将分布式系统转换为可嵌入的库有多难?

最近,我在开发一个本地 RAG/LLM 应用,需要支持语义搜索。实际上,作为一款本地应用,它可能产生的嵌入(embeddings)数量相对有限,很难超过百万级别。因此,在项目初期,一个简单幼稚的遍历匹配方法就足以应对需求。然而,我还是希望能够一步到位,找到一个支持 HNSW 索引的嵌入式向量数据库(关于 HNSW 索引的详细信息,请参考我之前的文章)。
理想情况下,我可以直接将 LanceDB 作为库嵌入到我的应用中,但遗憾的是,LanceDB 尚未实现 HNSW 索引。经过一番搜索,我发现 Rust 环境下并不存在其他可嵌入的向量数据库。由于我对 HNSW 的支持比较执拗,因此,我开始研究 Qdrant 的源代码,探索是否有可能将其裁剪为一个可嵌入的向量数据库。
Qdrant 是一个在 Rust 环境下相对成熟的开源向量数据库(Apache 2.0 许可),提供基于 Raft 的分布式集群功能。通常,优秀的分布式系统会首先构建一个可单机使用的核心,然后在此基础上增加分布式集群支持。Qdrant 在这方面做得相当不错,其核心是由 storage 为中心的一系列 crate 共同构成。如果我们直接与 storage 层的 TableOfContent 交互,就能绕过分布式系统的复杂性。但正如你从图中可以看到的,Qdrant 并非一个设计非常良好的系统。它缺乏清晰的分层结构,内部的 crate 像意大利面条一样相互交织缠绕。原本应该处在高层的 GRPC API(api crate),却被两个核心模块 storage 和 collection 来回引用,导致后来我裁剪的时候,虽然我并不需要任何 tonic(grpc)和 axum(grpc 的依赖)的代码,但我的依赖也不得不带上它们,这是后话。

在大概确定了 qdrant 可以被裁剪成一个嵌入式的向量数据库后,我开启了一个 POC 项目 tyrchen/qdrant-lib,目标是:在尽量不修改 qdrant 原始代码的前提下,构建出核心数据结构,调用其完成数据库的建立,数据的插入,以及语义化查询。
那么,如何找出 qdrant 的核心数据结构呢?我们不必深入阅读代码。最简单的方法是使用其客户端,调用某一个 API。比如创建一个数据库:
let client = QdrantClient::from_url("http://localhost:6334").build()?;
client
.create_collection(&CreateCollection {
collection_name: collection.into(),
vectors_config: Some(VectorsConfig {
config: Some(Config::Params(VectorParams {
size: OPENAI_EMBEDDING_DIM,
distance: Distance::Cosine.into(),
..Default::default()
})),
}),
..Default::default()
})
.await?;对这个代码稍作探索就可以发现它调用了相应的 GRPC 服务。剩下的事情就简单了,在 qdrant 代码库中找到 GRPC service 的实现(它用了 tonic,很容易辨识),然后找到 create collection 的方法,避开无关代码和任何跟分布式处理有关的代码,一层层找下去,很容易发现核心代码是 self.toc.perform_collection_meta_op,而核心的数据结构就是 TableOfContent:
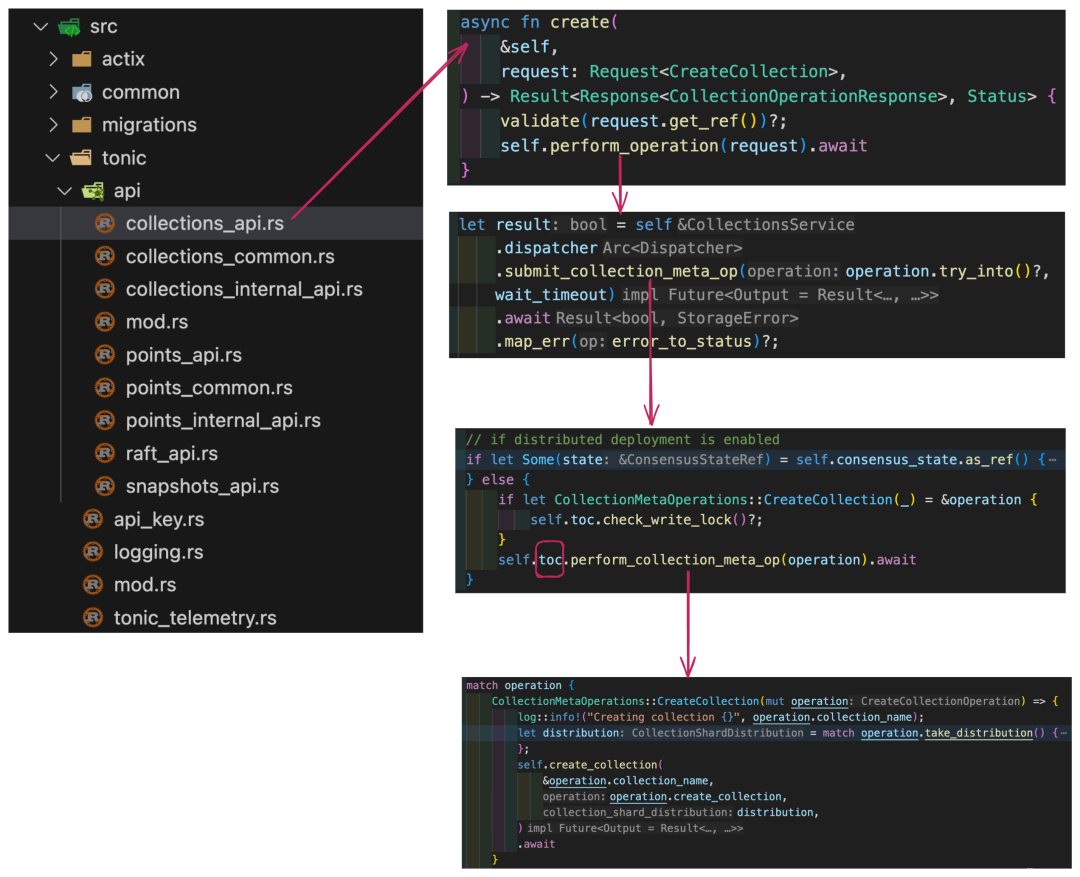
另外一个方法 —— 如上图所示,qdrant 还提供了 RESTful API(见 actix),所以我们也可以看它的代码:
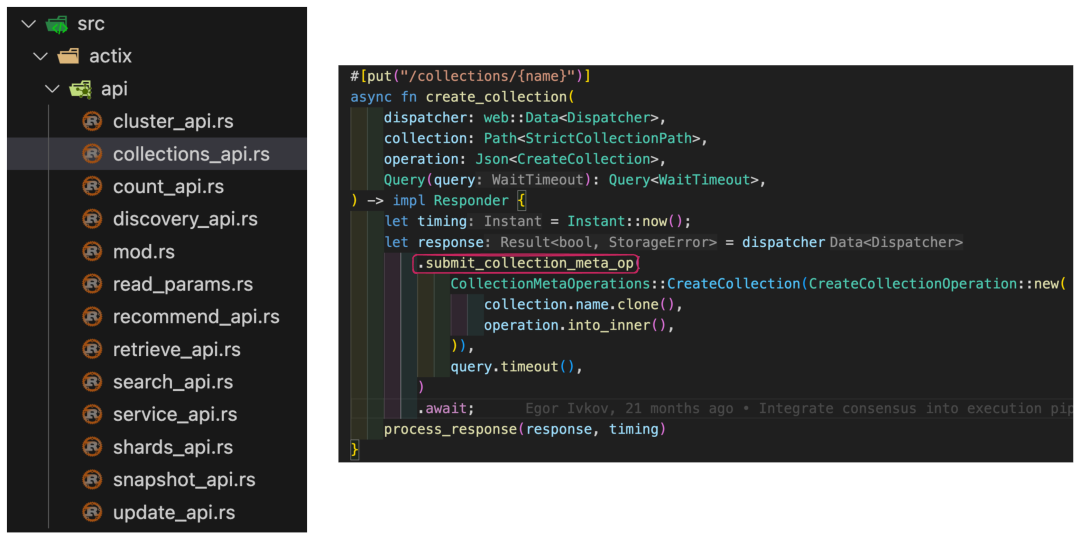
可以看到,二者殊途同归。
接下来,就是来找 TableOfContent 在何处创建。很简单的代码搜索后,不难发现它在 main.rs 里初始化的:
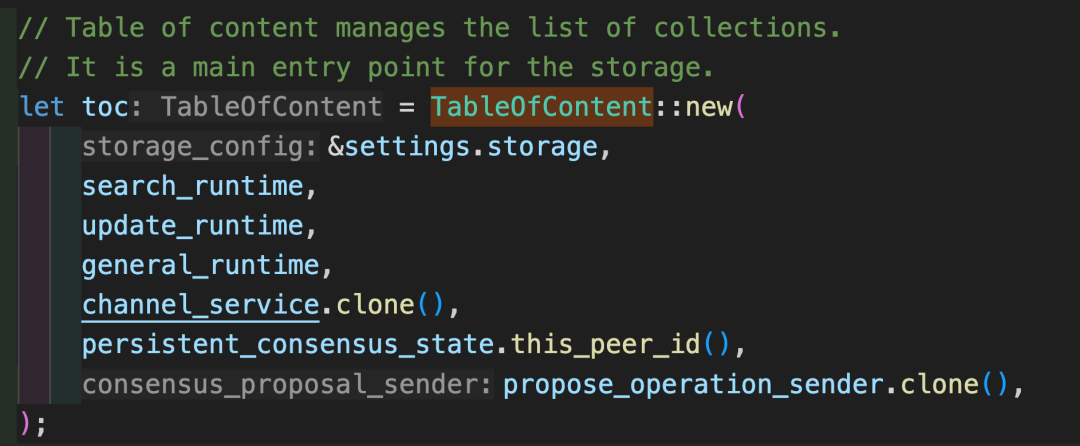
我们只需要确保相关的代码都拷贝到我们的 POC 代码中,并引入需要的依赖。
一旦我们确定了如何创建 TableOfContent,下一步就是将其功能与面向公众的客户端 API 集成。但是,由于 TableOfContent 初始化了多个用于索引和搜索的 Tokio 运行时,它不能在标准的 #[tokio::main] 应用程序下直接操作,否则会报 nested runtime error。
为了解决这个问题,我们在一个专用线程中实例化 TableOfContent,这样它的 runtime 和用户应用程序的 runtime 分属不同的线程,就不存在嵌套。但这样就意味着用户程序的主线程或者其他线程想要调用 TableOfContent 中的功能,就必须引入某种通讯机制。这在 Rust 下很简单,我们可以直接使用 Tokio mpsc channel。用户可以往这个 channel 里发消息,同时提供一个用于发送响应的 oneshot channel,这样,qdrant 所在的线程可以循环监听 mpsc channel,有消息到来就处理,然后通过 oneshot channel 把响应发送回去。如下所示:

这是一种典型的多线程写作的处理机制,我在《Rust 第一课》中也介绍过这种方法,代码见:https://github.com/tyrchen/geektime-rust 下的 38_async/examples/pow.rs。
当我花费几个小时让 POC 正常工作后,我发现了一个严重的问题 —— 即便是非常简单创建 collection 并 list_collections 的代码,在退出时都会产生 pthread invalid argument 的异常退出。
let client = QdrantInstance::start(None)?;
let collection_name = "test_collection";
let ret = client.create_collection(collection_name, Default::default()).await?;
println!("Collection created: {:?}", v);
let collections = client.list_collections().await?;
println!("Collections: {:?}", collections);由于 Rust 代码不直接使用 pthread,这个错误感觉是某个 C/C++ 依赖没有正确退出导致的。我猜想这是由于主线程退出时,qdrant 线程还没有妥善退出,导致 TableOfContent 底层使用的 Rocksdb 还在使用它启动的一些线程。稍微介绍一下 —— rocksdb 是 facebook 提供的一个嵌入式 KV store,使用 C++ 撰写,被广泛应用在各种现代数据库中作为底层的存储层。
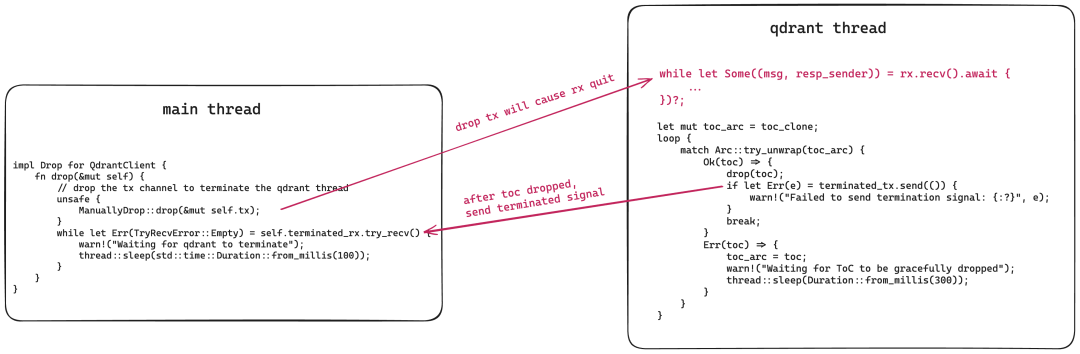
所以这里我们需要让 qdrant 线程先于主线程退出,这样让 TableOfContent 有机会正常关闭 rocksdb。这也是经典的多线程协作方案,做法如下:
- 为 QdrantClient 实现 Drop trait。当其 drop 时,把用于发送消息的 tx 先 drop 掉。这样会导致 mpsc channel 结束,qdrant thread 中的消息处理循环会终结。
- 在 QdrantClient 的 Drop trait 中,等待一个结束信号。QdrantClient 在创建后和 qdrant 线程共享一个 oneshot channel,这个结束信号由 qdrant 线程在正常结束
TableOfContent后发出。如果等不到这个结束信号,就让主线程休息一下,等待一会。 - 最终,整个系统正常退出
解决了创建和销毁这两大难题后,剩下的事情 —— 一个个 API 进行接口实现 —— 基本就是体力活。
总结
对开源代码进行裁剪以使其适应特定需求是一个软件开发者经常使用到的技能。20年前,在我刚刚开始以软件工程师的角色开始工作时,我的第一个重要的任务就是把 linux 2.6 的 netlink 裁剪并移植回公司使用的 linux 2.4。那个任务给我最大的收获是:有时候你不必对系统有深入扎实的理解,就能做好看似需要更高段位才能完成的任务。
如今,算法工程师常常被调侃成调参工程师,其实软件工程师大部分时候也不过是写胶水代码的裱糊匠,或者做裁剪移植工作的裁缝,没什么大不了的。那么,如何做好「裁缝」的工作呢?
为了最大化投入产出比,很多时候我们无需对目标系统有深入的理解,只要理解要做的事情的核心接口即可。把一个分布式的系统裁剪成一个可嵌入使用的库,最重要的就是找到核心数据结构,而寻找核心数据结构,可以顺着高层的,对外提供服务的 API 抽丝拔茧,一点点找到调用的轨迹。虽然我没有阅读过 qdrant 全部十万行代码,甚至在撰写完 qdrant-lib 时,依旧对 TableOfContent 里大部分实现细节并不了解,但并不妨碍我花上两三个晚上,几个小时时间完成这个工作。希望这篇文章的思路可以帮到你。你也可以去b站喜欢历史的程序君看我对此更加详细的视频解读。如果你希望在自己的桌面或者移动应用中嵌入向量数据库,那么,也可以试试这个 repo: github.com/tyrchen/qdrant-lib。