Depth Anything | 致敬SAM,港大&字节提出用于任意图像的深度估计大模型,已开源!
Depth Anything | 致敬SAM,港大&字节提出用于任意图像的深度估计大模型,已开源!


https://arxiv.org/abs/2401.10891 https://github.com/LiheYoung/Depth-Anything https://depth-anything.github.io/
本文提出一种用于单目深度估计(Monocular Depth Estimation, MDE)的高度实用方案Depth Anything「致敬Segment Anything」,它旨在构建一种可以处理任务环境下任意图像的简单且强力的基础深度模型。为此,作者从三个维度进行了探索:
- 数据集维度,设计了一种数据引擎用于数据收集与自动标注,构建了~62M的大规模无标注数据,这极大程度提升了数据覆盖率、降低泛化误差;
- 通过利用数据增广工具构建了一种更具挑战性的优化目标,促使模型主动探索额外的视觉知识,进而提升特征鲁棒性;
- 设计了一种辅助监督信息以迫使模型从预训练Encoder中继承丰富语义先验信息。
作者在六个公开数据集与随机拍摄图片上评估了模型的zero-shot能力;通过度量深度信息微调达成新的SOTA;更优的深度模型进而引申出更优的深度引导ControlNet。更多Demo示例建议前往该项目主页:https://depth-anything.github.io

本文方案
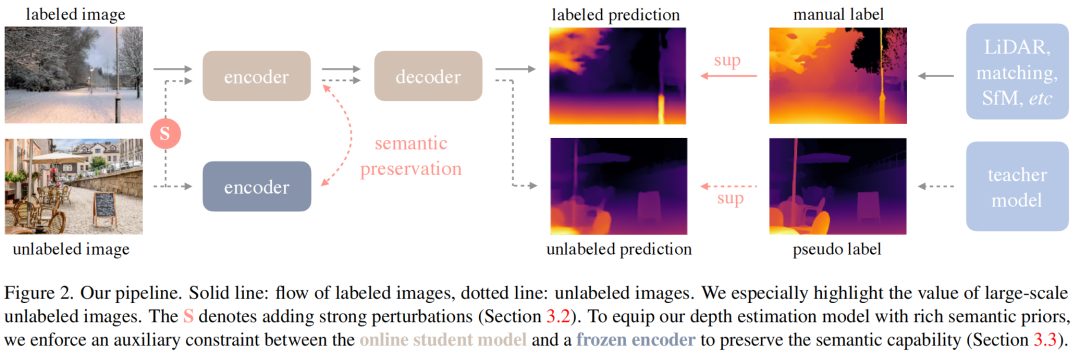
上图给出了所提方案架构图,本文采用有标签与无标签图像训练更优的单目深度估计。假设
分别表示有标签与无标签数据集。
- 首先,基于数据集
学习一个老师模型T;
- 然后,利用T为数据集
赋予伪标签;
- 最后,基于两个数据训练一个学生模型S。
大规模数据集
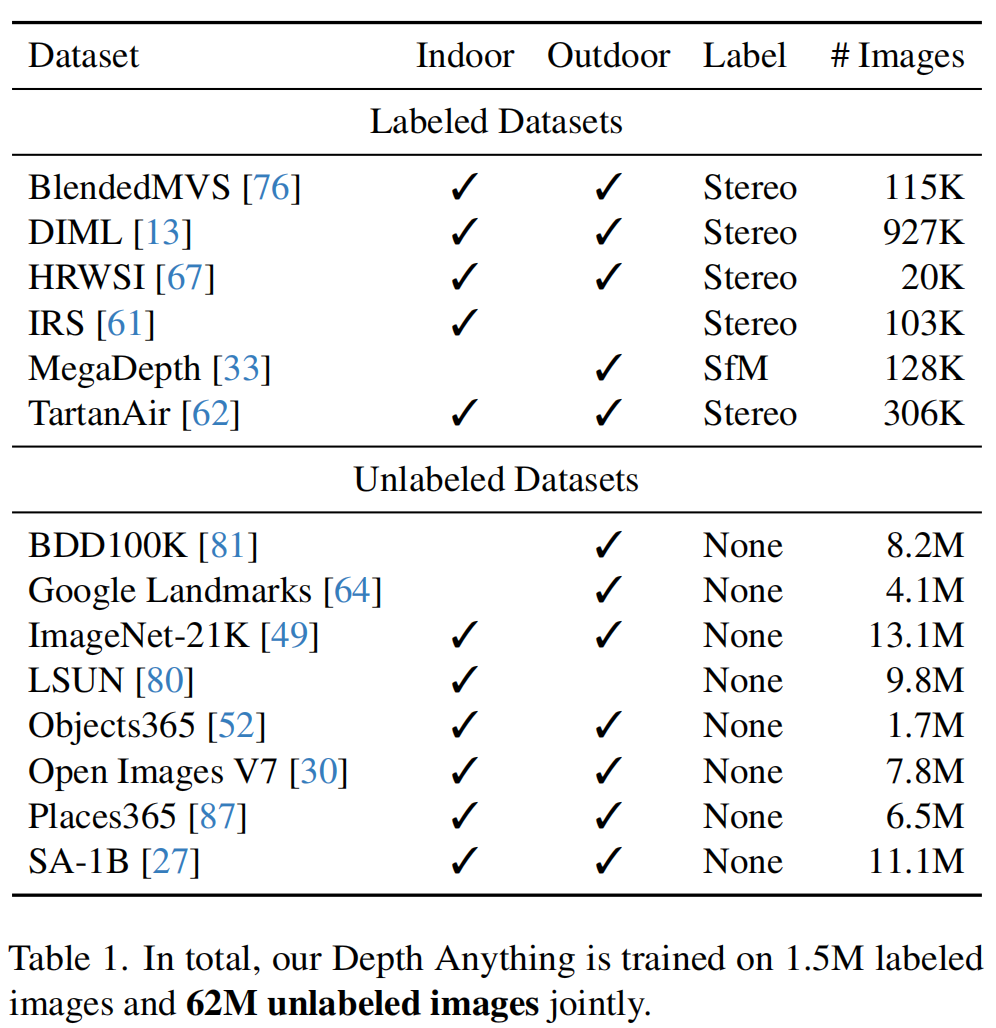
上表给出了本文所构建的有标签与无标签数据集,相比于MiDaS v3.1,该方案使用的有标签数据集更少(6 vs 12)。
- 未用NYUv2与KITTI以确保zero-shot评估;
- Movies与WSVD不再可获取;
- 某些数据质量比较差,如RedWeb;
尽管实用了更少的有标签数据,但更易获取且多样性的无标签数据足以补偿数据覆盖率并极大提升模型的泛化能力与鲁棒性。此外,为进一步增强老师模型,作者采用DINOv2预训练权值进行初始化。
释放无标签数据的能量
受益于互联网的发展,我们可以比较容易的构建一个多样性的大规模无标签数据集,同时也可以借助于预训练MDE模型为这些无标签图像生成稠密深度图。这要比立体匹配、SfM重建更方便且高效。
给定预训练MDE老师模型T,我们可以将无标签数据集
转换为伪标签数据集
:
基于组合数据
,我们就可以训练学生模型S咯~但是,不幸的是:通过上述自训练方案,我们难以取得性能改善。
作者猜想:当有足够的有标签数据后,从无标签数据中获取的额外知识相当受限。针对此,作者为学生模型制定了更难的优化目标以从额外无标签数据中学习额外的视觉知识。
在训练过程中,作者为无标签数据注入强扰动,这种处理有助于学生模型主动探寻额外的视觉知识并从中学习不变性表征。在具体实现方面,主要有以下两种扰动:
- 强色彩失真,包含颜色抖动、高斯模糊;
- 强空域畸变,如CutMix。
尽管上述操作比较简单,但它们有助于大规模无标签数据大幅改善有标签图像的基线。
语义辅助感知
尽管已有一些研究通过语义分割任务辅助改善深度估计模型性能,但不幸的是:经过尝试,RAM+GroundDINO+HQ-SAM组合方案无法进一步提升原始MDE模型的性能。
作者推测:将图像解码到离散类别空间会损失太多寓意信息,这些语义Mask带有的有限信息难以进一步提升深度模型性能(尤其是该模型已经极具竞争力)。
因此,作者从DINOv2方案中探寻更强语义信息以辅助监督该深度估计任务,即将DINOv2强语义能力通过辅助特征对齐损失方式迁移到所提深度模型中。损失函数定义如下:
特征对齐的一个关键在于:DINOv2的语义编码器倾向于为同一目标不同部件生成相似特征。但是,在深度估计中,不同部件可能具有不同的深度。因此,没有必要要求深度模型生成与冻结编码器严格相同的特征。
为解决该问题,作者为特征对齐设置了一个冗差参数
:当
之间的相似度高于该阈值时,该像素不被包含在上述损失中。这就使得该方案同时具备DINOv2的语义感知表征与深度监督的部件判别表征能力。
本文方案
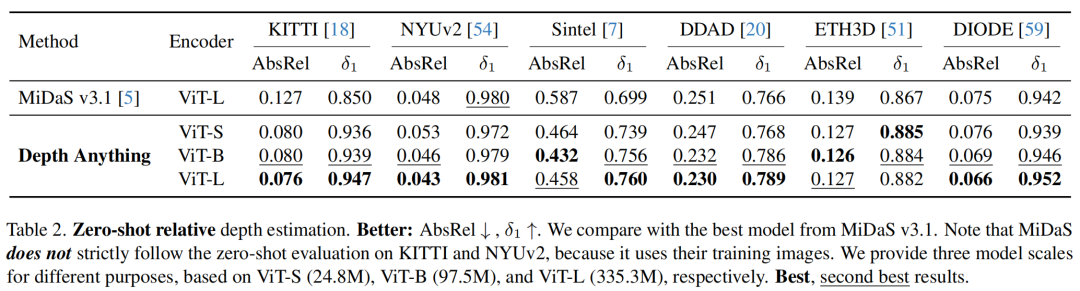
上表对比了当前相对深度估计SOTA方案MiDaS v3.1与所提方案在不同数据集上的性能,可以看到:
- 在两个指标方面,所提方案均优于最强MiDaS模型;
- 在DDAD数据集上,AbsRel指标从0.251改善到了0.230,
指标从0.766提升到了0.789;
- ViT-B模型甚至已经明显优于MiDaS模型,更小的ViT-S甚至都可以在几个未见数据集上优于MiDaS。

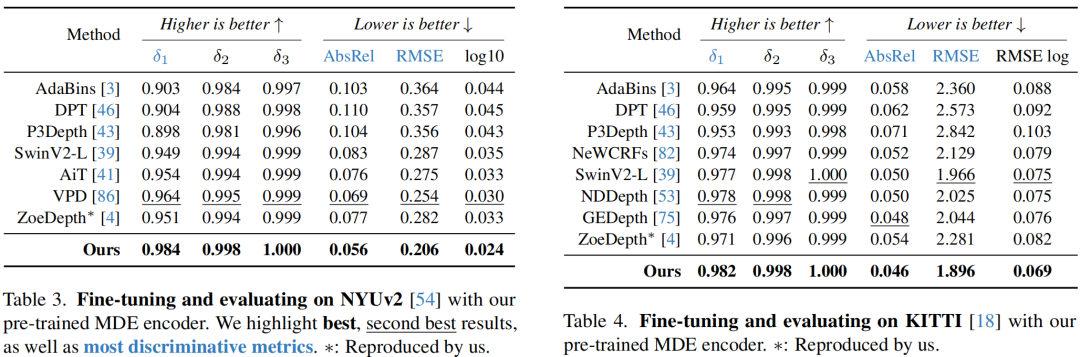
上两表域内与域外度量深度估计角度进行了对比,很明显:所提方案取得了非常优异的微调性能。
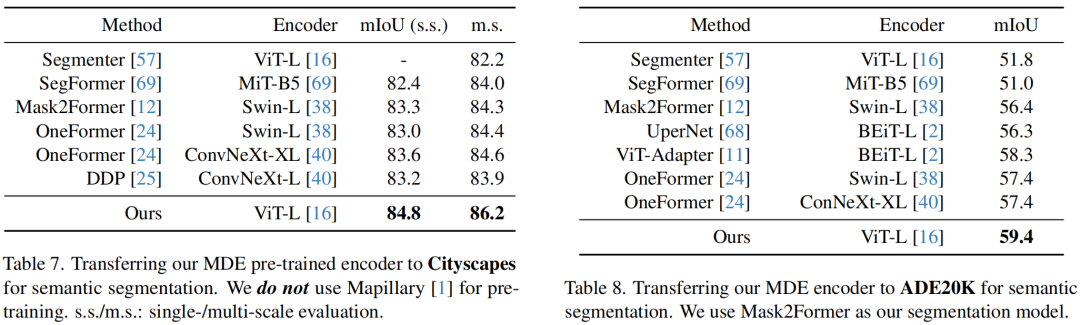
最后,作者还验证了所提MDE编码器在语义分割任务上的迁移能力,见上表。