不止有SORA!一文带你了解 AI 视频生成技术的探索与趋势
不止有SORA!一文带你了解 AI 视频生成技术的探索与趋势

随着科技的不断进步,生活中所见的一切已经不再局限于现实。在这个数字化时代,无论是图片、视频,还是其他形式的媒体内容,都有可能是通过 AI 算法生成的。精彩的场景、动人的情节,甚至栩栩如生的角色,都可能是由 AI 算法创造出来的。当你观看一段视频时,你是否曾思考过这个问题:这是一个真实的视频,还是由 AI 算法生成的呢?
前几天 Sora 横空出世震撼全场,今天 Stable Diffusion 3 也如约而至!在生成式 AI 发展正如火如荼的今天,许多小伙伴也在使用趋动云强大且灵活的算力进行相关探索。
本篇文章将探讨视频生成技术的发展现状,介绍一些近期刷屏的视频生成工具,包括商业产品和开源项目。
Sora
Sora 是由 OpenAI 开发的 text-to-video 模型。它可以根据一段简短的提示词,生成 60 秒的视频,不仅可以理解提示词内容,还能处理细致的场景,运用复杂的运镜、生成丰富的情感状态,实现真实的物理交互。
- 官网链接:https://openai.com/sora
Sora 效果演示
提示词:一位时尚的女士穿着黑色皮夹克、红色的长裙和黑色短靴、手拿黑色手袋,在东京一条灯光温暖、霓虹灯闪烁、带有动感城市标志的街头自信而随意地行走。她戴着太阳镜,大红唇。街道潮湿而有反光效果,色彩缤纷的灯光仿佛在地面上营造出镜面效果,许多人在街道上来往。
Stable Diffusion 3
Stable Diffusion 3 是由 Stability AI 公司发布的新一代图像合成模型。相比前一代产品,它能生成细节丰富的多主体图像,并提高了文本生成的质量和准确性。
特点
- SD3 的参数数量范围从 8 亿到 80 亿不等。允许不同版本模型在各种设备上运行——从智能手机到服务器。意味着 AI 算力消耗或许会更低,推理速度却更快。
- SD3 系列采用了 diffusion transformer 架构(类似于Sora),一种利用 AI 创建图像的新方法,它将通常的图像构建模块(如 U-Net 架构)换成了一个在小块图片上工作的系统。这种方法不仅能高效扩展,还能生成更高质量的图像。
- 另外,还采用“flow matching”技术,一种创建 AI 模型的技术,可以通过学习如何从随机噪音顺利过渡到结构化图像来生成图像。不需要模拟流程中的每一个步骤,仅专注于图像创建应遵循的整体方向或流程。
- Stability 公司表示,一旦测试完成,其权重可以免费下载并在本地运行。
- 可以实现视频、3D等功能。
SD3 效果演示

提示词:史诗般的动漫艺术风格,一位巫师站在夜间的山顶上,向黑暗的天空施放咒语,上面写着由彩色能量生成的“Stable Diffusion 3”文字

提示词:一辆跑车的夜间照片,侧面写有“SD3”字样,汽车在赛道上高速行驶,巨大的路标上写着“FASTER”的文字。
Stable Video Diffusion
Stable Video Diffusion 是由 Stability AI 发布的视频生成大模型,是基于他们原有的 Stable Diffusion 文生图模型开发的,专门用于视频生成的大型模型。
- 论文链接:https://static1.squarespace.com/static/6213c340453c3f502425776e/t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf
- 项目链接:https://github.com/Stability-AI/generative-models
- huggingface链接:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
在线体验
- https://replicate.com/stability-ai/stable-video-diffusion
在该页面可以直接查看演示效果图,也可以使用自己的图片上传生成视频。

图源网络

生成结果
VideoPoet
VideoPoet 是由谷歌开发的一种大型语言模型(LLM),能够胜任多种视频生成任务,包括 text-to-video、image-to-video、video stylization、video inpainting & outpainting 和 video-to-audio。VideoPoet 的一大特点是可提升视频时长,通过重复的方法延长视频的长度,即让 AI 根据视频的最后一秒预测下一秒的内容。
- 官网链接:https://sites.research.google/videopoet/
- 论文链接:https://storage.googleapis.com/videopoet/paper.pdf
VideoPoet 效果演示
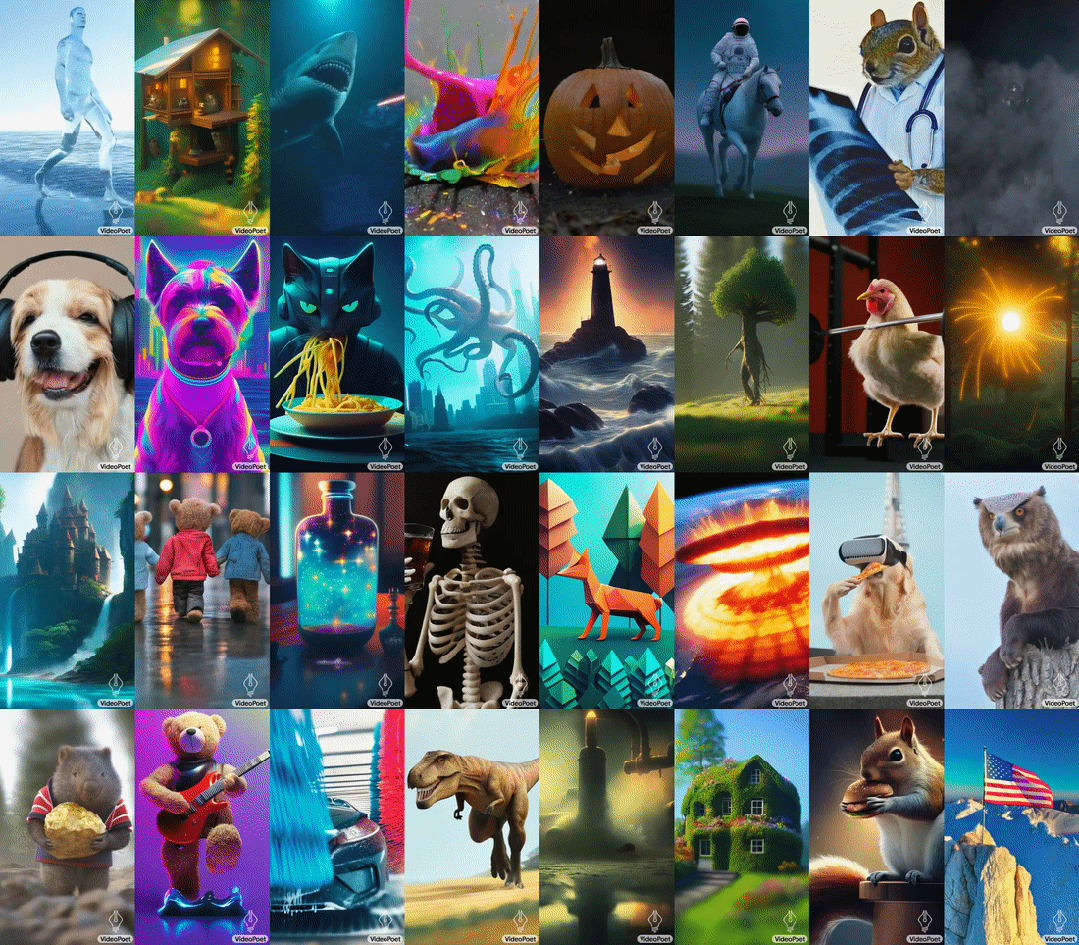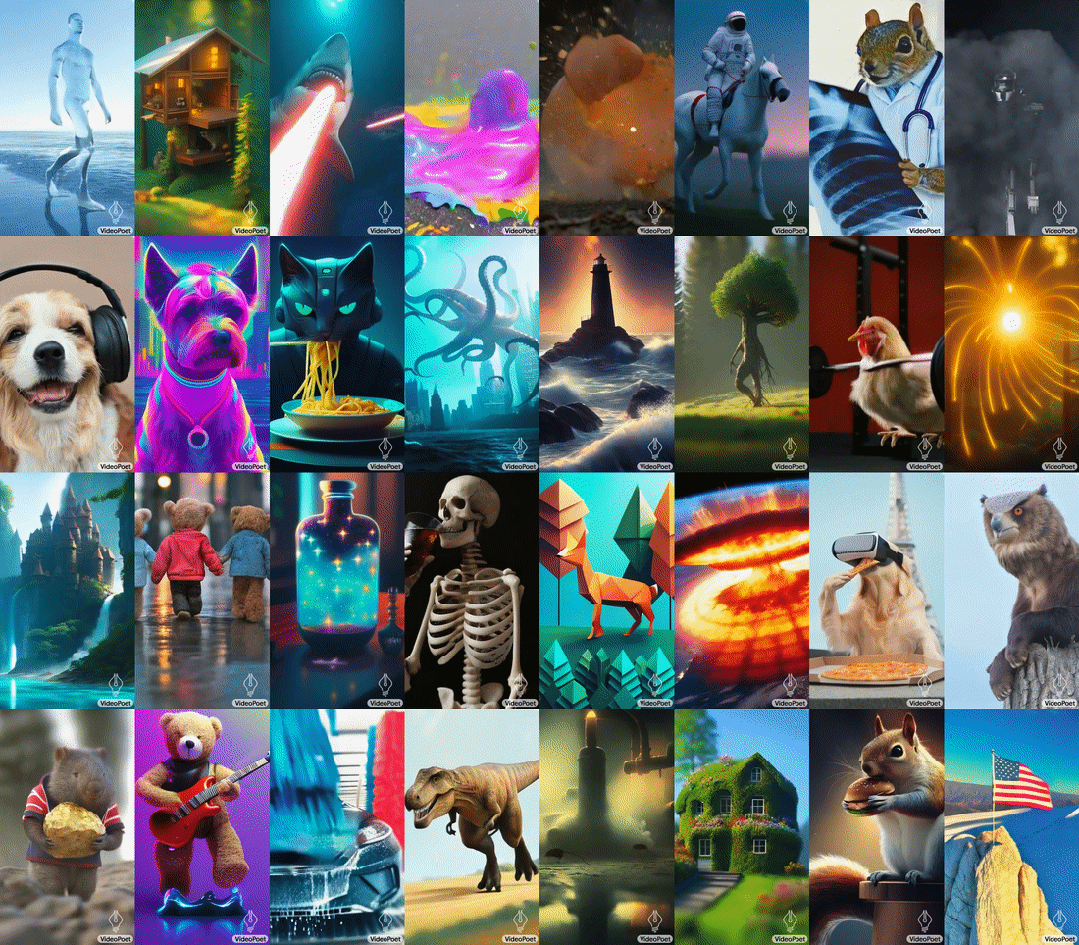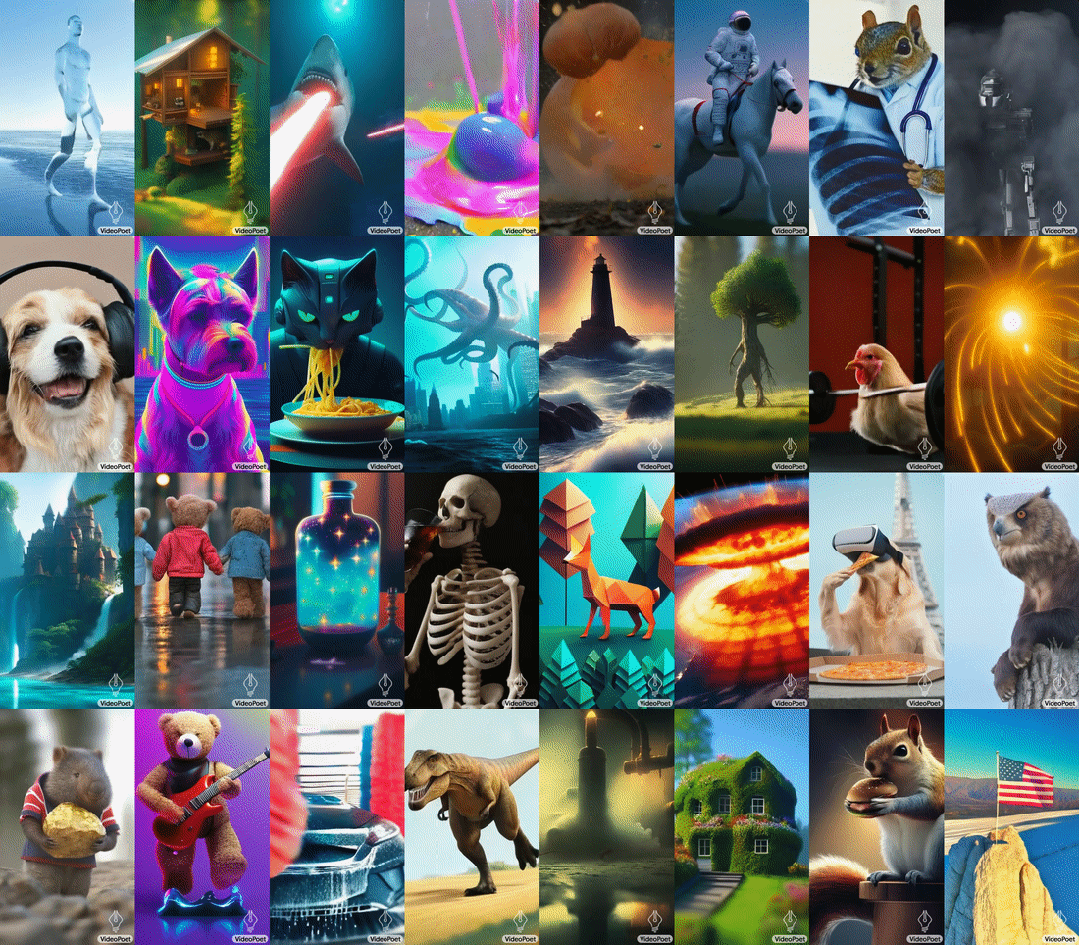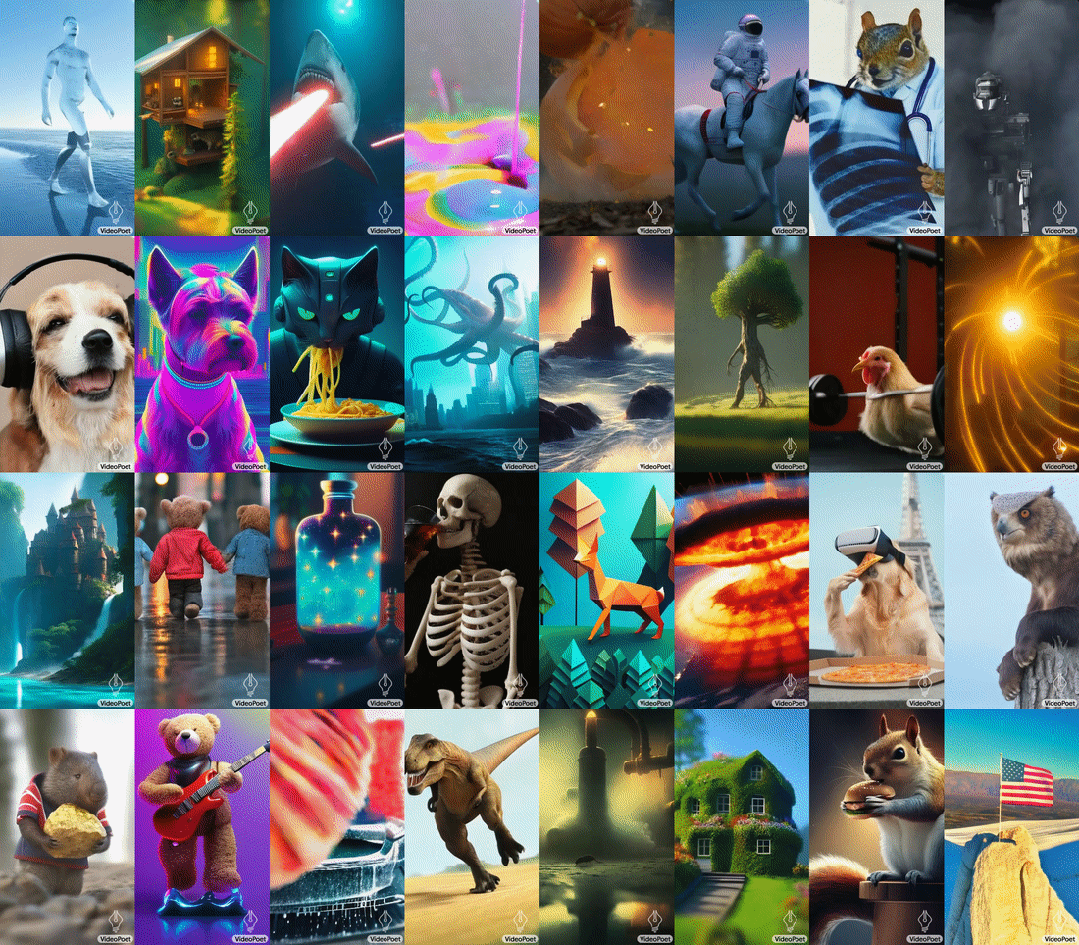
VideoPoet 根据各种文本提示生成的视频。
长视频

提示词:一名宇航员开始在火星上跳舞,背景是五彩缤纷的烟花。
趋动云赋能视频创作
视频生成技术的飞速发展离不开算力的强大支持。随着云计算技术的日益成熟和普及,趋动云作为算力服务商提供了高性能、高可靠性的算力资源,为视频生成技术的进步奠定了坚实基础。利用云计算平台提供的强大算力,视频生成模型能够更高效地训练和推理,从而不断提升生成的质量和效率。
未来,随着算力技术的不断创新和发展,视频生成技术将迎来更加广阔的发展空间。
参考文献
- https://stability.ai/news/stable-diffusion-3
- https://arstechnica.com/information-technology/2024/02/stability-announces-stable-diffusion-3-a-next-gen-ai-image-generator/
- Flow Matching论文地址:https://arxiv.org/abs/2210.02747
- https://blog.research.google/2023/12/videopoet-large-language-model-for-zero.htm