用户, 在高性能、高可用、大规模、低成本、简单易用、稳定可靠等方面体现出显著优势。
为了更加言简意赅,可以直接看我做成的脑图,更加直观的感受腾讯云向量数据库优势:
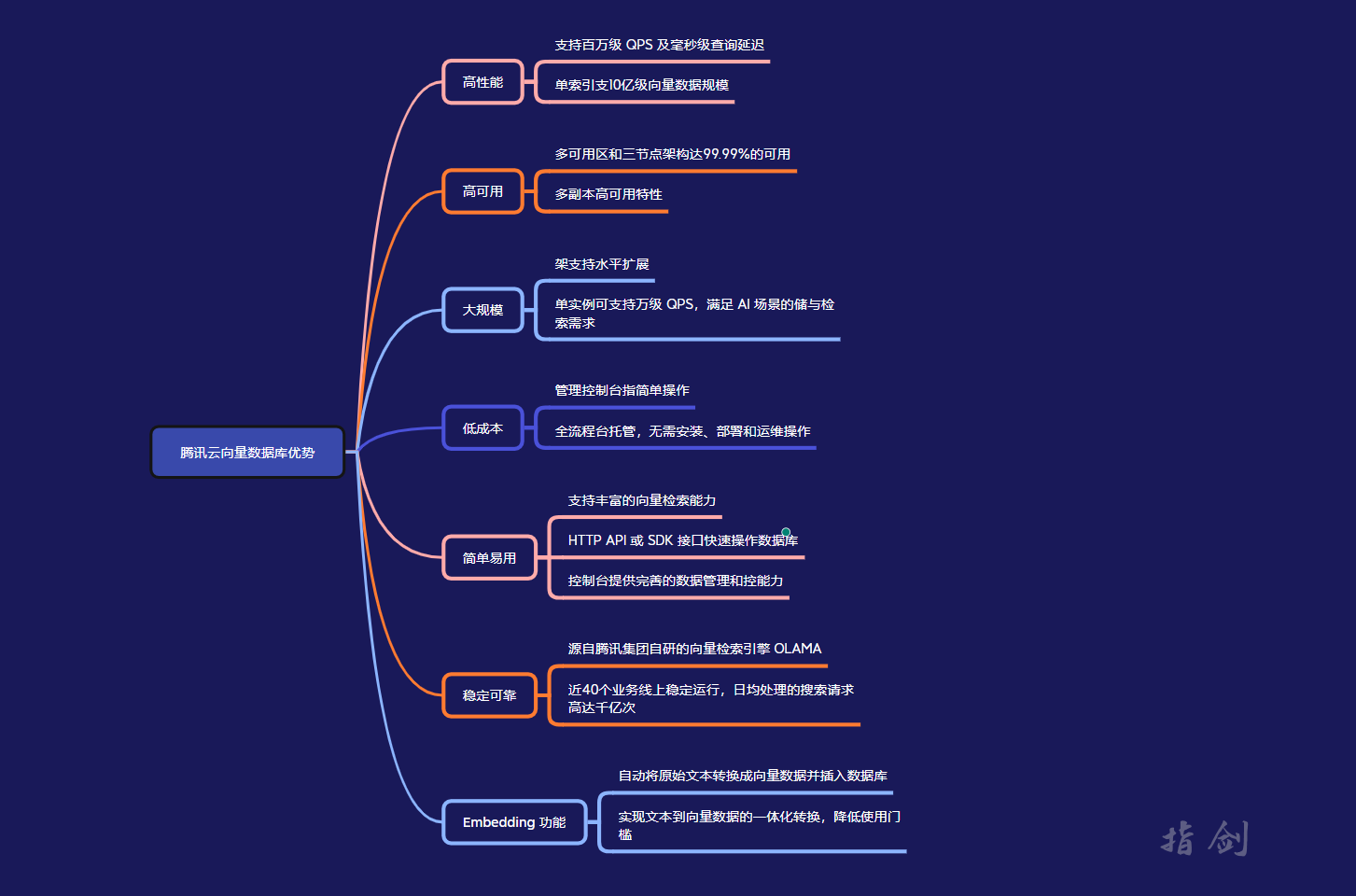
- 高性能 向量数据库单索引支持10亿级向量数据规模,可支持百万级 QPS 及毫秒级查询延迟。
- 高可用 向量数据库提供多副本高可用特性,其多可用区和三节点的架构可用性可达99.99%,显著提高系统的可靠性和容错性,确保数据库在面临节点故障和负载变化等挑战时仍能正常运行。 大规模 向量数据库架构支持水平扩展,单实例可支持百万级 QPS,轻松满足 AI 场景下的向量存储与检索需求。
- 低成本 只需在管理控制台按照指引,简单操作几个步骤,即可快速创建向量数据库实例,全流程平台托管,无需进行任何安装、部署和运维操作,有效减少机器成本、运维成本和人力成本开销。
- 简单易用 支持丰富的向量检索能力。用户通过 HTTP API 或者 SDK 接口即可快速操作数据库,开发效率高。同时控制台提供了完善的数据管理和监控能力,操作简单便捷。
- 稳定可靠 向量数据库源自腾讯集团自研的向量检索引擎 OLAMA,近40个业务线上稳定运行,日均处理的搜索请求高达千亿次,服务连续性、稳定性有保障。
- Embedding 功能 向量数据库的 Embedding 功能会自动将原始文本进行转换,生成对应的向量数据并插入数据库或进行相似性检索,实现了文本到向量数据的一体化转换,减少了用户的操作步骤,极大降低了使用门槛。
3.3 腾讯云向量数据库现阶段落地项目
当下,腾讯云向量数据库成为腾讯企业内外广泛采用的首选。内部各应用产品纷纷依托腾讯云向量数据库,实现高效数据管理与应用,助力业务发展。外部行业也不例外,大量产品纷纷选择腾讯云向量数据库,充分利用其优势。这种趋势呈现出愈发增长的态势,已经成为当今技术发展中的一大亮点,体现了腾讯云向量数据库在业界的卓越地位。
腾讯云向量数据库现阶段腾讯集团内部 40+业务接入, 1600亿次请求/天; 1000+外部用户接入。
四、腾讯云向量数据库实战(金融信用数据库分析)
金融分析案例(重要)
4.1 前期准备
4.1.1 采购腾讯云向量数据库
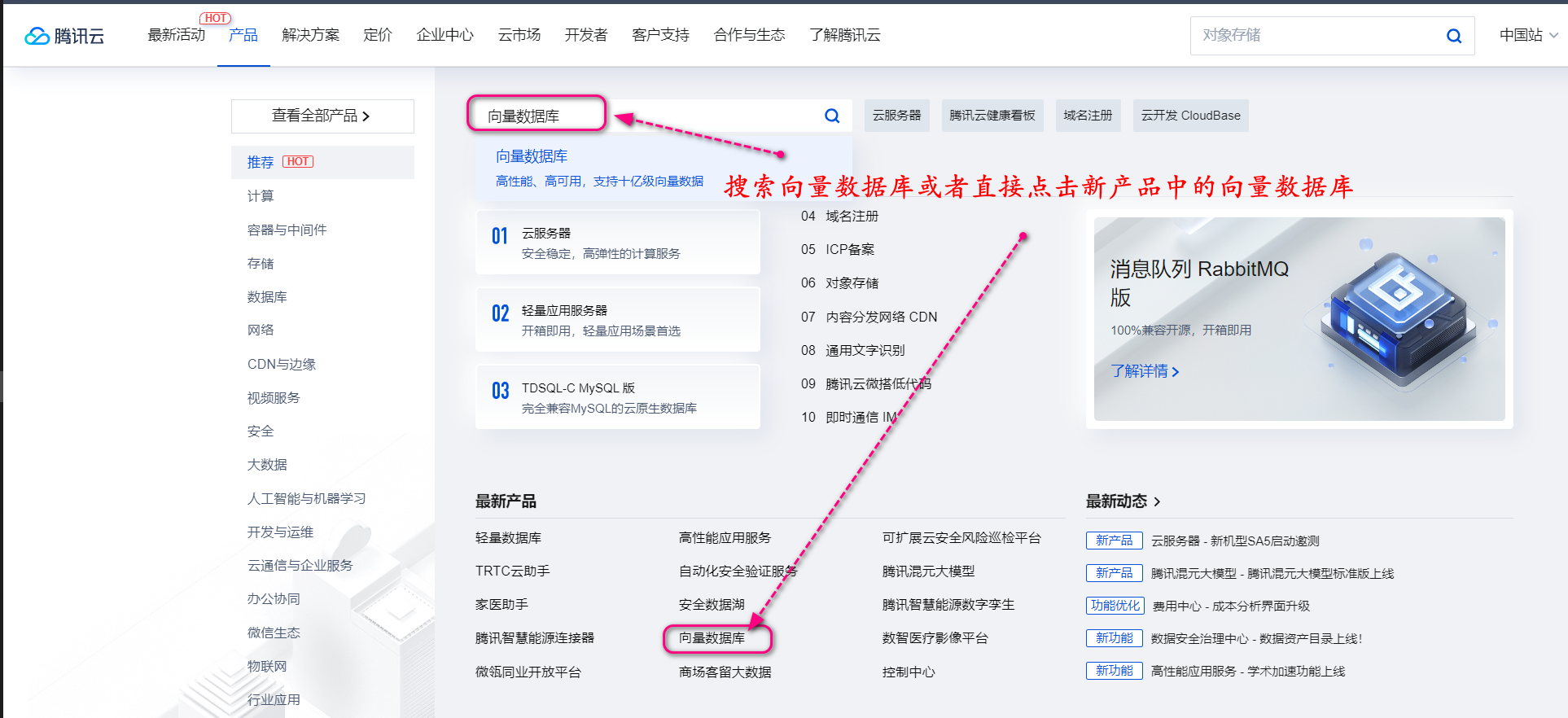
在腾讯云产品页面,搜索向量数据库或者直接点击新产品中的向量数据库。
进入到腾讯云向量数据库首页后,点击立即体验:
在进入创建实例页面中,依次选择配置的地域信息,规格等信息。
详细的信息参照下图,如果没有创建的一些配置,可以根据下图的提示进行提前创建。
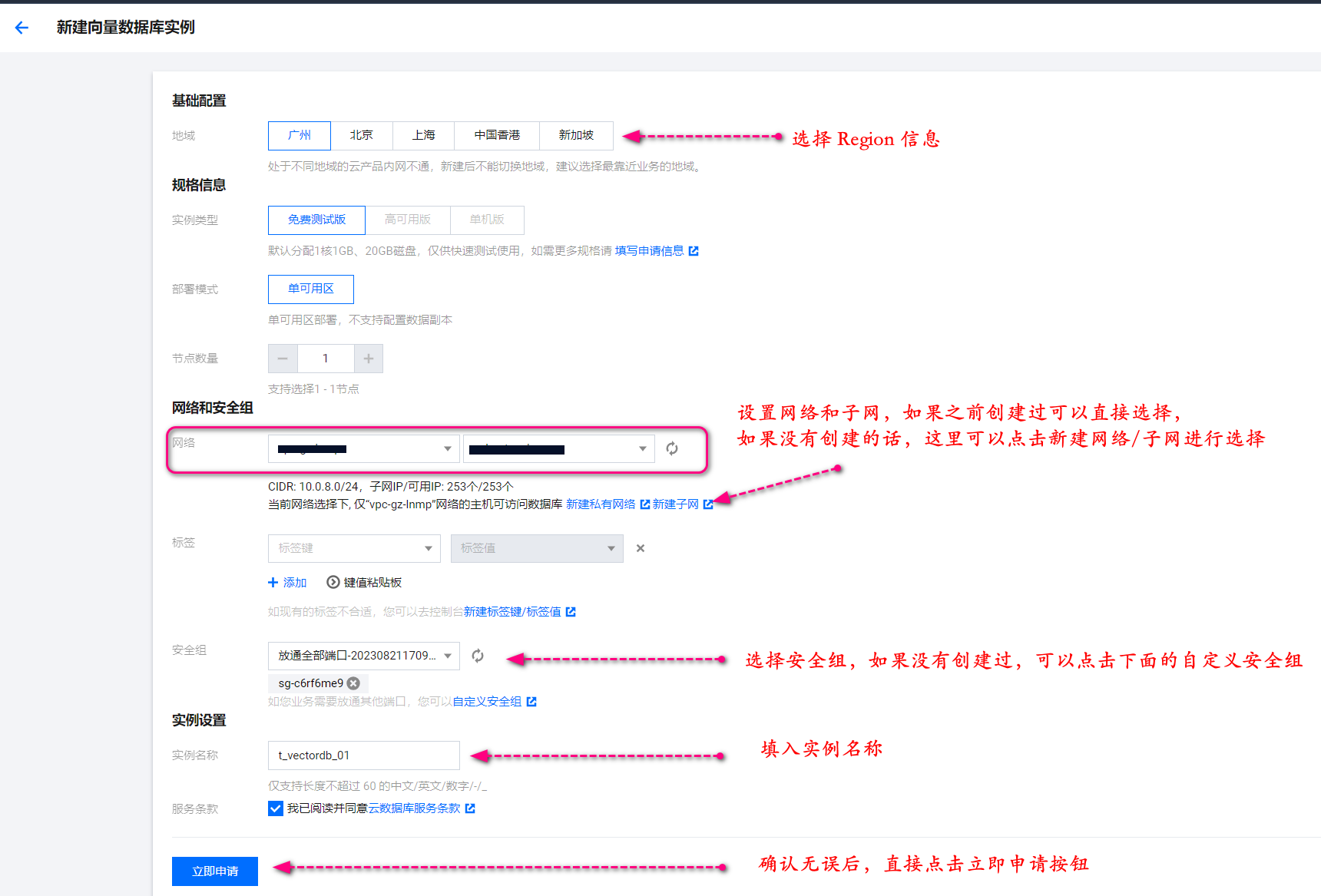
注意:所申请的免费体验实例,最长使用时间为1个月,1个月到期后会被回收。
4.1.2 登陆腾讯云向量数据库
根据自身情况,开启外网访问权限,如果是生产环境不建议开启,只需要自己使用内网即可,本文为了测试演示,开启了外网访问权限。

开启外网访问权限后,点击实例ID进入详情页面,如下图,点击登录按钮。
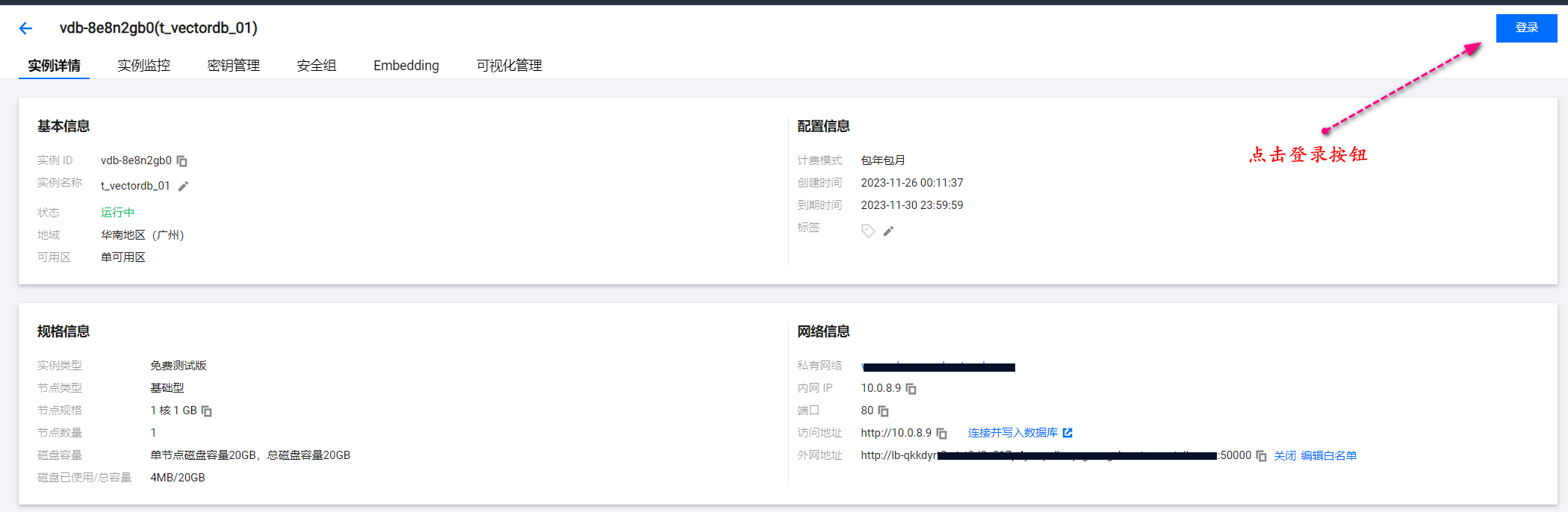
进入到向量数据库登录界面,如图需要账号和密码账号默认是root,密码是向量数据库配置(上图)中的密钥。
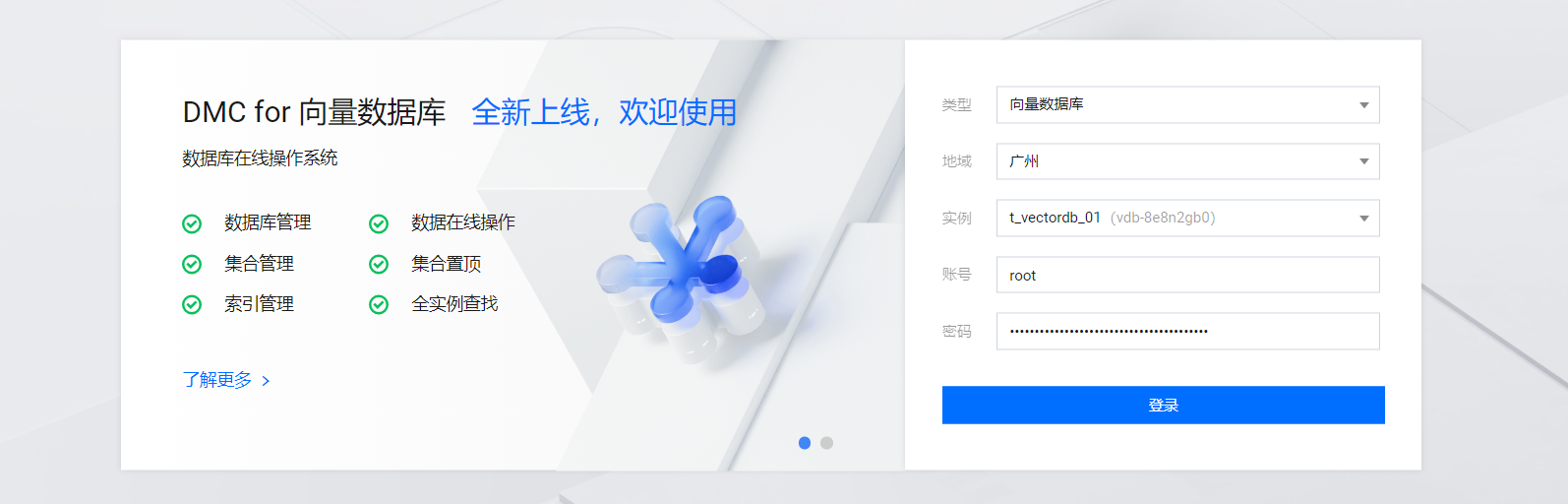
4.1.3 腾讯云向量数据库 SDK 准备
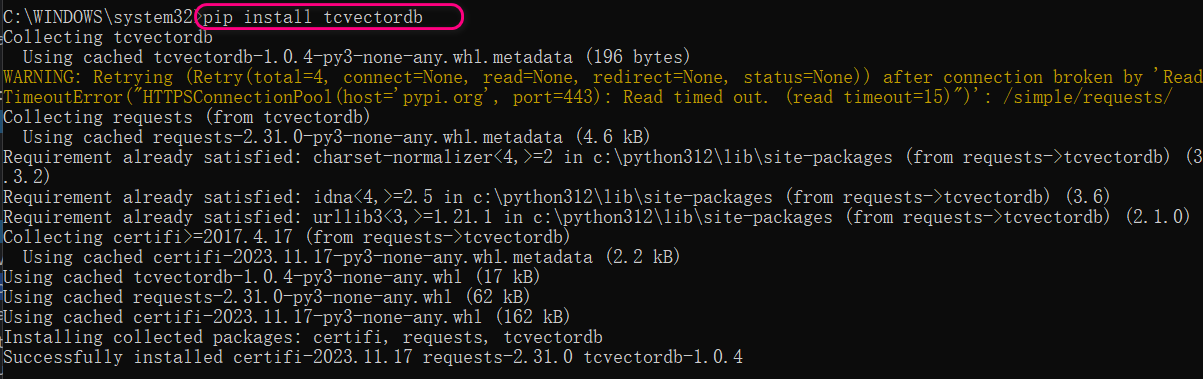
我们以 Python 环境为案例,执行如下命令,可直接安装最新版本。
pip install tcvectordb执行如下图所示:
4.2 案例数据库开发流程
4.2.1 创建数据库
使用如下的代码进行创建数据库:
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
# 创建数据库连接对象
client = tcvectordb.VectorDBClient(url='http://lb-*******.ap-guangzhou.tencentclb.com:50000', username='root', key='G283v2GaQRJG3vk******', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 创建数据库
db = client.create_database(database_name='t_vectordb_demo_01')
print(db.database_name)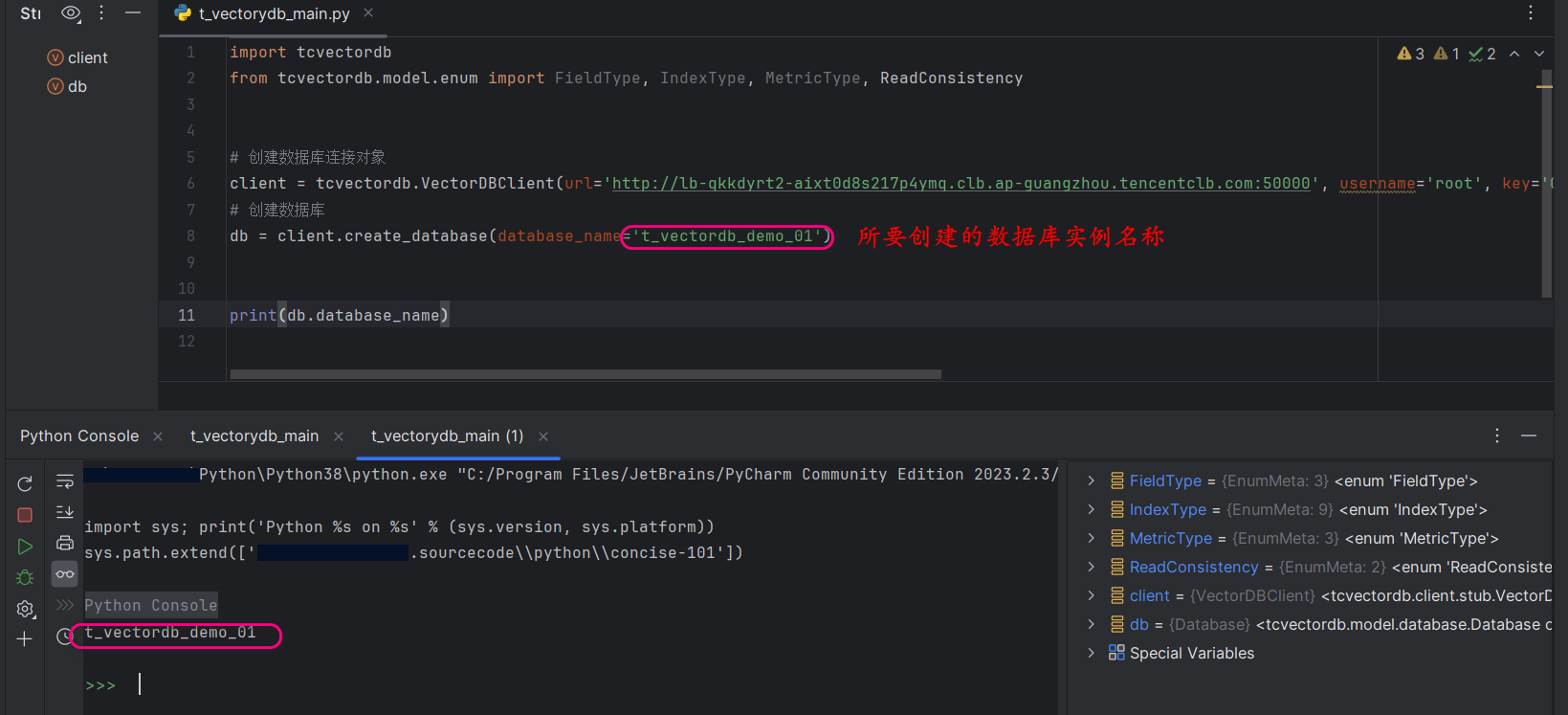
4.2.2 创建集合
# 第一步,设计索引
index = Index(
FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),
VectorIndex(name='vector', dimension=768, index_type=IndexType.HNSW,
metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200)),
)
ebd = Embedding(vector_field='vector', field='text', model=EmbeddingModel.BGE_BASE_ZH)
# 第二步:创建 Collection
coll = db.create_collection(
name='loan_data_analysis',
shard=1,
replicas=0,
description='this is a collection of test embedding',
embedding=ebd,
index=index
)
print(vars(coll))4.2.3 导入数据
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
from tcvectordb.model.enum import FieldType, IndexType, MetricType, EmbeddingModel
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams
from tcvectordb.model.collection import Embedding, UpdateQuery
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
from tcvectordb.model.document import Document, Filter, SearchParams
# # 创建数据库连接对象
client = tcvectordb.VectorDBClient(url='http://lb-******.clb.ap-guangzhou.tencentclb.com:50000', username='root', key='G283v2******', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 指定写入原始文本的数据库与集合
db = client.database('t_vectordb_demo_01')
coll = db.collection('loan_data_analysis')
# 写入数据,可能存在一定延迟
# 1. 支持动态 Schema,除了 id、text 字段必须写入,可以写入其他任意字段,text 字段为创建集合时,设置的文本字段名
# 2. upsert 会执行覆盖写,若文档id已存在,则新数据会直接覆盖原有数据(删除原有数据,再插入新数据)
# 3. 参数 build_index 为 True,指写入数据同时重新创建索引。
res = coll.upsert(
documents=[
Document(
id='1077501',
text="1077501:10+ years",
author='RENT',
bookName='5000',
page=36,
funded_amnt=5000,
funded_amnt_inv=4975,
int_rate=10.65,
installment=162.87,
grade='B',
sub_grade='B2',
emp_title='',
emp_length='10+ years',
home_ownership='RENT'
),
Document(
id='1077430',
text="1314167:< 1 year",
author='RENT',
bookName='2500',
page=60,
funded_amnt=2500,
funded_amnt_inv=2500,
int_rate=15.27,
installment=59.83,
grade='C',
sub_grade='C4',
emp_title='Ryder',
emp_length='< 1 year',
home_ownership='RENT'
)
],
build_index=True
)注意:
1. 支持动态 Schema,除了 id、text 字段必须写入,可以写入其他任意字段,text 字段为创建集合时,设置的文本字段名
2. upsert 会执行覆盖写,若文档id已存在,则新数据会直接覆盖原有数据(删除原有数据,再插入新数据)
3. 参数 build_index 为 True,指写入数据同时重新创建索引。插入测试数据后,我们返回到腾讯云向量数据库中,查看数据如下图所示:
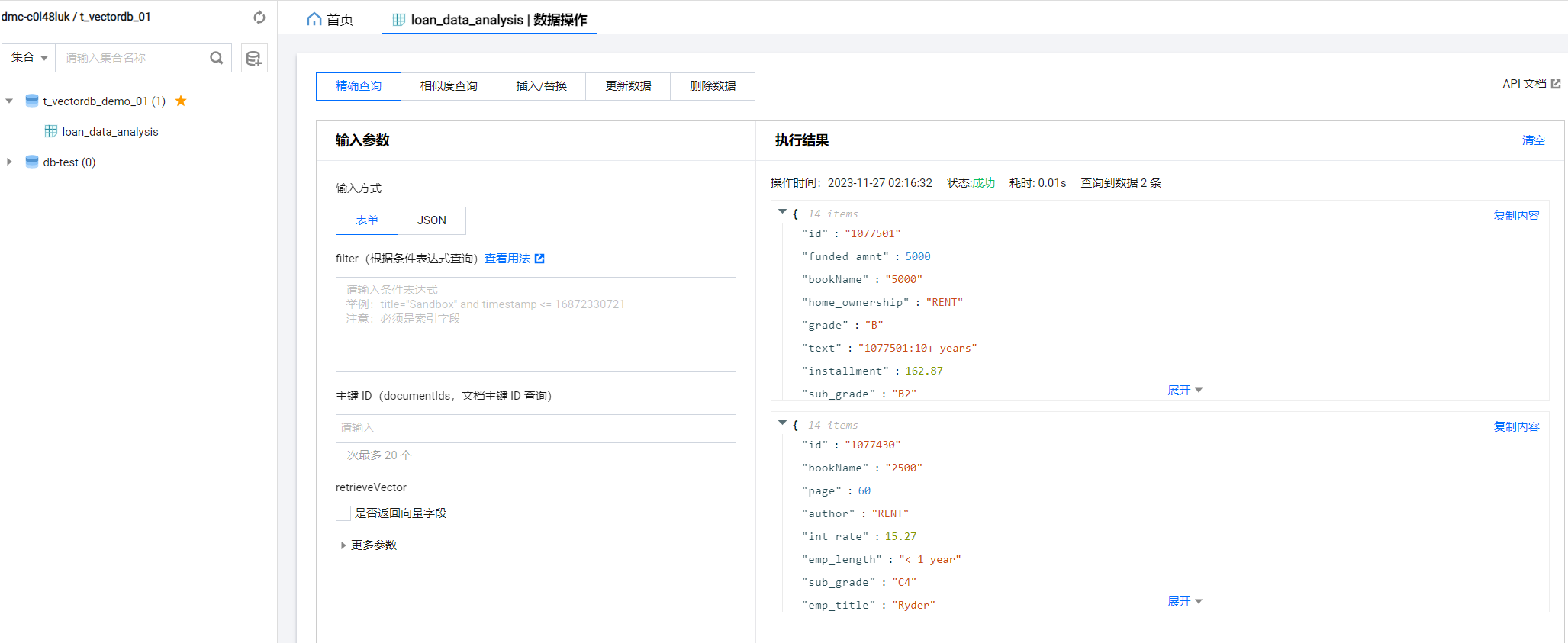
我们可以批量导入下面类似的数据库进入数据库
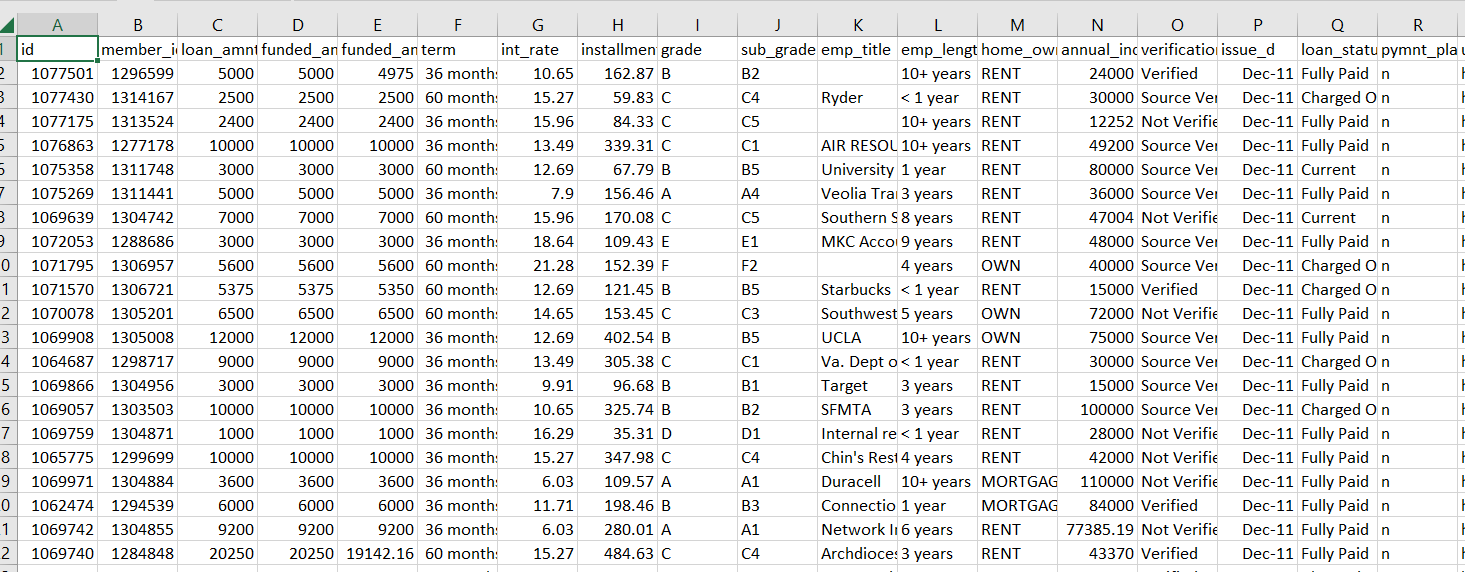
4.2.3 读取数据
读取数据我们使用的是query的方法功能
基于精确匹配的查询方式,query()用于精确查找与查询条件完全匹配的向量,具体支持如下功能。
支持根据主键 id(Document ID),搭配自定义的标量字段的 Filter 表达式一并检索。
支持指定查询起始位置 offset 和返回数量 limit,实现数据 SCAN 能力。
# Set filter
filter_param=Filter(Filter.In("text",["year", "years"]))
# query
doc_list = coll.query(document_ids=['1077501','1077430'], retrieve_vector=True, filter=filter_param, limit=2, offset=0, output_fields=['text','author'])
for doc in doc_list:
print(doc)取出的向量数据如下:
4.2.4 数据分析
将变量转换为其适当的数据类型
某些变量不是其适当的数据类型,需要进行预处理以转换为正确的格式。我们定义了一些函数来帮助自动化这个过程。用于将变量转换为其适当数据类型的函数如下所示。
# 将术语列转换为数字数据类型
def term_numeric(df, column):
df[column] = pd.to_numeric(df[column].str.replace(' months', ''))
term_numeric(data, 'term')
#converting emp-length to numeric datatype
def emp_length_convert(df, column):
df[column] = df[column].str.replace('\+ years', '')
df[column] = df[column].str.replace('< 1 year', str(0))
df[column] = df[column].str.replace(' years', '')
df[column] = df[column].str.replace(' year', '')
df[column] = pd.to_numeric(df[column])
df[column].fillna(value = 0, inplace = True)
# 预处理日期列
def date_columns(df, column):
# store current month
today_date = pd.to_datetime('2020-08-01')
# convert to datetime format
df[column] = pd.to_datetime(df[column], format = "%b-%y")
# calculate the difference in months and add to a new column
df['mths_since_' + column] = round(pd.to_numeric((today_date - df[column]) / np.timedelta64(1, 'M')))
# make any resulting -ve values to be equal to the max date
df['mths_since_' + column] = df['mths_since_' + column].apply(lambda x: df['mths_since_' + column].max() if x < 0 else x)
# drop the original date column
df.drop(columns = [column], inplace = True)目标列的预处理
我们数据集中的目标列是贷款状态,其中包含不同的唯一值。这些值将需要转换为二进制。即,对于不良借款人为0,对于良好借款人为1。在我们的案例中,不良借款人的定义是指在我们的目标列中属于以下情况的人员:已冲销,违约,逾期(31-120天),不符合信用政策的状态:已冲销。其余被分类为良好借款人。
# 基于loan_status列创建一个新列,这将是我们的目标变量
data['good_bad'] = np.where(data.loc[:, 'loan_status'].isin(['Charged Off', 'Default', 'Late (31-120 days)',
'Does not meet the credit policy. Status:Charged Off']), 0, 1)
# Drop the original 'loan_status' column
data.drop(columns = ['loan_status'], inplace = True)分析获取证据权重(WOE)和信息价值
信用风险模型通常需要是可解释和易于理解的。为了实现这一点,所有独立变量都必须是分类的。由于一些变量是连续的,我们将采用证据权重(Weight of Evidence)的概念。
证据权重将帮助我们将连续变量转换为分类特征。连续变量被分为不同区间,并基于它们的证据权重创建新的变量。此外,信息价值帮助我们确定哪个特征在预测中是有用的。下面列出了独立变量的信息价值。信息价值小于0.02的变量将不会被包含在模型中,因为它们没有预测能力
Information value of term is 0.035478
Information value of int_rate is 0.347724
Information value of grade is 0.281145
Information value of emp_length is 0.007174
Information value of home_ownership is 0.017952
Information value of annual_inc is 0.037998
Information value of verification_status is 0.033377
Information value of pymnt_plan is 0.000309
Information value of purpose is 0.028333
Information value of addr_state is 0.010291
Information value of dti is 0.041026
Information value of delinq_2yrs is 0.001039
Information value of inq_last_6mths is 0.040454
Information value of mths_since_last_delinq is 0.002487
Information value of open_acc is 0.004499
Information value of pub_rec is 0.000504
Information value of revol_util is 0.008858
Information value of initial_list_status is 0.011513
Information value of out_prncp is 0.703375
Information value of total_pymnt is 0.515794
Information value of total_rec_int is 0.011108
Information value of last_pymnt_amnt is 1.491828我们训练集中目标列的类别标签存在不平衡,正如下面的条形图所示。使用这种不平衡的数据来训练我们的模型会导致其偏向于预测具有大多数标签的类别。为了防止这种情况,我使用了随机过采样来增加目标列中少数类别的观察数量。需要注意的是,这个过程仅在训练数据上执行。
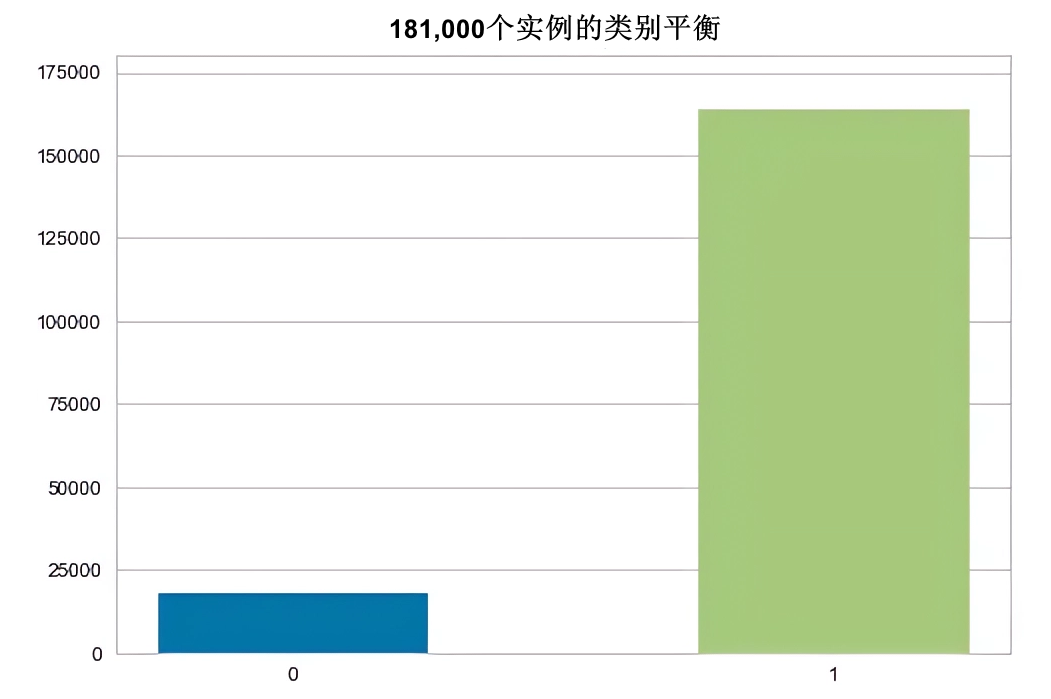
从上述图中,我们可以清晰的看出:对于不良借款人为0,对于良好借款人为1的最终结果。
五、文末总结
这篇文章提供了对数据库分类和腾讯云向量数据库的深入了解。它探讨了向量数据库的重要性以及其在不断变化的需求下的应用。
通过介绍腾讯云向量数据库的优势和实际项目落地情况,文章展示了其在金融信用数据库分析中的实战应用。
这篇文章全面介绍了腾讯云向量数据库的重要性、工作原理以及在实际项目中的应用,为读者提供了深入了解和实际操作的指导。
从使用过程中来看腾讯云向量数据库的优势很多,具有高性能、高可用、大规模、低成本、简单易用、稳定可靠、智能运维等优势。它可以用于各种应用场景,包括推荐系统、自然语言处理、计算机视觉等。在入门方面腾讯云也是毫不吝啬的给到了体验资格,在初入使用的过程中可以比较愉快的体验。
我认为,随着人工智能技术的不断发展,数据库在人工智能领域的应用将会更加广泛。向量数据库作为一种专门用于存储和检索向量数据的数据库,将会在人工智能领域发挥越来越重要的作用。
六、推荐参考文献
AIGC 时代的数据管理 - 向量数据库,扫码即可阅读!

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。