【Tomcat】《How Tomcat Works》英文版GPT翻译(第三章)
【Tomcat】《How Tomcat Works》英文版GPT翻译(第三章)

Part1Chapter 3: Connector
1Overview
As mentioned in Introduction, there are two main modules in Catalina: the connector and the container. In this chapter you will enhance the applications in Chapter 2 by writing a connector that creates better request and response objects. A connector compliant with Servlet 2.3 and 2.4 specifications must create instances of javax.servlet.http.HttpServletRequest and javax.servlet.http.HttpServletResponse to be passed to the invoked servlet's service method. In Chapter 2 the servlet containers could only run servlets that implement javax.servlet.Servlet and passed instances of javax.servlet.ServletRequest and javax.servlet.ServletResponse to the service method. Because the connector does not know the type of the servlet (i.e. whether it implements javax.servlet.Servlet, extends javax.servlet.GenericServlet, or extends javax.servlet.http.HttpServlet), the connector must always provide instances of HttpServletRequest and HttpServletResponse.
正如介绍中所提到的,Catalina 有两个主要模块:连接器和容器。
在本章中,您将通过编写一个连接器来改进第二章中的应用程序,该连接器可以创建更好的请求和响应对象。
符合Servlet 2.3和2.4规范的连接器必须创建javax.servlet.http.HttpServletRequest和javax.servlet.http.HttpServletResponse的实例,以传递给调用的servlet的service方法。
在第二章中,servlet容器只能运行实现javax.servlet.Servlet并将javax.servlet.ServletRequest和javax.servlet.ServletResponse的实例传递给service方法的servlet。
因为连接器不知道servlet的类型(即它是否实现javax.servlet.Servlet,扩展javax.servlet.GenericServlet或扩展javax.servlet.http.HttpServlet),所以连接器必须始终提供HttpServletRequest和HttpServletResponse的实例。
In this chapter's application, the connector parses HTTP request headers and enables a servlet to obtain headers, cookies, parameter names/values, etc. You will also perfect the getWriter method in the Response class in Chapter 2 so that it will behave correctly. Thanks to these enhancements, you will get a complete response from PrimitiveServlet and be able to run the more complex ModernServlet.
在本章的应用中,连接器解析HTTP请求头,并使得 servlet 能够获取头部信息、cookie、参数名/值等。
您还将完善第2章中 Response 类中的 getWriter 方法,以确保其正确运行。
通过这些改进,您将能够从 PrimitiveServlet 获得完整的响应,并能够运行更复杂的ModernServlet。
The connector you build in this chapter is a simplified version of the default connector that comes with Tomcat 4, which is discussed in detail in Chapter 4. Tomcat's default connector is deprecated as of version 4 of Tomcat, however it still serves as a great learning tool. For the rest of the chapter, "connector" refers to the module built in our application.
本章中您构建的连接器是Tomcat 4默认连接器的简化版本,在第4章中有详细讨论。
Tomcat 4的默认连接器已被弃用,但仍可作为学习工具使用。
在本章的其余部分,“连接器”指的是我们应用程序中构建的模块。
Note Unlike the applications in the previous chapters, in this chapter's application the connector is separate from the container. 注意与前几章的应用程序不同,本章的应用程序中连接器与容器是分开的。
The application for this chapter can be found in the ex03.pyrmont package and its sub-packages. The classes that make up the connector are part of the ex03.pyrmont.connector and ex03.pyrmont.connector.http packages. Starting from this chapter, every accompanying application has a bootstrap class used to start the application. However, at this stage, there is not yet a mechanism to stop the application. Once run, you must stop the application abruptly by closing the console (in Windows) or by killing the process (in UNIX/Linux).
本章的应用程序可以在ex03.pyrmont包及其子包中找到。
构成连接器的类属于ex03.pyrmont.connector和ex03.pyrmont.connector.http包。
从本章开始,每个附带的应用程序都有一个引导类用于启动应用程序。
然而,在这个阶段,还没有停止应用程序的机制。一旦运行,您必须通过关闭控制台(在Windows中)或终止进程(在UNIX/Linux中)来突然停止应用程序。
Before we explain the application, let me start with the StringManager class in the org.apache.catalina.util package. This class handles the internationalization of error messages in different modules in this application and in Catalina itself. The discussion of the accompanying application is presented afterwards.
在解释应用程序之前,让我先介绍一下 org.apache.catalina.util 包中的 StringManager 类。
该类处理本应用程序中不同模块和 Catalina 本身中错误信息的国际化。
随后将对配套应用程序进行讨论。
Part2The StringManager Class(字符串管理器类)
A large application such as Tomcat needs to handle error messages carefully. In Tomcat error messages are useful for both system administrators and servlet programmers. For example, Tomcat logs error messages in order for system administrator to easily pinpoint any abnormality that happened. For servlet programmers, Tomcat sends a particular error message inside every javax.servlet.ServletException thrown so that the programmer knows what has gone wrong with his/her servlet.
像Tomcat这样的大型应用程序需要仔细处理错误消息。
在Tomcat中,错误消息对系统管理员和Servlet开发程序员都非常有用。
例如,Tomcat会记录错误消息,以便系统管理员可以轻松地找到任何异常情况。
对于Servlet开发程序员来说,Tomcat会在每次抛出javax.servlet.ServletException时发送特定的错误消息,以便程序员知道他/她的Servlet出了什么问题。
The approach used in Tomcat is to store error messages in a properties file, so that editing them is easy. However, there are hundreds of classes in Tomcat. Storing all error messages used by all classes in one big properties file will easily create a maintenance nightmare. To avoid this, Tomcat allocates a properties file for each package. For example, the properties file in the org.apache.catalina.connector package contains all error messages that can be thrown from any class in that package. Each properties file is handled by an instance of the org.apache.catalina.util.StringManager class. When Tomcat is run, there will be many instances of StringManager, each of which reads a properties file specific to a package. Also, due to Tomcat's popularity, it makes sense to provide error messages in multi languages. Currently, three languages are supported. The properties file for English error messages is named LocalStrings.properties. The other two are for the Spanish and Japanese languages, in the LocalStrings_es.properties and LocalStrings_ja.properties files respectively.
Tomcat使用的方法是将错误消息存储在一个属性文件中,以便于编辑。
然而,在Tomcat中有数百个类。将所有类使用的错误消息存储在一个大的属性文件中会很容易造成维护上的困难。
为了避免这种情况,Tomcat为每个包分配一个属性文件。
例如,org.apache.catalina.connector包中的属性文件包含了该包中任何类可能抛出的所有错误消息。
每个属性文件都由org.apache.catalina.util.StringManager类的一个实例处理。
当Tomcat运行时,会有许多StringManager的实例,每个实例都会读取一个特定于某个包的属性文件。
另外,由于Tomcat的流行,提供多语言的错误消息是有意义的。
目前支持三种语言。英语错误消息的属性文件名为LocalStrings.properties。
其他两种语言分别是西班牙语和日语,对应的属性文件分别是LocalStrings_es.properties和LocalStrings_ja.properties。
When a class in a package needs to look up an error message in that package's properties file, it will first obtain an instance of StringManager. However, many classes in the same package may need a StringManager and it is a waste of resources to create a StringManager instance for every object that needs error messages. The StringManager class therefore has been designed so that an instance of StringManager is shared by all objects inside a package. If you are familiar with design patterns, you'll guess correctly that StringManager is a singleton class. The only constructor it has is private so that you cannot use the new keyword to instantiate it from outside the class. You get an instance by calling its public static method getManager, passing a package name. Each instance is stored in a Hashtable with package names as its keys.
当一个包中的类需要在该包的属性文件中查找错误消息时,它首先会获取一个StringManager的实例。
然而,同一个包中的许多类可能都需要一个 StringManager,为每个需要错误消息的对象创建一个StringManager实例是一种资源浪费。
因此,StringManager 类被设计成在一个包内的所有对象之间共享一个 StringManager 实例。
如果你熟悉设计模式,你会猜到 StringManager 是一个单例类。
它只有一个私有构造函数,因此你不能使用new关键字从类外部实例化它。
你可以通过调用它的公共静态方法getManager并传递一个包名来获取一个实例。
每个实例都存储在一个Hashtable中,
以包名作为键。
private static Hashtable managers = new Hashtable();
public synchronized static StringManager
getManager(String packageName) {
StringManager mgr = (StringManager)managers.get(packageName);
if (mgr == null) {
mgr = new StringManager(packageName);
managers.put(packageName, mgr);
}
return mgr;
}
Note An article on the Singleton pattern entitled "The Singleton Pattern" can be found in the accompanying ZIP file. 注意:在附带的ZIP文件中可以找到一篇关于单例模式的文章,标题为“单例模式”。
For example, to use StringManager from a class in the ex03.pyrmont.connector.http package, pass the package name to the StringManager class's getManager method:
例如,要在ex03.pyrmont.connector.http包中的一个类中使用 StringManager,将包名传递给 StringManager 类的 getManager 方法。
StringManager sm = StringManager.getManager("ex03.pyrmont.connector.http");
In the ex03.pyrmont.connector.http package, you can find three properties files: LocalStrings.properties, LocalStrings_es.properties and LocalStrings_ja.properties. Which of these files will be used by the StringManager instance depends on the locale of the server running the application. If you open the LocalStrings.properties file, the first non-comment line reads:
在ex03.pyrmont.connector.http包中,您可以找到三个属性文件:
LocalStrings.propertiesLocalStrings_es.propertiesLocalStrings_ja.properties
StringManager实例将使用这些文件中的哪一个取决于运行应用程序的服务器的区域设置。如果您打开LocalStrings.properties文件,第一行非注释行的内容如下:
httpConnector.alreadyInitialized=HTTP connector has already been initialized httpConnector.alreadyInitialized=HTTP连接器已经初始化
To get an error message, use the StringManager class's getString, passing an error code. Here is the signature of one of its overloads:
要获取错误消息,请使用StringManager类的getString方法,并传递错误代码。以下是其重载之一的签名:
public String getString(String key)
Calling getString by passing httpConnector.alreadyInitialized as the argument returns HTTP connector has already been initialized.
通过将httpConnector.alreadyInitialized作为参数调用 getString,会返回 HTTP 连接器已经初始化。
Part3The Application
Starting from this chapter, the accompanying application for each chapter is divided into modules. This chapter's application consists of three modules: connector, startup, and core.
从本章开始,每个章节的附带应用程序被分成了模块。本章的应用程序由三个模块组成:连接器、启动器和核心部分。
The startup module consists only of one class, Bootstrap, which starts the application. The connector module has classes that can be grouped into five categories:
启动模块只包含一个类 Bootstrap,它用于启动应用程序。连接器模块包含可以分为五个类别的类:
- The connector and its supporting class (HttpConnector and HttpProcessor).
- The class representing HTTP requests (HttpRequest) and its supporting classes.
- The class representing HTTP responses (HttpResponse) and its supporting classes.
- Fa?ade classes (HttpRequestFacade and HttpResponseFacade).
- The Constant class.
- 连接器及其支持类(
HttpConnector和HttpProcessor)。 - 表示HTTP请求的类(
HttpRequest)及其支持类。 - 表示HTTP响应的类(
HttpResponse)及其支持类。 - 门面类(
HttpRequestFacade和HttpResponseFacade)。 - 常量类。
The core module consists of two classes: ServletProcessor and StaticResourceProcessor.
核心模块由两个类组成:ServletProcessor 和 StaticResourceProcessor。
Figure 3.1 shows the UML diagram of the classes in this application. To make the diagram more readable, the classes related to HttpRequest and HttpResponse have been omitted. You can find UML diagrams for both when we discuss Request and Response objects respectively
图3.1显示了该应用程序中类的UML图。
为了使图表更易读,与 HttpRequest 和 HttpResponse 相关的类被省略了。当我们分别讨论请求和响应对象时,您可以找到 HttpRequest 和 HttpResponse 的UML图。
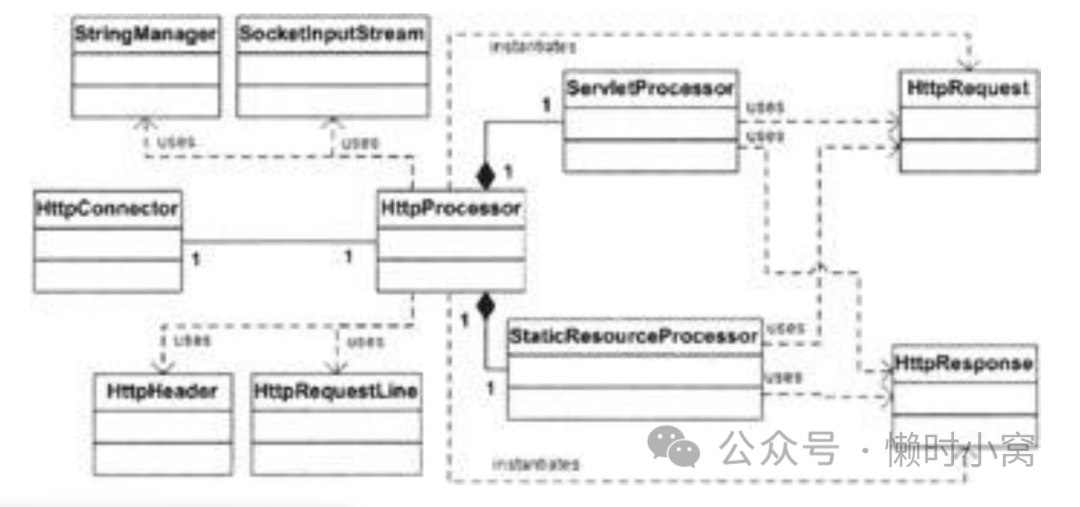
Figure 3.1: The UML diagram of the application
Figure 3.1: The UML diagram of the application
图 3.1:应用程序的 UML 图
Compare the diagram with the one in Figure 2.1. The HttpServer class in Chapter 2 has been broken into two classes: HttpConnector and HttpProcessor, Request has been replaced by HttpRequest, and Response by HttpResponse. Also, more classes are used in this chapter's application.
将图表与图2.1中的图表进行比较。第2章中的HttpServer类已被拆分为两个类:HttpConnector和HttpProcessor,Request被替换为HttpRequest,Response被替换为HttpResponse。此外,本章应用程序中使用了更多的类。
The HttpServer class in Chapter 2 is responsible for waiting for HTTP requests and creating request and response objects. In this chapter's application, the task of waiting for HTTP requests is given to the HttpConnector instance, and the task of creating request and response objects is assigned to the HttpProcessor instance.
第2章中的 HttpServer 类负责等待HTTP请求并创建请求和响应对象。
在本章应用程序中,等待HTTP请求的任务交给了 HttpConnector 实例,创建请求和响应对象的任务分配给了 HttpProcessor 实例。
In this chapter, HTTP request objects are represented by the HttpRequest class, which implements javax.servlet.http.HttpServletRequest. An HttpRequest object will be cast to a HttpServletRequest instance and passed to the invoked servlet's service method. Therefore, every HttpRequest instance must have its fields properly populated so that the servlet can use them. Values that need to be assigned to the HttpRequest object include the URI, query string, parameters, cookies and other headers, etc. Because the connector does not know which values will be needed by the invoked servlet, the connector must parse all values that can be obtained from the HTTP request. However, parsing an HTTP request involves expensive string and other operations, and the connector can save lots of CPU cycles if it parses only values that will be needed by the servlet. For example, if the servlet does not need any request parameter (i.e. it does not call the getParameter, getParameterMap, getParameterNames, or getParameterValues methods of javax.servlet.http.HttpServletRequest), the connector does not need to parse these parameters from the query string and or from the HTTP request body. Tomcat's default connector (and the connector in this chapter's application) tries to be more efficient by leaving the parameter parsing until it is really needed by the servlet.
在本章中,HTTP请求对象由实现javax.servlet.http.HttpServletRequest的HttpRequest类表示。
HttpRequest 对象将被转换为 HttpServletRequest 实例并传递给被调用的 servlet 的 service 方法。
因此,每个 HttpRequest 实例必须正确填充其字段,以便 servlet 可以使用它们。
需要分配给 HttpRequest 对象的值包括
- URI
- 查询字符串
- 参数
Cookie- 其他头部
等等。
因为连接器不知道被调用的 servlet 将需要哪些值,所以连接器必须解析从 HTTP 请求中获取的所有值。
然而,解析HTTP请求涉及昂贵的字符串和其他操作,如果连接器仅解析servlet将需要的值,它可以节省大量的CPU周期。
例如,如果 servlet 不需要任何请求参数(即不调用javax.servlet.http.HttpServletRequest的 getParameter、getParameterMap、getParameterNames 或 getParameterValues 方法),连接器不需要从查询字符串或HTTP请求体中解析这些参数。
Tomcat的默认连接器(以及本章应用程序中的连接器)通过将参数解析推迟到servlet实际需要时来提高效率。
Tomcat's default connector and our connector use the SocketInputStream class for reading byte streams from the socket's InputStream. An instance of SocketInputStream wraps the java.io.InputStream instance returned by the socket's getInputStream method. The SocketInputStream class provides two important methods: readRequestLine and readHeader.readRequestLine returns the first line in an HTTP request, i.e. the line containing the URI, method and HTTP version. Because processing byte stream from the socket's input stream means reading from the first byte to the last (and never moves backwards), readRequestLine must be called only once and must be called before readHeader is called. readHeader is called to obtain a header name/value pair each time it is called and should be called repeatedly until all headers are read. The return value of readRequestLine is an instance of HttpRequestLine and the return value of readHeader is an HttpHeader object. We will discuss the HttpRequestLine and HttpHeader classes in the sections to come.
Tomcat 的默认连接器和我们的连接器都使用 SocketInputStream 类来从套接字的 InputStream 中读取字节流。
SocketInputStream 的实例包装了由套接字的 getInputStream 方法返回的 java.io.InputStream 实例。
SocketInputStream 类提供了两个重要的方法:readRequestLine 和 readHeader。readRequestLine 返回HTTP请求中的第一行,即包含URI、方法和HTTP版本的行。
由于从套接字的输入流中处理字节流意味着从第一个字节读取到最后一个字节(并且永远不会向后移动), readRequestLine 只能调用一次,并且必须在调用readHeader之前调用。
每次调用 readHeader 时,它都会返回一个头部名称/值对,并且应该重复调用直到读取完所有头部。
readRequestLine的返回值是一个 HttpRequestLine 的实例,而 readHeader 的返回值是一个 HttpHeader 对象。
我们将在接下来的部分讨论HttpRequestLine和HttpHeader类。
The HttpProcessor object creates instances of HttpRequest and therefore must populate fields in them. The HttpProcessor class, using its parse method, parses both the request line and headers in an HTTP request. The values resulting from the parsing are then assigned to the fields in the HttpProcessor objects. However, the parse method does not parse the parameters in the request body or query string. This task is left to the HttpRequest objects themselves. Only if the servlet needs a parameter will the query string or request body be parsed.
HttpProcessor 对象创建HttpRequest的实例,因此必须为它们填充字段。
HttpProcessor 类使用其 parse 方法解析HTTP请求中的请求行和头部。
解析的结果值然后被分配给 HttpProcessor 对象中的字段。
然而,parse方法不会解析请求体或查询字符串中的参数。
这个任务留给了HttpRequest对象自己。只有当servlet需要参数时,才会解析查询字符串或请求体。
Another enhancement over the previous applications is the presence of the bootstrap class ex03.pyrmont.startup.Bootstrap to start the application.
与之前的应用程序相比,另一个改进是使用了引导类 ex03.pyrmont.startup.Bootstrap,以启动应用程序。
We will explain the application in detail in these sub-sections:
我们将在这些小节中详细介绍应用程序:
- Starting the Application
- The Connector
- Creating an HttpRequest Object
- Creating an HttpResponse Object
- Static resource processor and servlet processor
- Running the Application
- 启动应用程序
- 连接器
- 创建
HttpRequest对象 - 创建
HttpResponse对象 - 静态资源处理器和
servlet处理器 - 运行应用程序
2Starting the Application(启动应用程序)
You start the application from the ex03.pyrmont.startup.Bootstrap class. This class is given in Listing 3.1.
您可以通过 ex03.pyrmont.startup.Bootstrap 类启动应用程序。 该类如清单 3.1 所示。
Listing 3.1: The Bootstrap class
清单 3.1:Bootstrap 类
package ex03.pyrmont.startup;
import ex03.pyrmont.connector.http.HttpConnector;
public final class Bootstrap {
public static void main(String[] args) {
HttpConnector connector = new HttpConnector();
connector.start();
}
}
The main method in the Bootstrap class instantiates the HttpConnector class and calls its start method. The HttpConnector class is given in Listing 3.2.
Bootstrap 类中的 main 方法会实例化 HttpConnector 类,并调用其 start 方法。HttpConnector 类见清单 3.2。
Listing 3.2: The HttpConnector class's start method
清单 3.2:HttpConnector 类的启动方法
package ex03.pyrmont.connector.http;
import java.io.IOException;
import java.net.InetAddress;
import java.net.ServerSocket;
import java.net.Socket;
public class HttpConnector implements Runnable {
boolean stopped;
private String scheme = "http";
public String getScheme() {
return scheme;
}
public void run() {
ServerSocket serverSocket = null;
int port = 8080;
try {
serverSocket = new
ServerSocket(port, 1, InetAddress.getByName("127.0.0.1"));
}
catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
while (!stopped) {
// Accept the next incoming connection from the server socket
Socket socket = null;
try {
socket = serverSocket.accept();
}
catch (Exception e) {
continue;
}
// Hand this socket off to an HttpProcessor
HttpProcessor processor = new HttpProcessor(this);
processor.process(socket);
}
}
public void start() {
Thread thread = new Thread(this);
thread.start ();
}
}
3The Connector(连接器)
The ex03.pyrmont.connector.http.HttpConnector class represents a connector responsible for creating a server socket that waits for incoming HTTP requests. This class is presented in Listing 3.2.
ex03.pyrmont.connector.http.HttpConnector 类表示一个负责创建等待传入HTTP请求的服务器套接字的连接器。
这个类在3.2节的清单中展示。
The HttpConnector class implements java.lang.Runnable so that it can be dedicated a thread of its own. When you start the application, an instance of HttpConnector is created and its run method executed.
HttpConnector 类实现了java.lang.Runnable接口,因此它可以拥有自己的线程。
当您启动应用程序时,会创建一个 HttpConnector 实例并执行其 run 方法。
Note You can read the article "Working with Threads" to refresh your memory about how to create Java threads. 注意 您可以阅读文章“使用线程”以回顾如何创建Java线程。
The run method contains a while loop that does the following:
run方法包含一个循环,执行以下操作:
- Waits for HTTP requests
- Creates an instance of HttpProcessor for each request.
- Calls the process method of the HttpProcessor.
- 等待
HTTP请求 - 为每个请求创建一个
HttpProcessor实例。 - 调用
HttpProcessor的process方法。
Note The run method is similar to the await method of the HttpServer1 class in Chapter 2. 注意 run方法类似于第2章中的HttpServer1类的await方法。
You can see right away that the HttpConnector class is very similar to the ex02.pyrmont.HttpServer1 class, except that after a socket is obtained from the accept method of java.net.ServerSocket, an HttpProcessor instance is created and its process method is called, passing the socket.
您可以立即看到HttpConnector类与ex02.pyrmont.HttpServer1类非常相似,只是在从java.net.ServerSocket的accept方法获取套接字之后,会创建一个HttpProcessor实例并调用其process方法,传递套接字。
Note The HttpConnector class has another method calls getScheme, which returns the scheme (HTTP). 注意 HttpConnector类还有一个名为getScheme的方法,用于返回方案(HTTP)。
The HttpProcessor class's process method receives the socket from an incoming HTTP request. For each incoming HTTP request, it does the following:
注意 HttpConnector 类还有一个名为getScheme的方法,用于返回方案(HTTP)。
- Create an HttpRequest object.
- Create an HttpResponse object.
- Parse the HTTP request's first line and headers and populate the HttpRequest object.
- Pass the HttpRequest and HttpResponse objects to either a ServletProcessor or a StaticResourceProcessor. Like in Chapter 2, the ServletProcessor invokes the service method of the requested servlet and the StaticResourceProcessor sends the content of a static resource.
- 创建一个
HttpRequest对象。 - 创建一个
HttpResponse对象。 - 解析HTTP请求的第一行和标头,并填充HttpRequest对象。
- 将HttpRequest和HttpResponse对象传递给
ServletProcessor或StaticResourceProcessor。与第2章类似,ServletProcessor调用所请求servlet的service方法,而StaticResourceProcessor发送静态资源的内容。
The process method is given in Listing 3.3.
process 方法在3.3节中给出。
Listing 3.3: The HttpProcessor class's process method.
清单 3.3:HttpProcessor 类的 process 方法。
public void process(Socket socket) {
SocketInputStream input = null;
OutputStream output = null;
try {
input = new SocketInputStream(socket.getInputStream(), 2048);
output = socket.getOutputStream();
// create HttpRequest object and parse
request = new HttpRequest(input);
// create HttpResponse object
response = new HttpResponse(output);
response.setRequest(request);
response.setHeader("Server", "Pyrmont Servlet Container");
parseRequest(input, output);
parseHeaders(input);
//check if this is a request for a servlet or a static resource
//a request for a servlet begins with "/servlet/" if (request.getRequestURI().startsWith("/servlet/")) {
ServletProcessor processor = new ServletProcessor();
processor.process(request, response);
}
else {
StaticResourceProcessor processor = new
StaticResourceProcessor();
processor.process(request, response);
}
// Close the socket
socket.close();
// no shutdown for this application
}
catch (Exception e) {
e.printStackTrace ();
} }
The process method starts by obtaining the input stream and output stream of the socket. Note, however, in this method we use the SocketInputStream class that extends java.io.InputStream.
处理方法从获取套接字的输入流和输出流开始。请注意,在这个方法中,我们使用了扩展了java.io.InputStream的SocketInputStream类。
SocketInputStream input = null;
OutputStream output = null;
try {
input = new SocketInputStream(socket.getInputStream(), 2048);
output = socket.getOutputStream();
Then, it creates an HttpRequest instance and an HttpResponse instance and assigns
the HttpRequest to the HttpResponse.
// create HttpRequest object and parse
request = new HttpRequest(input);
// create HttpResponse object
response = new HttpResponse(output);
response.setRequest(request);
The HttpResponse class in this chapter's application is more sophisticated than the Response class in Chapter 2. For one, you can send headers to the client by calling its setHeader method.
本章应用中的HttpResponse类比第二章中的Response类更为复杂。首先,您可以通过调用其setHeader方法向客户端发送头部信息。
response.setHeader("Server", "Pyrmont Servlet Container");
Next, the process method calls two private methods in the HttpProcessor class for parsing the request.
接下来,process方法在HttpProcessor类中调用了两个私有方法来解析请求。
parseRequest(input, output);
parseHeaders (input);
Then, it hands off the HttpRequest and HttpResponse objects for processing to either a ServletProcessor or a StaticResourceProcessor, depending the URI pattern of the request.
然后,它将HttpRequest和HttpResponse对象交给ServletProcessor或StaticResourceProcessor进行处理,取决于请求的URI模式。
if (request.getRequestURI().startsWith("/servlet/")) {
ServletProcessor processor = new ServletProcessor();
processor.process(request, response);
}
else {
StaticResourceProcessor processor =
new StaticResourceProcessor();
processor.process(request, response);
}
Finally, it closes the socket.
最后,它会关闭套接字。
socket.close();
Note also that the HttpProcessor class uses the org.apache.catalina.util.StringManager class for sending error messages: 还请注意,HttpProcessor 类使用 org.apache.catalina.util.StringManager 类发送错误信息:
protected StringManager sm = StringManager.getManager("ex03.pyrmont.connector.http");
The private methods in the HttpProcessor class--parseRequest, parseHeaders, and normalize-- are called to help populate the HttpRequest. These methods will be discussed in the next section, "Creating an HttpRequest Object".
HttpProcessor类中的私有方法——parseRequest、parseHeaders和normalize——被调用来帮助填充HttpRequest对象。
这些方法将在下一节“创建HttpRequest对象”中进行讨论。
4Creating an HttpRequest Object(创建一个HttpRequest对象)
The HttpRequest class implements javax.servlet.http.HttpServletRequest. Accompanying it is a fa?ade class called HttpRequestFacade. Figure 3.2 shows the UML diagram of the HttpRequest class and its related classes.
HttpRequest类实现了javax.servlet.http.HttpServletRequest接口。与之相伴的是一个名为HttpRequestFacade的外观类。图3.2展示了HttpRequest类及其相关类的UML图。

Figure 3.2: The HttpRequest class and related classes
图3.2:HttpRequest类和相关类
Many of the methods in the HttpRequest class are left blank (you have to wait until Chapter 4 for a full implementation), but servlet programmers can already retrieve the headers, cookies and parameters of the incoming HTTP request. These three types of values are stored in the following reference variables:
HttpRequest 类中的许多方法都是空白的(完整的实现要等到第4章),但是 Servlet 程序员已经可以获取到传入HTTP请求的头部、Cookie和参数。这三种类型的值存储在以下引用变量中:
protected HashMap headers = new HashMap();
protected ArrayList cookies = new ArrayList();
protected ParameterMap parameters = null;
Note ParameterMap class will be explained in the section "Obtaining Parameters". 注意 ParameterMap类将在“获取参数”部分中进行解释。
Therefore, a servlet programmer can get the correct return values from the following methods in javax.servlet.http.HttpServletRequest:getCookies,getDateHeader, getHeader, getHeaderNames, getHeaders, getParameter, getPrameterMap, getParameterNames, and getParameterValues. Once you get headers, cookies, and parameters populated with the correct values, the implementation of the related methods are easy, as you can see in the HttpRequest class.
因此,Servlet程序员可以从javax.servlet.http.HttpServletRequest中的以下方法中获得正确的返回值:
- getCookies
- getDateHeader
- getHeader
- getHeaderNames
- getHeaders
- getParameter
- getParameterMap
- getParameterNames
- getParameterValues
一旦获取了正确的头部、Cookie和参数值,相关方法的实现就变得简单了,您可以在HttpRequest类中看到。
Needless to say, the main challenge here is to parse the HTTP request and populate the HttpRequest object. For headers and cookies, the HttpRequest class provides the addHeader and addCookie methods that are called from the parseHeaders method of HttpProcessor. Parameters are parsed when they are needed, using the HttpRequest class's parseParameters method. All methods are discussed in this section.
不用说,这里的主要挑战是解析HTTP请求并填充HttpRequest对象。对于头部和Cookie,HttpRequest类提供了addHeader和addCookie方法,这些方法从HttpProcessor的parseHeaders方法中调用。
参数在需要时进行解析,使用HttpRequest类的parseParameters方法。
所有方法都在本节中讨论。
Since HTTP request parsing is a rather complex task, this section is divided into the following subsections:
由于HTTP请求解析是一项相当复杂的任务,本节分为以下子节:
- Reading the socket's input stream
- Parsing the request line
- Parsing headers
- Parsing cookies
- Obtaining parameters
- 读取套接字的输入流
- 解析请求行
- 解析头部
- 解析Cookie
- 获取参数
1Reading the Socket's Input Stream(读取套接字的输入流)
In Chapters 1 and 2 you did a bit of request parsing in the ex01.pyrmont.HttpRequest and ex02.pyrmont.HttpRequest classes. You obtained the request line containing the method, the URI, and the HTTP version by invoking the read method of the java.io.InputStream class:
在第1章和第2章中,您在ex01.pyrmont.HttpRequest和ex02.pyrmont.HttpRequest类中进行了一些请求解析。
通过调用java.io.InputStream类的read方法,您可以获得包含方法、URI和HTTP版本的请求行:
byte[] buffer = new byte [2048];
try {
// input is the InputStream from the socket.
i = input.read(buffer);
}
You did not attempt to parse the request further for the two applications. In the application for this chapter, however, you have the ex03.pyrmont.connector.http.SocketInputStream class, a copy of org.apache.catalina.connector.http.SocketInputStream. This class provides methods for obtaining not only the request line, but also the request headers.
你没有进一步尝试解析这两个应用程序的请求。
然而,在本章的应用程序中,你有一个名为ex03.pyrmont.connector.http.SocketInputStream的类,它是org.apache.catalina.connector.http.SocketInputStream的一个副本。
这个类提供了获取请求行和请求头的方法。
You construct a SocketInputStream instance by passing an InputStream and an integer indicating the buffer size used in the instance. In this application, you create a SocketInputStream object in the process method of ex03.pyrmont.connector.http.HttpProcessor, as in the following code fragment:
你可以通过传递一个InputStream和一个表示实例中使用的缓冲区大小的整数来构造一个SocketInputStream实例。
在这个应用程序中,你在ex03.pyrmont.connector.http.HttpProcessor的process方法中创建了一个SocketInputStream对象,如下面的代码片段所示:
SocketInputStream input = null;
OutputStream output = null;
try {
input = new SocketInputStream(socket.getInputStream(), 2048);
...
As mentioned previously, the reason for having a SocketInputStream is for its two important methods: readRequestLine and readHeader. Read on.
如前所述,拥有SocketInputStream的原因是它具有两个重要的方法:readRequestLine和 readHeader。
请继续阅读。
2Parsing the Request Line(解析请求行)
The process method of HttpProcessor calls the private parseRequest method to parse the request line, i.e. the first line of an HTTP request. Here is an example of a request line:
HttpProcessor的 process 方法调用私有的parseRequest方法来解析请求行,即HTTP请求的第一行。以下是一个请求行的示例:
GET /myApp/ModernServlet?userName=tarzan&password=pwd HTTP/1.1
The second part of the request line is the URI plus an optional query string. In the example above, here is the URI:
请求行的第二部分是URI加上可选的查询字符串。在上面的例子中,这是URI:
/myApp/ModernServlet
And, anything after the question mark is the query string. Therefore the query string is the following:
而且,问号后面的任何内容都是查询字符串。因此,查询字符串如下:
userName=tarzan&password=pwd
The query string can contain zero or more parameters. In the example above, there are two parameter name/value pairs: userName/tarzan and password/pwd. In servlet/JSP programming, the parameter name jsessionid is used to carry a session identifier. Session identifiers are usually embedded as cookies, but the programmer can opt to embed the session identifiers in query strings, for example if the browser's support for cookies is being turned off.
查询字符串可以包含零个或多个参数。在上面的示例中,有两个参数名/值对:userName/tarzan和password/pwd。 在servlet/JSP编程中,参数名jsessionid用于携带会话标识符。
会话标识符通常嵌入在cookie中,但程序员可以选择将会话标识符嵌入在查询字符串中,例如如果浏览器的cookie支持被关闭。
When the parseRequest method is called from the HttpProcessor class's process method, the request variable points to an instance of HttpRequest. The parseRequest method parses the request line to obtain several values and assigns these values to the HttpRequest object. Now, let's take a close look at the parseRequest method in Listing 3.4.
当从HttpProcessor类的process方法调用parseRequest方法时,request变量指向HttpRequest的一个实例。parseRequest方法解析请求行以获取多个值,并将这些值分配给HttpRequest对象。
现在,让我们仔细看一下 HttpProcessor 类中的 parseRequest 方法,如清单3.4所示。
Listing 3.4: The parseRequest method in the HttpProcessor class
清单3.4:HttpProcessor 类中的 parseRequest 方法
private void parseRequest(SocketInputStream input, OutputStream output)
throws IOException, ServletException {
// Parse the incoming request line
input.readRequestLine(requestLine);
String method =
new String(requestLine.method, 0, requestLine.methodEnd);
String uri = null;
String protocol = new String(requestLine.protocol, 0,
requestLine.protocolEnd);
// Validate the incoming request line
if (method, length () < 1) {
throw new ServletException("Missing HTTP request method");
}
else if (requestLine.uriEnd < 1) {
throw new ServletException("Missing HTTP request URI");
}
// Parse any query parameters out of the request URI
int question = requestLine.indexOf("?");
if (question >= 0) {
request.setQueryString(new String(requestLine.uri, question + 1,
requestLine.uriEnd - question - 1));
uri = new String(requestLine.uri, 0, question);
}
else {
request.setQueryString(null);
uri = new String(requestLine.uri, 0, requestLine.uriEnd);
}
// Checking for an absolute URI (with the HTTP protocol)
if (!uri.startsWith("/")) {
int pos = uri.indexOf("://");
// Parsing out protocol and host name
if (pos != -1) {
pos = uri.indexOf('/', pos + 3);
if (pos == -1) {
uri = "";
}
else {
uri = uri.substring(pos);
}
}
}
// Parse any requested session ID out of the request URI
String match = ";jsessionid=";
int semicolon = uri.indexOf(match);
if (semicolon >= 0) {
String rest = uri.substring(semicolon + match,length());
int semicolon2 = rest.indexOf(';');
if (semicolon2 >= 0) {
request.setRequestedSessionId(rest.substring(0, semicolon2));
rest = rest.substring(semicolon2);
}
else {
request.setRequestedSessionId(rest);
rest = "";
}
request.setRequestedSessionURL(true);
uri = uri.substring(0, semicolon) + rest;
}
else {
request.setRequestedSessionId(null);
request.setRequestedSessionURL(false);
}
// Normalize URI (using String operations at the moment)
String normalizedUri = normalize(uri);
// Set the corresponding request properties
((HttpRequest) request).setMethod(method);
request.setProtocol(protocol);
if (normalizedUri != null) {
((HttpRequest) request).setRequestURI(normalizedUri);
}
else {
((HttpRequest) request).setRequestURI(uri);
}
if (normalizedUri == null) {
throw new ServletException("Invalid URI: " + uri + "'");
}
}
The parseRequest method starts by calling the SocketInputStream class's readRequestLine method:
parseRequest 方法首先调用 SocketInputStream 类的 readRequestLine 方法:
input.readRequestLine(requestLine);
where requestLine is an instance of HttpRequestLine inside HttpProcessor:
其中 requestLine 是 HttpProcessor 内的 HttpRequestLine 实例:
private HttpRequestLine requestLine = new HttpRequestLine();
Invoking its readRequestLine method tells the SocketInputStream to populate the HttpRequestLine instance.
调用 readRequestLine 方法会告诉 SocketInputStream 填充 HttpRequestLine 实例。
Next, the parseRequest method obtains the method, URI, and protocol of the request line:
接下来,parseRequest 方法会获取请求行的方法、URI 和协议:
String method =
new String(requestLine.method, 0, requestLine.methodEnd);
String uri = null;
String protocol = new String(requestLine.protocol, 0,
requestLine.protocolEnd);
However, there may be a query string after the URI. If present, the query string is separated by a question mark. Therefore, the parseRequest method attempts to first obtain the query string and populates the HttpRequest object by calling its setQueryString method:
不过,URI 后可能会有一个查询字符串。如果存在,查询字符串会以问号分隔。
因此,parseRequest 方法会尝试首先获取查询字符串,然后通过调用 setQueryString 方法填充 HttpRequest 对象:
// Parse any query parameters out of the request URI
int question = requestLine.indexOf("?");
if (question >= 0) { // there is a query string.
request.setQueryString(new String(requestLine.uri, question + 1,
requestLine.uriEnd - question - 1));
uri = new String(requestLine.uri, 0, question);
}
else {
request.setQueryString (null);
uri = new String(requestLine.uri, 0, requestLine.uriEnd);
}
However, while most often a URI points to a relative resource, a URI can also be an absolute value, such as the following:
不过,虽然 URI 通常指向相对资源,但 URI 也可以是一个绝对值,例如以下内容:
http://www.brainysoftware.com/index.html?name=Tarzan
The parseRequest method also checks this:
parseRequest 方法也会检查这一点:
// Checking for an absolute URI (with the HTTP protocol)
if (!uri.startsWith("/")) {
// not starting with /, this is an absolute URI
int pos = uri.indexOf("://");
// Parsing out protocol and host name
if (pos != -1) {
pos = uri.indexOf('/', pos + 3);
if (pos == -1) {
uri = "";
}
else {
uri = uri.substring(pos);
}
}
}
Then, the query string may also contain a session identifier, indicated by the jsessionid parameter name. Therefore, the parseRequest method checks for a session identifier too. If jsessionid is found in the query string, the method obtains the session identifier and assigns the value to the HttpRequest instance by calling its setRequestedSessionId method:
然后,查询字符串还可能包含一个会话标识符,由jsessionid参数名指示。
因此,parseRequest 方法也会检查会话标识符。如果在查询字符串中找到了 jsessionid,则该方法会获取会话标识符,并通过调用其 setRequestedSessionId 方法将该值分配给 HttpRequest 实例:
// Parse any requested session ID out of the request URI
String match = ";jsessionid=";
int semicolon = uri.indexOf(match);
if (semicolon >= 0) {
String rest = uri.substring(semicolon + match.length());
int semicolon2 = rest.indexOf(';');
if (semicolon2 >= 0) {
request.setRequestedSessionId(rest.substring(0, semicolon2));
rest = rest.substring(semicolon2);
}
else {
request.setRequestedSessionId(rest);
rest = "";
}
request.setRequestedSessionURL (true);
uri = uri.substring(0, semicolon) + rest;
}
else {
request.setRequestedSessionId(null);
request.setRequestedSessionURL(false);
}
If jsessionid is found, this also means that the session identifier is carried in the query string, and not in a cookie. Therefore, pass true to the request's setRequestSessionURL method. Otherwise, pass false to the setRequestSessionURL method and null to the setRequestedSessionURL method.
如果找到了 jsessionid,这也意味着会话标识符是通过查询字符串传递的,而不是通过 cookie 传递的。
因此,将true传递给请求的setRequestSessionURL方法。否则,将false传递给setRequestSessionURL方法,并将null传递给setRequestedSessionURL方法。
At this point, the value of uri has been stripped off the jsessionid.
此时,uri 的值已经去除了 jsessionid。
Then, the parseRequest method passes uri to the normalize method to correct an "abnormal" URI. For example, any occurrence of \ will be replaced by /. If uri is in good format or if the abnormality can be corrected, normalize returns the same URI or the corrected one. If the URI cannot be corrected, it will be considered invalid and normalize returns null. On such an occasion (normalize returning null), the parseRequest method will throw an exception at the end of the method.
然后,parseRequest 方法将 uri 传递给 normalize 方法,以纠正“异常”的URI。
例如,任何出现的\都将被替换为/。如果uri格式良好或者异常可以被纠正,normalize方法将返回相同的URI或者纠正后的URI。
如果URI无法被纠正,它将被视为无效,并且normalize方法将返回null。在这种情况下( normalize 返回null),parseRequest 方法将在方法的末尾抛出异常。
Finally, the parseRequest method sets some properties of the HttpRequest object:
最后,parseRequest 方法设置了 HttpReques 对象的一些属性:
((HttpRequest) request).setMethod(method);
request.setProtocol(protocol);
if (normalizedUri != null) {
((HttpRequest) request).setRequestURI(normalizedUri);
}
else {
((HttpRequest) request).setRequestURI(uri);
}
And, if the return value from the normalize method is null, the method throws an exception:
如果 normalize 方法的返回值为空,该方法就会抛出异常:
if (normalizedUri == null) {
throw new ServletException("Invalid URI: " + uri + "'");
}
3Parsing Headers(解析头部)
An HTTP header is represented by the HttpHeader class. This class will be explained in detail in Chapter 4, for now it is sufficient to know the following:
一个HTTP头由 HttpHeader 类表示。
这个类将在第4章中详细解释,目前只需知道以下内容即可:
- You can construct an HttpHeader instance by using its class's no-argument constructor.
- Once you have an HttpHeader instance, you can pass it to the readHeader method of SocketInputStream. If there is a header to read, the readHeader method will populate the HttpHeader object accordingly. If there is no more header to read, both nameEnd and valueEnd fields of the HttpHeaderinstance will be zero.
- To obtain the header name and value, use the following:
- String name = new String(header.name, 0, header.nameEnd);
- String value = new String(header.value, 0, header.valueEnd);
- 您可以使用该类的无参数构造函数构造一个
HttpHeader实例。 - 一旦您拥有了HttpHeader实例,您可以将其传递给SocketInputStream的readHeader方法。如果有要读取的头部,readHeader方法将相应地填充HttpHeader对象。如果没有更多的头部可读取,HttpHeader实例的nameEnd和valueEnd字段都将为零。
- 要获取头部的名称和值,请使用以下代码:
- String name = new String(header.name, 0, header.nameEnd);
- String value = new String(header.value, 0, header.valueEnd);
The parseHeaders method contains a while loop that keeps reading headers from the SocketInputStream until there is no more header. The loop starts by constructing an HttpHeader instance and passing it to the SocketInputStream class's readHeader:
parseHeaders 方法包含一个while循环,该循环会从 SocketInputStream 中不断读取头部,直到没有更多的头部可读取为止。循环从构造一个 HttpHeader 实例并将其传递给 SocketInputStream 类的 readHeader 方法开始。
HttpHeader header = new HttpHeader();
// Read the next header
input.readHeader(header);
Then, you can test whether or not there is a next header to be read from the input stream by testing the nameEnd and valueEnd fields of the HttpHeader instance:
然后,您可以通过测试 HttpHeader 实例的 nameEnd 和 valueEnd 字段来测试是否有下一个要从输入流中读取的标头:
if (header.nameEnd == 0) {
if (header.valueEnd == 0) {
return;
}
else {
throw new ServletException
(sm.getString("httpProcessor.parseHeaders.colon"));
}
}
If there is a next header, the header name and value can then be retrieved:
如果存在下一个标头,可以获取标头名称和值:
String name = new String(header.name, 0, header.nameEnd);
String value = new String(header.value, 0, header.valueEnd);
Once you get the header name and value, you add it to the headers HashMap in the HttpRequest object by calling its addHeader method:
一旦你获取到头部名称和值,你可以通过调用HttpRequest对象的 addHeader 方法将其添加到headers HashMap中。
request.addHeader(name, value);
Some headers also require the setting of some properties. For instance, the value of the content-length header is to be returned when the servlet calls the getContentLength method of javax.servlet.ServletRequest, and the cookie header contains cookies to be added to the cookie collection. Thus, here is some processing:
有些标头还需要设置一些属性。
例如,当servlet调用javax.servlet.ServletRequest的getContentLength方法时,需要返回content-length标头的值;
而cookie标头包含要添加到cookie集合中的cookie。因此,这里有一些处理过程:
if (name.equals("cookie")) {
... // process cookies here } else if (name.equals("content-length")) {
int n = -1;
try {
n = Integer.parseInt(value);
} catch (Exception e) {
throw new ServletException(sm.getString(
"httpProcessor.parseHeaders.contentLength"));
}
request.setContentLength(n);
} else if (name.equals("content-type")) {
request.setContentType(value);
}
Cookie parsing is discussed in the next section, Parsing Cookies.
Cookie 解析将在下一节 "解析 Cookie "中讨论。
4Parsing Cookies(解析 Cookie)
Cookies are sent by a browser as an HTTP request header. Such a header has the name "cookie" and the value is the cookie name/value pair(s). Here is an example of a cookie header containing two cookies: userName and password.
Cookies是由浏览器作为HTTP请求头发送的。
这样的请求头的名称是"cookie",其值是 cookie 的名称/值对。
下面是一个包含两个 cookie(userName 和 password)的 cookie 头的示例:
Cookie: userName=budi; password=pwd;
Cookie parsing is done using the parseCookieHeader method of the org.apache.catalina.util.RequestUtil class. This method accepts the cookie header and returns an array of javax.servlet.http.Cookie. The number of elements in the array is the same as the number of cookie name/value pairs in the header. The parseCookieHeader method is given in Listing 3.5.
使用org.apache.catalina.util.RequestUtil类的parseCookieHeader方法来解析cookie。该方法接受cookie头并返回一个javax.servlet.http.Cookie数组。数组中的元素数量与头中的cookie名称/值对数量相同。parseCookieHeader方法如下所示(见代码清单3.5):
Listing 3.5: The org.apache.catalina.util.RequestUtil class's parseCookieHeader method
代码清单3.5:org.apache.catalina.util.RequestUtil类的parseCookieHeader方法
public static Cookie[] parseCookieHeader(String header) {
if ((header == null) || (header.length 0 < 1) )
return (new Cookie[0]);
ArrayList cookies = new ArrayList();
while (header.length() > 0) {
int semicolon = header.indexOf(';');
if (semicolon < 0)
semicolon = header.length();
if (semicolon == 0)
break;
String token = header.substring(0, semicolon);
if (semicolon < header.length())
header = header.substring(semicolon + 1);
else header = "";
try {
int equals = token.indexOf('=');
if (equals > 0) {
String name = token.substring(0, equals).trim();
String value = token.substring(equals+1).trim();
cookies.add(new Cookie(name, value));
}
}
catch (Throwable e) {
;
}
}
return ((Cookie[]) cookies.toArray (new Cookie [cookies.size ()]));
}
And, here is the part of the HttpProcessor class's parseHeader method that processes the cookies:
这里是HttpProcessor类的parseHeader方法中处理cookie的部分:
else if (header.equals(DefaultHeaders.COOKIE_NAME)) {
Cookie cookies[] = RequestUtil.ParseCookieHeader (value);
for (int i = 0; i < cookies.length; i++) {
if (cookies[i].getName().equals("jsessionid")) {
// Override anything requested in the URL
if (!request.isRequestedSessionIdFromCookie()) {
// Accept only the first session id cookie
request.setRequestedSessionId(cookies[i].getValue());
request.setRequestedSessionCookie(true);
request.setRequestedSessionURL(false);
}
}
request.addCookie(cookies[i]);
}
}
5Obtaining Parameters(获取参数)
You don't parse the query string or HTTP request body to get parameters until the servlet needs to read one or all of them by calling the getParameter, getParameterMap, getParameterNames, or getParameterValues methods of javax.servlet.http.HttpServletRequest. Therefore, the implementations of these four methods in HttpRequest always start with a call to the parseParameter method
直到servlet需要通过调用javax.servlet.http.HttpServletRequest的getParameter、 getParameterMap 、getParameterNames 或 getParameterValues 方法来读取一个或所有参数,你才会解析查询字符串或HTTP请求体以获取参数。
因此,HttpRequest中这四个方法的实现总是以调用parseParameter方法开始。
The parameters only needs to be parsed once and may only be parsed once because if the parameters are to be found in the request body, parameter parsing causes the SocketInputStream to reach the end of its byte stream. The HttpRequest class employs a boolean called parsed to indicate whether or not parsing has been done.
参数只需要解析一次,并且只能解析一次,因为如果参数在请求体中被找到,参数解析会导致SocketInputStream达到其字节流的末尾。
HttpRequest类使用一个名为parsed的布尔值来指示是否已经进行了解析。
Parameters can be found in the query string or in the request body. If the user requested the servlet using the GET method, all parameters are on the query string. If the POST method is used, you may find some in the request body too. All the name/value pairs are stored in a HashMap. Servlet programmers can obtain the parameters as a Map (by calling getParameterMap of HttpServletRequest) and the parameter name/value. There is a catch, though. Servlet programmers are not allowed to change parameter values. Therefore, a special HashMap is used: org.apache.catalina.util.ParameterMap.
参数可以在查询字符串或请求体中找到。
如果用户使用GET方法请求servlet,则所有参数都在查询字符串中。
如果使用POST方法,则可能在请求体中也可以找到一些参数。
所有的名称/值对都存储在一个HashMap中。
Servlet程序员可以通过调用HttpServletRequest的getParameterMap方法以Map的形式获取参数,并获取参数的名称/值。
不过,有一个限制,Servlet程序员不允许更改参数值。因此,使用了一个特殊的HashMap:org.apache.catalina.util.ParameterMap。
The ParameterMap class extends java.util.HashMap and employs a boolean called locked. The name/value pairs can only be added, updated or removed if locked is false. Otherwise, an IllegalStateException is thrown. Reading the values, however, can be done any time. The ParameterMap class is given in Listing 3.6. It overrides the methods for adding, updating and removing values. Those methods can only be called when locked is false.
ParameterMap类扩展了java.util.HashMap,并使用了一个名为locked的布尔值。
只有当locked为false时,才能添加、更新或删除名称/值对。
否则,将抛出IllegalStateException异常。
然而,可以随时进行值的读取。
ParameterMap类在3.6节中给出。
它重写了添加、更新和删除值的方法。这些方法只能在locked为false时调用。
Listing 3.6: The org.apache.Catalina.util.ParameterMap class.
3.6节:org.apache.Catalina.util.ParameterMap类。
package org.apache.catalina.util;
import java.util.HashMap;
import java.util.Map;
public final class ParameterMap extends HashMap {
public ParameterMap() {
super ();
}
public ParameterMap(int initialCapacity) {
super(initialCapacity);
}
public ParameterMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
}
public ParameterMap(Map map) {
super(map);
}
private boolean locked = false;
public boolean isLocked() {
return (this.locked);
}
public void setLocked(boolean locked) {
this.locked = locked;
}
private static final StringManager sm =
StringManager.getManager("org.apache.catalina.util");
public void clear() {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
super.clear();
}
public Object put(Object key, Object value) {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
return (super.put(key, value));
}
public void putAll(Map map) {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
super.putAll(map);
}
public Object remove(Object key) {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
return (super.remove(key));
}
}
Now, let's see how the parseParameters method works.
现在,让我们来看看parseParameters方法是如何工作的。
Because parameters can exist in the query string and or the HTTP request body, the parseParameters method checks both the query string and the request body. Once parsed, parameters can be found in the object variable parameters, so the method starts by checking the parsedboolean, which is true if parsing has been done before.
由于参数可以存在于查询字符串和/或HTTP请求体中,parseParameters方法会同时检查查询字符串和请求体。
一旦解析完成,参数可以在对象变量parameters中找到,所以该方法首先检查parsedboolean的值,如果解析已经完成,则其值为true。
if (parsed)
return;
Then, the parseParameters method creates a ParameterMap called results and points it to parameters. It creates a new ParameterMap if parameters is null.
然后,parseParameters方法创建了一个名为results的ParameterMap,并将其指向parameters。如果parameters为null,则创建一个新的ParameterMap。
ParameterMap results = parameters;
if (results == null)
results = new ParameterMap();
Then, the parseParameters method opens the parameterMap's lock to enable writing to it.
然后,parseParameters 方法打开 parameterMap 的锁以使其可写入。
results.setLocked(false);
Next, the parseParameters method checks the encoding and assigns a default encoding if the encoding is null.
接下来,parseParameters方法会检查编码,并在编码为null时分配一个默认编码。
String encoding = getCharacterEncoding();
if (encoding == null)
encoding = "ISO-8859-1";
Then, the parseParameters method tries the query string. Parsing parameters is done using the parseParameters method of org.apache.Catalina.util.RequestUtil.
然后,parseParameters方法尝试解析查询字符串。
解析参数是通过org.apache.Catalina.util.RequestUtil的parseParameters方法完成的。
// Parse any parameters specified in the query string
String queryString = getQueryString();
try {
RequestUtil.parseParameters(results, queryString, encoding);
}
catch (UnsupportedEncodingException e) {
;
}
Next, the method tries to see if the HTTP request body contains parameters. This happens if the user sends the request using the POST method, the content length is greater than zero, and the content type is application/x-www-form-urlencoded. So, here is the code that parses the request body.
接下来,该方法尝试查看HTTP请求体是否包含参数。
这种情况发生在用户使用POST方法发送请求时,内容长度大于零且内容类型为application/x-www-form-urlencoded。
因此,以下是解析请求体的代码。
// Parse any parameters specified in the input stream
String contentType = getContentType();
if (contentType == null)
contentType = "";
int semicolon = contentType.indexOf(';');
if (semicolon >= 0) {
contentType = contentType.substring (0, semicolon).trim();
}
else {
contentType = contentType.trim();
}
if ("POST".equals(getMethod()) && (getContentLength() > 0)
&& "application/x-www-form-urlencoded".equals(contentType)) {
try {
int max = getContentLength();
int len = 0;
byte buf[] = new byte[getContentLength()];
ServletInputStream is = getInputStream();
while (len < max) {
int next = is.read(buf, len, max - len);
if (next < 0 ) {
break;
}
len += next;
}
is.close();
if (len < max) {
throw new RuntimeException("Content length mismatch");
}
RequestUtil.parseParameters(results, buf, encoding);
}
catch (UnsupportedEncodingException ue) {
;
}
catch (IOException e) {
throw new RuntimeException("Content read fail");
}
}
Finally, the parseParameters method locks the ParameterMap back, sets parsed to true and assigns results to parameters.
最后,parseParameters方法将ParameterMap重新锁定,将parsed设置为true,并将结果赋值给parameters。
// Store the final results
results.setLocked(true);
parsed = true;
parameters = results;
6Creating a HttpResponse Object(创建一个HttpResponse对象)
The HttpResponse class implements javax.servlet.http.HttpServletResponse. Accompanying it is a fa?ade class named HttpResponseFacade. Figure 3.3 shows the UML diagram of HttpResponse and its related classes.
HttpResponse类实现了javax.servlet.http.HttpServletResponse接口。
与之相伴的是一个名为HttpResponseFacade的外观类。
图3.3显示了HttpResponse及其相关类的UML图。

Figure 3.3: The HttpResponse class and related classes
Figure 3.3: The HttpResponse class and related classes
图3.3:HttpResponse类及相关类
In Chapter 2, you worked with an HttpResponse class that was only partially functional. For example, its getWriter method returned a java.io.PrintWriter object that does not flush automatically when one of its print methods is called. The application in this chapter fixes this problem. To understand how it is fixed, you need to know what a Writer is.
在第2章中,您使用的HttpResponse类只是部分功能可用。
例如,它的getWriter方法返回一个java.io.PrintWriter对象,当调用其print方法之一时,它不会自动刷新。
本章的应用程序解决了这个问题。要理解如何解决它,您需要了解什么是Writer。
From inside a servlet, you use a PrintWriter to write characters. You may use any encoding you desire, however the characters will be sent to the browser as byte streams. Therefore, it's not surprising that in Chapter 2, the ex02.pyrmont.HttpResponse class has the following getWriter method:
从servlet内部,您可以使用PrintWriter来写入字符。
您可以使用任何编码,但字符将作为字节流发送到浏览器。
因此,在第2章中,ex02.pyrmont.HttpResponse类具有以下getWriter方法,
这一点并不令人意外:
public PrintWriter getWriter() {
// if autoflush is true, println() will flush,
// but print() will not.
// the output argument is an OutputStream
writer = new PrintWriter(output, true);
return writer;
}
See, how we construct a PrintWriter object? By passing an instance of java.io.OutputStream. Anything you pass to the print or println methods of PrintWriter will be translated into byte streams that will be sent through the underlying OutputStream.
看到了吗,我们是如何构建PrintWriter对象的?
通过传递一个java.io.OutputStream的实例。
无论您将什么传递给PrintWriter的print或println方法,都会被转换为字节流,并通过底层的OutputStream发送。
In this chapter you use an instance of the ex03.pyrmont.connector.ResponseStream class as the OutputStream for the PrintWriter. Note that the ResponseStream class is indirectly derived from the java.io.OutputStream class.
在本章中,您使用ex03.pyrmont.connector.ResponseStream类的实例作为PrintWriter的OutputStream。
请注意,ResponseStream类是间接继承自java.io.OutputStream类的。
You also have the ex03.pyrmont.connector.ResponseWriter class that extends the PrintWriter class. The ResponseWriter class overrides all the print and println methods and makes any call to these methods automatically flush the output to the underlying OutputStream. Therefore, we use a ResponseWriter instance with an underlying ResponseStream object.
您还有一个扩展PrintWriter类的ex03.pyrmont.connector.ResponseWriter类。
ResponseWriter类重写了所有的print和println方法,并使对这些方法的任何调用自动将输出刷新到底层的OutputStream。
因此,我们使用一个ResponseWriter实例和一个底层的ResponseStream对象。
We could instantiate the ResponseWriter class by passing an instance of ResponseStream object. However, we use a java.io.OutputStreamWriter object to serve as a bridge between the ResponseWriter object and the ResponseStream object.
我们可以通过传递一个ResponseStream对象的实例来实例化ResponseWriter类。
然而,我们使用一个java.io.OutputStreamWriter对象作为ResponseWriter对象和ResponseStream对象之间的桥梁。
With an OutputStreamWriter, characters written to it are encoded into bytes using a specified charset. The charset that it uses may be specified by name or may be given explicitly, or the platform's default charset may be accepted. Each invocation of a write method causes the encoding converter to be invoked on the given character(s). The resulting bytes are accumulated in a buffer before being written to the underlying output stream. The size of this buffer may be specified, but by default it is large enough for most purposes. Note that the characters passed to the write methods are not buffered.
使用OutputStreamWriter,写入到它的字符将使用指定的字符集编码为字节。
它使用的字符集可以通过名称指定,也可以明确给出,或者可以接受平台的默认字符集。
每个写入方法的调用都会导致编码转换器对给定的字符进行转换。
转换后的字节在写入底层输出流之前会累积在缓冲区中。
这个缓冲区的大小可以指定,但默认情况下对大多数情况来说已经足够大了。
请注意,传递给写入方法的字符不会被缓冲。
Therefore, here is the getWriter method:
因此,这是getWriter方法:
public PrintWriter getWriter() throws IOException {
ResponseStream newStream = new ResponseStream(this);
newStream.setCommit(false);
OutputStreamWriter osr =
new OutputStreamWriter(newStream, getCharacterEncoding());
writer = new ResponseWriter(osr);
return writer;
}
7Static Resource Processor and Servlet Processor(静态资源处理器和Servlet处理器)
The ServletProcessor class is similar to the ex02.pyrmont.ServletProcessor class in Chapter 2. They both have only one method: process. However, the process method in ex03.pyrmont.connector.ServletProcessor accepts an HttpRequest and an HttpResponse, instead of instances of Request and Response. Here is the signature of the process method in this chapter's application:
ServletProcessor类与第2章的ex02.pyrmont.ServletProcessor类相似。
它们都只有一个方法:process。
然而,在本章中,ex03.pyrmont.connector.ServletProcessor的process方法接受一个HttpRequest和一个HttpResponse,而不是Request和Response的实例。
以下是本章应用程序中process方法的签名:
public void process(HttpRequest reques%% %%t, HttpResponse response) {
In addition, the process method uses HttpRequestFacade and HttpResponseFacade as facade classes for the request and the response. Also, it calls the HttpResponse class's finishResponse method after calling the servlet's service method.
此外,该过程方法使用HttpRequestFacade和HttpResponseFacade作为请求和响应的外观类。
此外,它在调用servlet的service方法之后调用HttpResponse类的finishResponse方法。
servlet = (Servlet) myClass.newInstance();
HttpRequestFacade requestPacade = new HttpRequestFacade(request);
HttpResponseFacade responseFacade = new
HttpResponseFacade(response);
servlet.service(requestFacade, responseFacade);
((HttpResponse) response).finishResponse();
The StaticResourceProcessor class is almost identical to the ex02.pyrmont.StaticResourceProcessor class.
StaticResourceProcessor类几乎与ex02.pyrmont.StaticResourceProcessor类完全相同。
Part1Running the Application
To run the application in Windows, from the working directory, type the following:
要在 Windows 中运行应用程序,请在工作目录中键入以下内容:
java -classpath ./lib/servlet.jar;./ ex03.pyrmont.startup.Bootstrap
In Linux, you use a colon to separate two libraries.
在 Linux 中,使用冒号分隔两个库。
java -classpath ./lib/servlet.jar:./ ex03.pyrmont.startup.Bootstrap
To display index.html, use the following URL:
要显示 index.html,请使用以下 URL:
http://localhost:808O/index.html
To invoke PrimitiveServlet, direct your browser to the following URL:
http://localhost:8080/servlet/PrimitiveServlet
You'll see the following on your browser:
您将在浏览器上看到以下内容:
Hello. Roses are red.
Violets are blue.
Note Running PrimitiveServlet in Chapter 2 did not give you the second line.
请注意,在第 2 章中运行 PrimitiveServlet 并不会显示第二行。
You can also call ModernServet, which would not run in the servlet containers in
你还可以调用 ModernServet,它不会在第 2 章中的 servlet 容器中运行。
Chapter 2. Here is the URL:
第 2 章中的 servlet 容器中运行。下面是 URL:
http://localhost:8080/servlet/ModernServlet
Note The source code for ModernServlet can be found in the webroot directory under
注释 ModernServlet 的源代码可在工作目录下的 webroot 目录中找到。
the working directory.
工作目录下的 webroot 目录中。
You can append a query string to the URL to test the servlet. Figure 3.4 shows the
您可以向 URL 附加查询字符串来测试 servlet。图 3.4 显示了
result if you run ModernServlet with the following URL.
运行 ModernServlet 的结果。
http://localhost:8080/servlet/ModernServlet?userName=tarzan&password=pwd
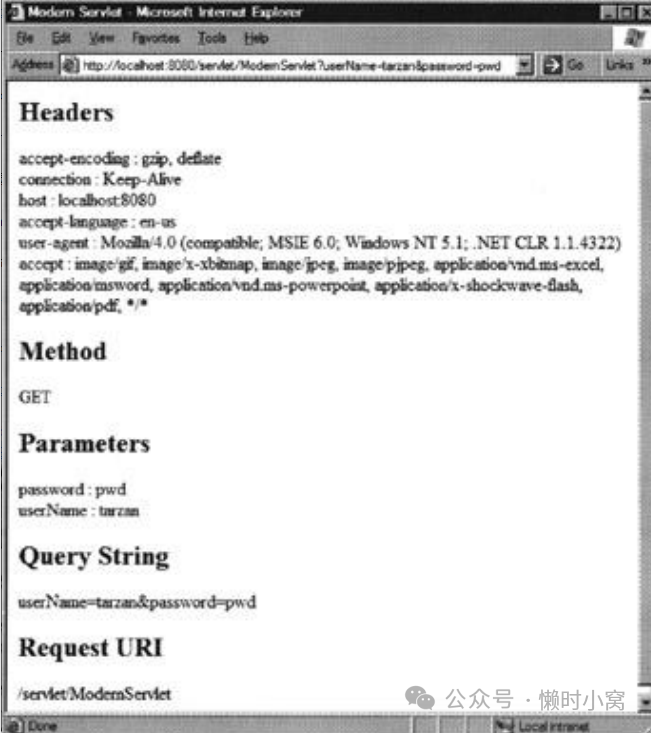
Figure 3.4: Running ModernServlet
图 3.4: 运行 ModernServlet
Part2Summary
In this chapter you have learned how connectors work. The connector built is a simplified version of the default connector in Tomcat 4. As you know, the default connector has been deprecated because it is not efficient. For example, all HTTP request headers are parsed, even though they might not be used in the servlet. As a result, the default connector is slow and has been replaced by Coyote, a faster connector, whose source code can be downloaded from the Apache Software Foundation's web site. The default connector, nevertheless, serves as a good learning tool and will be discussed in detail in Chapter 4.
在本章中,您已经学习了连接器的工作原理。
构建的连接器是Tomcat 4中默认连接器的简化版本。
正如您所知,由于其效率不高,因此默认连接器已被弃用。
例如,即使在servlet中可能不使用它们,所有的HTTP请求头都会被解析。
因此,默认连接器速度较慢,并已被名为Coyote的更快连接器取代,其源代码可以从Apache软件基金会的网站下载。
然而,默认连接器作为一个很好的学习工具,在第四章中将会详细讨论。