YOLOv5改进: RT-DETR引入YOLOv5,neck和检测头助力检测
原创YOLOv5改进: RT-DETR引入YOLOv5,neck和检测头助力检测
原创
本文独家改进: 1) RT-DETR neck代替YOLOv5 neck部分; 2)引入RTDETRDecoder
1.RT-DETR介绍

?
论文: https://arxiv.org/pdf/2304.08069.pdf
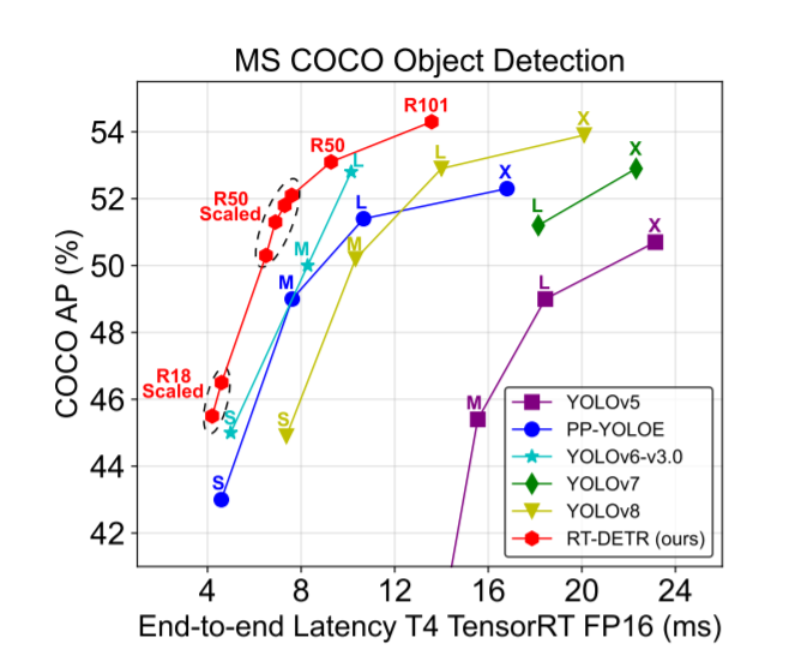
RT-DETR (Real-Time DEtection TRansformer) ,一种基于 DETR 架构的实时端到端检测器,其在速度和精度上取得了 SOTA 性能
为什么会出现:
YOLO 检测器有个较大的待改进点是需要 NMS 后处理,其通常难以优化且不够鲁棒,因此检测器的速度存在延迟。为避免该问题,我们将目光移向了不需要 NMS 后处理的 DETR,一种基于 Transformer 的端到端目标检测器。然而,相比于 YOLO 系列检测器,DETR 系列检测器的速度要慢的多,这使得"无需 NMS "并未在速度上体现出优势。上述问题促使我们针对实时的端到端检测器进行探索,旨在基于 DETR 的优秀架构设计一个全新的实时检测器,从根源上解决 NMS 对实时检测器带来的速度延迟问题。
?
RT-DETR作者团队认为只需将Encoder作用在S5 特征上,既可以大幅度地减小计算量、提高计算速度,又不会损伤到模型的性能。为了验证这一点,作者团队设计了若干对照组,如下图所示。
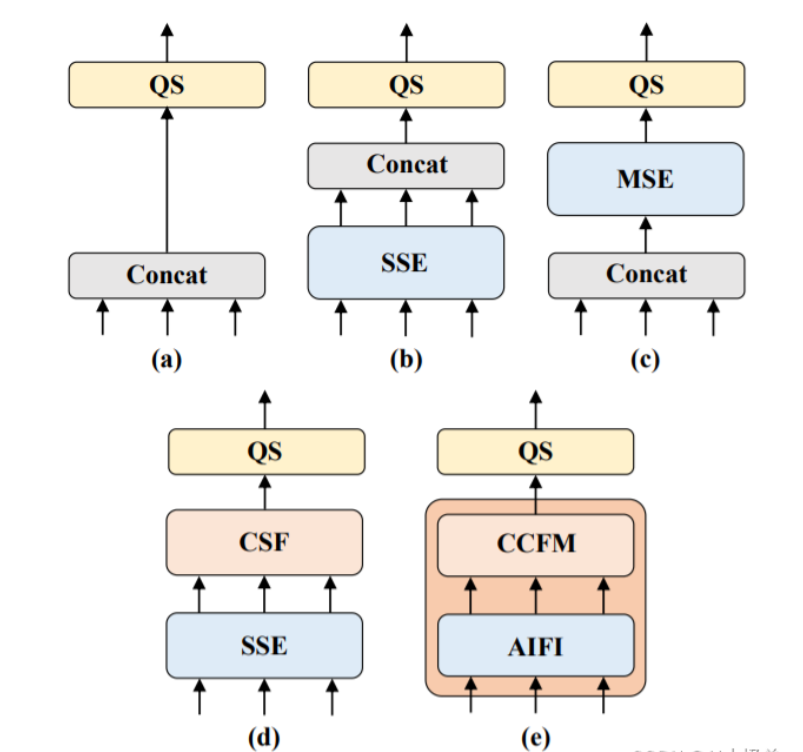
实验结果:
DETR类在COCO上常用的尺度都是800x1333,以往都是以Res50 backbone刷上45 mAP甚至50 mAP为目标,而RT-DETR在采用了YOLO风格的640x640尺度情况下,也不需要熬时长训几百个epoch 就能轻松突破50mAP,精度也远高于所有DETR类模型。

2.RT-DETR引入到YOLOv5
2.1 RT-DETR加入common.py
class RepConv(nn.Module):
"""
RepConv is a basic rep-style block, including training and deploy status.
This module is used in RT-DETR.
Based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
"""Initializes Light Convolution layer with inputs, outputs & optional activation function."""
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward process."""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process."""
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
"""Returns equivalent kernel and bias by adding 3x3 kernel, 1x1 kernel and identity kernel with their biases."""
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
"""Pads a 1x1 tensor to a 3x3 tensor."""
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
"""Generates appropriate kernels and biases for convolution by fusing branches of the neural network."""
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, 'id_tensor'):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def fuse_convs(self):
"""Combines two convolution layers into a single layer and removes unused attributes from the class."""
if hasattr(self, 'conv'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('conv1')
self.__delattr__('conv2')
if hasattr(self, 'nm'):
self.__delattr__('nm')
if hasattr(self, 'bn'):
self.__delattr__('bn')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
class RepC3(nn.Module):
"""Rep C3."""
def __init__(self, c1, c2, n=3, e=1.0):
"""Initialize CSP Bottleneck with a single convolution using input channels, output channels, and number."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.m = nn.Sequential(*[RepConv(c_, c_) for _ in range(n)])
self.cv3 = Conv(c_, c2, 1, 1) if c_ != c2 else nn.Identity()
def forward(self, x):
"""Forward pass of RT-DETR neck layer."""
return self.cv3(self.m(self.cv1(x)) + self.cv2(x))
### intrascale feature interaction (AIFI)
class TransformerEncoderLayer(nn.Module):
# paper: DETRs Beat YOLOs on Real-time Object Detection
# https://arxiv.org/pdf/2304.08069.pdf
"""Defines a single layer of the transformer encoder."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):
"""Initialize the TransformerEncoderLayer with specified parameters."""
super().__init__()
self.ma = nn.MultiheadAttention(c1, num_heads, dropout=dropout, batch_first=True)
# Implementation of Feedforward model
self.fc1 = nn.Linear(c1, cm)
self.fc2 = nn.Linear(cm, c1)
self.norm1 = nn.LayerNorm(c1)
self.norm2 = nn.LayerNorm(c1)
self.dropout = nn.Dropout(dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.act = act
self.normalize_before = normalize_before
@staticmethod
def with_pos_embed(tensor, pos=None):
"""Add position embeddings to the tensor if provided."""
return tensor if pos is None else tensor + pos
def forward_post(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with post-normalization."""
q = k = self.with_pos_embed(src, pos)
src2 = self.ma(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src))))
src = src + self.dropout2(src2)
return self.norm2(src)
def forward_pre(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with pre-normalization."""
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.ma(q, k, value=src2, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src2))))
return src + self.dropout2(src2)
def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Forward propagates the input through the encoder module."""
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
class AIFI(TransformerEncoderLayer):
### intrascale feature interaction (AIFI)
"""Defines the AIFI transformer layer."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):
"""Initialize the AIFI instance with specified parameters."""
super().__init__(c1, cm, num_heads, dropout, act, normalize_before)
def forward(self, x):
### intrascale feature interaction (AIFI)
"""Forward pass for the AIFI transformer layer."""
c, h, w = x.shape[1:]
pos_embed = self.build_2d_sincos_position_embedding(w, h, c)
x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))
return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):
"""Builds 2D sine-cosine position embedding."""
grid_w = torch.arange(int(w), dtype=torch.float32)
grid_h = torch.arange(int(h), dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij')
assert embed_dim % 4 == 0, \
'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'
pos_dim = embed_dim // 4
omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
omega = 1. / (temperature ** omega)
out_w = grid_w.flatten()[..., None] @ omega[None]
out_h = grid_h.flatten()[..., None] @ omega[None]
return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]2.2 yolov5s_RTDETR_neck.yaml
# YOLOv5 ? by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[ [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] , # 10 input_proj.2
[-1, 1, AIFI, [1024, 8]],
[-1, 1, Conv, [256, 1, 1]] , # 12, Y5, lateral_convs.0
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[6, 1, Conv, [256, 1, 1, None, 1, 1, False]], # 14 input_proj.1
[[-2, -1], 1, Concat, [1]],
[-1, 3, RepC3, [256]], # 16, fpn_blocks.0
[-1, 1, Conv, [256, 1, 1]], # 17, Y4, lateral_convs.
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[3, 1, Conv, [256, 1, 1, None, 1, 1, False]], # 19 input_proj.0
[[-2, -1], 1, Concat, [1]], # cat backbone P4
[-1, 3, RepC3, [256]], # X3 (21), fpn_blocks.1
[-1, 1, Conv, [256, 3, 2]], # 22, downsample_convs.0
[[-1, 17], 1, Concat, [1]], # cat Y4
[-1, 3, RepC3, [256]], # F4 (24), pan_blocks.0
[-1, 1, Conv, [256, 3, 2]], # 25, downsample_convs.1
[[-1, 12], 1, Concat, [1]], # cat Y5
[-1, 3, RepC3, [256]], # F5 (27), pan_blocks.1
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
by CSDN AI小怪兽
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。