机器算法|线性回归、逻辑回归、随机森林等介绍、实现、实例
原创机器算法|线性回归、逻辑回归、随机森林等介绍、实现、实例
原创
引言
2023年人工智能的发展取得了令人瞩目的成就,不仅在技术层面取得了重大突破,也在产业应用方面展现出广阔的前景。人工智能在深度学习、自动驾驶、自然语言处理等领域取得了重大突破。在人工智能领域,机器学习是一个必不可少的核心,而机器学习又离不开算法。
什么是机器学习
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 ——来自百度百科。
在人工智能领域,机器学习是它的核心,是使计算机具有智能的根本途径。我们通常讲的机器算法、机器学习、机器学习算法都是同一个概念(Machine Learning),是计算机科学中的一个领域,它研究的最终目的如何从数据中学习并做出预测或决策。有许多不同类型的机器学习算法,包括线性回归、决策树、支持向量机、神经网络等。这些算法可以从数据中提取模式,并使用这些模式进行预测或分类。

机器算法有哪些
机器学习算法总体上来说,基于学习分类上可以分为三大类:监督学习、无监督学习、强化学习。基于数据形式上又可以分为两大类:结构化和非结构化。
而基本的机器学习算法大体有如下几种,其中线性回归算法、逻辑回归算法、随机森林算法为本篇重点讲解:
- 线性回归算法 (Linear Regression)
- 支持向量机算法 (Support Vector Machine,SVM)
- 最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
- 逻辑回归算法 (Logistic Regression)
- 决策树算法 (Decision Tree)
- k-平均算法 (K-Means)
- 随机森林算法 (Random Forest)
- 朴素贝叶斯算法 (Naive Bayes)
- 降维算法 (Dimensional Reduction)
- 梯度增强算法 (Gradient Boosting)

机器算法实践
Scikit-learn(以前称为scikits.learn,也称为sklearn)是针对Python 编程语言的免费软件机器学习库。所以本篇以学习为目的,简单讲解下线性回归、逻辑回归以及随机森林,有不到之处还望给予指正。
1 线性回归
1.1 线性回归简介
线性回归是一种基本的回归分析,用于预测一个因变量(目标变量)基于一个或多个自变量(特征)的值。在Python中,我们可以使用scikit-learn库中的LinearRegression类进行线性回归。线性回归算法(Linear Regression)的建模过程就是使用数据点来寻找最佳拟合线。公式,y = mx + c,其中 y 是因变量,x 是自变量,利用给定的数据集求 m 和 c 的值。
线性回归又分为两种类型,即 简单线性回归(simple linear regression)和多变量回归(multiple regression)。
- 简单线性回归(simple linear regression):只有 1 个自变量;
- 多变量回归(multiple regression):至少两组以上自变量。
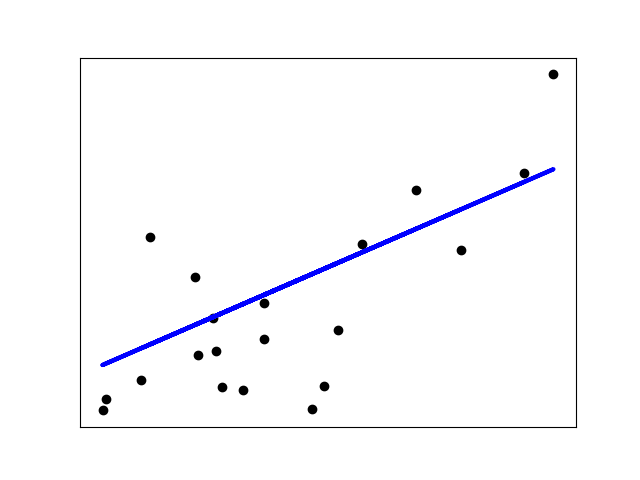
1.2 线性回归实现逻辑
下面跟着我一起学习下线性回归吧
- 导入所需的库(此处的依赖库使用到了
scikit-learn,暂时先这样子处理) - 创建一些样本数据 (此处可以读取文本或者数据库,由于限制,此处使用样例数据)
- 训练数据和测试数据
- 创建线性回归模型对象
- 使用训练数据拟合模型
- 使用模型进行预测
- 输出预测结果和实际结果的比较
1.3 线性回归代码示例
下面是一个简单的线性回归的示例
# 导入所需的库(暂时解决办法)
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "scikit-learn"])
# 导入所需的库
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
# 创建一些样本数据
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型对象
model = LinearRegression()
# 使用训练数据拟合模型
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
# 输出预测结果和实际结果的比较
print("预测值:", y_pred)
print("实际值:", y_test)
print("均方误差:", metrics.mean_squared_error(y_test, y_pred))2 逻辑回归
2.1 逻辑回归简介
逻辑回归是另一种从统计领域借鉴而来的机器学习算法,与线性回归相同,不同的是线性回归是一个开放的值,而逻辑回归更像是做一道是或不是的判断题,在二分问题上是首选方法。其次逻辑回归模型是监督分类算法族的成员之一,它的目的是找出每个输入变量的对应参数值。预测输出所用的变换是一个被称作 logistic 函数的非线性函数,Logistic 回归通过使用逻辑函数估计概率来测量因变量和自变量之间的关系。
逻辑函数中Y值的范围从 0 到 1,是一个概率值。逻辑函数通常呈S 型,曲线把图表分成两块区域,因此适合用于分类任务。 它可以用公式表示为:
Y = E ^(b0+b1 x)/(1 + E ^(b0+b1 x ))

2.2 逻辑回归实现逻辑
下面跟着我一起学习下逻辑回归吧
- 导入所需的库(此处的依赖库使用到了
scikit-learn,暂时先这样子处理) - 获取一些样本数据 (此处可以读取文本或者数据库,由于限制,此处使用第三方库自带的样本数据)
- 训练数据和测试数据
- 创建逻辑回归模型对象
- 使用训练数据拟合模型
- 使用模型进行预测
- 输出预测结果和实际结果的比较
2.3 逻辑回归代码示例
下面是一个简单的逻辑回归的示例
# 导入所需的库(暂时解决办法)
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "scikit-learn"])
# 导入所需的库
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.datasets import load_iris
# 获取样本数据,此处使用scikit-learn库自带数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.9, random_state=50)
# 创建逻辑回归模型对象
model = LogisticRegression()
# 使用训练数据拟合模型
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
# 输出预测结果和实际结果的比较
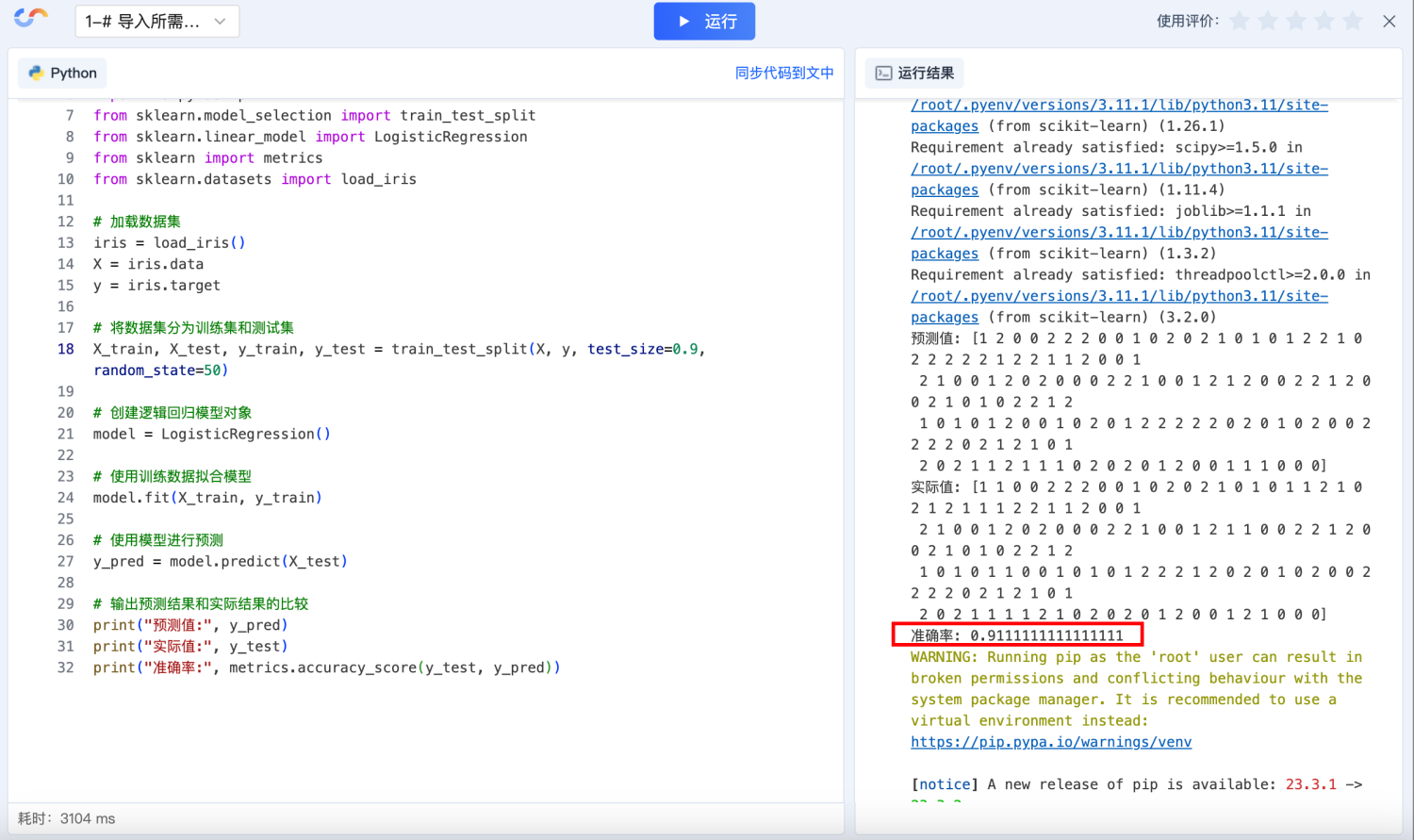
print("预测值:", y_pred)
print("实际值:", y_test)
print("准确率:", metrics.accuracy_score(y_test, y_pred))预测结果的准确度:
3 随机森林
3.1 随机森林简介
如果你把一堆树放在一起,你就得到了一片森林。我感觉这是对「随机森林算法」最好的解释。随机森林是一种集成学习算法,它通过构建多个决策树并综合它们的预测结果来提高预测精度。决策树是机器学习预测建模的一类重要算法,可以用二叉树来解释决策树模型。除了决策树,他还可以同支持向量机、朴素贝叶斯、神经网络等算法结合,来提高准确度。
- 优点:特征选择、鲁棒性、可解释性、预测精度提升
- 缺点:容易过拟合、参数敏感度高(包括对不平衡数据集处理不佳、对缺失值和无限值敏感)
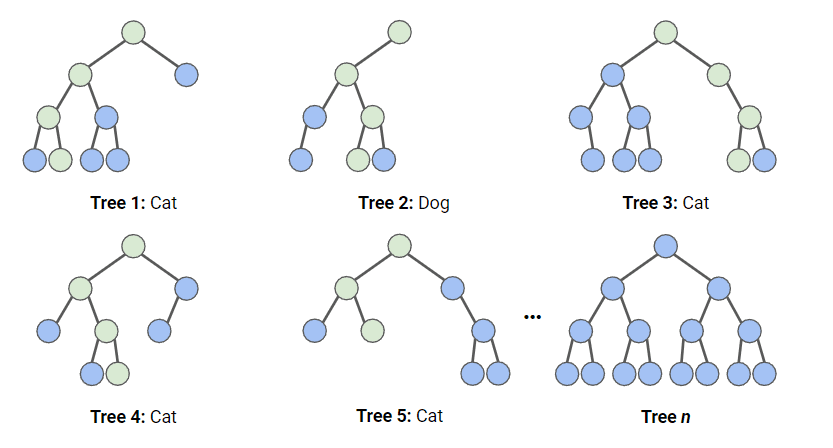
3.2 随机森林实现逻辑
1、生成随机数据集:随机森林采用自助法(bootstrap)从原始数据集中随机抽取样本生成新的训练数据集。每次抽取时都会从原始数据集中有放回地随机选择一定数量的样本,这样可以保证原始数据集中的样本可能会被多次抽取到。
2、构建决策树:在每个训练数据集上,使用决策树算法(如ID3、C4.5等)构建一棵决策树。在构建决策树时,对于每个节点分裂,只考虑随机选取的一部分特征,而不是考虑所有的特征。这样可以增加模型的多样性,提高集成学习的效果。
3、集成决策树:将所有构建好的决策树的结果进行综合。对于分类问题,可以采用投票的方式,即多数投票原则,选择获得票数最多的类别作为最终的分类结果;对于回归问题,则可以将所有决策树的预测结果进行平均或取最大值、最小值等操作得到最终的预测结果。
3.3 随机森林代码示例
# 导入所需的库
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "scikit-learn"])
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 获取样本数据,此处使用scikit-learn库自带数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.7, random_state=80)
# 创建随机森林分类器对象
clf = RandomForestClassifier(n_estimators=100, max_depth=4, random_state=80)
# 使用训练数据拟合模型
clf.fit(X_train, y_train)
# 使用模型进行预测
y_pred = clf.predict(X_test)
# 输出预测结果和实际结果的比较
print("预测值:", y_pred)
print("实际值:", y_test)
print("准确率:", accuracy_score(y_test, y_pred))预测结果的准确度:

写在最后
本文介绍了什么是线性回归、逻辑回归、随机森林以及已经如何在Python中实现,可以利用pandas对数据进行处理,pandas直观高效的处理数据,并且可以与scikit-learn, statsmodels库实现无缝衔接。
线性回归可以通过两种方式实现:
- scikit-learn:如果不需要回归模型的详细结果,用sklearn库是比较合适的。
- statsmodels:用于获取回归模型详细统计结果。两个库都可以做进一步的探索。
更详细的使用方法可以参考相关官方文档。
最后在这里非常感谢群里的大佬给予本篇很多帮助:努力的小雨、花花@Binki、以及虫无涯大佬,感谢工作人员。
[参考引用]
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。