基于知识指令的人类语言-蛋白质语言对齐模型

近年来,大语言模型的出现革新了自然语言处理领域。ChatGPT,Claude-2等模型已经深入到人们的日常生活中了如语言翻译、信息获取、代码生成。但这些语言模型在自然语言和代码语言上极强的处理能力并不能迁移到生物序列(如蛋白质序列)上。当让其描述一条蛋白质序列的功能或者生成一条符合某种性质的蛋白质,它们常常不会遵从指令,或者给出错误答案。文章认为这一现象的出现是因为当前蛋白质-文本对数据集存在两个缺陷:(1)缺乏指令信号;(2)数据注释的不均衡。这两个缺陷导致模型对蛋白质序列建模效果不好且无法有效理解用户的意图。为了弥补这些缺陷,本文提出了一种自动构建蛋白质-文本指令数据集的方法,通过在这个数据集上进行指令微调,模型可以大幅提升蛋白质序列的理解能力和指令跟随能力。本文首次探索了蛋白质语言和人类语言的双向生成能力,展示了将生物序列作为大语言模型能力一部分的潜力,为其更好的服务科学领域提供可能。
方法
注释不均衡问题


数据标注不均衡现象
如图所示在子细胞器位置中一共存在446种分类,前五名的注释量占到了总注释的62.9%,大量的分类只出现了一次即占总注释量的0.000224%。这种注释不均衡问题已经影响到了已有的大语言模型,我们让不同模型预测位置,可以发现预测其预测结果也是存在数据不均衡问题,因此指令数据集的自动化构建不能单纯依赖大语言模型。
知识指令
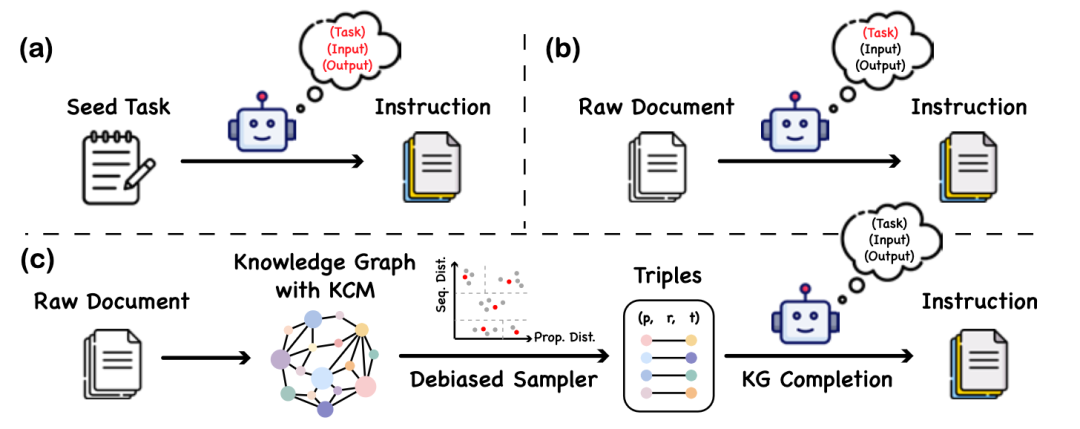
知识指令的构建过程
本文提出了一个名叫知识指令(Knowledge instruction)的数据构建方式,通过知识图谱和大语言模型的合作构建出平衡、多样的指令数据集。该方法不包含大语言模型具备蛋白质语言理解的任何假设,不会产生因为模型幻觉引入的虚假信息。构建过程包含了三个阶段,首先是基于已有蛋白质-文本对构建知识图谱。文章选择用UniProtKB作为数据源。注意到UniProtKB中的数据是结构性的,因此很容易转换为知识图谱。本文在知识图谱上还添加了三元组之间的因果关系,这可以在指令数据中提供注释之间的逻辑链条。在构建完知识图谱后,需要从中抽取蛋白质-文本对构建指令数据。在挑选三元组的过程中一种合理的做法是对蛋白质进行聚类然后在类间均匀采样。本文考虑了序列和性质相似度,当其都大于一定阈值的时候才会被认为是同一类。文章用两个序列的一致性作为序列相似度。在计算性质相似度的时候,先在知识图谱上计算知识图谱嵌入,两蛋白质嵌入的距离作为计算依据。最后一步是将这个三元组转化为指令数据,文章利用已有的大语言模型依据知识图谱补全任务提供的模版进行转化。

知识图谱三元组转变为人类语言-蛋白质语言对齐的指令
模型训练
本文先在自然语言和蛋白语言的文本上分别进行与训练,然后再在指令数据集上进行微调,获得对齐两种语言的能力。
实验
文章在蛋白质序列理解和设计上评估大语言模型
蛋白质理解
文章在三个蛋白质分类任务上对模型进行了评估:蛋白质位置预测、蛋白质功能预测(基于Gene Ontology分类)、蛋白质金属离子结合能力预测。作者将已有的数据集转化为类似于自然语言中的阅读理解问题来评价大语言模型。具体来说,每一条数据包含着一条蛋白质和一个问题,模型需要回答这个问题。假设是一个判断题,只有是/否两个输出会被考虑,选择概率高的哪一个作为模型的预测结果。

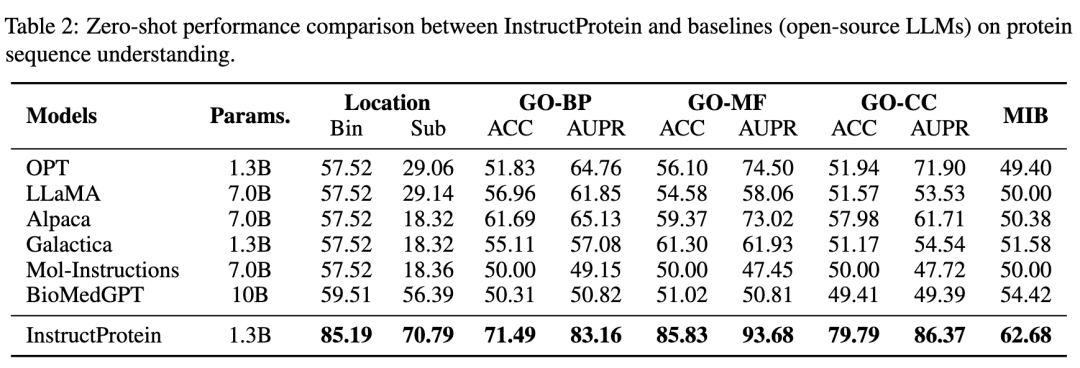
与所有基线方法相比,InstructProtein在所有任务上均取得了最佳性能。有两点需要注意。首先,InstructProtein明显优于源自自然语言训练语料库的LLMs(即ChatGPT、LLaMA、Alpaca)。这些结果表明,使用同时包含蛋白质和自然语言的语料库进行训练对LLMs是有益的,这提高了它们在蛋白质语言理解方面的能力。其次,尽管Galactica、BioMedGPT和Mol-Instructions都利用UniProtKB作为与蛋白质进行自然语言对齐的语料库,但InstructProtein始终表现优于它们。值得注意的是,在蛋白质位置预测(Bin)任务中的奇怪结果是因为现存的大语言模型收到注释不平衡的影响将所有蛋白质分类为单一组。
蛋白质设计
文章设计了一个名叫指令蛋白配对的任务来评估指令和生成的蛋白的一致性。具体来说给定一个蛋白质p及其对应描述z(p),作者会再随机选择9个不对应的描述作为负例,由此可以计算出基于这10个描述的生成蛋白质p的概率。描述z(p)对应的概率最大表示指令和蛋白质正确配对。
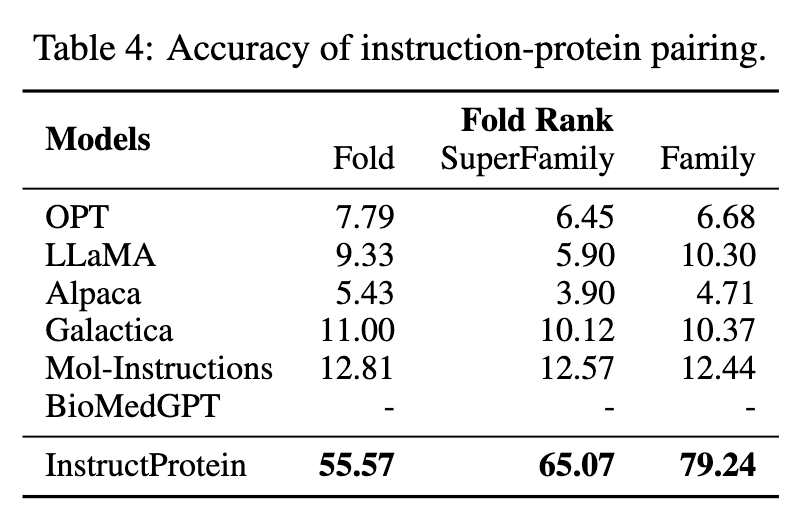
可以观察到,InstructProtein在很大程度上超越了基准。BioMedGPT仅专注于将蛋白质转化为文本,缺乏蛋白质设计的能力。Galactica的训练数据缺乏指令信号导致在指令与蛋白质对齐的零样本性能方面表现有限。Mol-Instructions在蛋白质语料库上缺乏预训练,这使得模型难以区分蛋白质的微妙差异,导致结果不佳。
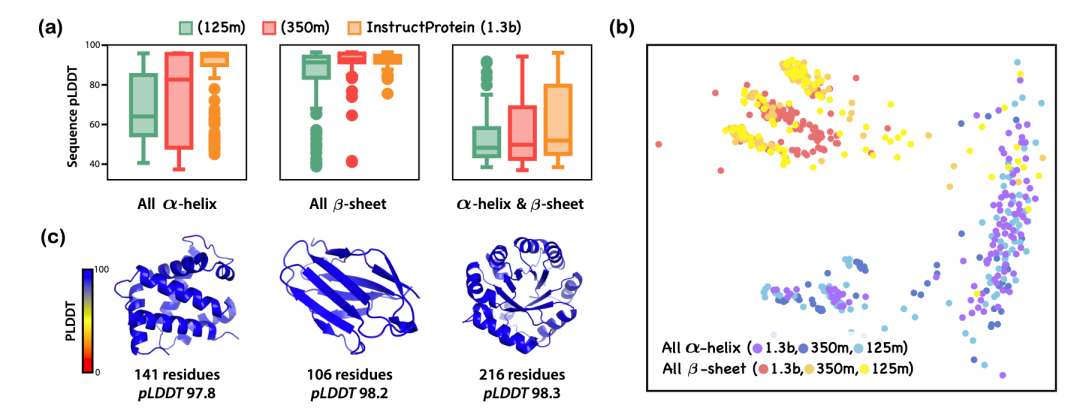

文章还对基于结构相关指令和功能相关指令的蛋白质生成能力进行了进一步的分析。在基于结构相关指令的从头设计中,文章让模型设计了纯alpha螺旋蛋白质、纯beta折叠蛋白质和alpha螺旋以及beta折叠共存的蛋白质。可以看到随着模型的规模的增加,(1)生成蛋白质的pLDDT指标在提高,反映无序区域在减少;(2)基于纯alpha螺旋和纯beta折叠指令生成的蛋白质表示差异越来越大,反应指令跟随能力再提升。在基于功能相关指令的从头设计中,作者利用计算手段发现生成蛋白质的离子结合能力与自然界中具备该功能的蛋白的结合能力类似。这些结论共同说明了InstructProtein在蛋白质从头设计问题上的强大能力。
消融实验
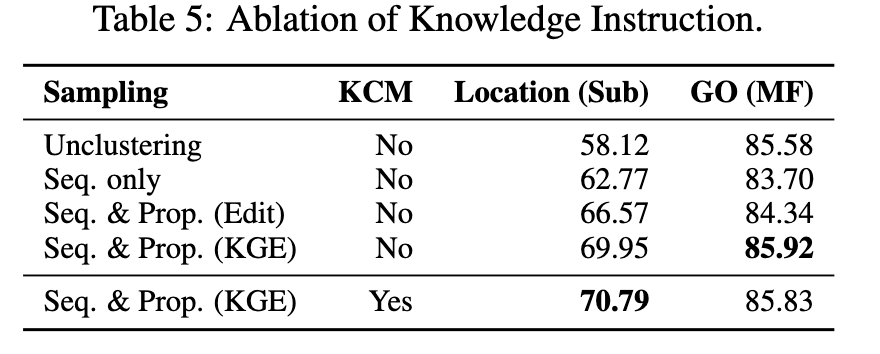
作者对构建数据集中的采样策略和知识因果建模进行了消融研究。可以看到在注释不平衡相关任务(Location)中对相似蛋白质进行聚类可以有效提高模型性能。然而,在注释不平衡不显著的任务中(GO),仅基于序列的聚类方法会降低模型性能。这是合理的,因为该方法减少了困难样本(具有相似序列但不同功能的蛋白质)在训练集中的出现的频率。通过考虑序列和性质的相似性,可以避免这个问题。我们比较了基于知识图谱嵌入距离和编辑距离的性质聚类方法,结果证明知识图谱嵌入具有更强的建模性质相似性的能力。我们还观察到由知识因果建模引入的注释之间的因果关系有助于提高性能。
总结
本文介绍了一种对齐自然语言和蛋白质语言的方法。通过知识图谱和大语言模型合作的方式,基于聚类采样,自动化的生成平衡、事实、多样的指令数据集,通过在该数据集上指令微调,模型可以解锁在生物语言方面的能力。但需要注意的是当前的工作存在着局限性。与大型语言模型共有的这样一个限制是 InstructProtein 在处理数值方面遇到了挑战。而对数值的处理是定量化建模蛋白质重要的一环,如描述他的稳定性、3D结构。在之后的工作中,需要对这个方面有更多的探索。
参考资料
Wang, Zeyuan, Qiang Zhang, Keyan Ding, Ming Qin, Xiang Zhuang, Xiaotong Li, and Huajun Chen. "InstructProtein: Aligning Human and Protein Language via Knowledge Instruction." arXiv preprint arXiv:2310.03269 (2023).