LoRA ±КәЗ - plus studio
LoRA ±КәЗ - plus studio

LoRA ±КәЗ
ЧФИ»УпСФө¦АнµДТ»ёцЦШТҒ·¶КҢ°ьАЁ¶ФТ»°гБмУтКэңЭµДөу№жДӘФ¤СµБ·ғН¶ФМШ¶ЁИООс»тБмУтµДККУ¦ҰӘµ±ОТГЗФ¤СµБ·ёьөуµДДӘРНК±Ә¬ЦШРВСµБ·ЛщУРДӘРНІОКэµДНкХыОұµч±дµГІ»ДЗГөүЙРРҰӘLoRA[1]¶іҢбФ¤СµБ·ДӘРНИЁЦШІұҢ«үЙСµБ·µДЦИ·ЦҢвңШХуЧұИлµҢ Transformer әЬ№№µДГүТ»ІгЦРӘ¬өуөуәхЙЩБЛПВУОИООсµДүЙСµБ·ІОКэµДКэБүҰӘУлУГ Adam ОұµчµД GPT-3 175B Па±ИӘ¬LoRA үЙТФҢ«үЙСµБ·ІОКэµДКэБүәхЙЩБЛ 10,000 ±¶Ә¬GPU ДЪөжРиЗуәхЙЩБЛ 3 ±¶ҰӘ
КІГөКЗlow-rank
КЧПИРиТҒГчИ·Т»Р©КІГөКІГөКЗңШХуµДЦИӘ¬rank
ФЪ№ъДЪµД±ңүЖПЯРФөъКэүОіМЦРОТГЗКЗХвСщ¶ЁТеңШХуµДЦИµД
ЙиФЪңШХу\(A\) ЦРУРТ»ёцУРТ»ёцІ»µИУЪ\(0\) µД\(r\) ҢЧЧУКҢ\(D\) ,ЗТЛщУР\(r+1\) ҢЧЧУКҢ(Из№ыөжФЪµД»°)¶әµИУЪ\(0\) Ә¬ДЗГө\(D\) іЖОҒңШХу\(A\) µДЧоёЯҢЧ·ЗБгЧУКҢӘ¬Кэ\(r\) іЙОҒңШХуµДЦИӘ¬әЗОҒ\(R(A)\) ҰӘІұ№ж¶ЁБгңШХуµДЦИОҒ0ҰӘ[2]
ФхГөЗуңШХуµДЦИДШӘ¬ғЬәтµӨАІңНКЗ°СТ»ёцңШХу»ҮіЙRREF(үО±ңЙП№ЬХвёцҢРРРЧоәтРРңШХу)И»ғуКэТ»ПВГүТ»РРµЪТ»ёц·ЗБгФҒЛШЛщФЪБРОҒµӨО»ПтБүµДёцКэңНүЙТФБЛҰӘ
ғГµДӘ¬·ұЙъБЛКІГөӘүғГПсІұГ»УРҢвКНЗеіюЦИµҢµЧКЗКІГөҰӘ
КµәКЙП°ҰӘ¬ЦИ·өУіБЛңШХуАпБРПтБүПЯРФПа№ШµДіМ¶ИӘ¬ТвЛәңНКЗДгңШХуАпµДДЗәёёцПтБүДЬҰ°Ц§Ұ±іцАөәёО¬Ә¬әЩИзЛµОТУРТ»ёцңШХуАпГжУРОеёцПтБүӘ¬µ«КЗЛыµДңШХуЦИКЗ3,ХвңНЛµГчОеёцПтБүЦ»ДЬіЕЖрТ»ёц3О¬үХәдӘ¬КӘПВБҢёцПтБүүЙТФ±»ИэёцІ»ДЬ±»»ӨПа±нКңµДПтБү±нКң(үО±ңЙП№ЬХвёцҢРПЯРФПа№ШғНПЯРФОЮ№Ш)Ә¬УГАоғкТгµД»°ЛµңНКЗХвАпУРБҢёцПтБүФЪ"ЛӘ·П"ҰӘ
НЖәцТ»ПВ3Blue1BrownµДКУЖµhttps://www.bilibili.com/video/BV1ys411472E/?spm_id_from=333.999.0.0Ә¬ПЯРФөъКэҢІµДғЬЗеіюҰӘ
ёГЗеіюБЛЦИКЗКІГөӘ¬µНЦИКЗКІГөңНғЬғГАнҢвБЛӘ¬ңНКЗУРёцңШХуЛыµДЦИғЬµНӘ¬РҰУЪңШХуАпГжПтБүµДёцКэ(ПтБүЧйПЯРФПа№Ш/УРПтБүФЪ"ЛӘ·П")ҰӘ
ДгүЙДЬ»бПлОКӘ¬LoRAЧчОҒТ»ёцОұµчөуУпСФДӘРНғННәОДөуДӘРНµД·Ң·ЁӘ¬№ШңШХуµДЦИКІГөКВӘүФЪ2020ДкӘ¬[3] ЦёіцөуДӘРНµДСµБ·КµәК·ұЙъФЪlow-rankүХәдЙПµД,ЛщТФЛµОТГЗЦ»РиТҒ№№ФмТ»ёцµНЦИүХәдПВµДСµБ··Ң·ЁңНүЙТФБЛҰӘ
ОҒКІГөРиТҒLoRA
LoRAІұІ»КЗµЪТ»ёцҢшРРОұµчөуДӘРНµДӘ¬өУЗЁТЖС§П°үҒКәУРғЬ¶аµДіұКФӘ¬ТФУпСФҢЁДӘОҒАэӘ¬ФЪУРР§ККУ¦·ҢГжУРБҢЦЦН»іцµДІЯВФӘғМнәУККЕдЖчІг»тУЕ»ҮДіЦЦРОКҢµДКдИлІгә¤»оҰӘИ»¶шӘ¬ХвБҢЦЦІЯВФ¶әУРЖдңЦПЮРФӘ¬УИЖдКЗФЪөу№жДӘғНСУіЩГфёРµДЙъІъіҰң°ЦРҰӘ ### МнәУККЕдЖчІг(ТэИлНЖАнСУіЩ) ККЕдІг(Adapter) КµәКЙПңНКЗФЪФ±ңµДәЬ№№ЙПМнәУТ»Р©ІгӘ¬ИГЛыС§µҢРВµД¶«ОчҰӘАэИз[4]
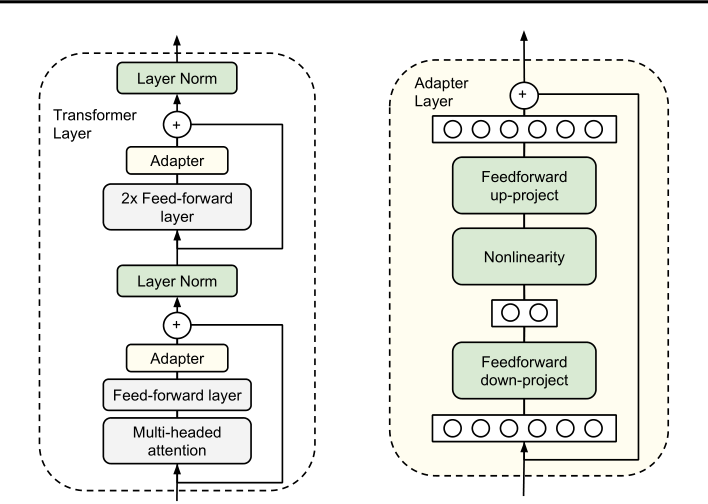
ЧуІаОҒГүёц Transformer ІгМнәУККЕдЖчДӘүйБҢөОӘғФЪ¶аН·ЧұТвБ¦µДН¶У°ғНБҢёцЗ°АҰІгЦ®ғуҰӘУТІаККЕдЖчУЙТ»ёцЖүң±ЧйіЙӘ¬ёГЖүң±°ьғ¬Па¶ФУЪФКәДӘРНЦРµДЧұТвБ¦ІгғНЗ°АҰІгµДІОКэғЬЙЩҰӘККЕдЖч»№°ьғ¬Мш№эБ¬ҢУҰӘФЪККЕдЖчµчХыЖЪәдӘ¬ВМЙ«ІгФЪПВУОКэңЭЙПҢшРРСµБ·Ә¬Хв°ьАЁККЕдЖчҰұІг№йТ»»ҮІОКэғНЧоЦХ·ЦАаІгӘЁНәЦРОөПФКңӘ©ҰӘ
ЛдИ»үЙТФНЁ№эРЮәфІг»тАыУГ¶аИООсЙиЦГАөәхЙЩХыМеСУіЩӘ¬µ«Г»УРЦ±ҢУµД·Ң·ЁИЖ№эККЕдЖчІгЦРµД¶оНвәЖЛгҰӘФЪµӨёц GPU ЙП¶Ф GPT-2ҢйЦКФЛРРНЖАнӘ¬ОТГЗүөµҢФЪК№УГККЕдЖчК±СУіЩПФЧЕФцәУӘ¬әөК№Жүң±О¬¶И·ЗіӘРҰҰӘ
УЕ»ҮДіЦЦРОКҢµДКдИлІгә¤»о(ғЬДСҢшРР)
ЧчХЯ№ЫІмµҢЗ°ЧғµчХығЬДСУЕ»ҮӘ¬ІұЗТЛьµДРФДЬФЪүЙСµБ·ІОКэЦР·ЗµӨµчµШ±д»ҮӘ¬Ц¤КµБЛФКәВЫОДЦРµДАаЛЖ№ЫІмҢб№ыҰӘёьёщ±ңµДКЗӘ¬±ӘБфРтБРі¤¶ИµДТ»Іү·ЦҢшРРККУ¦±ШИ»»бҢµµНүЙУГУЪө¦АнПВУОИООсµДРтБРі¤¶ИӘ¬ЛщТФЧчХЯ»іТЙУлЖдЛы·Ң·ЁПа±ИӘ¬µчХыМбКңµДРФДЬҢПµНҰӘ
LoRAµҢµЧФхГө№¤Чч
ЙсңНшВз°ьғ¬Рн¶аЦөРРңШХуіЛ·ЁµДГЬәҮІгҰӘХвР©ІгЦРµДИЁЦШңШХуНЁіӘңЯУРВъЦИҰӘ¶ФУЪФ¤СµБ·µДИЁЦШңШХу \(W_0 ҰК R^{dҰБk}\)Ә¬ОТГЗНЁ№эК№УГµНЦИ·ЦҢв \(W_0 + ¦¤W = W_0 + BA\) ±нКңғуХЯАөФәКшЖдёьРВӘ¬ЖдЦР \(B ҰК R^{dҰБr} , A ҰК R^{rҰБk}\)Ә¬ЦИ\(r\) ОҒ \(min(d, k)\)ҰӘФЪСµБ·ЖЪәдӘ¬\(W_0\) ±»¶іҢбІұЗТІ»ҢУКХМЭ¶ИёьРВӘ¬¶ш \(A\) ғН \(B\) °ьғ¬үЙСµБ·µДІОКэҰӘЧұТв \(W_0\) ғН \(¦¤W = BA\) ¶әіЛТФПаН¬µДКдИлӘ¬ЛьГЗёчЧФµДКдіцПтБү°өЧш±кЗуғНҰӘ¶ФУЪ \(h = W_0x\)Ә¬ОТГЗРЮёДғуµДЗ°Птө«µЭІъЙъӘғ\[h=W_0x+\Delta Wx=W_0x+BAx\] ІОКэіхКә»ҮК±Ә¬ОТГЗ¶Ф A К№УГЛж»ъёЯЛ№іхКә»ҮӘ¬B К№УГБгӘ¬ТтөЛ ¦¤W = BA ФЪСµБ·үҒКәК±ОҒБгҰӘЛщТФ \(\Delta W = BA\) ФЪСµБ·үҒКәК±ОҒБг.УГ\(\frac{\alpha}{r}\) Лх·Е \(¦¤Wx\)Ә¬ЖдЦР \(\alpha\) КЗ \(r\) ЦРµДТ»ёціӘКэҰӘФЪК№УГ Adam ҢшРРУЕ»ҮК±Ә¬Из№ыОТГЗККµ±µШЛх·ЕіхКә»ҮӘ¬µчХы \(\alpha\) УлµчХыС§П°ВКөуЦВПаН¬ҰӘТтөЛӘ¬ОТГЗЦ»РиҢ« \(\alpha\) ЙиЦГОҒОТГЗіұКФµДµЪТ»ёц rӘ¬¶шІ»¶ФЖдҢшРРµчХыҰӘµ±ОТГЗёД±дК±Ә¬ХвЦЦЛх·ЕУРЦъУЪәхЙЩЦШРВµчХыі¬ІОКэµДРиТҒ
ХвЦЦОұµч·ҢКҢУРБҢёцғГө¦
- НкИ«·ғ»ҮµДОұµч·ҢКҢ
- І»»бТэИлНЖАнСУіЩ
ФЪНЖАнµДК±ғтӘ¬Ц»РиТҒ°С\(B\)ғН\(A\) БҢёцңШХуіЛЖрАөИ»ғуәУ»ШµҢФПИµДІОКэңШХуңННкіЙБЛІОКэµДёьРВ

ІОүәОДПЧ
- LoRA: Low-Rank Adaptation of Large Language Models. (n.d.). ??
- Н¬әГөуС§КэС§Пµ№¤іМКэС§-ПЯРФөъКэ(µЪ6°ж)±КәЗғНүОғуП°Мв(ғ¬үәСРХжМв)ПкҢв. (2015). ??
- Aghajanyan, A., Gupta, S., & Zettlemoyer, L. (2021). Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Presented at the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online. https://doi.org/10.18653/v1/2021.acl-long.568 ??
- Houlsby, N., Giurgiu, A., Jastrz?bski, S., Morrone, B., Laroussilhe, Q., Gesmundo, A., Ұ Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP. International Conference on Machine Learning. ??
±ңОД·ЦПнЧФ ЧчХЯёцИЛХңµг/І©үН?З°НщІйүө
ИзУРЗЦИЁӘ¬ЗлБҒПµ cloudcommunity@tencent.com ЙңіэҰӘ
±ңОДІОУл?МЪС¶ФЖЧФГҢМе·ЦПнәЖ»®? Ә¬»¶УИИ°®РөЧчµДДгТ»ЖрІОУлӘҰ