手把手教你用Python爬取猫眼电影Top100榜
原创手把手教你用Python爬取猫眼电影Top100榜
原创
小宇-xiaoyu
发布于 2023-11-29 17:04:04
发布于 2023-11-29 17:04:04
1.观察网站
打开猫眼排行榜网站 按下F12后刷新 搜索第一个的名字可以发现
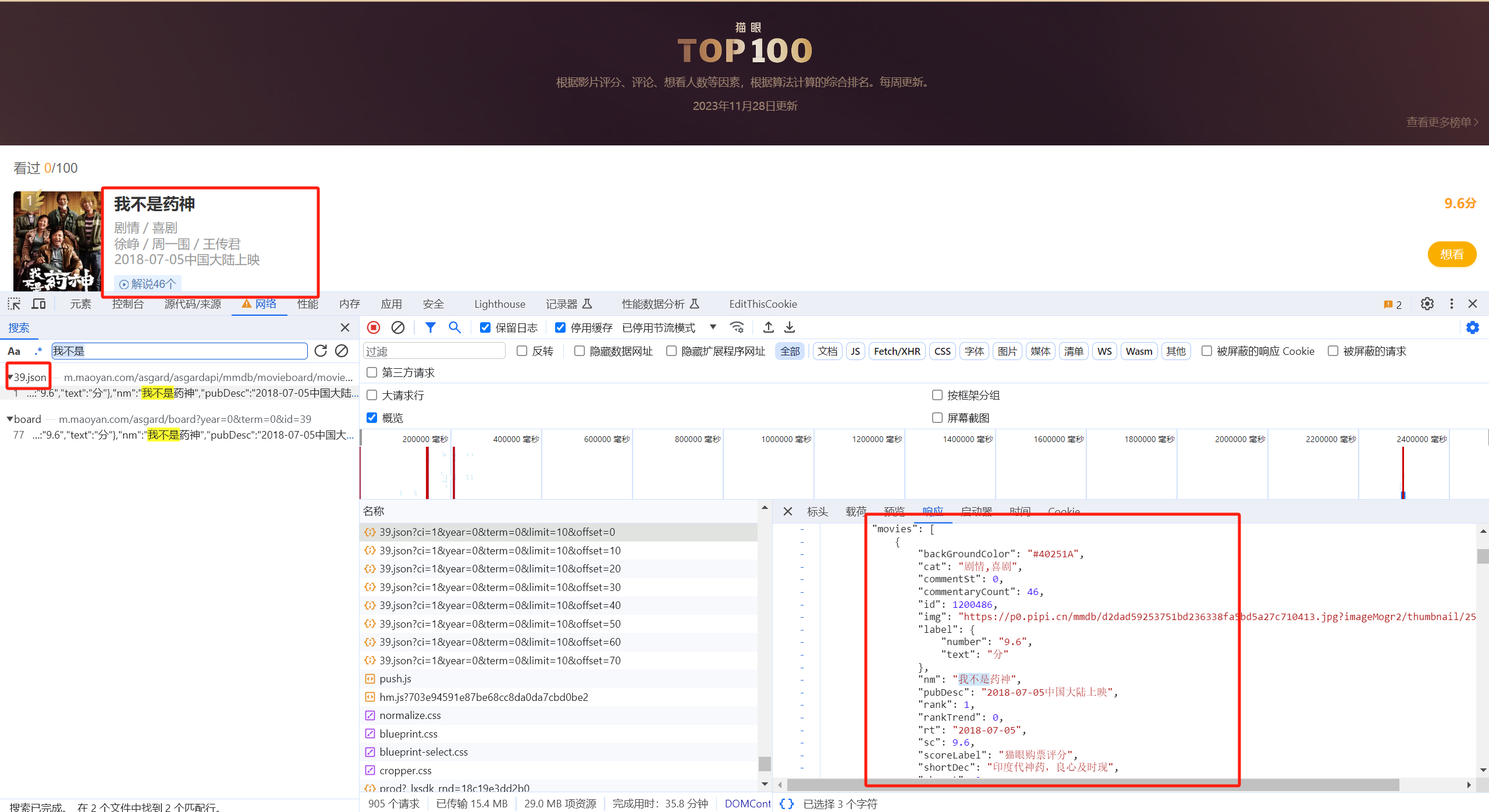
这就是包含前10个电影的json链接:https://m.maoyan.com/asgard/asgardapi/mmdb/movieboard/moviedetail/fixedboard/39.json?ci=1&year=0&term=0&limit=10&offset=0
观察链接发现,其中有limit=10,我们来试下将其改成100看看能不能一次性获取所有电影信息
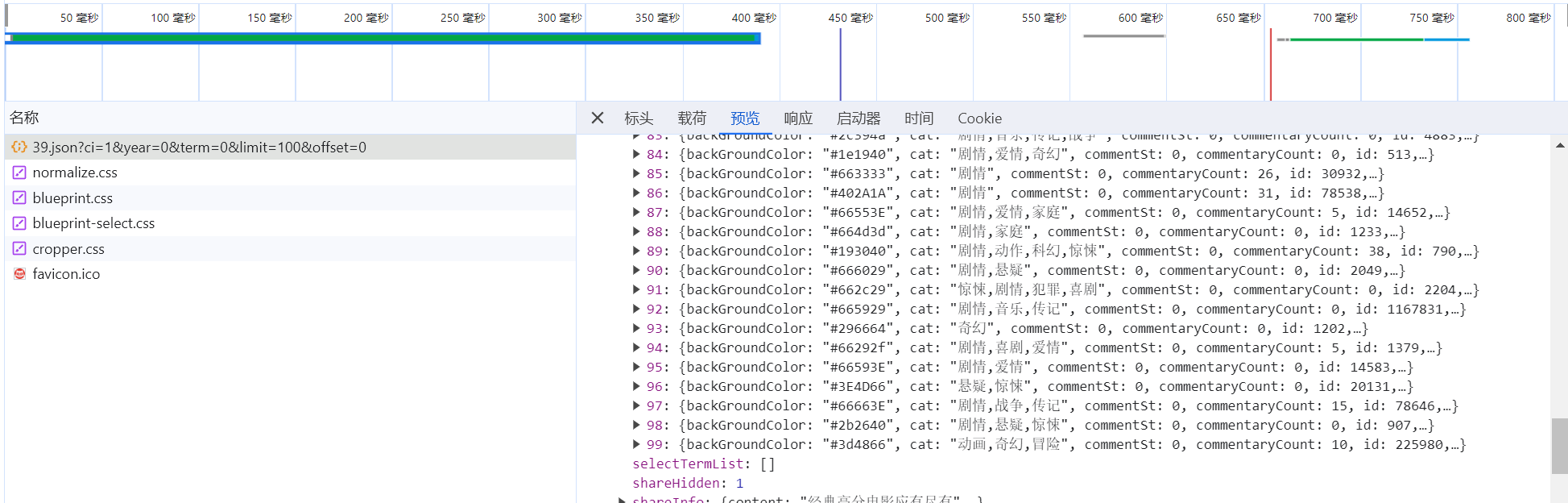
根据返回的结果可以看到 直接将limit改为100丝毫没有问题
2.开始编写代码
使用requests库来进行get请求
未下载requests库的可以使用pip安装,其中-i 为指定下载地址 我们选择腾讯镜像源
pip install -i https://mirrors.cloud.tencent.com/pypi/simple requestsimport requests
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
url = 'https://m.maoyan.com/asgard/asgardapi/mmdb/movieboard/moviedetail/fixedboard/39.json?ci=1&year=0&term=0&limit=100&offset=0'
req = requests.get(url,headers=headers).json()
print(req)运行后可以看到 数据已经获取成功

当然 只获取到json还是不够的,因为不符合人类的阅读习惯,我们来提取需要的字段 并保存为markdown文件
生成markdown表格
def generate_markdown_table(header, data):
# 生成表头
table = "| " + " | ".join(header) + " |\n"
# 生成分隔线
table += "| " + " | ".join(["---"] * len(header)) + " |\n"
# 生成数据行
for row in data:
table += "| " + " | ".join(str(cell) for cell in row) + " |\n"
return table提取数据并保存为md文件
header_list = ["封面", "电影名称", "电影评分", "电影类型", "上映时间", "主演","想看人数"]
data_list = []
for movie in req:
movie_data = [''.format(movie['nm'], movie['img'].replace('2500x2500', '300x500')), movie['nm'], movie['label']['number'], movie['cat'], movie['pubDesc'], movie['star'],movie['wish']]
data_list.append(movie_data)
# 生成Markdown表格
markdown_table = generate_markdown_table(header_list, data_list)
with open("maoyantop100.md", "w", encoding='utf8') as file:
file.write(markdown_table)
打开效果
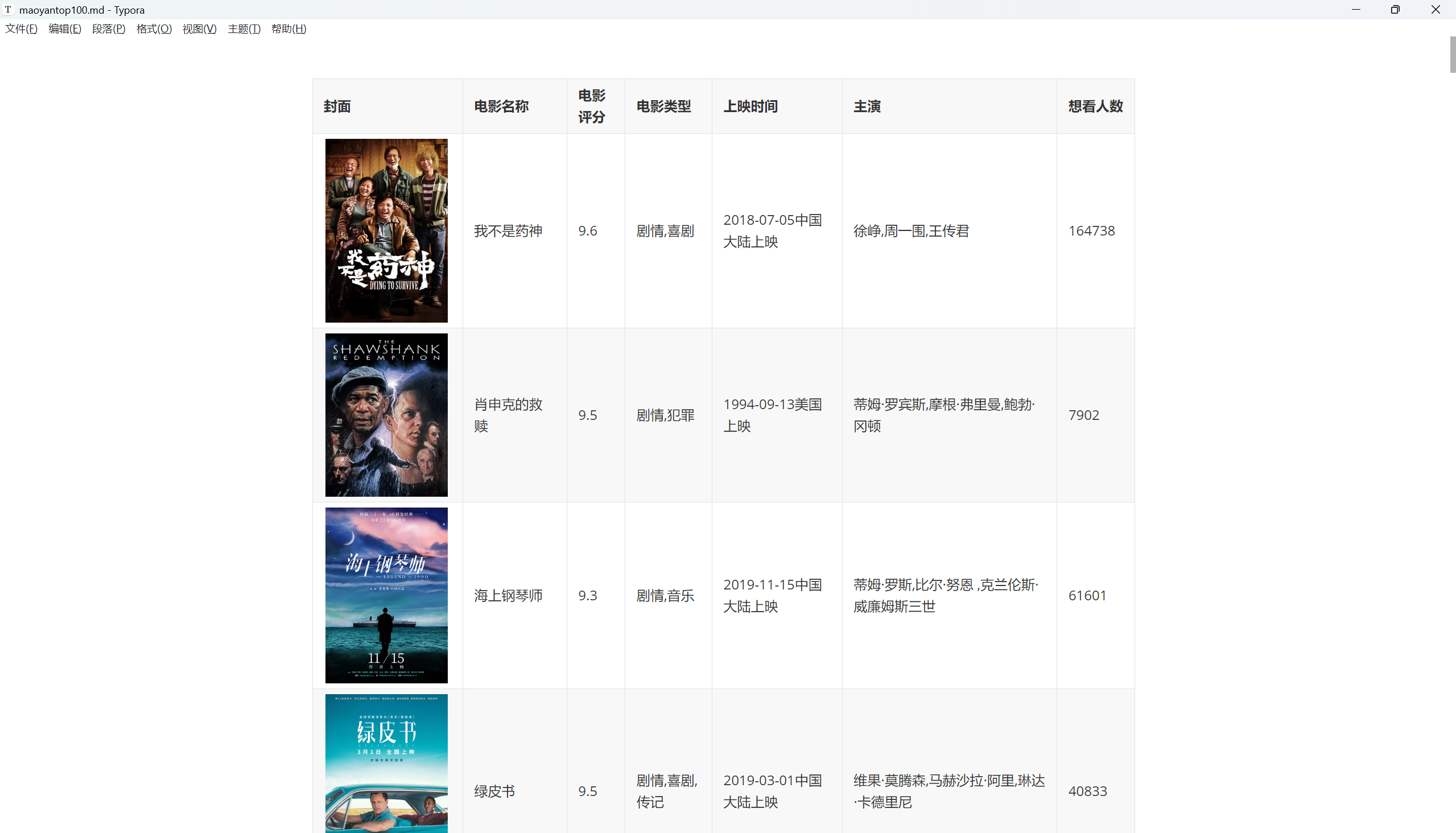
3.完整代码
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
url = 'https://m.maoyan.com/asgard/asgardapi/mmdb/movieboard/moviedetail/fixedboard/39.json?ci=1&year=0&term=0&limit=100&offset=0'
req = requests.get(url, headers=headers).json()['data']['movies']
# print(req)
def generate_markdown_table(header, data):
# 生成表头
table = "| " + " | ".join(header) + " |\n"
# 生成分隔线
table += "| " + " | ".join(["---"] * len(header)) + " |\n"
# 生成数据行
for row in data:
table += "| " + " | ".join(str(cell) for cell in row) + " |\n"
return table
header_list = ["封面", "电影名称", "电影评分", "电影类型", "上映时间", "主演","想看人数"]
data_list = []
for movie in req:
movie_data = [''.format(movie['nm'], movie['img'].replace('2500x2500', '300x500')), movie['nm'], movie['label']['number'], movie['cat'], movie['pubDesc'], movie['star'],movie['wish']]
data_list.append(movie_data)
# 生成Markdown表格
markdown_table = generate_markdown_table(header_list, data_list)
with open("maoyantop100.md", "w", encoding='utf8') as file:
file.write(markdown_table)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录