milvus insert数据在s3的存储
原创milvus insert数据在s3的存储
原创
insert数据在s3的存储
对segment进行flush操作,会将数据持久化至s3对象存储。
相关核心代码位置:
ibNode.flushManager.flushBufferData()主要代码在flushBufferData()函数。
代码位置:internal\datanode\flush_manager.go
// flushBufferData notifies flush manager insert buffer data.
// This method will be retired on errors. Final errors will be propagated upstream and logged.
func (m *rendezvousFlushManager) flushBufferData(data *BufferData, segmentID UniqueID, flushed bool, dropped bool, pos *msgpb.MsgPosition) (*storage.PrimaryKeyStats, error) {
field2Insert := make(map[UniqueID]*datapb.Binlog)
field2Stats := make(map[UniqueID]*datapb.Binlog)
kvs := make(map[string][]byte)
tr := timerecord.NewTimeRecorder("flushDuration")
// get segment info
collID, partID, meta, err := m.getSegmentMeta(segmentID, pos)
if err != nil {
return nil, err
}
inCodec := storage.NewInsertCodecWithSchema(meta)
// build bin log blob
binLogBlobs, fieldMemorySize, err := m.serializeBinLog(segmentID, partID, data, inCodec)
if err != nil {
return nil, err
}
// build stats log blob
pkStatsBlob, stats, err := m.serializePkStatsLog(segmentID, flushed, data, inCodec)
if err != nil {
return nil, err
}
// allocate
// alloc for stats log if have new stats log and not flushing
var logidx int64
allocNum := uint32(len(binLogBlobs) + boolToInt(!flushed && pkStatsBlob != nil))
if allocNum != 0 {
logidx, _, err = m.Alloc(allocNum)
if err != nil {
return nil, err
}
}
// binlogs
for _, blob := range binLogBlobs {
fieldID, err := strconv.ParseInt(blob.GetKey(), 10, 64)
if err != nil {
log.Error("Flush failed ... cannot parse string to fieldID ..", zap.Error(err))
return nil, err
}
k := metautil.JoinIDPath(collID, partID, segmentID, fieldID, logidx)
// [rootPath]/[insert_log]/key
key := path.Join(m.ChunkManager.RootPath(), common.SegmentInsertLogPath, k)
kvs[key] = blob.Value[:]
field2Insert[fieldID] = &datapb.Binlog{
EntriesNum: data.size,
TimestampFrom: data.tsFrom,
TimestampTo: data.tsTo,
LogPath: key,
LogSize: int64(fieldMemorySize[fieldID]),
}
logidx += 1
}
// pk stats binlog
if pkStatsBlob != nil {
fieldID, err := strconv.ParseInt(pkStatsBlob.GetKey(), 10, 64)
if err != nil {
log.Error("Flush failed ... cannot parse string to fieldID ..", zap.Error(err))
return nil, err
}
// use storage.FlushedStatsLogIdx as logidx if flushed
// else use last idx we allocated
var key string
if flushed {
k := metautil.JoinIDPath(collID, partID, segmentID, fieldID)
key = path.Join(m.ChunkManager.RootPath(), common.SegmentStatslogPath, k, storage.CompoundStatsType.LogIdx())
} else {
k := metautil.JoinIDPath(collID, partID, segmentID, fieldID, logidx)
key = path.Join(m.ChunkManager.RootPath(), common.SegmentStatslogPath, k)
}
kvs[key] = pkStatsBlob.Value
field2Stats[fieldID] = &datapb.Binlog{
EntriesNum: 0,
TimestampFrom: 0, // TODO
TimestampTo: 0, // TODO,
LogPath: key,
LogSize: int64(len(pkStatsBlob.Value)),
}
}
m.handleInsertTask(segmentID, &flushBufferInsertTask{
ChunkManager: m.ChunkManager,
data: kvs,
}, field2Insert, field2Stats, flushed, dropped, pos)
metrics.DataNodeEncodeBufferLatency.WithLabelValues(fmt.Sprint(paramtable.GetNodeID())).Observe(float64(tr.ElapseSpan().Milliseconds()))
return stats, nil
}BufferData数据结构
// BufferData buffers insert data, monitoring buffer size and limit
// size and limit both indicate numOfRows
type BufferData struct {
buffer *InsertData
size int64
limit int64
tsFrom Timestamp
tsTo Timestamp
startPos *msgpb.MsgPosition
endPos *msgpb.MsgPosition
}
// InsertData example row_schema: {float_field, int_field, float_vector_field, string_field}
// Data {<0, row_id>, <1, timestamp>, <100, float_field>, <101, int_field>, <102, float_vector_field>, <103, string_field>}
//
// system filed id:
// 0: unique row id
// 1: timestamp
// 100: first user field id
// 101: second user field id
// 102: ...
type InsertData struct {
// TODO, data should be zero copy by passing data directly to event reader or change Data to map[FieldID]FieldDataArray
Data map[FieldID]FieldData // field id to field data
Infos []BlobInfo
}
// TODO: fill it
// info for each blob
type BlobInfo struct {
Length int
}FieldData是一个接口,有13种实现:
- FloatVectorFieldData
- Float16VectorFieldData
- BinaryVectorFieldData
- ArrayFieldData
- BoolFieldData
- DoubleFieldData
- FloatFieldData
- Int16FieldData
- Int32FieldData
- Int64FieldData
- Int8FieldData
- JSONFieldData
- stringFieldData
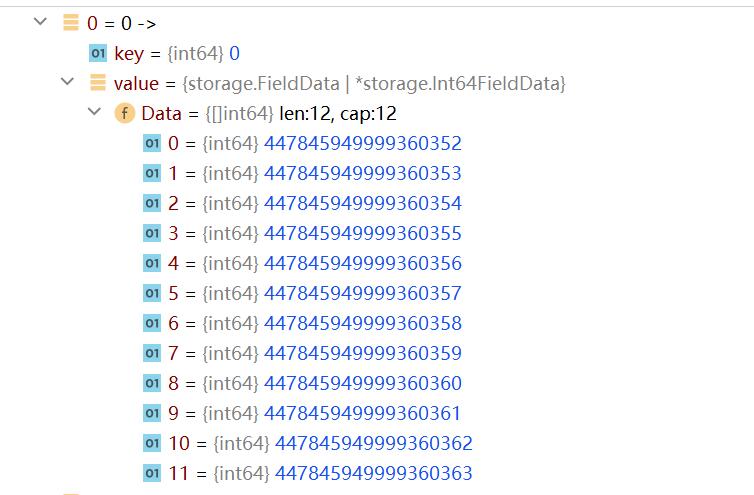
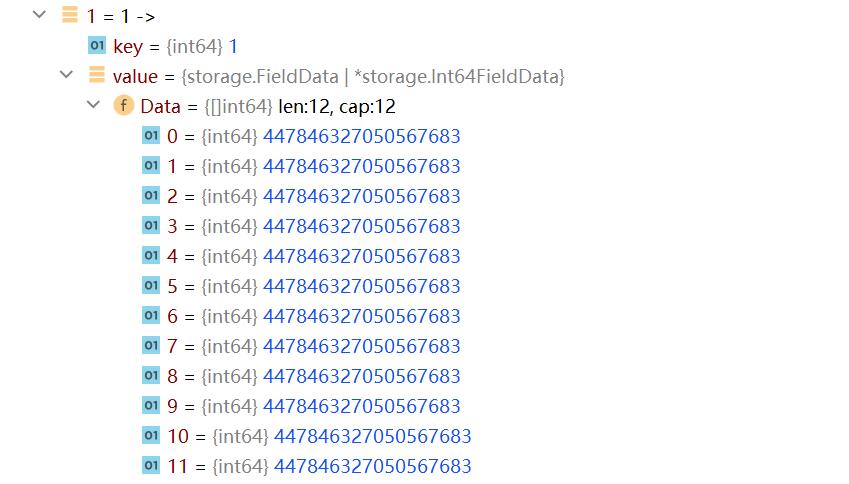
BufferData数据示例

前面的数字01234是FieldID,value是列数据。
这里可以发现collection只有3列数据,这里有5列,多了FieldID为0和1的列。
FieldID为0的是行id。FieldID为1的是时间戳。
序列化
前面的BufferData的数据不会直接存储进s3,而是先序列化后再存储到s3。
inCodec := storage.NewInsertCodecWithSchema(meta)
// build bin log blob
binLogBlobs, fieldMemorySize, err := m.serializeBinLog(segmentID, partID, data, inCodec)inCodec是InsertCodec类型,InsertCodec提供了数据的序列化(Serialize函数)和反序列化(Deserialize函数)。
binLogBlobs是[]*Blob。
// Blob is a pack of key&value
type Blob struct {
Key string
Value []byte
Size int64
RowNum int64
}
Value为byte数组。
kvs
kvs := make(map[string][]byte)遍历binLogBlobs数组,填充kvs。
向量数据在s3的存储路径:
分为insert_log和stats_log。stats_log存储的是主键状态。
files/insert_log/{collectionID}/{partitionID}/{segmentID}/{fieldID}/{logidx}
files/stats_log/{collectionID}/{partitionID}/{segmentID}/{fieldID}/1(flushed)
files/stats_log/{collectionID}/{partitionID}/{segmentID}/{fieldID}/{logidx}(not flushed)logidx每次+1。

kvs的key为s3的路径,values为数据,按列写入s3。
例:
files/stats_log/447847714614087578/447847714614087579/447847714614287586/100为路径,
447847714613886995为文件名。
flushBufferInsertTask
m.handleInsertTask(segmentID, &flushBufferInsertTask{
ChunkManager: m.ChunkManager,
data: kvs,
}, field2Insert, field2Stats, flushed, dropped, pos)flushInsertData
遍历数组写入s3。
// flushInsertData implements flushInsertTask
func (t *flushBufferInsertTask) flushInsertData() error {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
if t.ChunkManager != nil && len(t.data) > 0 {
tr := timerecord.NewTimeRecorder("insertData")
group, ctx := errgroup.WithContext(ctx)
for key, data := range t.data {
key := key
data := data
group.Go(func() error {
return t.Write(ctx, key, data)
})
}
err := group.Wait()
metrics.DataNodeSave2StorageLatency.WithLabelValues(fmt.Sprint(paramtable.GetNodeID()), metrics.InsertLabel).Observe(float64(tr.ElapseSpan().Milliseconds()))
if err == nil {
for _, d := range t.data {
metrics.DataNodeFlushedSize.WithLabelValues(fmt.Sprint(paramtable.GetNodeID()), metrics.InsertLabel).Add(float64(len(d)))
}
}
return err
}
return nil
}t.Write
t.Write()的实现为storage.MinioChunkManager
// Write writes the data to minio storage.
func (mcm *MinioChunkManager) Write(ctx context.Context, filePath string, content []byte) error {
_, err := mcm.putMinioObject(ctx, mcm.bucketName, filePath, bytes.NewReader(content), int64(len(content)), minio.PutObjectOptions{})
if err != nil {
log.Warn("failed to put object", zap.String("bucket", mcm.bucketName), zap.String("path", filePath), zap.Error(err))
return err
}
metrics.PersistentDataKvSize.WithLabelValues(metrics.DataPutLabel).Observe(float64(len(content)))
return nil
}总结
insert按列进行数据序列化后分别写入s3,一个列一个文件。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。