HuggingFists-低代码玩转LLM-腾讯云RAG(2)
原创HuggingFists-低代码玩转LLM-腾讯云RAG(2)
原创
完整视频《玩转数据之低代码LLM 腾讯云RAG》
前序
环境准备
在Cohere网站注册申请API访问账号。
添加Cohere访问账号
1. 点击界面右上角的“user_name”,点击“个人设置”进入“资源账号”界面。
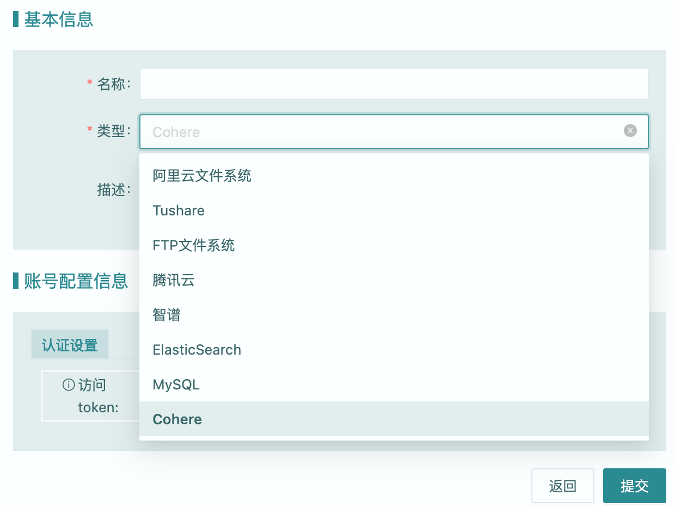
2. 点击“新建账号”按钮,选择“Cohere”账号类型,填写“访问token”,创建混元模型账号。
查询结果重排
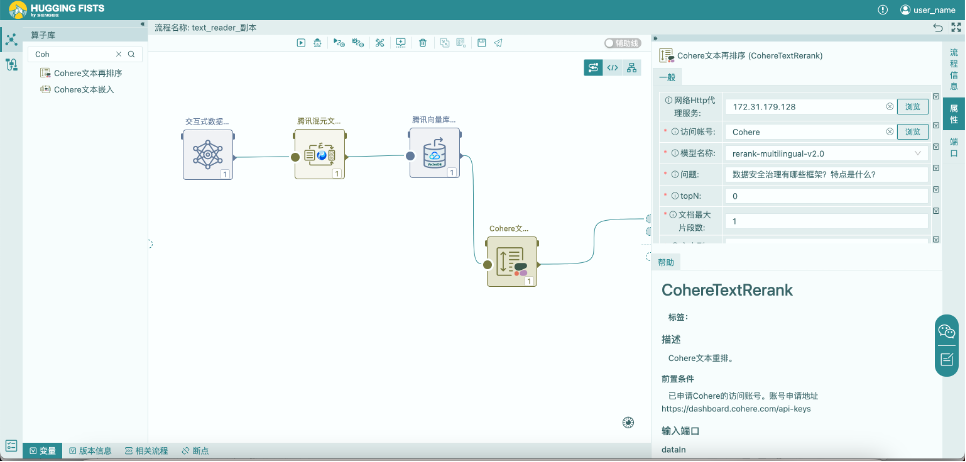
如上图,接上一篇文章《HuggingFists-低代码玩转LLM腾讯云RAG(1)》。我们在流程后加入了一个Cohere的文本重排算子,该算子用于对从向量库中检索到的结果与问题进行优化重排。
Cohere文本重排
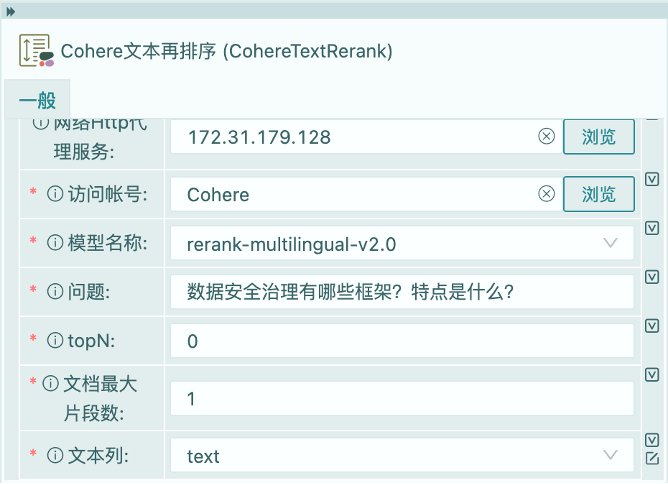
我们为算子设置预先申请好的访问账号”Cohere”。
选中Cohere提供的文本重排模型,Cohere缺省提供的是以英文为基础的文本重排模型。由于我们使用的是中文,所以这里我们需要选用其多语种的文本重排模型“rerank-multilingual-v2.0”。
在问题参数列,我们输入问题信息,该信息无法从流程的数据流中获取,可以通过设置变量进行替换,关于如何使用变量本文不做详细描述,感兴趣的可以通过文章《HuggingFists-低代码玩转LLM RAG(2) --Query》的相关部分进行了解。
topN参数用于控制文本重排算子返回的结果集的大小,当设置为0时,表示输出全部的输入信息。该属性用于控制返回结果的数量,减小I/O字节量。当该值大于1时,返回指定数量的前N个数据。返回的数据按照与问题的相关度,从大到小排序。
文档最大片段数用于控制是否对输入的文本再进行二次排序,若该值大于1,则文本会进行二次拆分,拆分数量由该值控制。对于输入文本颗粒度较大时,可用此参数进一步拆解文本。
文本列设置为”text”列,该列由腾讯向量库算子输出,用于存放与问题相关的文本。每个文本在Cohere的文本重排算法中被视为一个文档。
运行结果

从输出结果的图中我们可以看到,我们认定的能够更好回答问题的相关文本部分被排在了输出结果的首位。Cohere的文本重排算法有效修正了通过腾讯向量库检索回来的文本信息与问题的相关度排序。我们可以以重排后的信息作为问题回答的基础信息了。
LLM问题应答
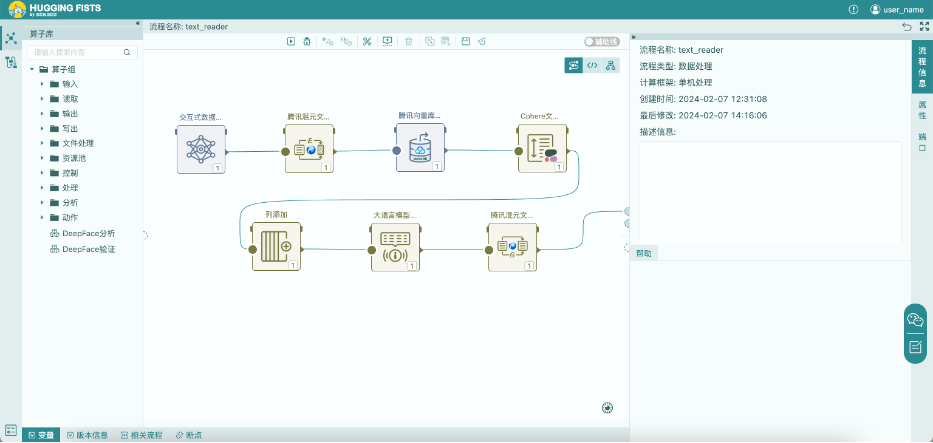
我们在上面流程的基础上,补全问题应答流程。为了搭建方便,我们将Cohere文本重排算子的topN参数设置为1,这样它就会返回一个与问题最相关的文本,也就是我们之前确认过的,能够真正用来回答问题的那个文本。然后我们依次再加入“列添加”、“大语言模型提示”以及“腾讯混元文本生成”算子。
列添加
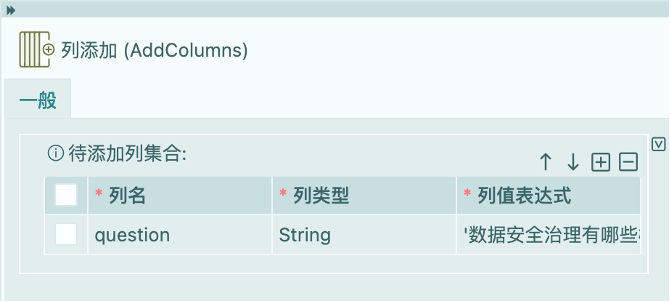
列添加在这里是一个技巧型的应用。主要是因为流程后面的“大语言模型提示”算子使用的提示模板中需要将内容和问题一起组合成为一个提示。而在上一步通过过滤获得的输出信息中只有数据信息,没有问题信息。所以,在这里为数据添加一个问题列,并为其设置具体的问题信息。需要特别注意的是,列值表达式参数支持输入表达式。因此,当为其输入问题信息时,需要在其两侧加上”'”号,表示输入字符串信息,若输入信息不存在”'”号时,表示数据集输入的列名称。
大语言模型提示
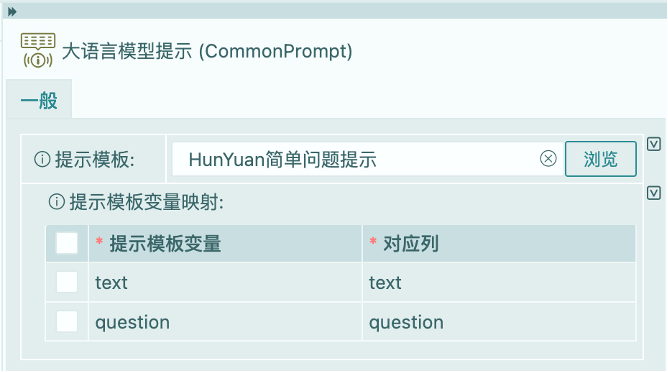
从提示模板库中选取提前准备好的提示模板,并将提示模板中的变量与输入的数据列进行映射。
腾讯混元文本生成

设置预先准备好的混元大语言模型访问账号,使用大语言模型参数的缺省值回答输入的问题。
运行结果
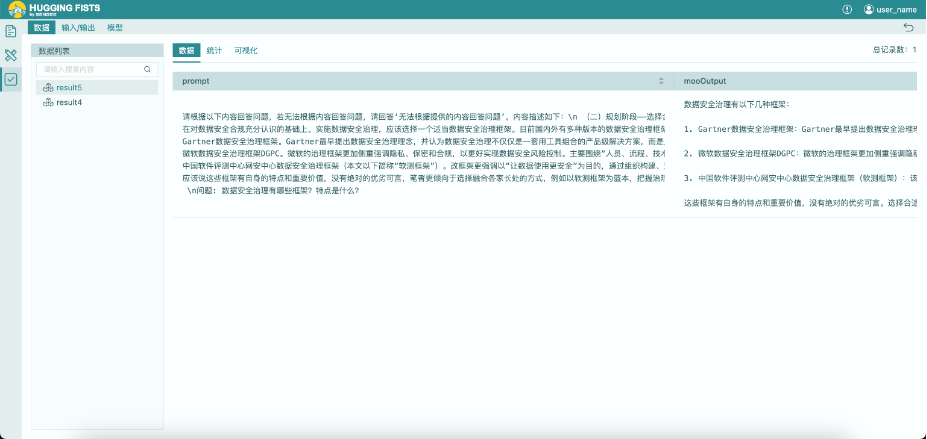
从输出结果我们可以看到,腾讯混元大模型能够很好的根据输入的提示信息,抽象、总结并回答问题。在这点上与其它笔者试用过的ChatGPT、Bard、通义千问等大语言模型不相上下。
结语
使用腾讯云技术栈搭建RAG(检索增强生成)的实验完成了。在这个实验中,我们主要利用了腾讯云的相关技术栈。但这种搭建方式可以扩展到其它的云端服务,可以最大限度的使用各类云端服务搭建起面向个人的RAG应用。实验中,我们引入了Cohere的文本重排算法,用于优化文本的相关度排序,减小提交到大语言模型的提示上下文的长度。这里有两方面内容需要权衡,一是成本问题,即Cohere的文本重排算法本质上也是收费的,那么到底是重排的收费更高还是生成的收费更高是我们需要在方案选取时思考的问题;另一个是效率问题,到底是重排+文本生成的效率高还是直接进行文本生成的效率更高。不同的技术栈可能在这两个问题权衡时会有不同的表现,使用者在使用时需要综合考虑。
HuggingFists是一款低代码AI应用工具,对于非开发人员更友好,相较于LangChain,其是一种更成熟的工程落地选择。实验中给出的文档相对都比较理想,不需要进行较为复杂的信息提取。而在实际工程中,可能需要进行图片、表格的抽取,文件格式转换等各类问题,也就是在传统结构化数据处理领域中我们常说的ETL过程。笔者认为,这个过程在非结构数据处理领域依然存在,不会因为数据格式的改变而消失。HuggingFists工具恰恰可以支持完成对非结构化数据的ETL工作,这也是笔者认为其相较于LangChain在工程落地方面更成熟的原因。
(注:HuggingFists社区版可通过以下链接获得https://github.com/Datayoo/HuggingFists)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。