常见的限流算法-python版本
原创常见的限流算法-python版本
原创
shigen坚持更新文章的博客写手,擅长Java、python、vue、shell等编程语言和各种应用程序、脚本的开发。记录成长,分享认知,留住感动。 个人IP:shigen
在系统的稳定性设计中,需要考虑到的就是限流,避免高并发环境下一下子把服务整垮了。shigen在翻看以前的笔记的时候,看到了python版本的限流算法,在此做一个分享。
前提
本地的redis服务已经启动,mac用户两行命令即可:
brew install redis && brew services start redis完了之后,在代码里写上获得redis连接的代码:
def get_redis_con():
pool = redis.ConnectionPool(max_connections=4, decode_responses=True)
return redis.Redis(connection_pool=pool)其他配置参照官方文档。
固定窗口
类似于把时间切分了,每个时间段只允许固定次的请求。
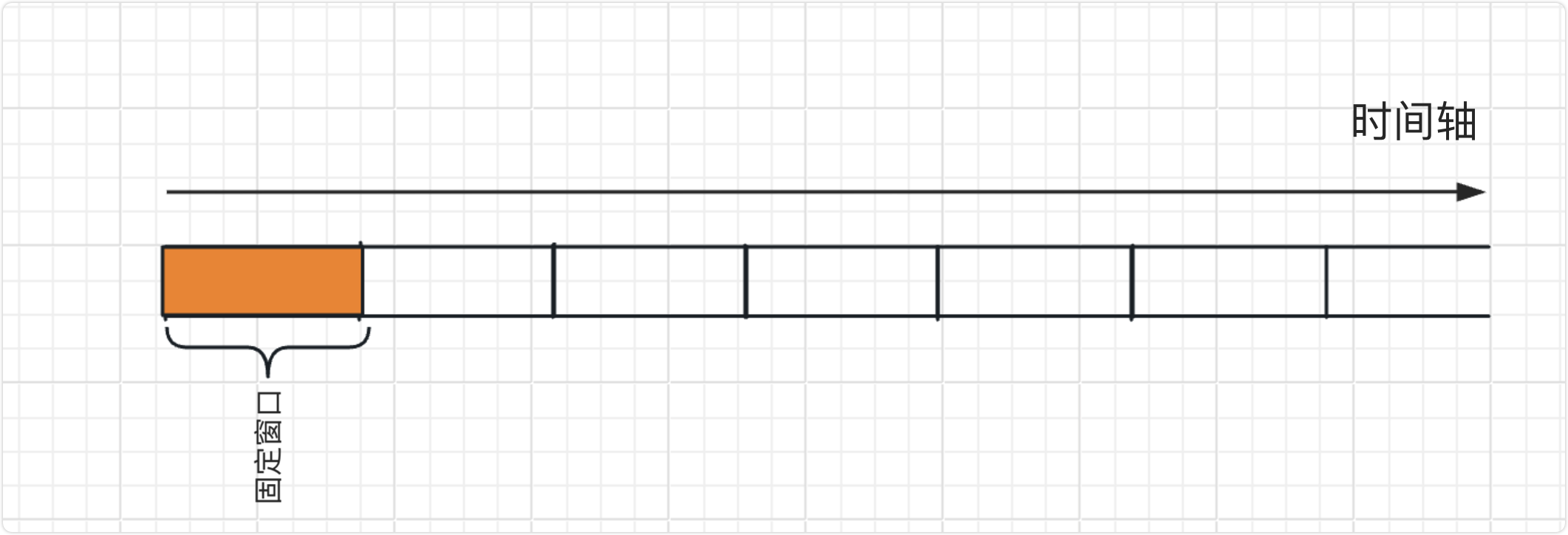
最直白的话语就是:我的接口1s只允许100次请求,多了我就抛异常。
def fixed_window(user, action, time_zone=60, max_times=30):
key = f'{action}'
count = get_redis_con().get(key)
if not count:
count = 1
get_redis_con().setex(key, time_zone, count)
if int(count) < max_times:
get_redis_con().incr(key)
return True
return False代码中加上了user,其实就是避免单个用户的接口防刷。在之前的文章<如何优雅的实现接口防刷>中,其实就是用的这种方法。
对应的话,其实也是有一些问题的。
最主要的一个缺点就是:流量不是平滑的,可能存在多个流量峰值导致服务间歇性的不可用。最直观的感受是在窗口切换的时候,流量堆积导致的问题。
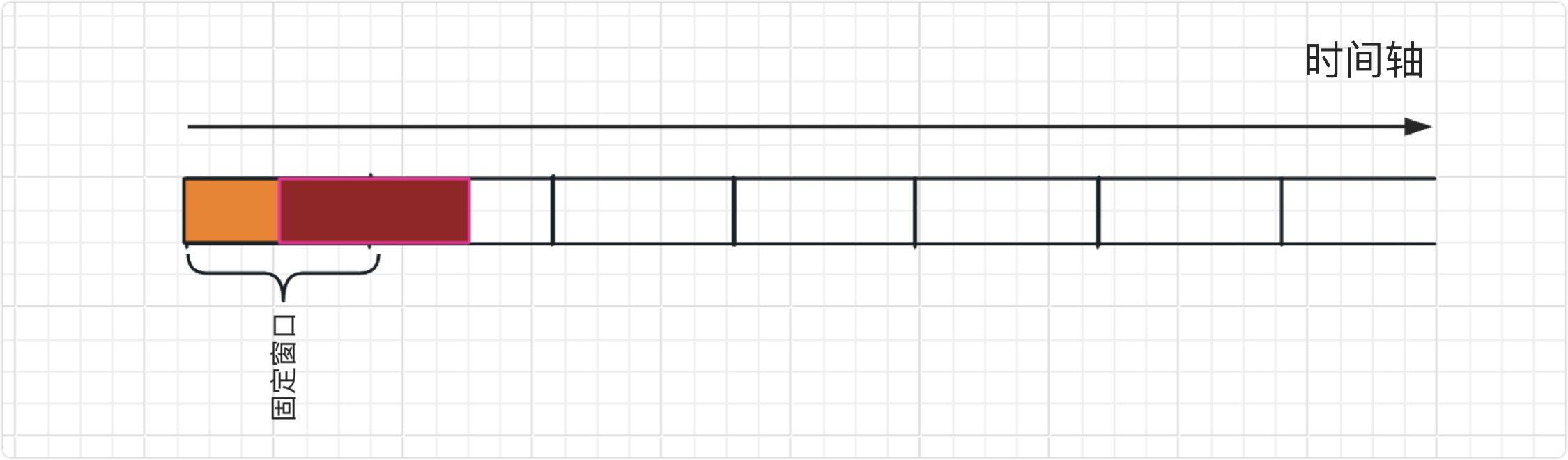
滑动窗口
描述的原理是:
- 将时间划分为细粒度的区间,每个区间维持一个计数器,每进入一个请求则将计数器加一;
- 多个区间组成一个时间窗口,每流逝一个区间时间后,则抛弃最老的一个区间,纳入新区间;
- 若当前窗口的区间计数器总和超过设定的限制数量,则本窗口内的后续请求都被丢弃。
可能还是有一些抽象,我们借用代码来讲解:
def silde_window(user, action, time_zone=60, max_times=30):
key = f'{action}'
now_ts = time.time() * 1000
# ms级时间戳,保证唯一
value = now_ts
# 时间窗口的左边界
old_ts = now_ts - time_zone * 1000
# 记录 {成员元素:分数值}
mapping = {
value: now_ts,
}
get_redis_con().zadd(key, mapping)
# 删除时间窗口之前的数据
get_redis_con().zremrangebyscore(key, -1, old_ts)
# 获得窗口内的行为数量
count = get_redis_con().zcard(key)
get_redis_con().expire(key, time_zone + 1)
if not count or int(count) < max_times:
return True
return False用到的数据结构是zset。这里的时间戳就是对应值的score。
这种方式可以应对流量的激增,但是流量的曲线还是不够平滑。
漏桶算法
就类似于一个桶,请求先去填满桶,填满之后,其它的请求直接拒绝;同时,桶以一定的速率漏出,放行请求。
这种算法的速率是不支持动态调整的,对于系统资源的充分利用上还是存在问题的。
令牌桶算法
漏桶算法的主角是桶,令牌桶的主角是令牌。
def pass_token_bucket(user, action, time_zone=60, max_times=30):
key = f'{user}:{action}'
# 令牌生成速度
rate = max_times / time_zone
capacity = max_times
token_count = get_redis_con().hget(key, 'tokens')
last_time = get_redis_con().hget(key, 'last_time')
now = time.time()
token_count = int(token_count) if token_count else capacity
last_time = last_time if last_time else now
# 经过一段时间之后生成的令牌数量
new_token_count = int((now - last_time) * rate)
if new_token_count > 1:
token_count += new_token_count
if token_count > capacity:
token_count = capacity
last_time = time.time()
get_redis_con().hset(key, 'last_time', last_time)
if token_count >= 1:
token_count -= 1
get_redis_con().hset(key, 'tokens', token_count)
return True
return False对于漏桶和令牌桶,算法的实现其实都大差不差。shigen在学习这个的时候,还有一点整混淆了。
最后,说一下如何验证,使用到了python的多线程。
executor = ThreadPoolExecutor(max_workers=4)
APIS = ['/api/a', '/get/user/1', '/get/user/2', '/get/user/3']
def task() -> bool:
user = random.randint(1000, 1010)
status = pass_token_bucket(user, random.choice(APIS))
if not status:
raise SystemError('{}被限制'.format(user))
return status
if __name__ == '__main__':
jobs = [executor.submit(task) for _ in range(1000)]
for job in jobs:
print(job.result())与shigen一起,每天不一样!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。