expLTV:通过专家网络路由和高价值用户识别进行LTV预测
expLTV:通过专家网络路由和高价值用户识别进行LTV预测

1.导读
Alt text
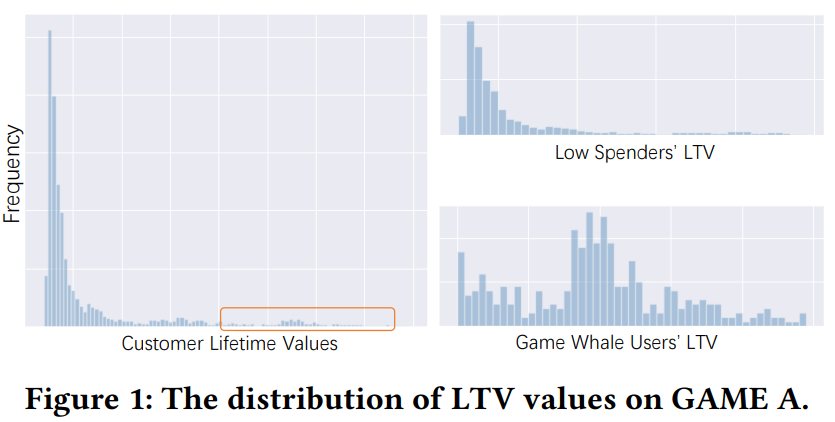
本文是针对LTV(生命周期价值)预估,提出的相关方法。主要是在以往LTV预估方法的基础上去额外考虑“鲸鱼”用户的分布,所谓鲸鱼用户就是具有高消费能力的用户,以游戏为例,用户的消费情况基本符合二八定律,即20%的“鲸鱼”用户提供了80%的成交收益。下文中主要就以高价值和低价值用户来分别指代两类用户,作者发现高价值用户和低价值用户的分布是存在明显差异的,若是一起训练会预测的不准,所以设计了ExpLTV方法:
- 设计一个门控网络,来检测用户属于高价值用户的概率,以此概率对用于后续预测的
和
进行加权
- 基于不同的专家网络分别预测高价值和低价值用户的
和
,然后用上述门控得到的权重进行加权融合
简单补充:上面说到的
和
是谷歌19年提出的ZILN方法,上述的
和
对应对数正态分布均值和标准差,详情可以阅读原论文,本文是在ZILN的基础上进行改进的,所以阅读本文需要一些ZILN的知识。相关内容网上还是挺多的,这里就不列了。论文:《A Deep Probabilistic Model For Customer Lifetime Value Prediction》
2. 方法
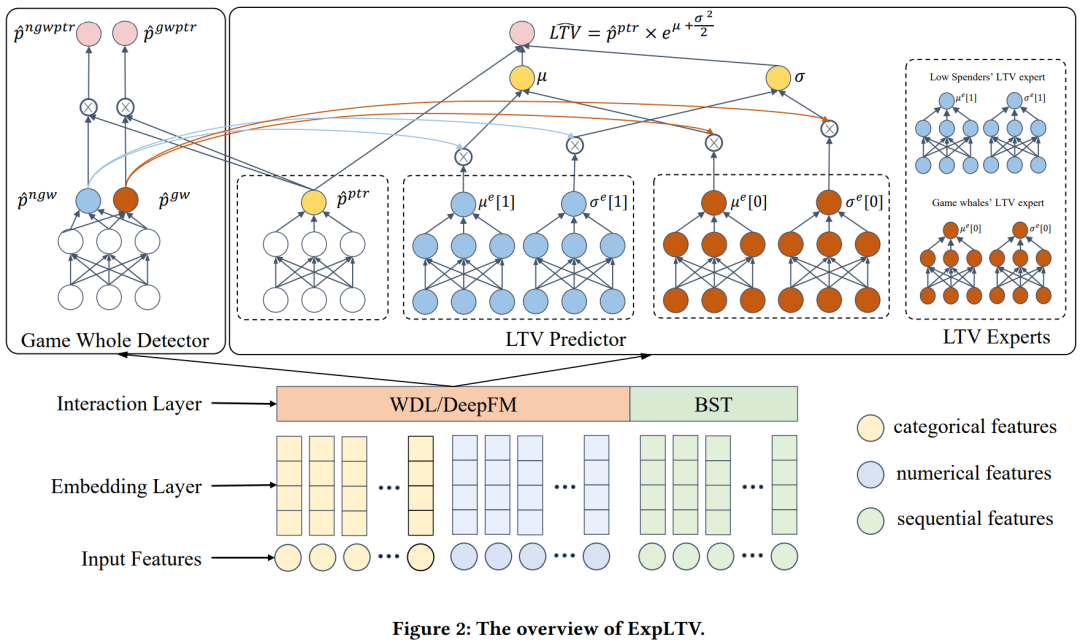
如图所示,模型结构主要是三部分,embe层,鲸鱼用户检测和融合预测
2.1 鲸鱼用户识别
令LTV大于阈值R的用户为鲸鱼用户,则鲸鱼用户的概率表示为下式,
表示是鲸鱼用户,
表示存在购买行为,一个用户只有存在购买行为才有可能是鲸鱼用户(eg:就像在淘宝里只有点击后才会有购买一样)
如果LTV小于R则
。
note:可以发现这里没有直接通过阈值R将用户分为高价值用户和低价值用户,因为如果直接这么分,我们只能知道这个用户是高价值用户的概率有多大,但是无法和LTV结合起来,而上述的方式,用户的概率越大可以反应LTV就会越大,所以作者把这个任务做成了回归任务。
鲸鱼用户的预测值表示为下式,就像前面说的需要同时考虑用户会购买的概率和是高价值用户的概率(类似ESMM)
普通用户有两种,一种是低价值的,一种是不会购买的,所以表示为
最后的损失函数为下式,第一项是预测用户是否会购买,使用交叉熵损失函数;第二项中的
是
的拼接,使用KL散度来衡量预测分布和真实分布的差异。
小总结:如结构图所示,鲸鱼用户识别网络的输出
为经过softmax后的概率值,然后再结合对用户是否会购买的概率的预估得到最终的预测,其中
。那这里为啥没有直接用
来建模呢?类似ESMM的思路,这里为了缓解selection bias和data sparsity。
2.2 LTV预测和损失函数
LTV预测部分整体和ZILN是类似的,但是作者再这两把原始ZILN中的
和
分别拆分成了两个,对应鲸鱼用户和普通用户的
和
。从图中很容易看出来,这里不过多赘述,对于四个expert分别用鲸鱼识别网络得到的权重进行加权聚合,得到最终的
和
。
聚合后进行预测和损失函数构造都和ZILN一样,不做赘述。
最终的损失函数
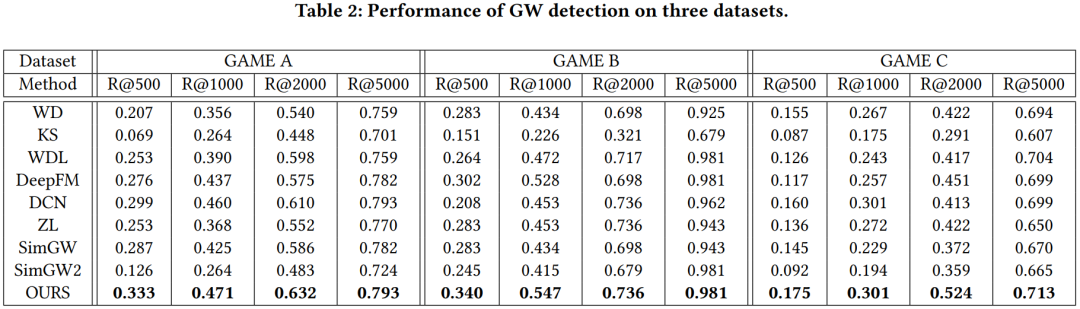
3. 结果
Alt text
4. 一点思考
ltv预估更多是需要结合不同的业务场景,不同的业务场景的数据分布会存在自身的一些特性,翻阅了一些文章,并没有发现统一的benchmark,大多数都是基于自身场景存在的问题提出对应的解决方法,可见ltv是具有较强场景属性的问题,不同的方法只能参考。