HuggingFists-低代码玩转LLM-腾讯云RAG(1)
原创HuggingFists-低代码玩转LLM-腾讯云RAG(1)
原创
前序
在之前的系列文章里,笔者介绍了如何使用阿里的千问LLM、阿里的文本嵌入模型以及Milvus向量库来搭建一个RAG(检索增强生成)的实验。可通过以下的文章链接回顾一下之前介绍的内容:
《HuggingFists-低代码玩转LLM RAG-准备篇》
《HuggingFists-低代码玩转LLMRAG(1) Embedding》
《HuggingFists-低代码玩转LLM RAG(2) --Query》
在之前的实验中,我们的环境里用到了Milvus向量库,关于这个向量库的搭建对很多人来说也显得有些繁琐。所以,本次我们选择使用腾讯云的向量库来代替Milvus向量库,完RAG应用场景的搭建。除了向量库采用腾讯云以外,我们本次也将文本Embedding以及大语言模型都换成腾讯云的技术栈,大模型使用腾讯云的混元大模型。在搭建这个实验的过程中,我们能够看到不同技术路线带来的效果差异。
(注:喜欢看视频的朋友可以看视频了解搭建过程《玩转数据之低代码LLM 腾讯云RAG》)
环境准备
在腾讯云网站注册申请账号,并申请开通混元大语言模型以及腾讯向量库的应用授权,这些授权的申请需要网站审批,当申请通过后,在对应的页面创建Access Token后,就可以在HuggingFists中进行后续的环境准备工作了。
添加腾讯向量库&混元模型访问账号
1. 点击界面右上角的“user_name”,点击“个人设置”进入“资源账号”界面。
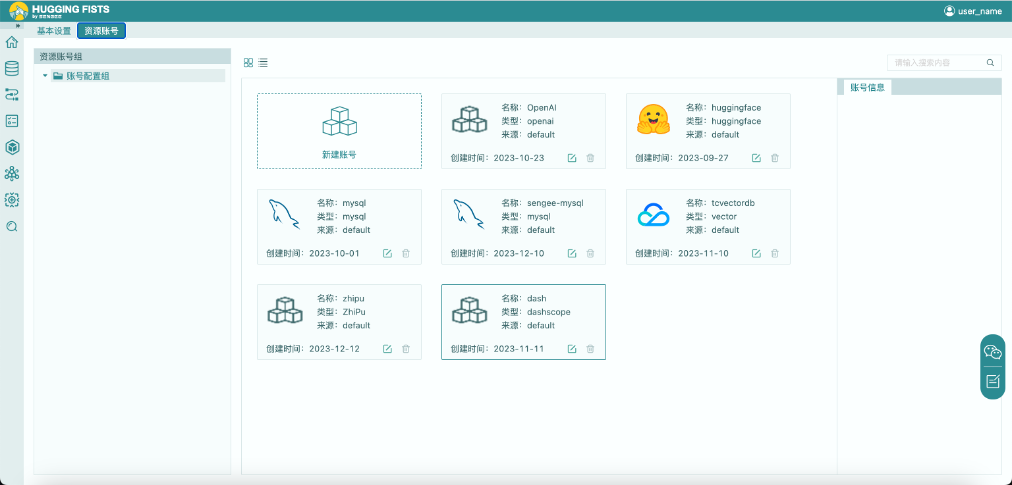
2. 点击“新建账号”按钮,选择“腾讯向量库”账号类型,填写“API密钥”,创建混元模型账号。
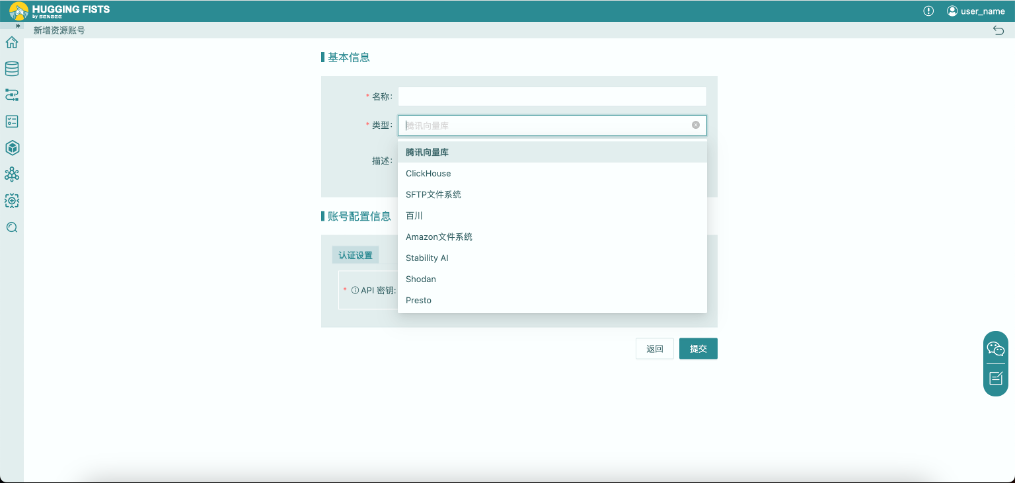
3. 点击“新建账号”按钮,选择“腾讯混元”账号类型,填写“用户名”、“访问token”以及”App Id”信息,创建混元模型账号。所有相关信息在申请“腾讯混元”许可时都可以在腾讯云获得。

添加腾讯向量库数据源
1. 进入HuggingFists数据源管理,选择数据库菜单。

2. 点击添加数据源按钮,选择创建腾讯向量库数据源类型

在数据源地址中添加腾讯向量库的访问地址,完成腾讯向量库的数据源添加。
创建腾讯向量库表(集合)
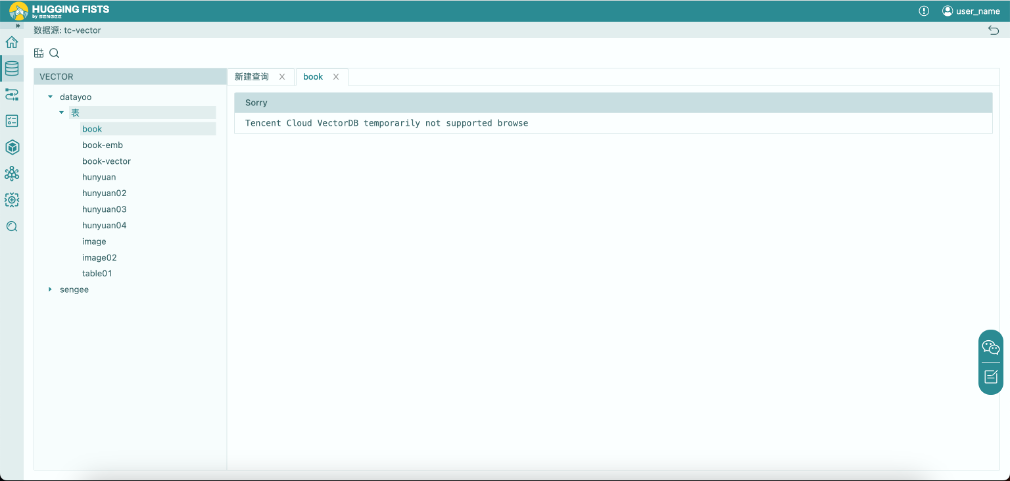
1. 点击查看腾讯向量库数据源,可以看到数据源中的数据表。(注:刚申请到的腾讯向量库是空的)。由于腾讯向量库检索时必须设置向量,所以HuggingFists目前不支持浏览向量数据库中的数据表。
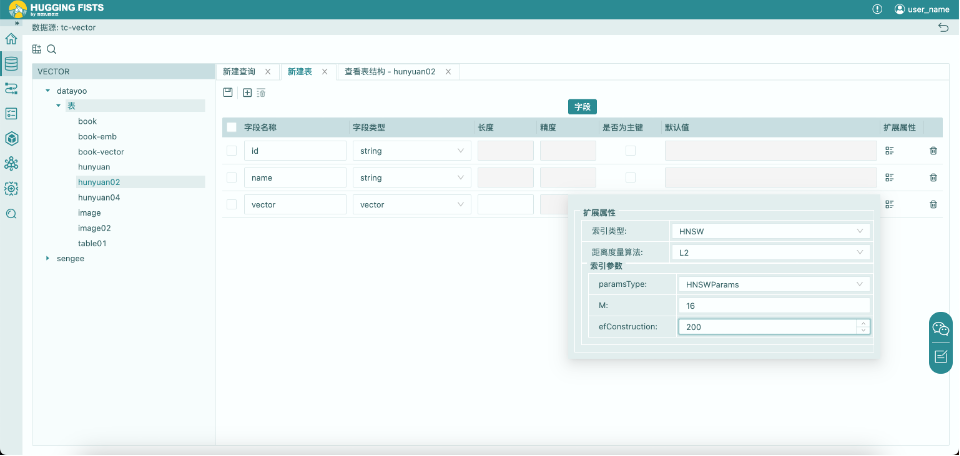
2. 点击“新建表”按钮;添加字段,必须为表指定一个id字段和一个vector字段。需要为表创建一个vector类型的向量字段,向量字段的长度设置为1024。因为腾讯提供的Embedding算法是1024维的。
3. 数据表创建成功,可以准备对腾讯向量库的读取或写出了。
添加Prompt模板
1. 点击“资源库”,点击进入“Prompt”库
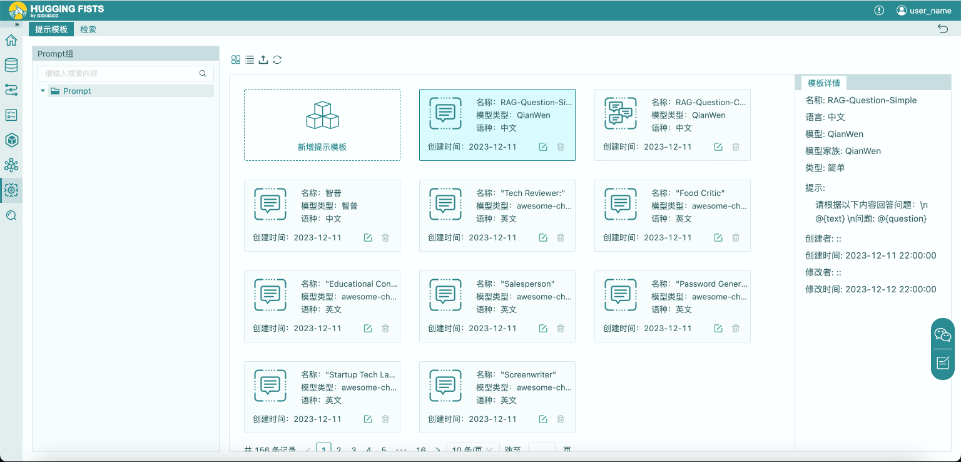
2. 点击“新建提示模板”,创建“简单”提示模板,用于单轮提示RAG检索流程的编写。
提示:“请根据以下内容回答问题,若无法根据内容回答问题,请回答‘无法根据提供的内容回答问题’。内容描述如下:\n @{text} \n问题: @{question}”
向量化数据写出
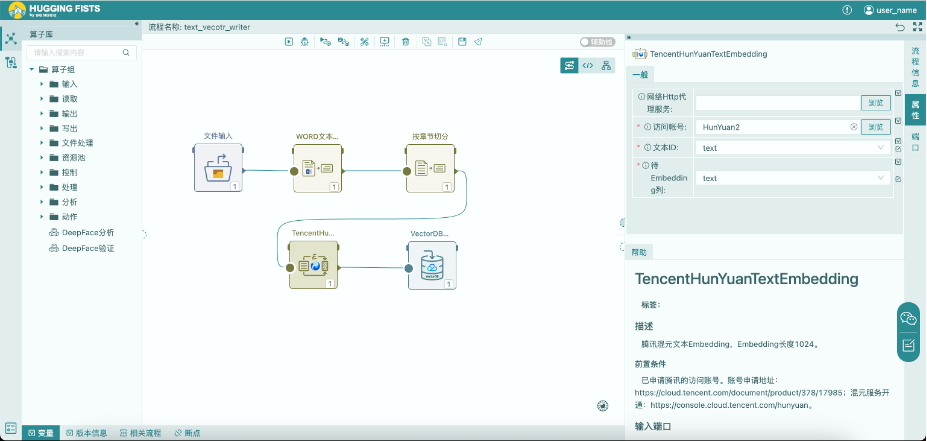
上图展示了一个将一个Doc文件向量化存入数据库的流程,流程定义的详细过程可以参见《HuggingFists-低代码玩转LLMRAG(1) Embedding》的相关章节。这里我们主要对腾讯向量库写出算子进行一下说明。

如上图所示,需要为腾讯向量写出算子选取之前配置好的向量库数据源及新建的数据集合book-rag。这个集合有三个字段,分别是id、name以及vector,我们需要为这三个列赋值,name和vector列我们为其配置了前序算子输出的两个对应列textId于embeddings。但是id列由于腾讯向量库为其约定的长度为0~255,故我们需要对其插入合适长度的值,于是在这里我们采用了对textId列中的值进行md5来当作id。
配置完流程后,我们运行流程,数据会被插入到向量库中,下面我们来查询看看输出结果如何。
向量化数据读取
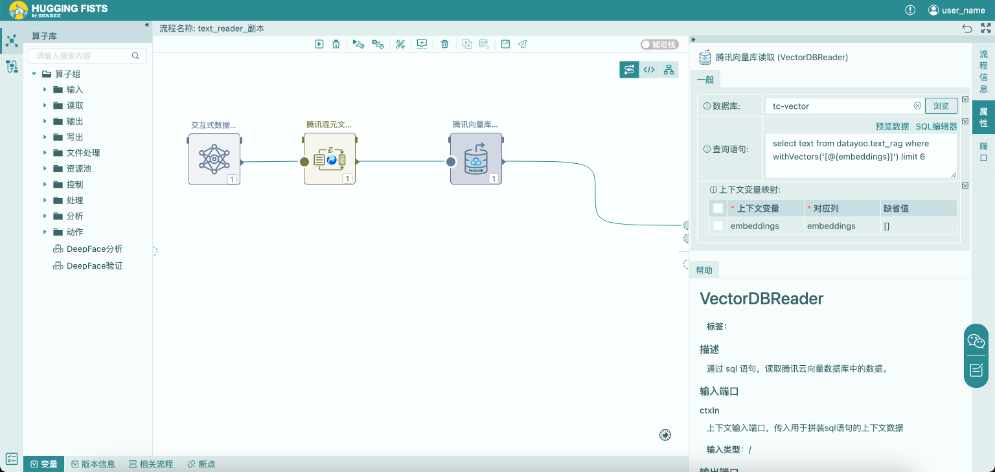
向量化数据读取流程由三个算子组成,用于测试是否能准确的从向量库中检索到与问题相关的文本块。下面对流程中的各个算子进行一下说明。
交互式数据输入

该算子用于模拟用户的输入,如上图,我们设定用户输入的问题为“数据安全治理有哪些框架?特点是什么?”。这个问题与之前使用Milvus向量库搭建的RAG场景一致。
腾讯混元文本嵌入

设置腾讯混元文本嵌入的访问账号。选取对输入的question列进行向量计算。
腾讯向量库读取

根据输入的问题向量,从腾讯向量库中查询匹配的数据。这里使用SQL语句方式访问。由于腾讯向量库本身不支持SQL的访问方式,所以这里使用的是基于开源项目MOQL对腾讯向量库支持的语法格式。在SQL语句中我们使用了@{embeddings}变量,该变量表示上下文变量,上下文变量可以与算子的输入列做绑定映射。该算子有一个名为embeddings的输入列,可以从配置中看到,变量embeddings与embeddings列做了映射绑定。运行时,变量会被输入列的值替换掉,从而生成可运行的SQL语句。当输入为多条记录时,每条记录都会驱动一次SQL的生成与检索。
SQL语句对返回结果进行了限制。如不做限定,向量库会将库中的数据按照与输入向量相似度从高到低的顺序全部返回。
运行结果

从输出结果的图中我们可以看到,回答问题所需的文本段在结果集第5条。这与上次使用Milvus向量库搭建的实验场景有了一定差异。在上一次实验中,用于回答问题的那段文本排在了查询结果的第一位。可以直接提交给大语言模型进行问题的回答。但是本次的查询,数据排在了结果的第5位。存在随着向量库数据的累积,其排序会更靠后的可能。那么我们到底需要获取多少条数据才能有效回答问题就变得非常不确定。另外一个众所周知的原因,大语言模型是根据token用量进行收费的,交给他的数据越多成本越高。给予大模型更大范围的数据来回答问题不是上上之选。因此,我们必须找到一种能够有效降低这种token用量的方法才行。
待续
目前学术圈对于这种检索出的数据无法经济的回答问题的场景,提出了一个Rerank的构想。就是对于向量检索返回的结果,给予了一次校正机会。可以对问题与检索结果进行二次比较,从而将与问题相关的文本块排在检索结果的前面。关于如何对结果集Rerank以及用混元大语言模型回答问题,我们将在下一篇文章中探讨。
(注:HuggingFists是一款低代码AI应用工具,力图发展为LangChain的低代码平替工具。其社区版可通过以下链接获得https://github.com/Datayoo/HuggingFists)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。