J Cheminform|DeepSA:深度学习驱动的化合物可合成性预测
J Cheminform|DeepSA:深度学习驱动的化合物可合成性预测

2023年11月2日,上海科技大学白芳老师团队在J Cheminform上发表文章DeepSA:a deep-learning driven predictor of compound synthesis accessibility。

作者提出了一个基于深度学习的计算模型DeepSA,用于预测化合物的可合成性(synthesis accessibility,SA),为分子筛选提供了有用的工具。DeepSA是一种化学语言模型,通过使用各种自然语言处理(NLP)的深度学习预训练模型,对大规模分子的数据集进行训练,并进行可合成性预测。DeepSA超越了现有的方法,并将有助于减少药物发现和开发所需的时间和成本。
背景
随着人工智能技术的不断发展,越来越多的生成新分子的计算模型被开发出来。然而,大多数由生成模型产生的新分子在可合成性方面往往面临重大挑战。可合成性预测可以看作是一个需要大量数据的复杂问题,机器学习适合于处理这类问题。基于大规模的分子训练数据集及其预先定义的“可合成性分数”,可以设计一个人工智能模型来学习分子结构与其可合成性之间的关系。
方法
本文提出的DeepSA包括三个模块:数据处理模块、特征嵌入模块和解码器模块。DeepSA的架构如图1所示。首先将数据集中原始的SMILES转换为规范的SMILES,然后通过RDKit引入一些随机选择的分子的替代格式的SMILES来进一步扩展数据集。经过数据增强后,训练、测试数据集的最终大小分别为3593053和399216。同时,使用HuggingFace标记器库中的字节对编码器(bit pair encoder, BPE)标记器(tokenizer)对化合物的结构进行编码,该标记器可以将输入SMILES中的基本原子和环结构视为“单词”或“句子”,并使用先前报道的SMILES预训练模型ChemBERTa进行有意义的预测。在标记中,综合使用了标记编码(token embedding)、位置编码(position embedding)和通过语义分割得到的片段编码(segment embedding)。
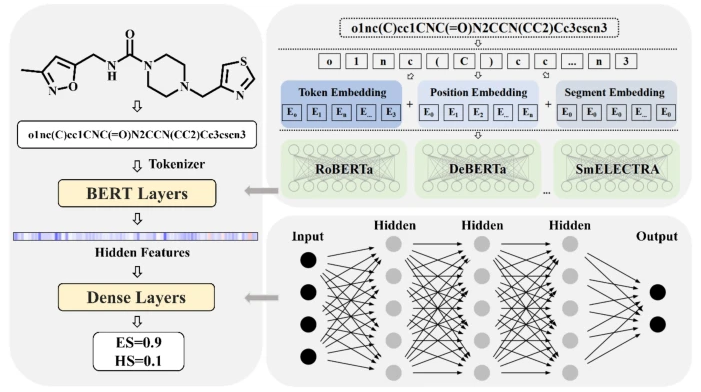
图1 DeepSA结构图
近年来,随着自然语言处理技术的发展,出现了大量的自然语言模型,为像自然语言一样处理分子序列数据提供了一系列框架。直观地说,用于表示化合物的SMILES序列与自然语言有某些相似之处。两者都是由多种简单的词汇组成,并通过简单的规则生成复杂的句子。这种相似性激发了研究人员将自然语言模型的框架转移到复合数据中,目的是训练化学语言模型,例如SMILES-BERT,以提高在化合物相关任务中的性能。探索是否可以将类似于自然语言中的文本分类任务的训练策略应用于化学语言模型来评估分子的可合成性,将进一步提高对化学语言模型和化合物可合成性的理解。
为此,作者首先从不同的自然语言模型中收集了一些网络架构,包括bert-mini (MinBert)、bert-tini (TinBert)、RoBERTa-base (RoBERTa)、DeBERTa-v3-base (DeBERTa)、Chem_GraphCodeBert (GraphCodeBert)和electra-small-discriminator (SmELECTRA),以及两个化学语言模型,包括ChemBERTa-77M-MTR (ChemMTR)和ChemBERTa-77M-MLM (ChemMLM)。
MinBERT:BERT的一个轻量级版本,通过减少模型的大小和复杂度来加速推理和减少计算资源需求。
TinBERT:与MinBERT类似,是BERT的另一个轻量级变体,通过进一步减少模型参数和优化结构来提供更快的推理速度。
RoBERTa:在BERT基础上进行了改进,使用更大的数据集进行训练,并且采用了动态掩膜策略,以提高模型的鲁棒性。
DeBERTa:在BERT的基础上引入了解耦注意力和增强型掩码策略,以提高模型的表示能力和对上下文的理解。
GraphCodeBert:在BERT的基础上结合了图结构和代码表示,可用于处理化学相关的文本和图数据。
SmELECTRA:ELECTRA的轻量化版本,结合了BERT与生成对抗网络,使用生成器-判别器的架构,其中判别器尝试区分输入数据是由生成器生成的还是来自真实数据集。
ChemMTR:一个化学领域的BERT模型,使用分子性质预测的多任务回归(multi-task regression,MTR)任务进行预训练,以增强对化学结构的理解。
ChemMLM:与ChemMTR类似,但使用掩码语言建模(masked language modelling,MLM)任务进行预训练,这是一种常见的自然语言处理任务,用于预测文本中被掩码的词。
接着,作者基于这些不同的自然语言模型和两种化学语言模型,使用设计的分子可合成性数据集训练DeepSA模型,得到分子的隐藏表示。然后,对这些自然语言模型的体系结构在可合成性预测任务上进行微调。AutoGluon包被用于微调阶段,以自动化地选择和调整模型,并存储验证集上准确率较高的模型。最后,通过“模型汤”方法(model soup method)融合准确率前三的模型,生成最终的DeepSA模型。
作者通过逆合成规划算法Retro-star标记可合成性,这是一种基于神经网络的A-star算法,可以有效地找到目标化合物的简化合成路线。一个分子需要小于或等于10个合成步骤被标记为ES (easy-to-synthesize,易合成),如果需要的合成步骤大于10或不能成功合成则被标记为HS (hard-to-synthesize,难合成)。将ES样本和HS样本分别视作阴性或阳性样本,其标签分别为0或1。于是,DeepSA输出的是一个(0,1)区间的分数,该分数越高说明化合物越难合成。同时,为了与二分类模型(即预测ES或HS)进行比较,DeepSA可选择不同的阈值,当预测分数大于该阈值,则预测为HS,否则预测为ES。
结果
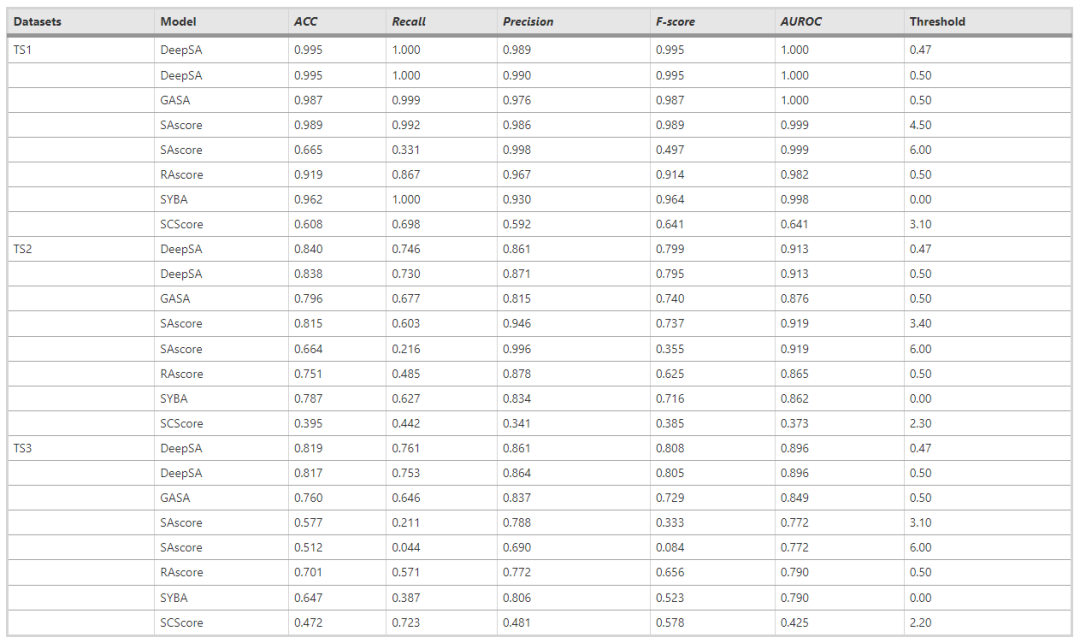
作者将DeepSA与一些具有代表性的方法进行了比较,在TS1, TS2, TS3这三个测试集上使用多个二分类指标(ACC, Recall, Precision, F-score, AUROC)来评估模型(越高越好),如表1所示。对于不同的数据集,本文提出的模型均超越了现有方法。
当前,对于可合成分数的定义,并没有一个统一的标准。对于DeepSA、SAscore和SCscore,越高的分数意味着分子越难合成,高于阈值的输出分数视为HS,低于阈值的输出分数视为ES。相反,对于GASA、RAscore和SYBA,越高的分数意味着分子越容易合成,高于阈值的输出分数为ES,低于阈值的输出分数为HS。不同方法输出的分数值域也不相同,DeepSA、GASA和RAscore输出的是一个(0,1)区间的分数,SYBA输出的值域是(-100,100),SAscore和SCscore的输出值域是(0,10)。为了能够比较所有模型的性能,需要使用不同的分类阈值来评估这些方法。因此,表1中列出了对于各个模型所选择的阈值。DeepSA在不同的阈值下均超越了现有方法。
表1 与其他方法对比
作者设计了消融实验。在训练集上对不同的语言模型进行对比。如表2所示,结果表明不同的预训练语言模型在可合成性预测中均具有较高的准确度,特别是基于化学语言的模型ChemMTR和ChemMLM具有更高的AUROC,能增强模型的预测能力。
表2 消融实验

作者还进行了案例分析。选取18种化合物,将其在DeepSA中的嵌入可视化,其中每个化合物都表示为256维向量。如图2所示,HS和ES的嵌入在大部分区域存在显著差异。ES的前100个维度的向量大小明显大于HS,而后100个维度的向量大小则相反。这表明DeepSA模型具有一定的可解释性。
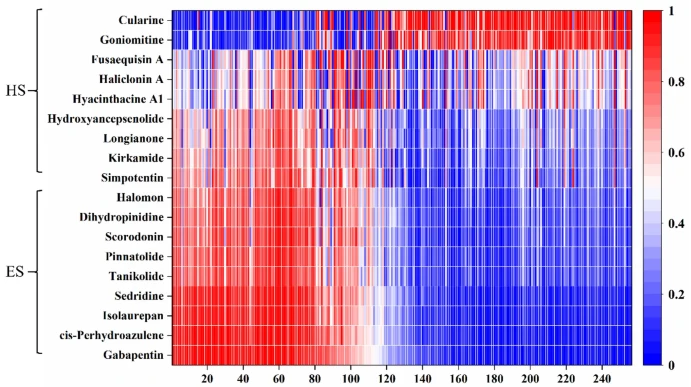
图2 案例分析
总结
在这项研究中,作者提出了一种名为DeepSA的新工具,这是一个基于化学语言模型开发的深度学习模型,可用于有机化合物的可合成性评估,它比以前已知的技术具有优势。然而,DeepSA仍有改进的余地。
第一,目前确定数据集中的分子是否难以合成的标签,是基于逆合成分析软件计算的评估,而不是基于研究者在实际的化学合成实验过程和结果的评估。这意味着,DeepSA无法了解真正的化学反应和实际的合成途径,而只能评估这些合成过程的复杂程度。
第二,确定评价一种化合物的合成难度的标准仍然是一个需要考虑的问题。在本研究中,以10个合成步骤作为HS和ES的阈值比较武断,而且基于逆合成算法去预测一个化合物的合成步骤数,其结果很容易受到逆合成算法参数设置的影响。实际上,评价一种化合物的合成难易性时,不仅要考虑合成反应的步骤数,还要关注每一步反应所得产物的产率、每一步化学反应的成本与实验条件的关系等。
以上问题是对化合物可合成性预测的巨大挑战,需要大量的时间和精力来解决。然而,在当前深度生成模型快速发展的背景下,评估化合物的合成难度具有非常高的学术和商业价值,值得继续努力进行深入思考和研究。
参考文献
[1] Wang et al. DeepSA: a deep-learning driven predictor of compound synthesis accessibility. J Cheminform. 2023