查询+缓存 —— 用 Elasticsearch 极速提升您的 RAG 应用性能
原创查询+缓存 —— 用 Elasticsearch 极速提升您的 RAG 应用性能
原创
在这个数据驱动的时代,我们对于信息的检索和处理速度有着前所未有的需求。尤其是在生成式人工智能(AI)应用领域,如何高效地处理和响应用户的查询成为了技术创新的前沿。本文将介绍如何利用 Elasticsearch 作为 RAG(Retrieval-Augmented Generation)应用的缓存层,大幅提升应用性能,减少成本,并确保生成响应的质量。
什么是 RAG 应用?
在深入之前,让我们先简要理解 RAG 应用的概念。RAG,即检索增强生成,是一种结合了信息检索和生成式AI模型的技术。通过这种方式,模型能够从庞大的数据库中检索信息,并生成准确、相关的回答。然而,这一过程的效率和成本一直是技术开发的挑战。
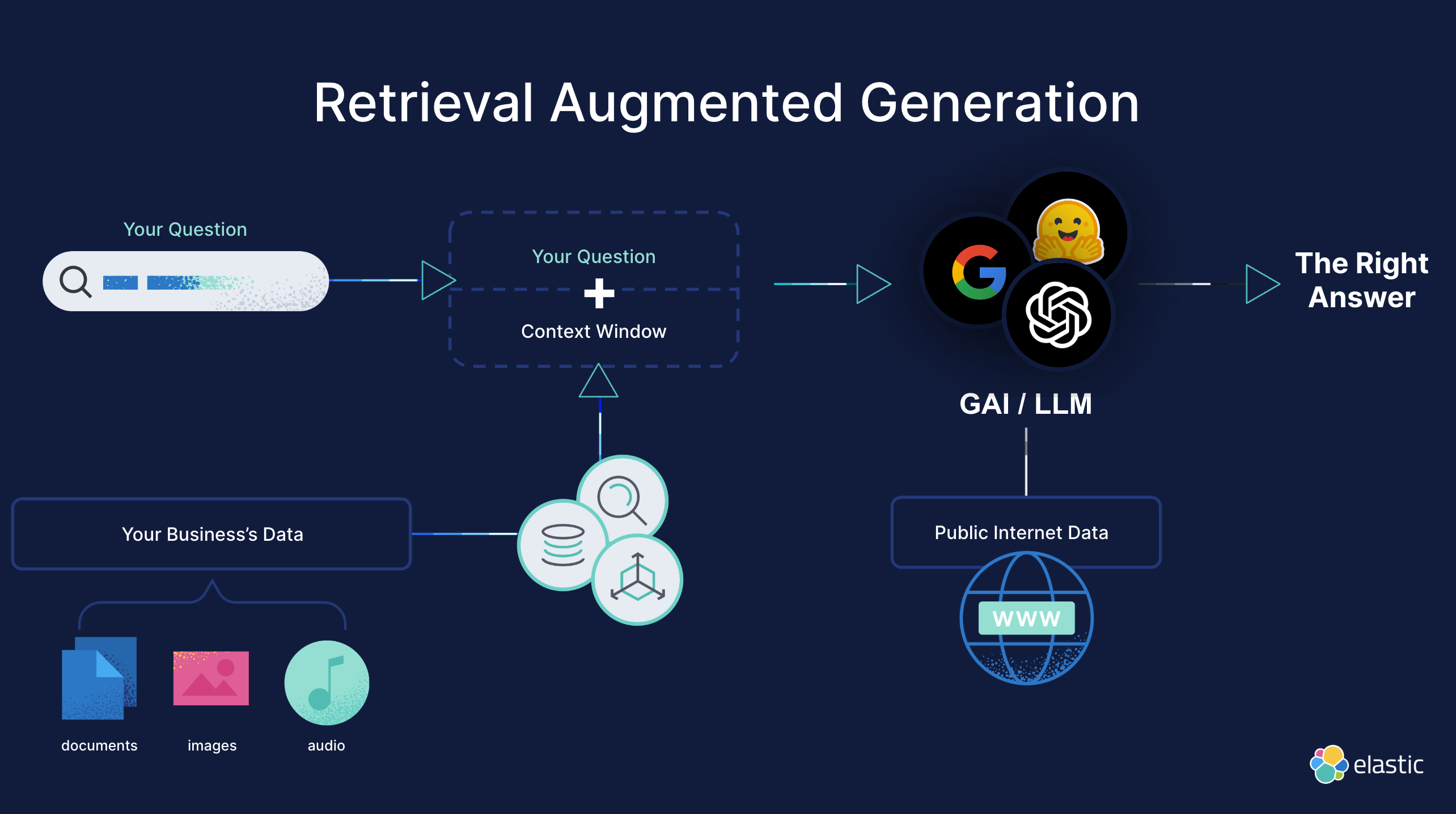
LLM 在RAG中的问题
首先,存在每个生成调用的 token 成本问题。token 是转换为模型可以理解的输入文本。它们可以短至单个字符,也可以长至单词。这很重要,因为您需要根据处理的令牌数量进行计费。现在,想象一个场景,多个用户询问完全相同的问题或向模型提供类似的提示。每个调用都需要花费token,因此如果处理两个相同的提示,则成本实际上会加倍。
然后是响应时间的问题。生成模型需要时间来接收数据、处理数据,然后生成响应。根据模型大小、提示的复杂性、运行位置以及其他因素,此响应时间可能会增长到数秒。这就像等待网页加载一样;几秒钟的时间感觉就像是永恒,并可能阻止用户进一步参与。
token 成本和响应时间这两个问题尤其重要,因为它们不仅影响运营效率,而且对用户体验和整体系统性能有直接影响。随着对更新的实时、智能响应的需求不断增长,这些挑战不容忽视。因此,我们发现自己正处于一个迫切需要寻找可扩展且高效的解决方案的时刻。
Elasticsearch 作为缓存层的革新之举
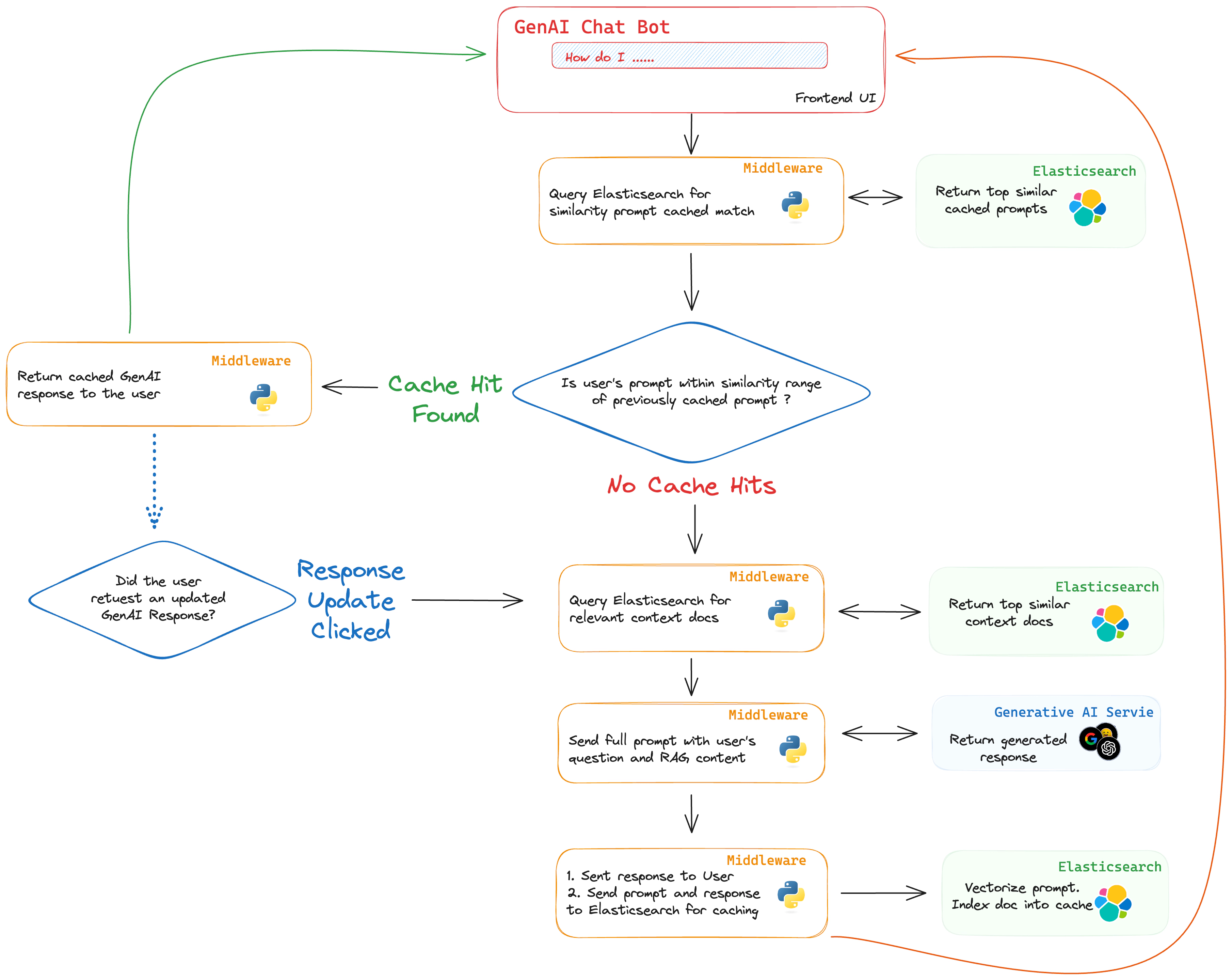
Elasticsearch 是一种向量数据库,它不仅能够存储问题和答案的原始文本,还能够将它们的语义或“基于含义的表达”转化为数值向量形式进行存储。通过这种方式,Elasticsearch 能够快速地对这些向量进行相似度比较,为识别与已回答问题相关的问题提供了一种稳定而高效的方法。
实现这种智能匹配的核心在于 k 最近邻 (kNN) 相似性搜索。通过 kNN 技术,Elasticsearch 能够迅速找出与新提出的查询最为贴近的现有内容。这一过程既快速又高效,如果找到了足够相似的已回答问题,就可以避免调用计算资源密集的生成模型,从而不仅提高响应速度,还能节省费用。Elasticsearch 通过在查询中启用相似性参数来实现这一功能。
要将 Elasticsearch 集成为缓存层,其工作流程可以是这样的:当有新的查询出现时,系统会先对该查询进行向量化处理,并在 Elasticsearch 中进行搜索,查找是否有与之高度匹配的现有向量。如果找到匹配的答案,就直接返回之前为相似查询生成的答案;如果没有找到,那么问题就会按照常规的 RAG 流程进行处理,新生成的答案会被存储回 Elasticsearch,以便未来使用。此外,您还可以提供选项,让用户在需要时能够要求获取“新鲜”的答案,绕过缓存。
与此同时,Elasticsearch 还可以配置成定期清理旧数据,类似于其他缓存系统中的 TTL(Time To Live)机制,确保缓存内容保持最新和有用。同时,还可以利用 Elasticsearch 的 Frozen Searchable Snapshot 功能来实施分层缓存策略,从而以较低的成本构建一个庞大的缓存层,用于存储访问频率较低的数据,但仍然能比生成新响应更快。
此外,还可以引入质量保证措施,比如为某些响应设置“审核通过”标记。这样就允许人工审核员在缓存的答案提供给最终用户之前进行复核,从而增加了系统的可靠性和准确性。
通过将 Elasticsearch 作为缓存层来实现,您的系统将更具可扩展性、效率更高,并在多个方面更加智能,能有效地解决部署 RAG 等生成式 AI 模型时常面临的挑战。
评估语义相似性:容忍与抵制
在利用 Elasticsearch 作为缓存层时,一个关键方面在于评估新提出的问题和之前存储的问题之间的语义相似性。我们的缓存机制的有效性很大程度上取决于我们将新查询与现有查询匹配的程度。该评估的核心有两个截然不同的概念:语义容忍和语义抵抗。
语义容忍度
语义容忍度(Semantic Tolerance),反映了召回率(Recall),是一个用更广泛的视角评估相似性函数的概念,允许问题之间更广泛的语义相似性。这种宽大处理可以带来更多匹配,从而有可能减少 LLM 的计算负载。然而,它也可能导致匹配不太精确,从而影响生成响应的准确性和相关性。
语义阻力
另一方面,与精确度产生共鸣的语义阻力采用了更严格的相似性函数,缩小了被视为“匹配”的范围。这种严格性往往会产生更准确和相关的匹配,但代价可能是更高的计算成本,因为更少的存储问题可能满足严格的相似性标准。
语义容忍度和语义阻力之间的平衡,就像召回率和精确度之间的权衡一样,对于优化 Elasticsearch 缓存层的性能和有效性至关重要。通过微调 KNN 搜索中的相似性参数,人们可以进行这种权衡,以使缓存机制与特定的操作要求和用户期望保持一致。
用 HR 示例说明语义相似性
为了更好地理解语义相似性的细微差别,让我们考虑一下公司环境中的一个常见场景:员工询问有关家庭活动(例如孩子的婚礼)的带薪休假 (PTO) 政策。这里有两个这样的查询:
- A:“我家里要举行婚礼,我的儿子要结婚了。我有资格获得一些 PTO 吗?”
- B : “我的孩子即将结婚,我可以带一些 PTO 参加婚礼吗?”
乍一看,很明显这两个查询都在寻求相同的信息,尽管措辞不同。我们的目标是确保系统能够识别这些查询的语义接近度,并提供一致且准确的响应,而不管措辞差异如何。
相似度参数对语义容忍度和抵抗力的影响
这种情况下语义匹配的有效性受到 Elasticsearch 内 KNN 搜索中相似性参数选择的影响。该参数确定向量被视为匹配所需的最小相似度。我们可以通过检查具有不同相似性阈值的两个假设场景来说明该参数的影响:
- 场景 A(高阈值 - 阻力):设置严格的相似性参数,例如 0.95,强调语义阻力。这仅允许具有高度相似性的查询来检索缓存的答案,以牺牲召回率为代价来提高精确度。
- 场景B(低阈值-容差):设置更宽松的相似性参数,例如0.75,强调语义容差。这允许更广泛的语义相关查询来检索缓存的答案,有利于召回而不是精确。
通过比较这些场景,我们可以观察相似性参数如何影响语义抵抗和语义容忍之间的平衡,进而影响召回率和精确率之间的权衡。下表说明了在这些场景下如何根据查询与有关儿童婚礼 PTO 的原始查询的假设相似度分数来处理不同的查询:
询问 | 假设相似度分数 | 在场景 A 中检索(高阈值 - 0.95) | 在场景 B 中检索(低阈值 - 0.75) |
|---|---|---|---|
我可以参加我儿子的婚礼吗? | 0.94 | 不 | 是的 |
家庭活动有休假政策吗? | 0.80 | 不 | 是的 |
我女儿结婚需要请假,可以吗? | 0.97 | 是的 | 是的 |
我如何申请因个人家庭活动而请假? | 0.72 | 不 | 不 |
参加家庭仪式请假的流程是什么? | 0.78 | 不 | 是的 |
我可以因为我兄弟姐妹的婚礼请几天假吗? | 0.85 | 不 | 是的 |
该表演示了不同的相似性阈值如何影响缓存答案的检索,显示了响应准确性(场景 A)和计算效率(场景 B)之间的权衡。
测试一下
虽然特定的应用程序取决于您的最终用例,但可以从此GH 存储库复制示例设置。
考虑一个涉及查询响应计时指标的场景。在没有缓存的第一次运行中,假设用户查询需要 300 毫秒才能从 RAG 接收生成的答案。现在,将该响应存储在 Elasticsearch 中后,会出现第二个类似的查询。这一次,由于我们的智能缓存层,响应时间降至仅 50 毫秒。这表明系统响应能力得到了切实改善——这对任何实时应用程序来说都是一个福音,也证明了所获得的成本和时间效率。
在示例项目中,您将找到两个主要文件。
elasticsearch_llm_cache.py中包含了 Python 类的示例存储库ElasticsearchLLMCache,您的应用程序将在启动时实例化该类。该类包含以下方法:
create_index如果 Elasticsearch 不存在,这将创建一个新的缓存索引query执行 kNN 搜索,包括向量化提示。它将返回相似度范围内的前 k 个相似文档。add通过调用对提示进行向量化_generate_vector,并以文本形式对提示和生成响应以及向量化提示进行索引
而 elasticRAG_with_cache.py 则利用了 elasticsearch_llm_cache.
但这不仅仅与速度有关,这也与可见性有关。如果您使用 Elasticsearch 的 Python 应用程序性能监控 (APM) 库,您可以获得有关查询时间、资源利用率甚至错误率的丰富指标。这些数据对于持续的系统优化非常宝贵,并且可以成为寻求微调性能的数据科学家和工程师的宝库。监控这些指标不仅可以改善用户体验,还可以更有效地管理资源。
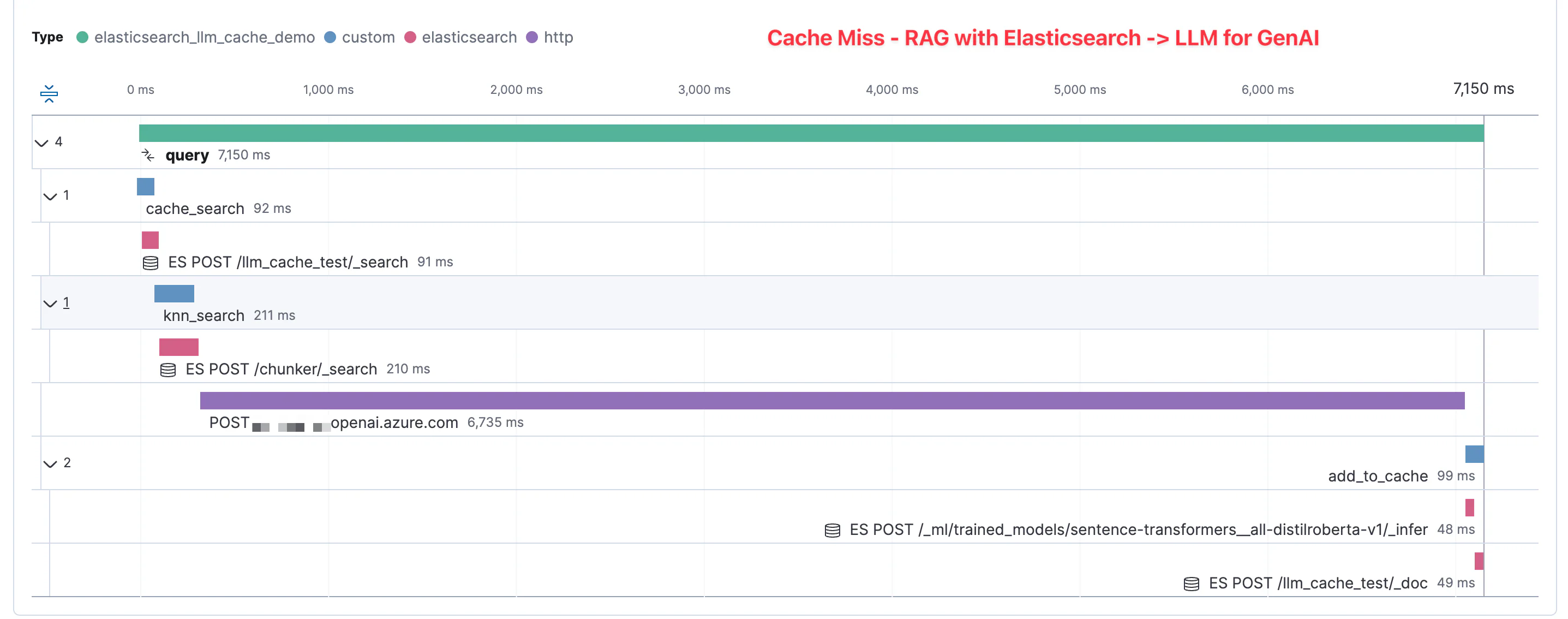
这是一条 APM 跟踪,显示输入新提示(没有匹配的缓存)时所花费的时间。我们可以看到,在此示例中,示例应用程序中从用户点击提交到应用程序从 GenAI 模式返回响应的总时间花费了 7,150 毫秒,即大约 7 秒。
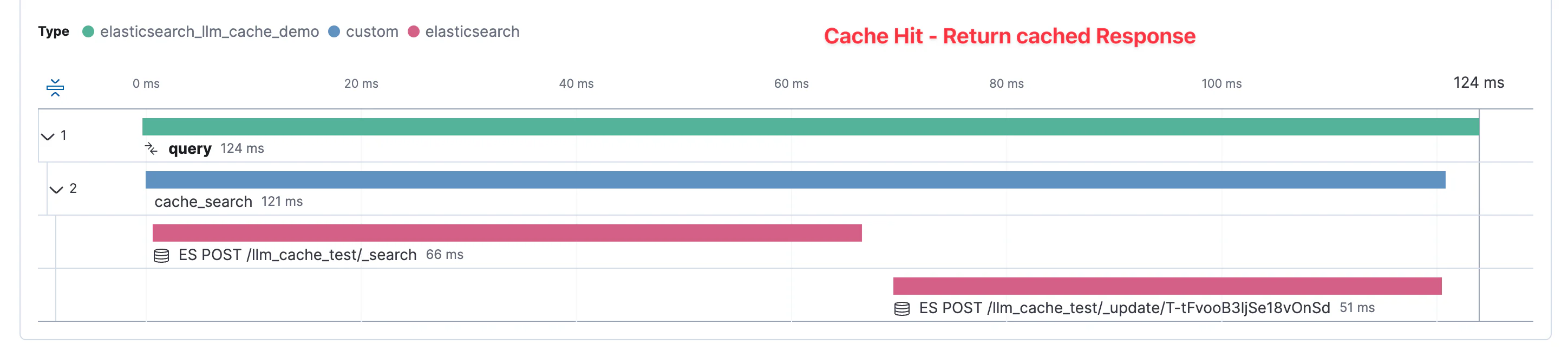
现在,该提示和响应已缓存在 Elasticsearch 中以供将来使用,下面的 APM 跟踪显示了何时回答类似的提示。这里我们看到,因为找到了足够接近的提示,所以我们可以直接返回之前生成的响应。现在,此快捷方式的总时间为 124 毫秒。
通过查看这些示例用例,您可以清楚地看出,将 Elasticsearch 实现为缓存层不仅仅是一项学术练习;它也是一项实践。它对性能、成本和用户体验具有现实意义。
总结
通过利用 Elasticsearch 作为向量数据库的功能及其相似性参数,我们为响应速度更快、更具成本效益且可扩展的生成 AI 系统打开了大门。无论是改善查询时间、实现细致的匹配,还是通过人工监督增加另一层可靠性,其好处都是显而易见的。
准备好开始了吗?检查Python 库和示例代码,并在腾讯云ES上创建一个集群,来试一下吧!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。