0913-7.7.1-Replication Manager使用优化
0913-7.7.1-Replication Manager使用优化

1 源集群中Hive数据分析
1.1 Hive Stats元数据解析
在当前CDP的大部分的场景中,PART_COL_STATS和TAB_COL_STATS这两张Hive元数据表都会比较大。因为这两张表是分别存放分区表和非分区表的一些字段上的统计信息,而在CDP中Hive的CBO、Mapjoin和谓词下推等优化查询功能默认是开启的,而这些优化功能又需要基于这些统计信息来做优化,所以在一个已经稳定运行的生产环境中,对应的这两张表可能有非常庞大的数据量(上千万甚至于上亿)。
1.2 分区表
1.在源集群中创建一张表testbdr1,并为其写入几条数据
create external table testbdr1 (id string,name string,sex string) partitioned by (daytime string);
insert into table testbdr1 partition (daytime = '20231101') values ('zhangsan','1','boy'),('wangwu','2','boy');
insert into table testbdr1 partition (daytime = '20231102') values ('hahah','3','boy'),('eqweq','4','boy');
insert into table testbdr1 partition (daytime = '20231103') values ('dadsa','5','boy'),('cadeqw','6','boy');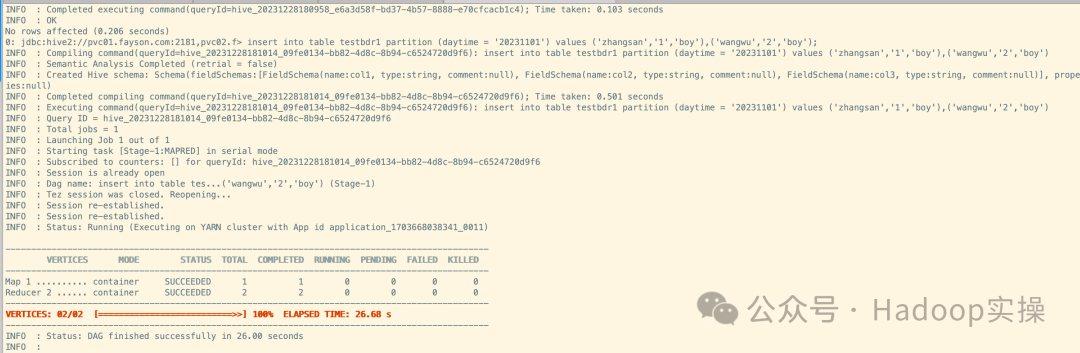
select * from testbdr1;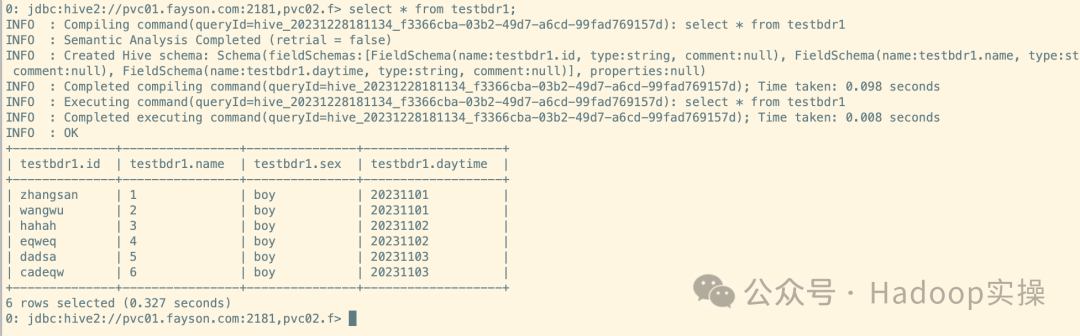
2.查看Hive元数据表信息
select * from PART_COL_STATS where TABLE_NAME = 'testbdr1';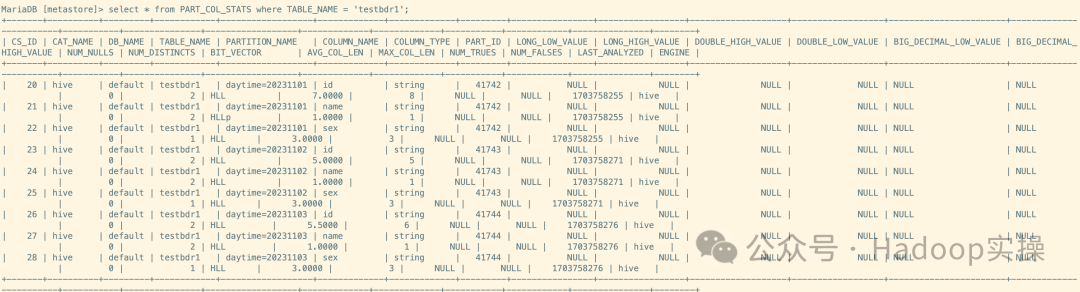
1.3 非分区表
1.在源集群中创建一张表testbdr1,并为其写入几条数据
create external table testbdr2 (id string,name string,sex string);
insert into table testbdr2 values ('1','zhangsan','boy');
insert into table testbdr2 values ('2','dasdas','boy');
insert into table testbdr2 values ('3','daskhdkad','boy');
select * from testbdr2;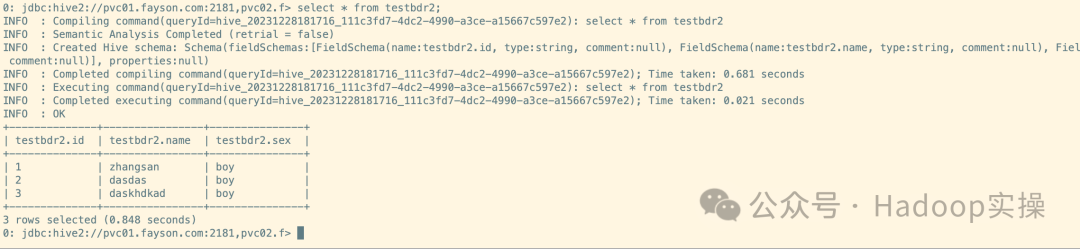
2.查看Hive元数据表信息
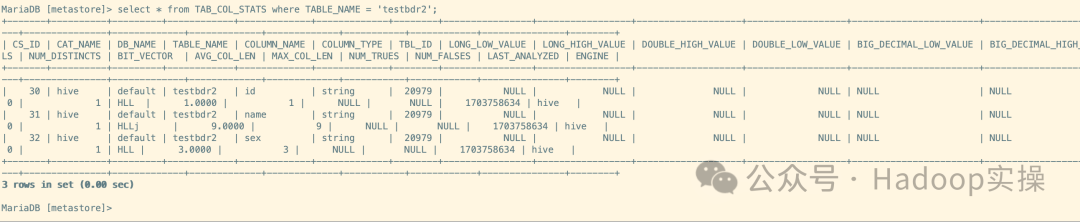
2 BDR Hive同步任务
2.1 BDR Hive Replication使用介绍
1.BDR Hive Replication作业,在配置页面有高级参数可以配置,如下:

2.资源页面介绍(资源池页面的配置主要针对于Replication MR任务)
Scheduler池: 这里可以指定MR任务运行在哪个资源池,如果MR复制阶段运行较慢,可以考虑将任务发起到一个资源充足的资源池,保障MR的运行速度。
最大Map时隙:指的是 MR任务发起的时候,Map Task的数量,如果MR复制任务需要复制的数据量较大或者文件数量较多,可以考虑适当的加大该值,保证MR的运行速度。
最大带宽: 指的是每个Map Task可以使用到的带宽。
File Listing Threads/复制策略: 一般建议保持默认即可。
3.高级配置页面介绍


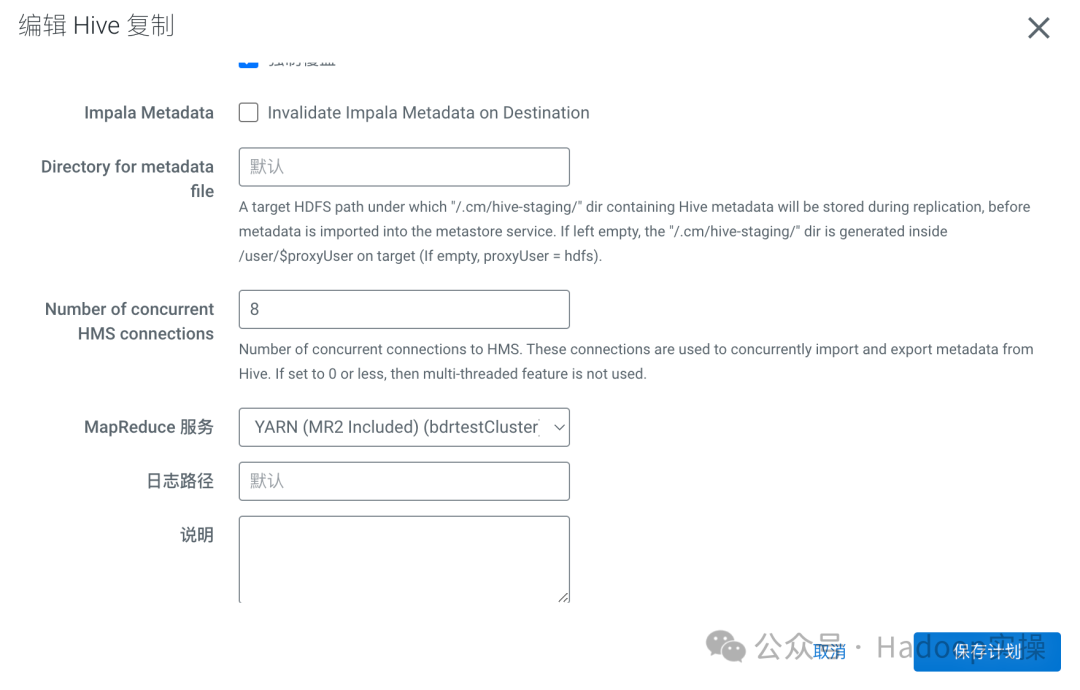
Hive复制: 这里可以选择是否同样复制HDFS文件(也就是真实数据),如果不勾选则只同步Hive元数据。
Impala Metadata: 勾选后在BDR同步结束时会对Impala执行invalidate Metadata的动作,这里一般不建议勾选。
Directory for MetadataFile: 这里可以输入一个自定义HDFS路径,作为BDR的临时目录,一般不单独指定,默认使用BDR任务执行用户目录。
Number of concurrent HMS connections: 这里指导入Hive MetaStore的BDR任务线程数量,默认值为4,如果同步的表数量较多,元数据量较大,可以适当加大该值。
MapReduce 服务: 这里保持默认即可。
日志路径: 一般不进行修改,默认路径为process进程目录。
错误处理: 对于BDR任务的错误处理,根据需求来选择处理方式即可。
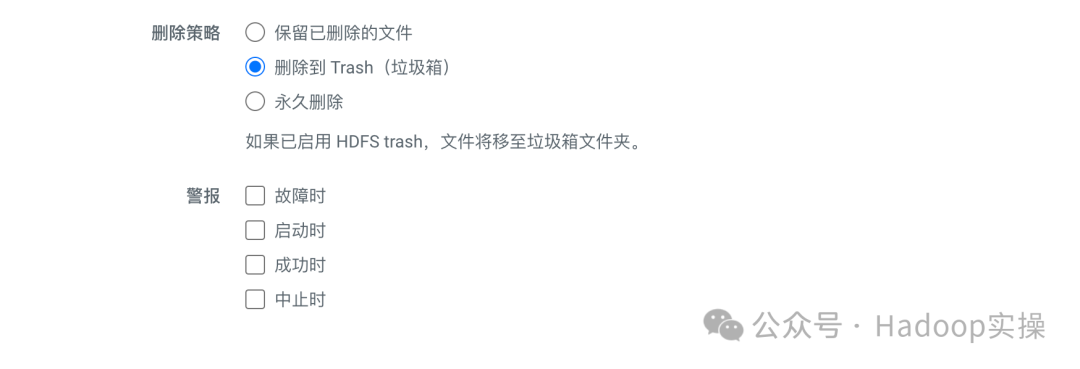
保留: 这里指从源端同步过来的数据,保留的信息有哪些,根据需求选择对应的保留即可。
删除策略: 这里指的是从源端同步过来的数据,目标端如果有需要删除的文件,如果进行删除,这里根据需求选择即可,一般建议保存到Trash。
警报: 一般保持默认即可。
2.2 当前元数据检查
1.在目标集群中查询这两张Stats表的数据
当前没有这两张表的信息
select * from PART_COL_STATS;
select * from TAB_COL_STATS;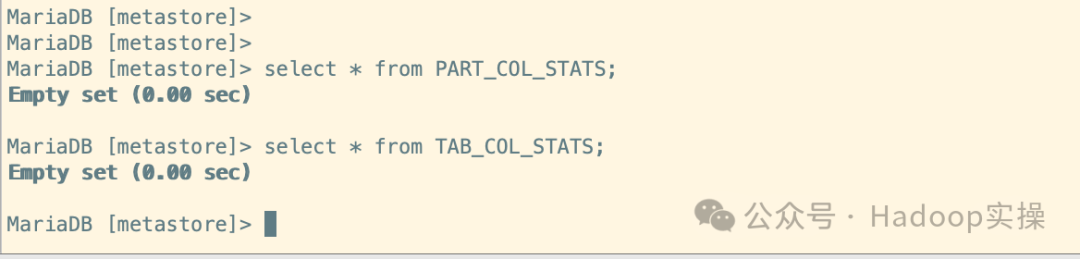
2.使用BDR将源集群中的testbdr1和testbdr2表同步过来
同步任务

同步完成
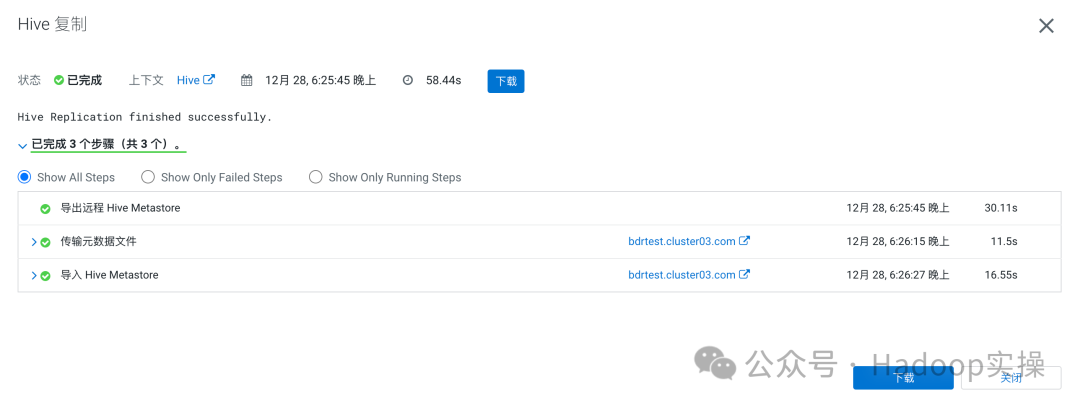
3.元数据检查
可以看到元数据已经同步过来了,带着States信息也被一起拷贝过来了
select * from PART_COL_STATS;
select * from TAB_COL_STATS;
select * from TBLS where TBL_NAME like 'test%'

2.3 同步执行过程分析
2.3.1 元数据同步,不同步真实数据
1.可以看到,这种同步方式,Replication总共只有如下三个步骤
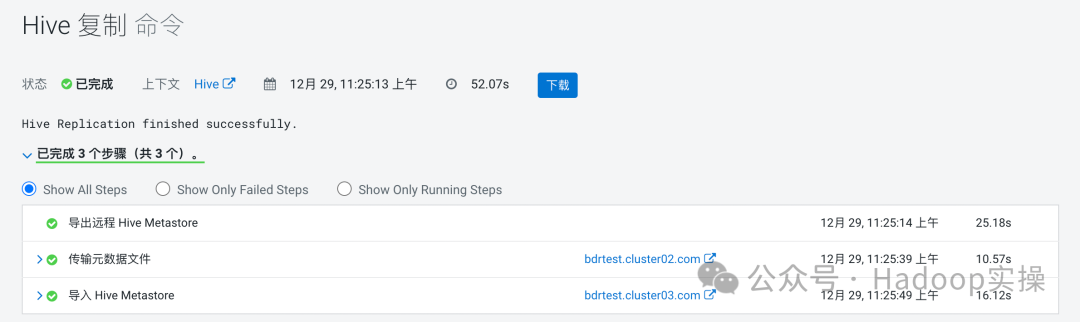
2.导出远程Hive MetaStore这一个步骤会在源端发起一个导出的命令,以BDR配置的表信息等为准

3.传输元数据文件的本质就是一个Distcp任务,将元数据文件等在源端导出的信息拷贝到目标集群中
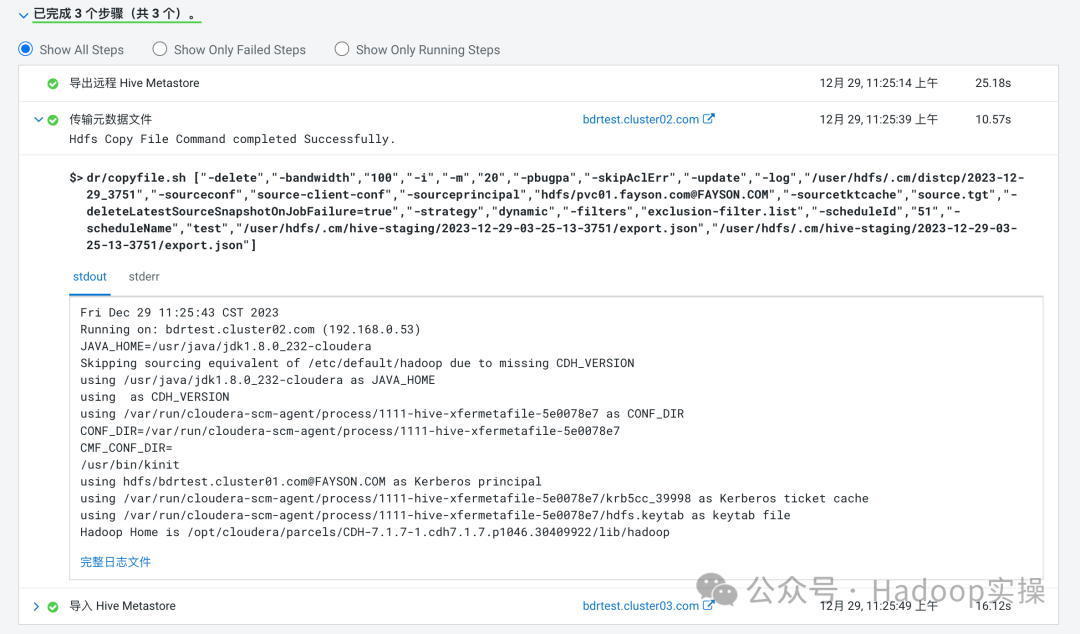
4.导入Hive MetaStore就是将拷贝过来的元数据文件导入进目标端的数据库中,使Hive可读

2.3.2 元数据和真实数据同步
1.这种同步方式相对于只同步元数据,不同步真实数据这个方式来说,只多了两个步骤
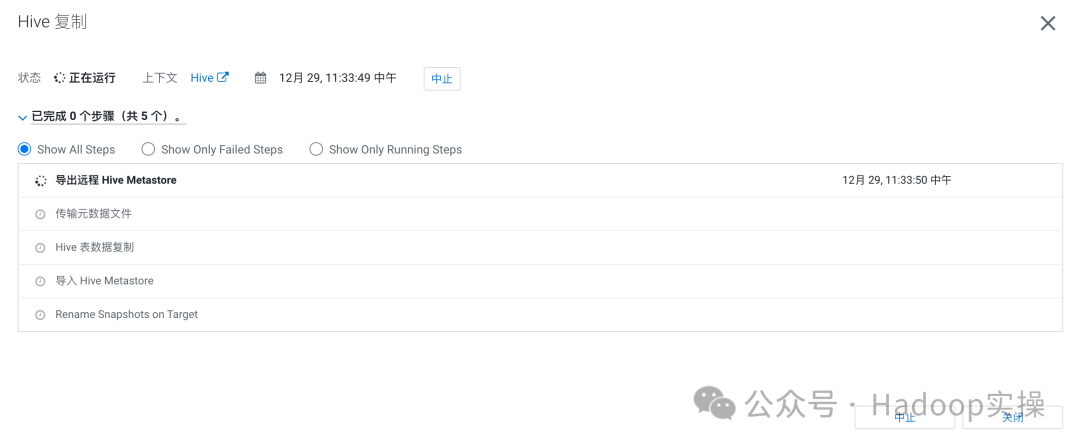
2.Hive表数据复制这个步骤,总的来说就是需要拷贝的文件会形成一个列表,然后对于这个列表源集群和目标集群都会进行一个check的动作,最后通过一个Distcp的命令将数据复制过来
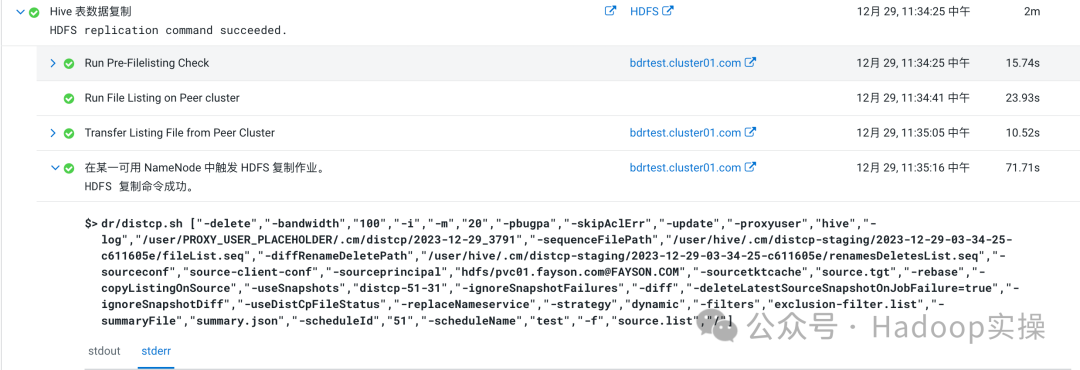
3.最后一步Rename Snapshots,这个是如果源集群有启用快照的话,同步完成之后会重命名同步后的快照文件,没有启用快照则跳过

3 BDR同步优化
3.1 Partition Ignored优化
可以如下参考文档:
https://docs.cloudera.com/replication-manager/cloud/operations/topics/rm-pc-troubleshoot6.html
The partition parameter names you provide are not compared during the import stage of the partition metadata replication process. Therefore, even if the partition parameters do not match between the exported and existing partitions, the partition is not dropped or recreated. After you configure this key-value pair, the import stage of the partition metadata replication process completes faster.1.进入CM,点击Hive > 配置 > 搜索replication,添加如下配置参数
HIVE_IGNORED_PARTITION_PARAMETERS=transient_lastDdlTime,totalSize,numRows,COLUMN_STATS_ACCURATE,numFiles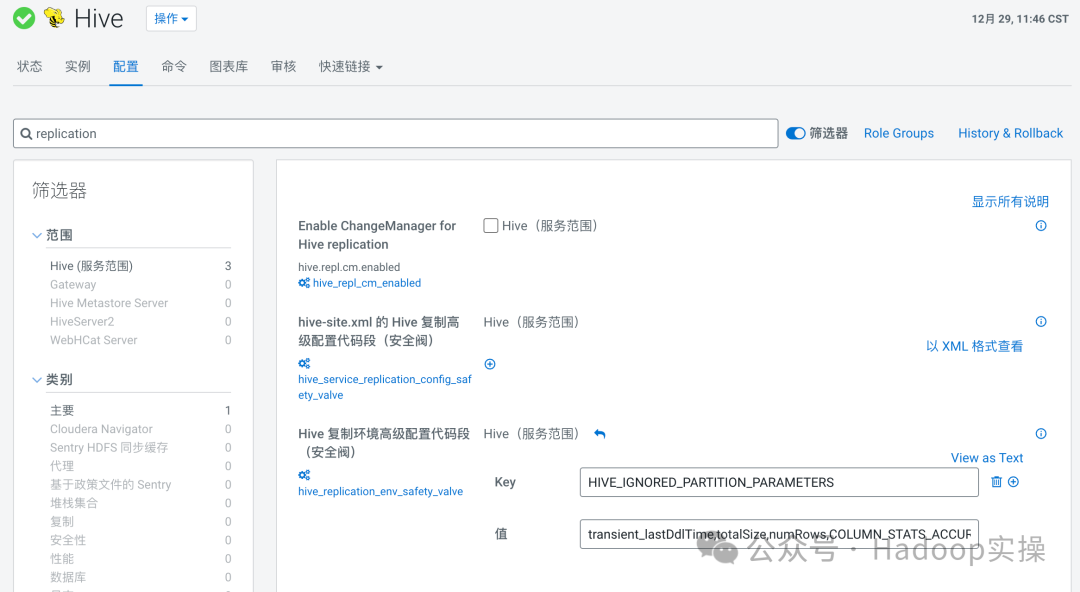
2.保存配置即可,该配置修改不需要重启服务

3.重新发起BDR任务,与之前的任务比对
修改参数之前:
dr/chive.sh ["-i","-o","-b","-t","default:testbdr1","-t","default:testbdr2","-f","/user/hdfs/.cm/hive-staging/2023-12-29-03-25-13-3751/export.json","-d","-h","-v","-x","-scheduleId","51","-scheduleName","test","-numThreads","4"]
修改参数之后:
dr/chive.sh ["-i","-o","-b","-t","default:testbdr1","-t","default:testbdr2","-f","/user/hdfs/.cm/hive-staging/2023-12-29-03-48-49-3831/export.json","-d","-h","-v","-x","-scheduleId","51","-scheduleName","test","-numThreads","4","-ignoredPartitionParameter","totalSize","-ignoredPartitionParameter","numRows","-ignoredPartitionParameter","COLUMN_STATS_ACCURATE","-ignoredPartitionParameter","numFiles","-ignoredPartitionParameter","transient_lastDdlTime"]
经过如上比对,可以发现该配置已经生效,正常的加入了Hive Replication中
3.2 Replication Advanced优化
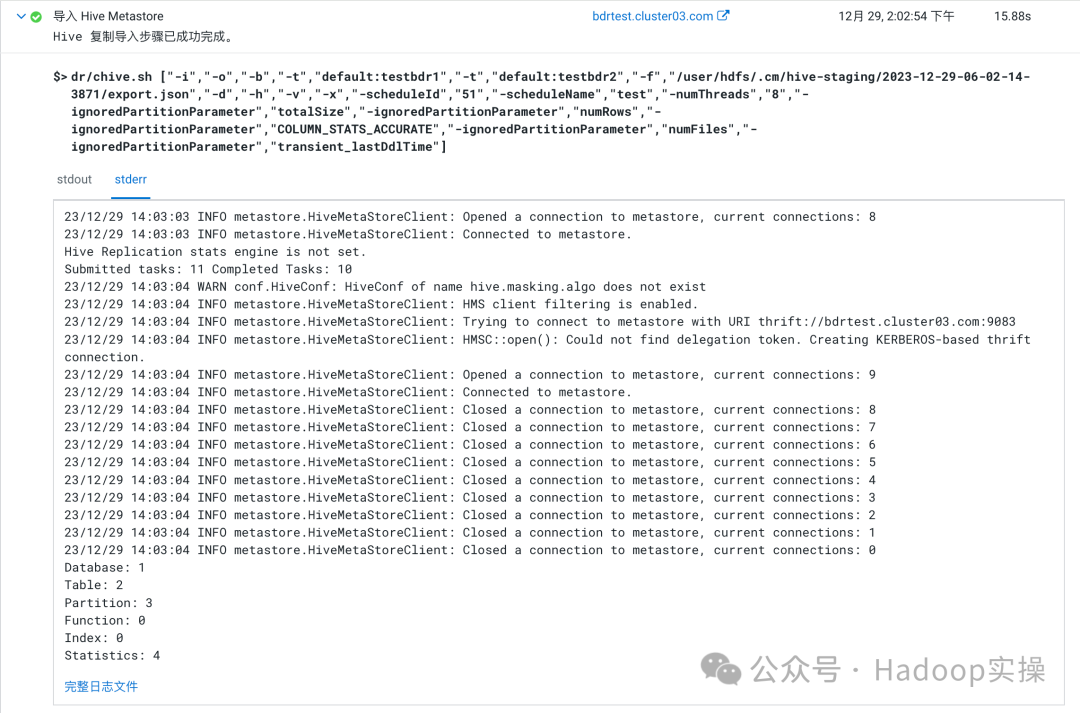
1.进入BDR Hive Replication配置高级参数页面,加大Hive MetaStore concurrent Thread
2.执行该任务,可以看到Hive MetaStore connecting已经变多了,实际中根据需求来进行调整该值,即可达到加快Hive元数据导入的效果
加大线程之前:

加大线程之后:
3.3 Partition/Col Stats优化
参考文档:
https://docs.cloudera.com/cdp-private-cloud-base/7.1.8/manager-release-notes/topics/chf14-cm-771.html3.3.1 场景叙述
1.发起一个BDR Hive Replication任务

2.任务执行完成,进行任务分析
任务完成:
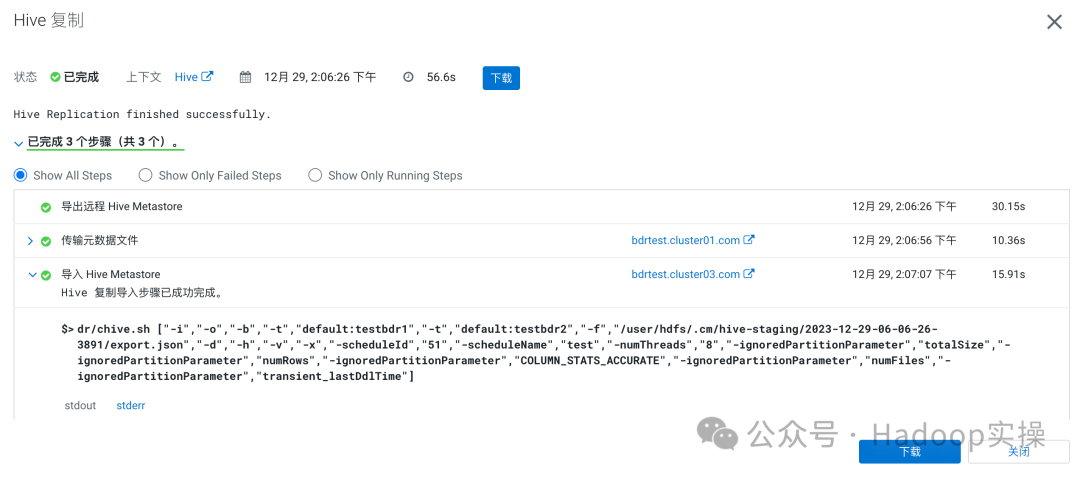
MySQL Binlog检查分析:
cat mysqld.log | grep -i part_col
SELECT 'org.apache.hadoop.hive.metastore.model.MPartitionColumnStatistics' AS `NUCLEUS_TYPE`,`A0`.`AVG_COL_LEN`,`A0`.`CAT_NAME`,`A0`.`COLUMN_NAME`,`A0`.`COLUMN_TYPE`,`A0`.`DB_NAME`,`A0`.`BIG_DECIMAL_HIGH_VALUE`,`A0`.`BIG_DECIMAL_LOW_VALUE`,`A0`.`DOUBLE_HIGH_VALUE`,`A0`.`DOUBLE_LOW_VALUE`,`A0`.`ENGINE`,`A0`.`LAST_ANALYZED`,`A0`.`LONG_HIGH_VALUE`,`A0`.`LONG_LOW_VALUE`,`A0`.`MAX_COL_LEN`,`A0`.`NUM_DISTINCTS`,`A0`.`NUM_FALSES`,`A0`.`NUM_NULLS`,`A0`.`NUM_TRUES`,`A0`.`PARTITION_NAME`,`A0`.`TABLE_NAME`,`A0`.`CS_ID`,`A0`.`PARTITION_NAME` AS `NUCORDER0` FROM `PART_COL_STATS` `A0` WHERE `A0`.`TABLE_NAME` = 'testbdr1' AND `A0`.`DB_NAME` = 'default' AND `A0`.`CAT_NAME` = 'hive' AND `A0`.`ENGINE` = 'hive' AND `A0`.`PARTITION_NAME` = 'daytime=20231101' AND (((`A0`.`COLUMN_NAME` = 'id') OR (`A0`.`COLUMN_NAME` = 'name')) OR (`A0`.`COLUMN_NAME` = 'sex')) ORDER BY `NUCORDER0`;
cat mysqld.log | grep -i part_col | wc -l
cat mysqld.log | grep -i tab_col
SELECT 'org.apache.hadoop.hive.metastore.model.MTableColumnStatistics' AS `NUCLEUS_TYPE`,`A0`.`AVG_COL_LEN`,`A0`.`CAT_NAME`,`A0`.`COLUMN_NAME`,`A0`.`COLUMN_TYPE`,`A0`.`DB_NAME`,`A0`.`BIG_DECIMAL_HIGH_VALUE`,`A0`.`BIG_DECIMAL_LOW_VALUE`,`A0`.`DOUBLE_HIGH_VALUE`,`A0`.`DOUBLE_LOW_VALUE`,`A0`.`ENGINE`,`A0`.`LAST_ANALYZED`,`A0`.`LONG_HIGH_VALUE`,`A0`.`LONG_LOW_VALUE`,`A0`.`MAX_COL_LEN`,`A0`.`NUM_DISTINCTS`,`A0`.`NUM_FALSES`,`A0`.`NUM_NULLS`,`A0`.`NUM_TRUES`,`A0`.`TABLE_NAME`,`A0`.`CS_ID` FROM `TAB_COL_STATS` `A0` WHERE `A0`.`TABLE_NAME` = 'testbdr2' AND `A0`.`DB_NAME` = 'default' AND `A0`.`CAT_NAME` = 'hive' AND `A0`.`ENGINE` = 'hive' AND (((`A0`.`COLUMN_NAME` = 'id') OR (`A0`.`COLUMN_NAME` = 'name')) OR (`A0`.`COLUMN_NAME` = 'sex'));
cat mysqld.log | grep -i tab_col | wc -l
从上图中可以看到,同步testbdr1和testbdr2的时候,在MySQL的PART_COL_STATS和TAB_COL_STATS这两张表里进行了多次的连续查询,我们接下来去查看源端中这两张表的数据量:
show create table testbdr1;
show create table testbdr2;
select count(*) from testbdr1;
select count(*) from testbdr2;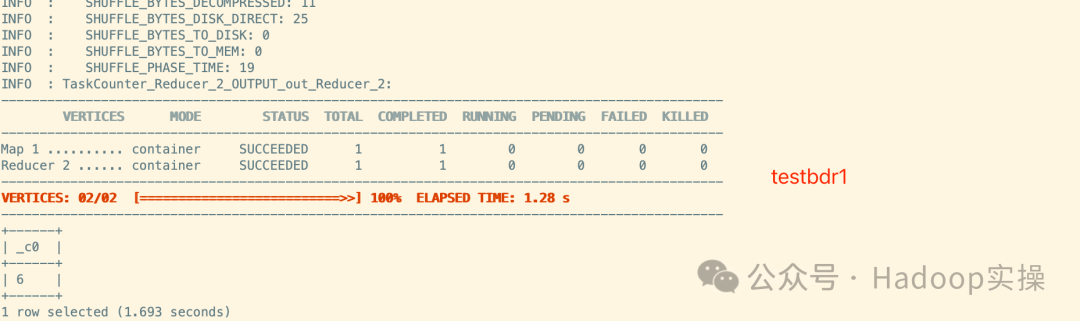
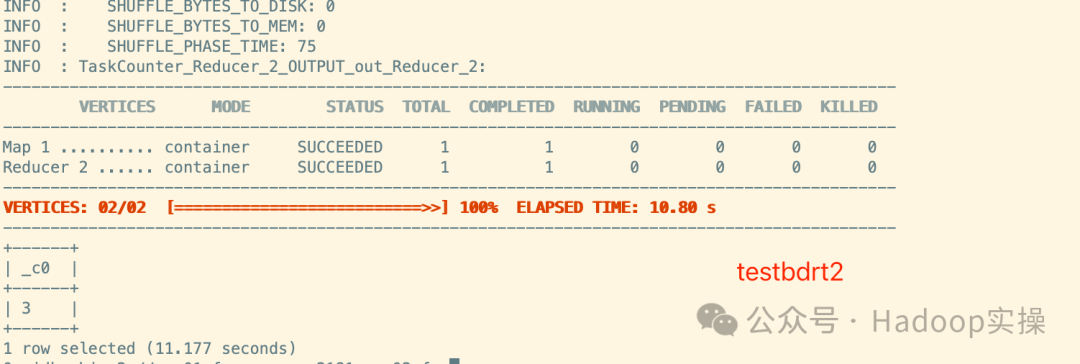
show partitions testbdr1;
从上图的查询中可以看到,表testbdr1和testbdr2,都是字段少、数据量小、分区少的测试表,但是同步这两张表都会在MySQL中进行如此复杂的查询,并且查询了多次。那么当一个集群已经平稳运行了较长时间,元数据表PART_COL_STATS和TAB_COL_STATS表也有上千万数据量的时候,同步Hive元数据就会花费特别长的时间,来做这些在数据库内的查询。
3.3.2 优化方案
1.进入CM,点击Hive > 配置 > 搜索Replication,添加如下配置
SKIP_COLUMN_STATS_IMPORT=true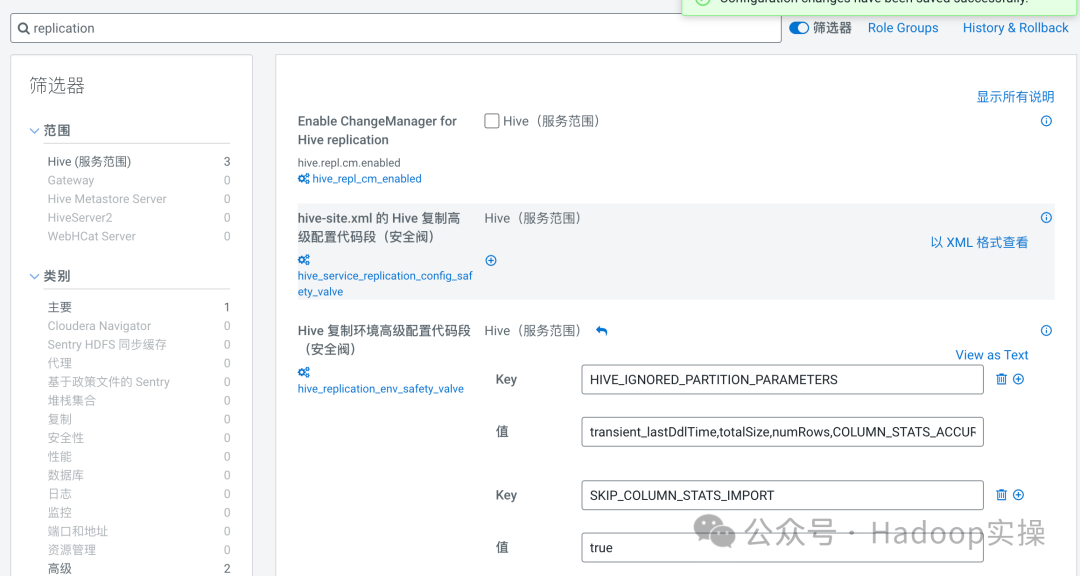
2.重新发起BDR任务
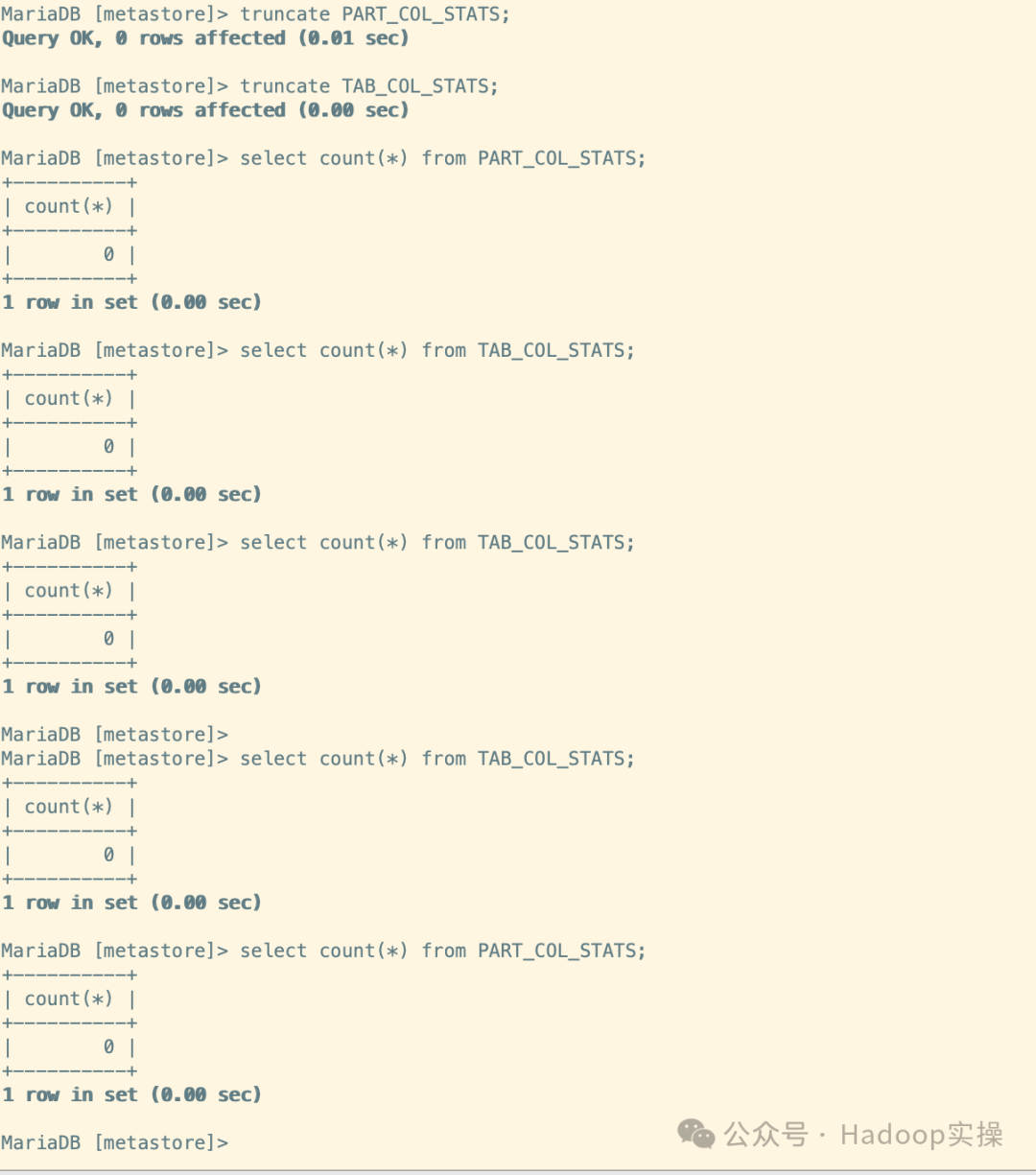
这里为了直观的观察,我们先将目标端的元数据PART_COL_STATS和TAB_COL_STATS清空
truncate PART_COL_STATS;
truncate TAB_COL_STATS;
select count(*) from PART_COL_STATS;
select count(*) from TAB_COL_STATS;
发起任务:

元数据库检查:
可以看到,STATS信息已经没再更新,参数成功生效:
select count(*) from TAB_COL_STATS;
select count(*) from PART_COL_STATS;