音视频开发之旅(68)-SD文生图
原创
目录
效果展示
sd使用流程:选大模型、写关键词和设置参数
SDWebui文生图调用流程
StableDiffusion原理浅析
参考资料
一、效果显示

1girl,smile,highres,wallpaper,in summer,landscape

1girl,smile,highres,wallpaper,in summer,city,street


二、sd使用流程:选大模型、写关键词和设置参数
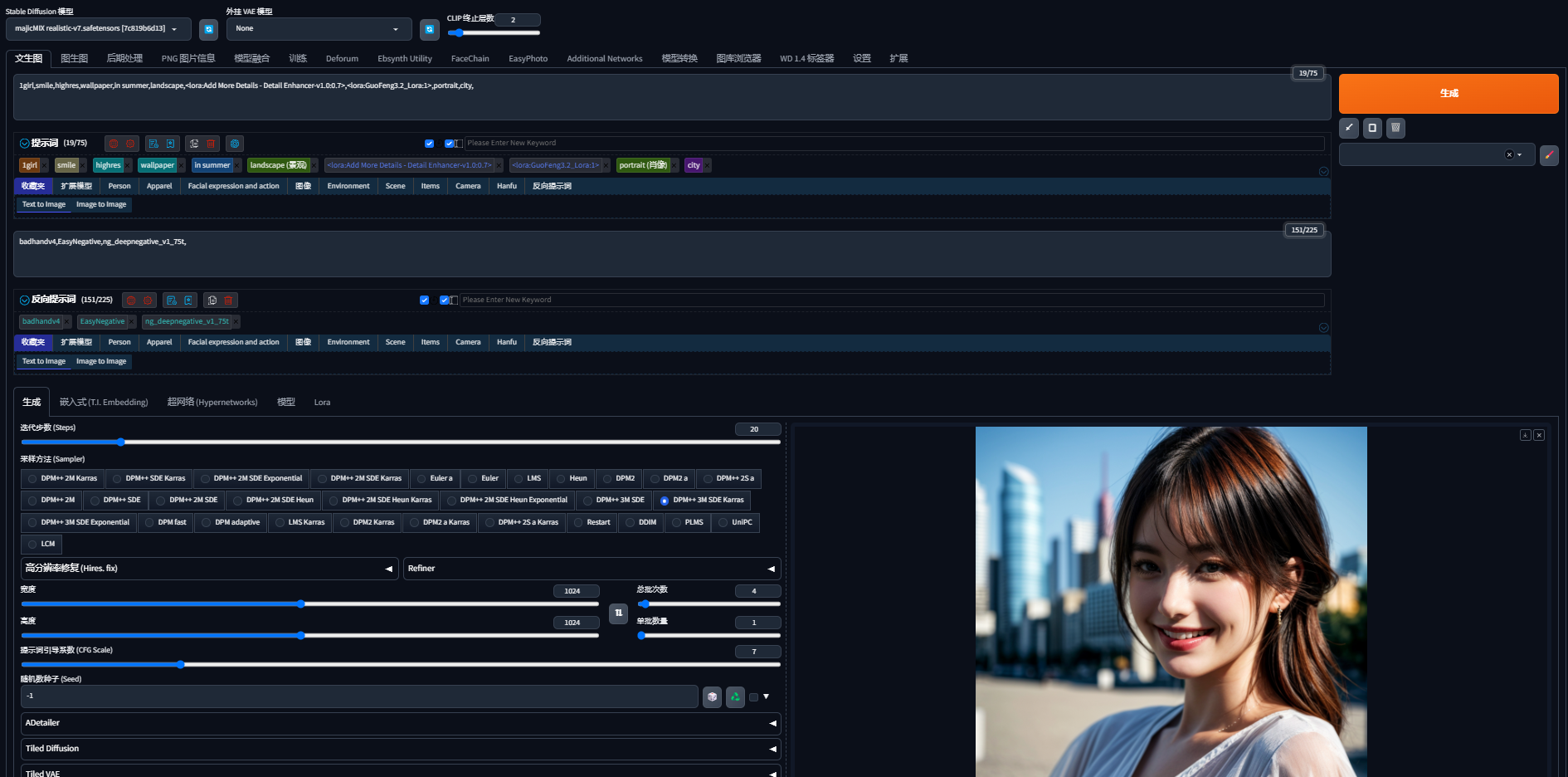
sdwebui的界面如上所示,可以分为模型(基础模型+lora模型)、提示词(正向提示词和反向提示词)以及参数设置(迭代步数、采样方法、分辨率等)
2.1 大模型分类
可以按照图片类型分为 二次元、2.5D和写实几个大类 常用模型如下所示
二次元:Anything系列、Counterfeit系列、Cetus-Mix系列、Meina-Mix系列、AW-Painting
2.5D:国风系列、Rev-Animated系列、Lyriel系列、BreakDomainRealistic系列
写实:ChilloutMix系列、RealisticVision系列、Deliberate系列、Majic系列
LoRA模型,Low-Rank Adaptation of Large Language Models,冻结预训练好的模型权重参数,然后在每个Transformer(Transforme就是GPT的那个T)块里注入可训练的层,可以理解为大模型的一个小模型。LoRA模型可以应用于各种不同的领域和用途,比如:角色lora、风格lora和服装lora等
C站civitai.com/上提供了各种类型的大模型和lora模型,供下载使用。
2.2 提示词
提示词分为正向提示词和反向提示词。
正向提示词可以分为 主题、场景风格、人物、情绪、衣着、质量
eg:上面生成的图片提示词如下
1girl,smile,highres,wallpaper,in summer,city,street,landscape,<lora:GuoFeng3.2_Lora:1>,
通用反向提示词
EasyNegative, ng_deepnegative_v1_75t, badhandv4,(worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((grayscale)), bad anatomy,DeepNegative, skin spots, acnes, skin blemishes,(fat:1.2),facing away, looking away,tilted head, lowres,bad anatomy,bad hands, missing fingers,extra digit, fewer digits,bad feet,poorly drawn hands,poorly drawn face,mutation,deformed,extra fingers,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,missing arms,missing legs,extra digit, extra arms, extra leg, extra foot,teethcroppe,signature, watermark, username,blurry,cropped,jpeg artifacts,text,error
webui种可以安装sd-webui-prompt-all-in-one github.com/Physton/sd-… 插件,快速选定各种类别的提示词
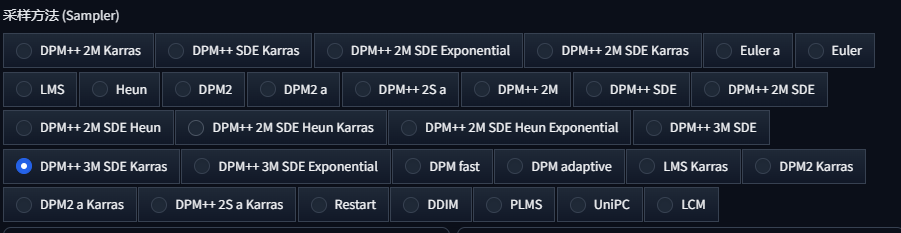
分辨率:设定输出图片的宽高
单批次数量,即依次生成几张图片;总批次,总共串行执行多次批次,通过修改总批次数量来控制生成多少张图片,尽量不要使用单批生成多张图片,除非显存很大。
提示词引导系数:这个是一个比较有意思的参数,通过随机种子生成一张高斯噪声图片,通过迭代步数不断的进行去噪,而提示词引导系数直接决定了生成的图片受prompt影响的程度,一般设置为6-7.
当然还有其他重要参数和插件,比如controlnet、animatediff、easyphoto和adetailer等,后续用到时再进一步探讨。
三、SDWebui文生图调用流程
点击webui通过gradio和fastapi来实现通过点击生成按钮调用api函数进行图片的生成
3.1 初始化 initialize.initialize
# 初始化LatentDiffusion
# stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py
LatentDiffusion.__init__
#初始化CLIP 文本编码器
#stable-diffusion-stability-ai/ldm/modules/encoders/modules.py
FrozenCLIPEmbedder.__init__
3.2 入口方法:modules.api.api.Api.text2imgapi
#如果使用了第三方的插件,eg:easyphoto等,通过init_script_args获取到对应的插件
script_args = self.init_script_args(txt2imgreq, self.default_script_arg_txt2img, selectable_scripts, selectable_script_idx, script_runner)
#如果插件不为空,走插件处理流程,否则直接process,我们直接看process_images的流程
if selectable_scripts is not None:
processed = scripts.scripts_txt2img.run(p, *p.script_args) # Need to pass args as list here
else:
processed = process_images(p)
3.3 process_images 加载sd基础模型和vae模型
for k, v in p.override_settings.items():
opts.set(k, v, is_api=True, run_callbacks=False)
#加载sd大模型
if k == 'sd_model_checkpoint':
sd_models.reload_model_weights()
#加载vae模型
if k == 'sd_vae':
sd_vae.reload_vae_weights()
#继续调用process生成图片
res = process_images_inner(p)
3.4 process_images_inner
#获得编码后的prompt
p.prompts = p.all_prompts[n * p.batch_size:(n + 1) * p.batch_size]
p.negative_prompts = p.all_negative_prompts[n * p.batch_size:(n + 1) * p.batch_size]
p.seeds = p.all_seeds[n * p.batch_size:(n + 1) * p.batch_size]
p.subseeds = p.all_subseeds[n * p.batch_size:(n + 1) * p.batch_size]
#采样
samples_ddim = p.sample(conditioning=p.c, unconditional_conditioning=p.uc, seeds=p.seeds, subseeds=p.subseeds, subseed_strength=p.subseed_strength, prompts=p.prompts)
#解码
x_samples_ddim = decode_latent_batch(p.sd_model, samples_ddim, target_device=devices.cpu, check_for_nans=True)
#保存生成的图片
images.save_image(image, p.outpath_samples, "", p.seeds[i], p.prompts[i], opts.samples_format, info=infotext(i), p=p)
3.5 VAE解码
stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py#decode_first_stage
self.first_stage_model.decode(z)
#最终调用到VAEDecoder模型进行解码
stable-diffusion-stability-ai/ldm/modules/diffusionmodules/model.py#Decoder.forward
整体流程如下:
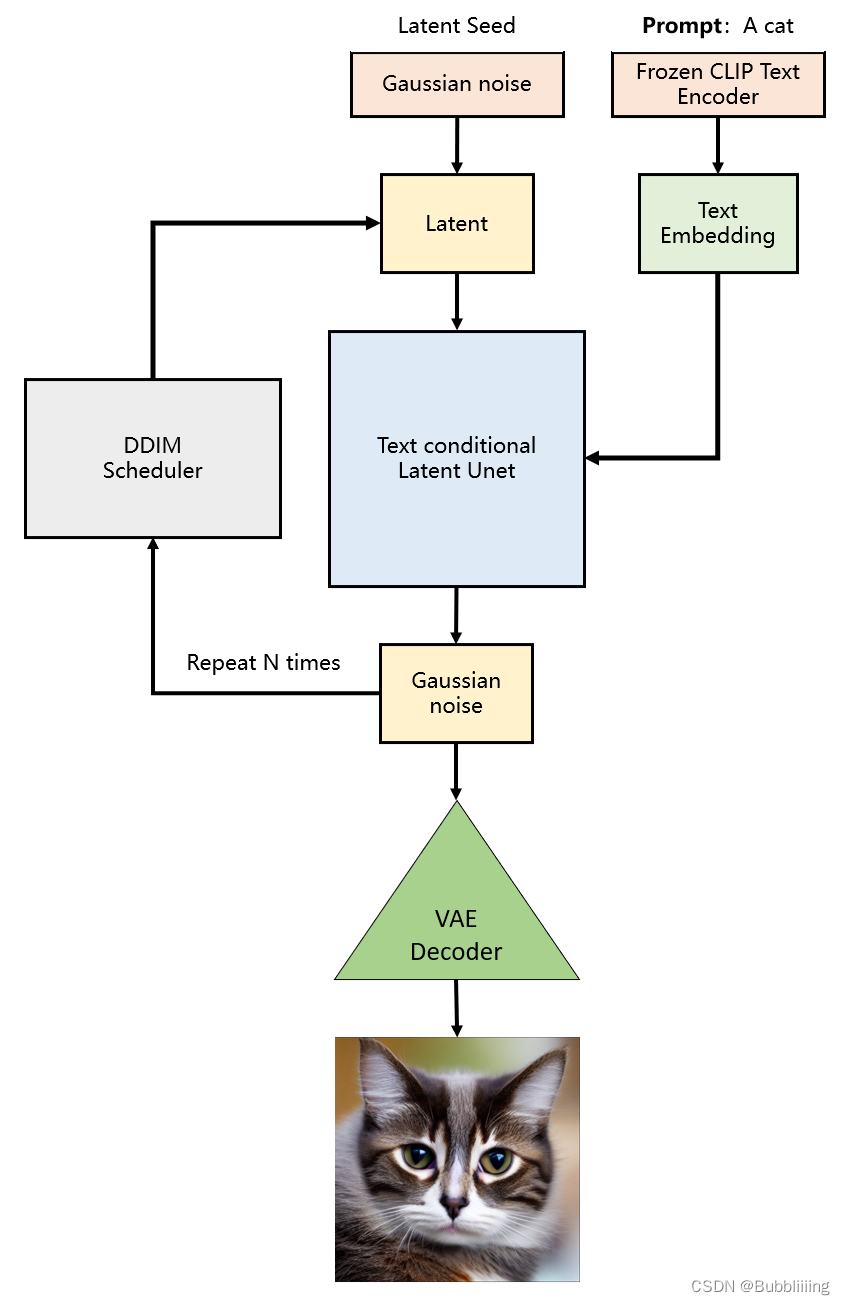
图片来自:AIGC专栏2——Stable Diffusion结构解析-以文本生成图像
四、StableDiffusion原理浅析
Stable Diffusion基于扩散模型,使用LAION-5B数据集进行预训练。在推理时通过不断的去噪,生成目标图片。
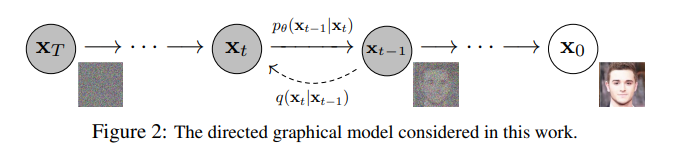
图片来自:Denoising Diffusion Probabilistic Models
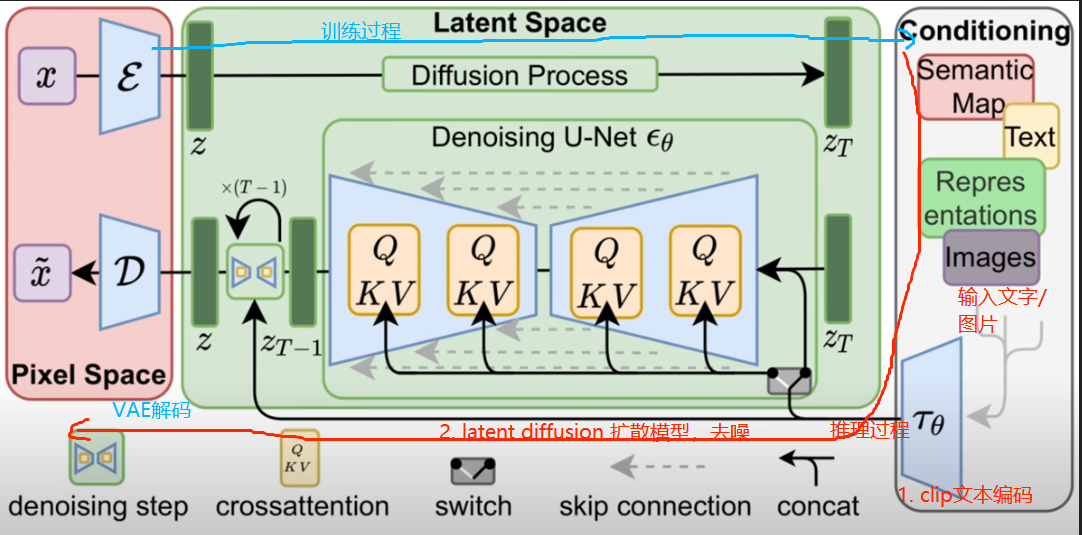
Stable Diffusion有三部分组成:
1. CLIP Embedder 文本编码器
2. Diffusion扩散模型(U-Net网络)
3. Variational Autoencoder(VAE)变分自编码器
在训练的时候不断的对原图片添加正态分布噪声,得到latent space噪声。
在推理时随机生成一个latent space空间的初始噪声,
用户输入的prompt通过FrozenCLIPEmbedder获得Text Embedding,Timestips获取Timesteps Embedding,一起送给Diffusion模型;
Diffusion模型采用Unet网络,UNetModel由ResBlock和Transformer模块组成,ResBlock用于结合时间步Timesteps Embedding,Transformer模块用于结合文本Text Embedding;
经过N步骤采样去噪生成latent space的Gaussian noise,再送给VAE解码模块解码出图像

图片来自:Stable Diffusion 原理详解
图片来自:AIGC专栏2——Stable Diffusion结构解析
五、参考资料
High-Resolution Image Synthesis with Latent Diffusion Models arxiv.org/abs/2112.10…
Denoising Diffusion Probabilistic Models arxiv.org/pdf/2006.11…
AIGC专栏2——Stable Diffusion结构解析-以文本生成图像(文生图,txt2img)为例 blog.csdn.net/weixin_4479…
从零开始学AI绘画,万字Stable Diffusion终极教程!zhuanlan.zhihu.com/p/659211251
万字总结:Stable Diffusion_Prompt详细指南,成为SD提示词专家,看这一篇就够了 blog.csdn.net/m0_71745258…
有哪些的?相见恨晚?的人气模型 zhuanlan.zhihu.com/p/636330920
扩散模型 blog.csdn.net/yujianmin19…
Stable Diffusion 原理详解 www.youtube.com/watch?v=I62…
李宏毅老师【生成式AI】Stable Diffusion、DALL-E、Imagen 背后共同的套路 www.bilibili.com/video/BV18a…
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。