python处理大数据表格
原创python处理大数据表格
原创
一、数据的利用效率
首先在开始讲正文之前,你首先应该考虑数据有多大。这真的有使用到那么大的数据吗?
假设你有1亿条记录,有时候用到75%数据量,有时候用到10%。也许你该考虑10%的使用率是不是导致不能发挥最优性能模型的最关键原因。
计算机通信领域有个句号叫“Garbage in, Garbage out”。“垃圾进,垃圾出”说明了如果将错误的、无意义的数据输入计算机系统,计算机自然也一定会输出错误数据、无意义的结果。
二、HDFS、Spark和云方案DataBricks
考虑HDFS分布式文件系统能够水平扩展部署在多个服务器上(也称为work nodes)。这个文件格式在HDFS也被称为parquet。这里有个巨大的csv类型的文件。在parquet里会被切分成很多的小份,分布于很多节点上。因为这个特性,数据集可以增长到很大。之后用(py)spark处理这种文件。Spark有能力并行在多个node上操作。当数据集变得更大,那么就加入更多的node。
比如说一个现实的生产案例,18x32的nodes的hadoops集群,存储了3 petabyte的数据。理论上这么多数据可以用于一次性训练模型。
但你需要记住就地部署软件成本是昂贵的。所以也可以考虑云替代品。比如说云的Databricks。
三、PySpark
Pyspark是个Spark的Python接口。这一章教你如何使用Pyspark。
3.1 创建免费的databricks社区帐号
这里在 Databricks Community Edition 上运行训练代码。需要先按照官方文档中提供的说明创建帐户。这完成此步骤之后,才能再继续后面的步骤。

创建账号后在注册邮箱里找到激活link完成。
3.2 使用Databricks 工作区(Workspace)
现在,使用此链接来创建Jupyter 笔记本的Databricks 工作区。操作步骤可以在下面的 GIF 中看到。
在左侧导航栏中,单击Workspace> 单击下拉菜单 > 单击Import> 选择URL选项并输入链接 > 单击Import。

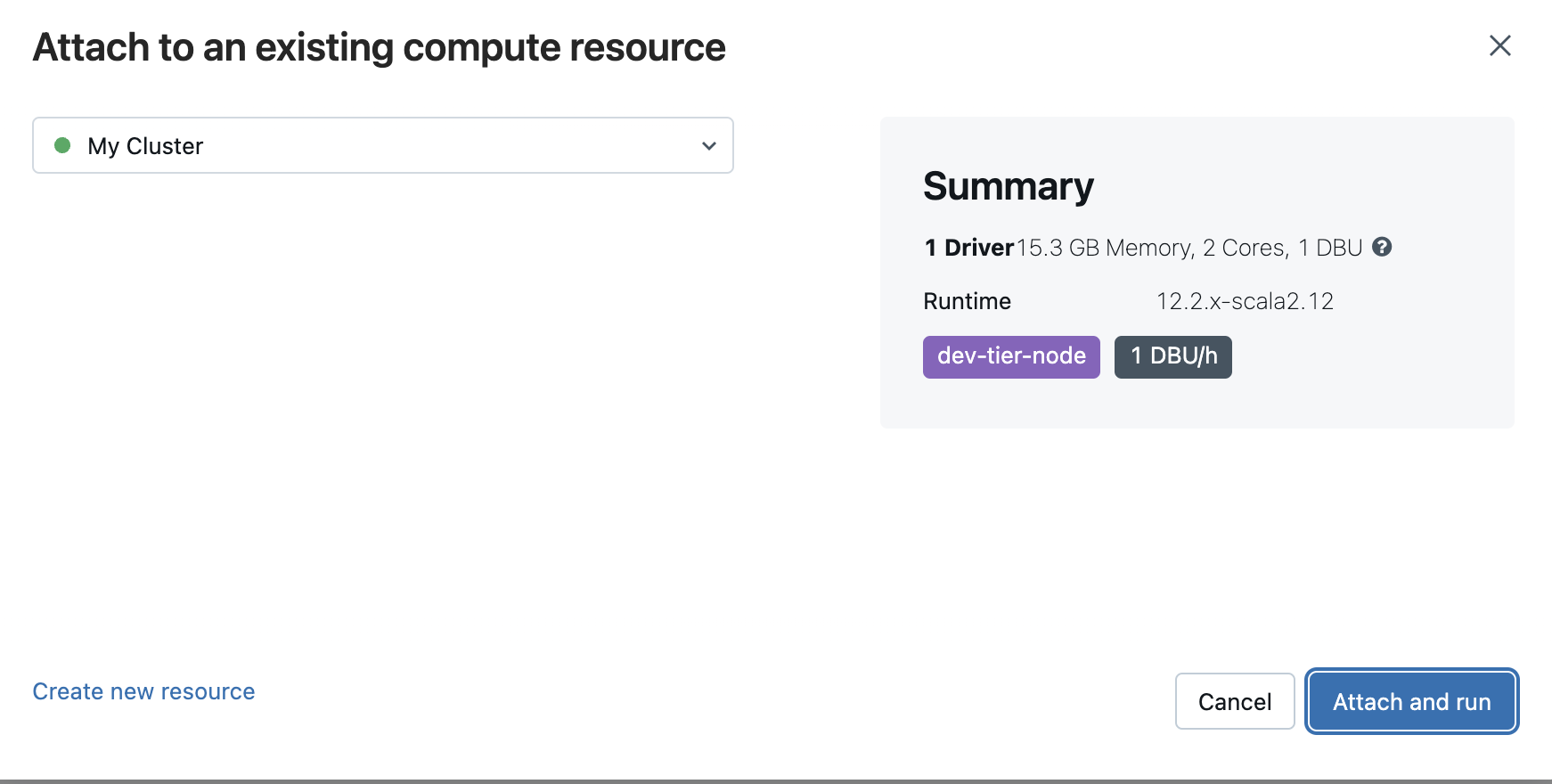
3.3 创建计算集群
我们现在将创建一个将在其上运行代码的计算集群。
- 单击导航栏上的“Compute”选项卡。然后单击“Create Compute”按钮。进入“New Cluster”配置视图。
- 为集群指定一个名称。从“Databricks 运行时版本”下拉列表中,选择“Runtime:12.2 LTS(Scala 2.12、Spark 3.3.2)”。
- 单击“Spark”选项卡。将以下行添加到“Spark config”字段。
spark.kryoserializer.buffer.max 2000M
spark.serializer org.apache.spark.serializer.KryoSerializer- 单击“Create Cluster”。创建集群可能需要几分钟的时间。

3.4 使用Pyspark读取大数据表格
完成创建Cluster后,接下来运行PySpark代码,就会提示连接刚刚创建的Cluster。注意到这里的Cluster有2Cores,后续可以看到的任务都会压榨这2个cores,这样可以得到更好的性能。
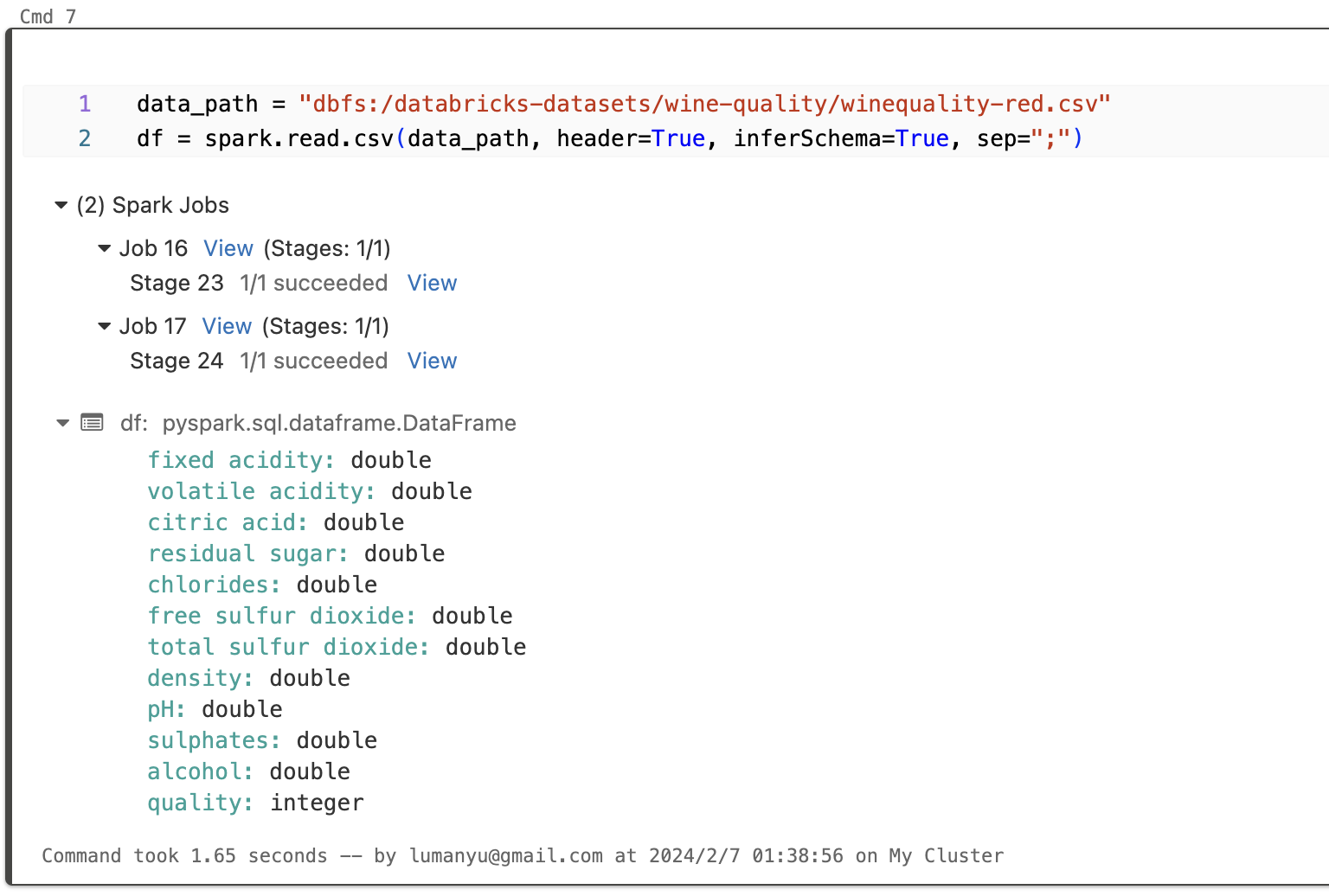
读取csv表格的pyspark写法如下:
data_path = "dbfs:/databricks-datasets/wine-quality/winequality-red.csv"
df = spark.read.csv(data_path, header=True, inferSchema=True, sep=";")运行,可以看到Spark Jobs有两个来完成读取csv。这里的header=True说明需要读取header头,inferScheme=True
- Header:
如果csv文件有header头 (位于第一行的column名字 ),设置header=true将设置第一行为dataframe的column名字。 如果 header=false (默认设置) 会让dataframe使用column这种名字 _c0, _c1, _c2, 等.
- Schema:
schema 指的是column 类型。 column 可以是String, Double或者Long等等。使用inferSchema=false (默认值) 将默认所有columns类型为strings (StringType).。取决于你希望后续以什么类型处理, strings 有时候不能有效工作。比如说你希望数据加加减减,那么columns 最好是numeric类型,不能是string。
如果设置了inferSchema=true, Spark 会读取并推断column类型。这需要额外的处理工作,所以 inferSchema 设成true理论上会更慢。
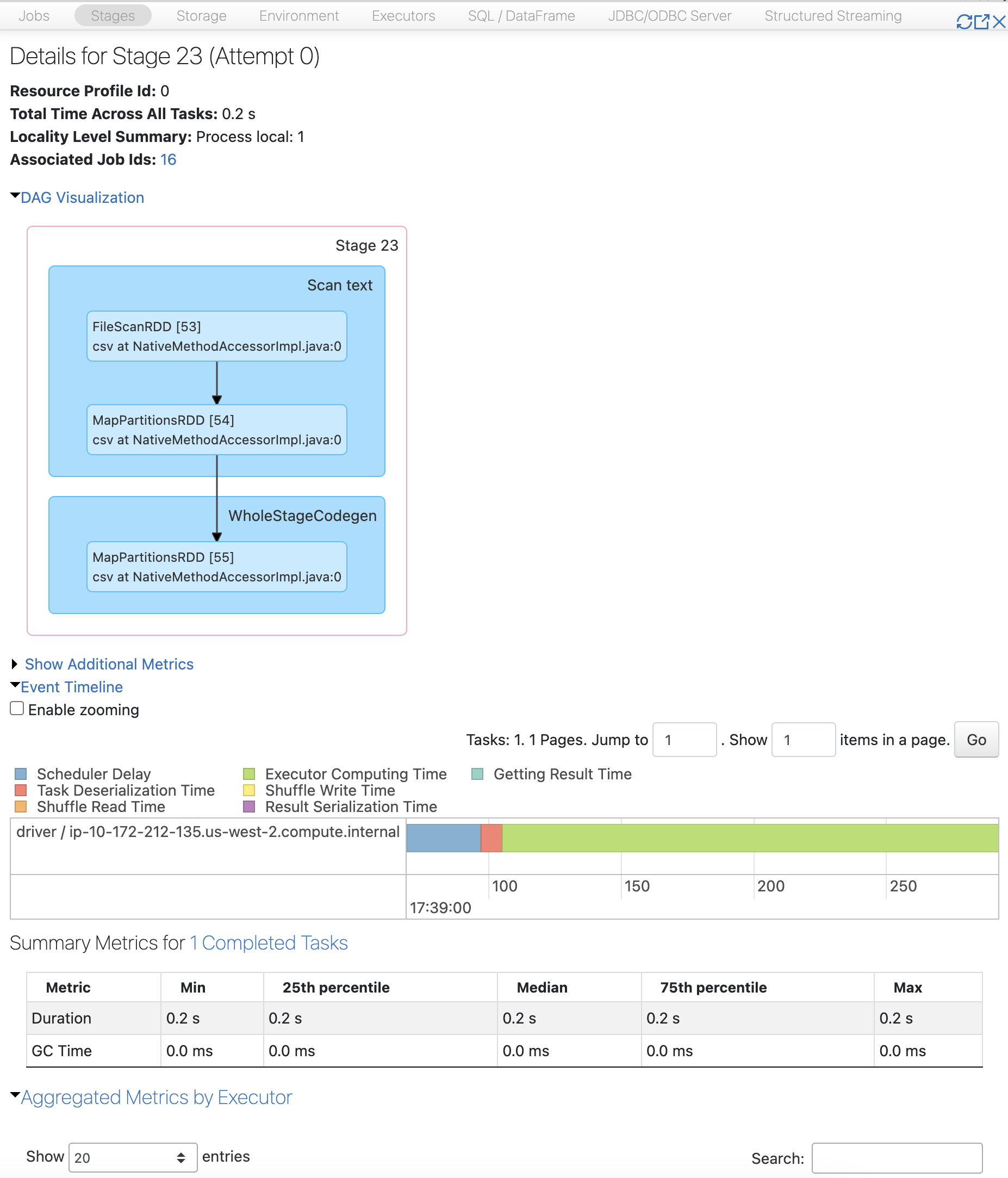
点击1个Spark Jobs,可以可视化这个Jobs的DAG。
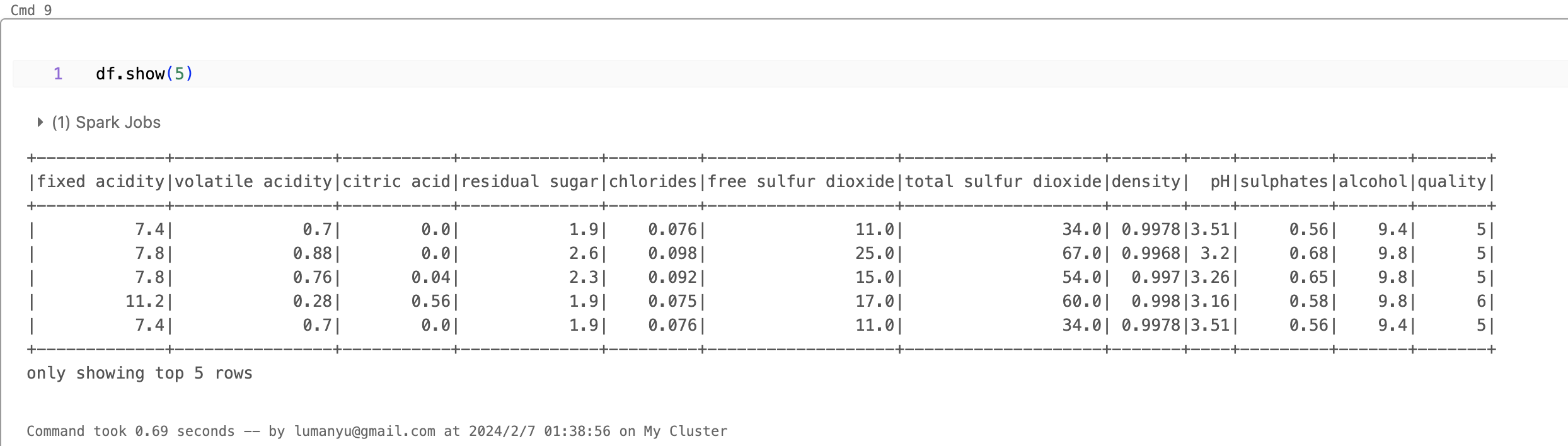
3.5 通过DataFrame来操作数据
接下来针对df,用我们熟悉的DataFrame继续处理。
- show展示top数据
- 选择部分数据
- 排序操作

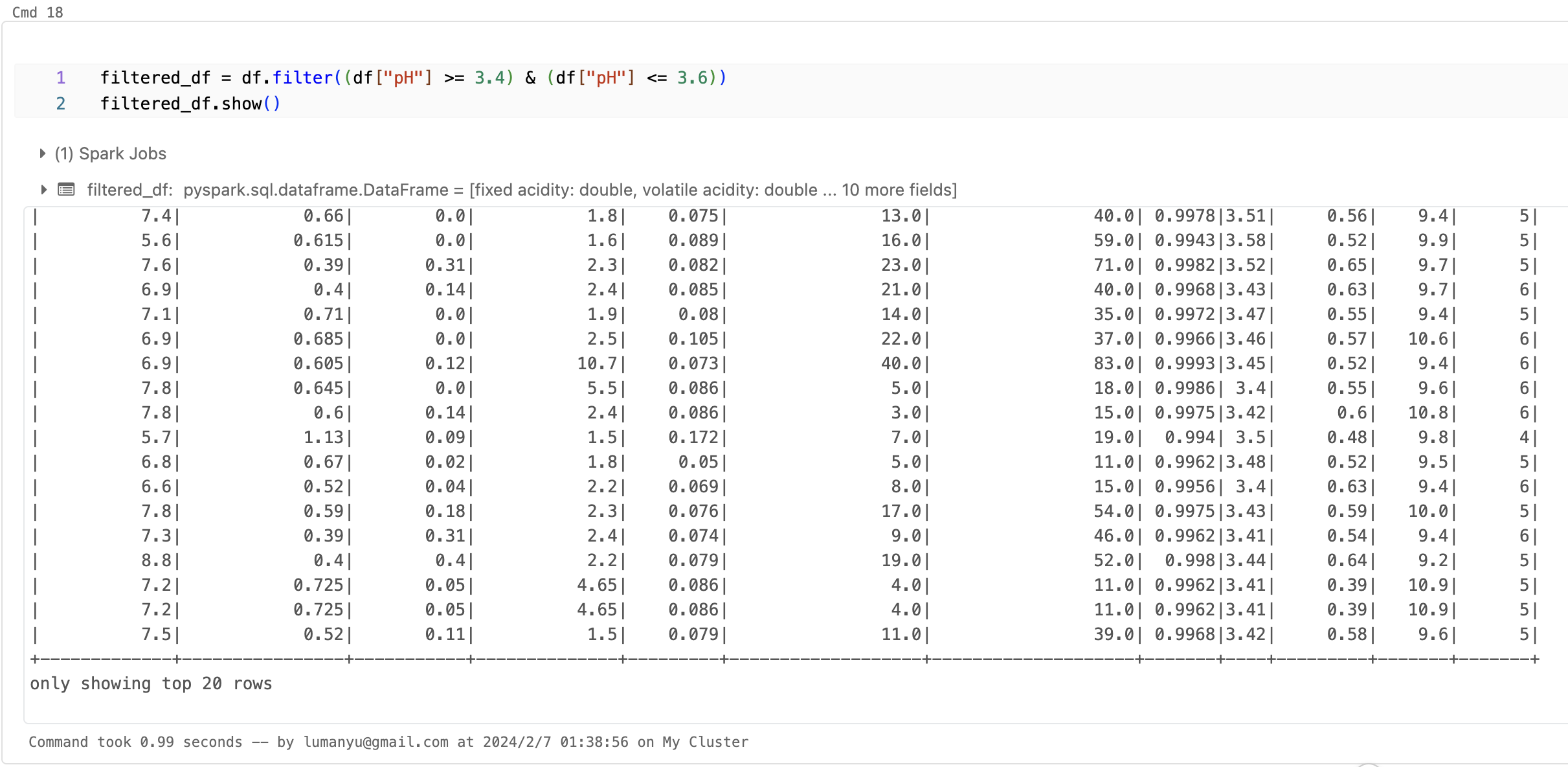
- 过滤筛选数据
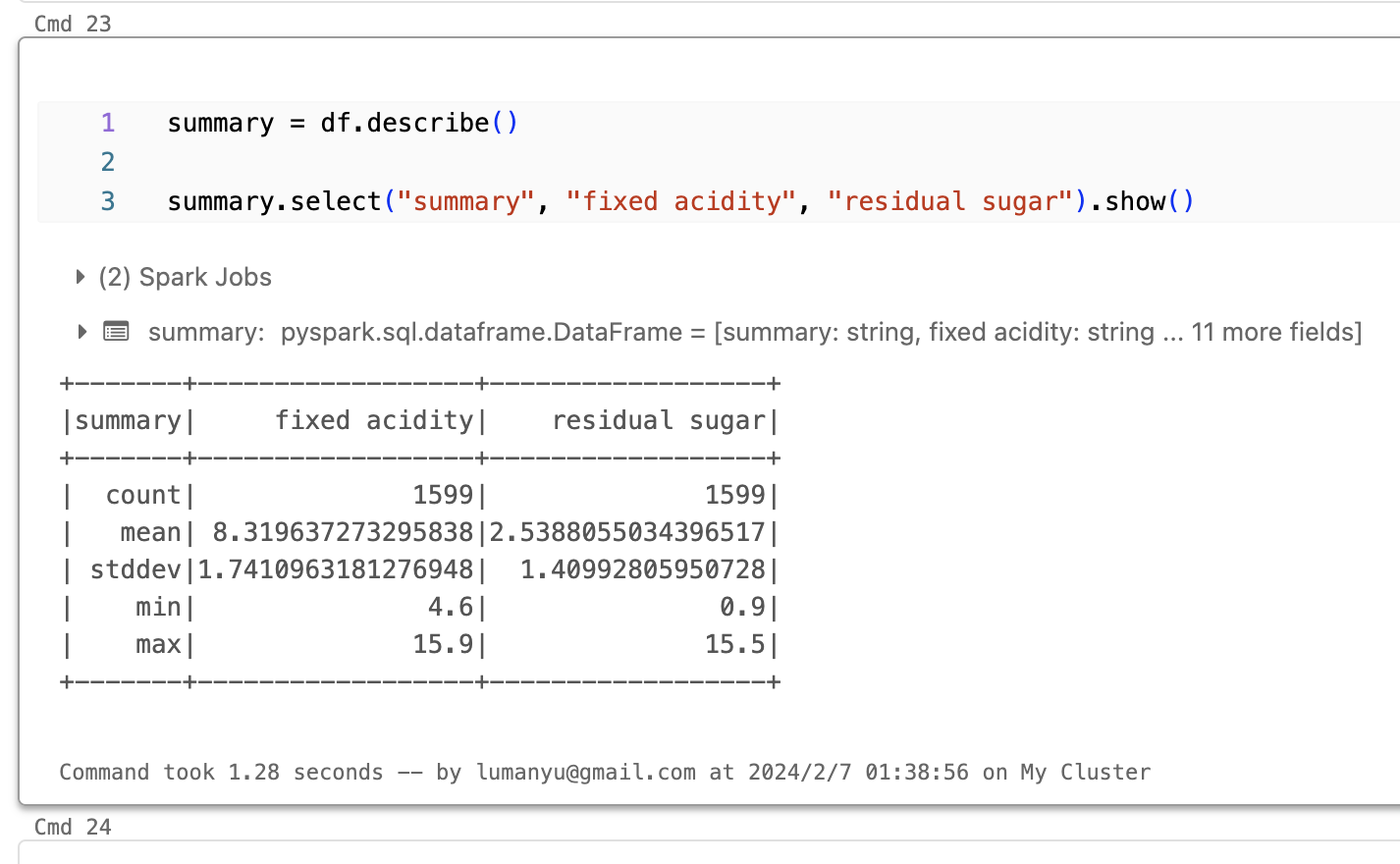
- 统计数据
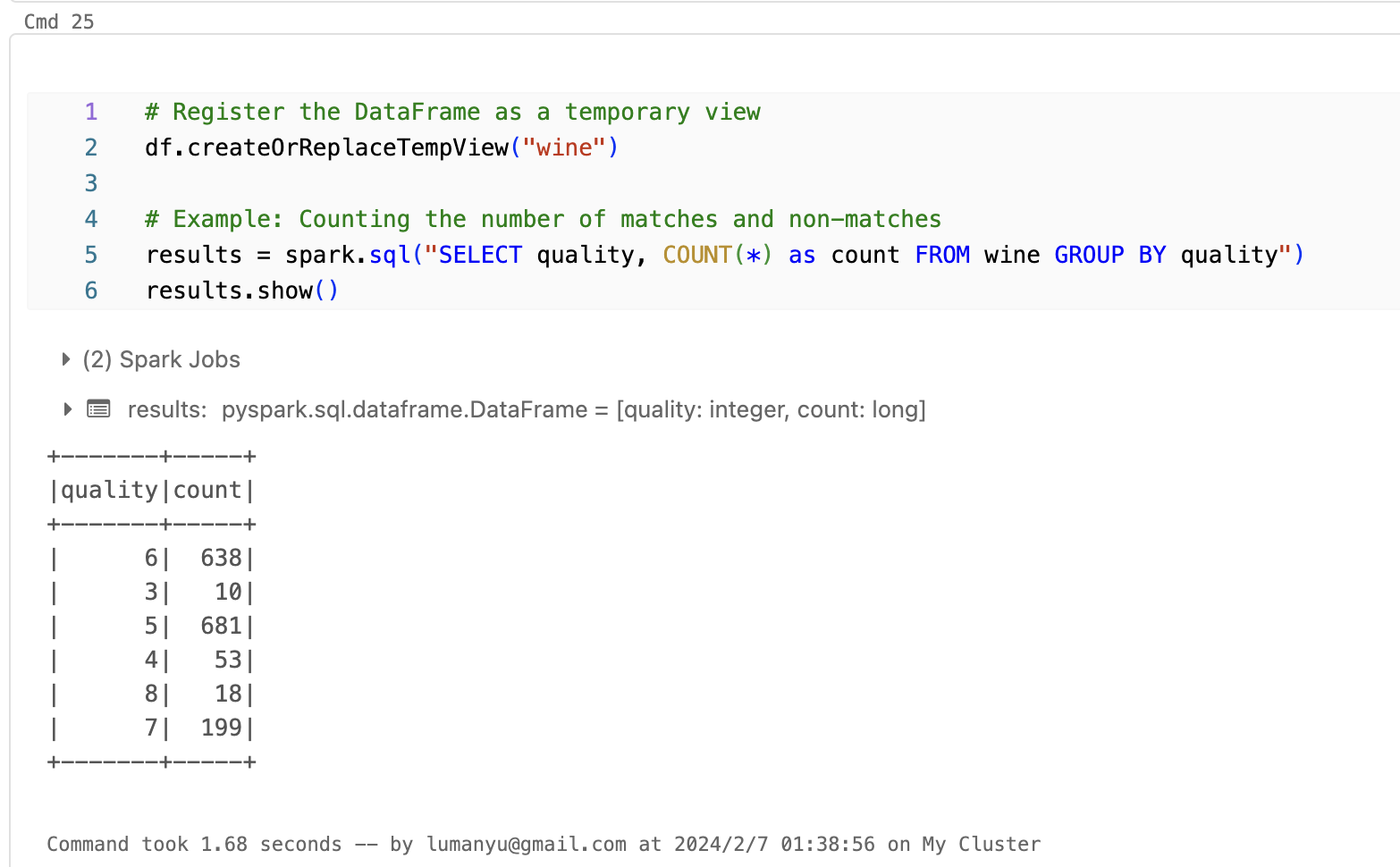
- 原生sql语句支持
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。